前言
系列专栏:机器学习:高级应用与实践【项目实战100+】【2024】✨︎
在本专栏中不仅包含一些适合初学者的最新机器学习项目,每个项目都处理一组不同的问题,包括监督和无监督学习、分类、回归和聚类,而且涉及创建深度学习模型、处理非结构化数据以及指导复杂的模型,如卷积神经网络、门控循环单元、大型语言模型和强化学习模型
对于文本分析,我们将使用 NLTK 库。NLTK 是构建 Python 程序以处理人类语言数据的领先平台。它为 50 多个语料库和词汇资源(如 WordNet)提供了易于使用的接口,同时还提供了一套用于分类、标记化、词干化、标记、解析和语义推理的文本处理库,工业级 NLP 库的封装器,以及一个活跃的讨论论坛。
目录
- 1. 相关库和数据集
- 1.1 相关库介绍
- 1.2 数据集介绍
- 1.3 数据去重统计
- 1.4 数据预处理
- 2. 探索性数据分析
- 2.1 数据集统计分析
- 2.2 转换文本为矢量
- 3. 模型训练、评估和预测
- 4. 结论
1. 相关库和数据集
1.1 相关库介绍
Python 库使我们能够非常轻松地处理数据并使用一行代码执行典型和复杂的任务。
Pandas– 该库有助于以 2D 数组格式加载数据框,并具有多种功能,可一次性执行分析任务。Numpy– Numpy 数组速度非常快,可以在很短的时间内执行大型计算。Matplotlib/Seaborn– 此库用于绘制可视化效果,用于展现数据之间的相互关系。Sklearn– 包含多个库,这些库具有预实现的功能,用于执行从数据预处理到模型开发和评估的任务。wordcloud– 单词云是在一张醒目的图片中显示许多单词的漂亮方法。TF-IDF– 是一种用于信息检索与数据挖掘的常用加权技术。
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import nltk
from nltk.corpus import stopwords
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from tqdm import tqdm
nltk.download('stopwords')
print(stopwords.words('english'))
1.2 数据集介绍
该数据集由亚马逊上的美食评论组成。数据的时间跨度超过 10 年,包括截至 2012 年 10 月的所有约 500,000 条评论。评论包括产品和用户信息、评分和纯文本评论。它还包括亚马逊所有其他类别的评论。
# Read in data
df = pd.read_csv('Reviews.csv')
df.head()

1.3 数据去重统计
pd.unique(df['Score'])
array([5, 1, 4, 2, 3], dtype=int64)
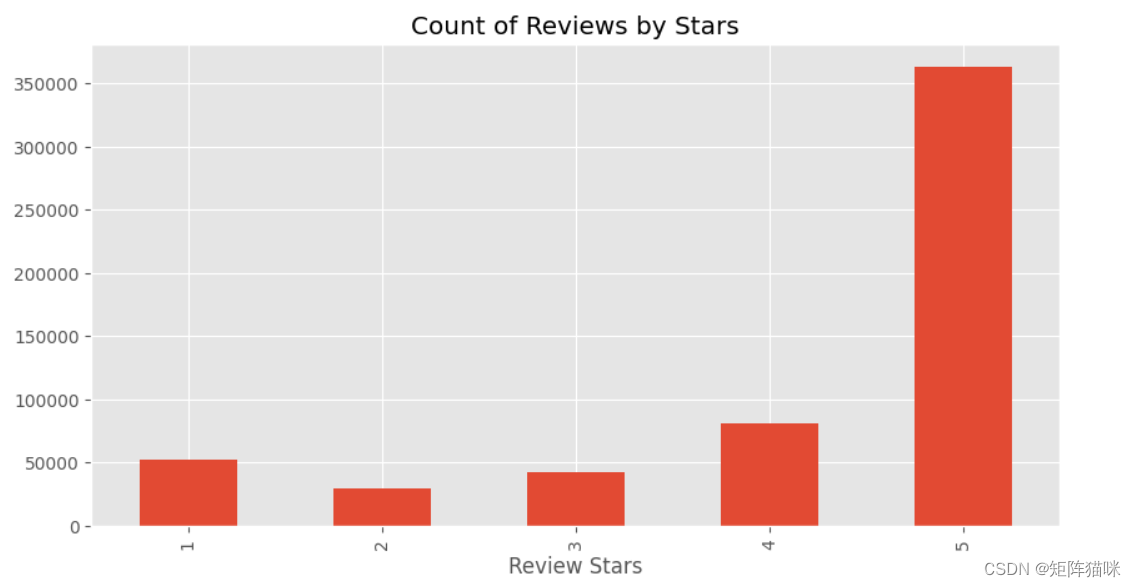
让我们看看相同的计数图
plt.style.use('ggplot')
ax = df['Score'].value_counts().sort_index() \
.plot(kind='bar',
title='Count of Reviews by Stars',
figsize=(10, 5))
ax.set_xlabel('Review Stars')
plt.show()
要将情绪预测为正(数值 = 1)或负(数值 = 0),我们需要将评级列更改为另一列 0 和 1 类别。为此,条件将类似于如果评级小于或等于 4,则它是负数 (0) 或正数 (1)。为了更好地理解,请参阅下面的代码。
# rating label(final)
pos_neg = []
for i in range(len(df['Score'])):
if df['Score'][i] >= 5:
pos_neg.append(1)
else:
pos_neg.append(0)
df['label'] = pos_neg
1.4 数据预处理
接下来,让我们创建用于预处理数据集的函数
def preprocess_text(text_data):
preprocessed_text = []
for sentence in tqdm(text_data):
# Removing punctuations
sentence = re.sub(r'[^\w\s]', '', sentence)
# Converting lowercase and removing stopwords
preprocessed_text.append(' '.join(token.lower()
for token in nltk.word_tokenize(sentence)
if token.lower() not in stopwords.words('english')))
return preprocessed_text
现在,我们可以为数据集实现此函数,代码如下。
preprocessed_review = preprocess_text(df['Text'].values)
df['Text'] = preprocessed_review
一旦我们完成了预处理。让我们看看前 5 行,看看改进后的数据集。
df.head()

2. 探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)是指对已有数据在尽量少的先验假设下通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法,该方法在上世纪70年代由美国统计学家J.K.Tukey提出。
2.1 数据集统计分析
首先,让我们看看积极和消极情绪各有多少计数。
df["label"].value_counts()
label
1 363122
0 205332
Name: count, dtype: int64
为了更好地了解单词的重要性,让我们创建标签为 1 的所有单词的词云,即 “正”。
from wordcloud import WordCloud
consolidated = ' '.join(
word for word in df['Text'][df['label'] == 1].astype(str))
wordCloud = WordCloud(width=1600, height=800,
random_state=21, max_font_size=110)
plt.figure(figsize=(15, 10))
plt.imshow(wordCloud.generate(consolidated), interpolation='bilinear')
plt.axis('off')
plt.show()

很明显,“很棒的产品”、“花生酱”、“绿茶”、“无麸质”、"强烈推荐 "等词在正面评论中出现的频率很高,这符合我们的假设。
2.2 转换文本为矢量
TF-IDF 计算一系列或语料库中的单词与文本的相关性。含义与单词在文本中出现的次数成比例增加,但由语料库(数据集)中的单词频率补偿。我们将使用以下代码实现此功能。
from sklearn.feature_extraction.text import TfidfVectorizer
cv = TfidfVectorizer(max_features=2500)
X = cv.fit_transform(df['Text']).toarray()
X
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
3. 模型训练、评估和预测
分析和矢量化完成后。现在我们可以探索任何机器学习模型来训练数据。但在此之前,要对数据进行训练-测试拆分。
X_train, X_test, y_train, y_test = train_test_split(X, df['label'],
test_size=0.33,
stratify=df['label'],
random_state = 42)
现在我们可以训练任何模型,让我们来探索决策树的预测方法。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train,y_train)
#testing the model
pred = model.predict(X_train)
print(accuracy_score(y_train,pred))
0.9997978280961183
让我们来看看混淆矩阵的结果。
from sklearn import metrics
cm = confusion_matrix(y_train,pred)
cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix = cm,
display_labels = [False, True])
cm_display.plot()
plt.show()

4. 结论
决策树分类器在处理这些数据时表现良好。今后,我们还可以通过从网站上抓取大量数据的方式来处理这些数据。