citylava:城市场景中VLMs的有效微调
- 摘要
- Introduction
- Related Work
- Vision-Language Models
- VLMs in Driving
- Methodology
CityLLaVA: Efficient Fine-Tuning for VLMs in City Scenario
摘要
在城市广阔且动态的场景中,交通安全描述与分析在从保险检查到事故预防的各种应用中起着关键作用。本文介绍了CityLLaVA,一个针对城市场景设计的视觉语言模型(VLMs)的新颖微调框架。CityLLaVA通过以下方式提升模型的认知和预测准确性:
(1) 在训练和测试阶段使用边界框进行最优视觉数据预处理,包括视频最佳视角选择和视觉提示工程;
(2) 构建简洁的问答序列并设计文本提示以细化指令理解;
(3) 实施块扩展以高效微调大型VLMs;
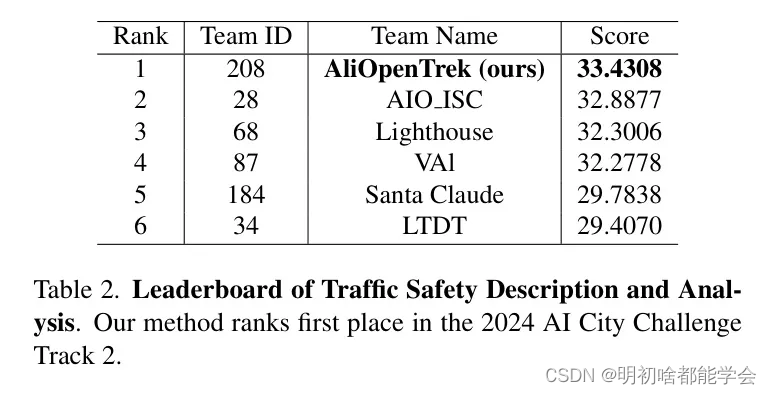
(4) 通过独特的顺序提问式预测增强来提高预测准确性。作者的方法展示了顶级性能,达到了33.4308的基准分数,在排行榜上取得了领先地位。
代码:https://github.com/alibaba/ACITY2024_Track2_AlOpenTrek_CityLLaVA
Introduction
随着大型语言模型(LLM)的快速进步,越来越多的领域开始探索这些模型的能力,研究它们对行业标准和社会实践的潜在影响。特别是在跨越计算机视觉(CV)和自然语言处理(NLP)的研究领域,如交通视频分析,这些模型不仅显著提高了自动化分析精度的标准,还开启了前所未有的应用前景。有许多基础的视觉-语言模型(VLMs),如GPT-V ,Qwen-VL-Chat ,LLaVA 等,它们证明了CV和NLP的协同潜力。尽管这些大型模型在一系列任务上展现出强大的能力,但当它们直接应用于高度专业化的领域,如交通安全场景描述时,往往未能达到预期。这显然表明这些模型需要经过必要的微调,以充分捕捉特定领域的细微差别。
将大型模型微调以满足特定应用的细粒度需求,需要应对一系列复杂的挑战,如构建有效的问题-答案对,设计适当的提示,以及选择关键的微调参数。此外,创建能够捕捉现实世界事件多方面特性的标注可能需要耗费大量劳动力。
鉴于这些挑战,本文旨在介绍一种有效的、全面的微调大型视觉-语言模型的范式,包括提示工程、持续训练和推理增强。图1展示了这一有效范式的细节,这是作者在行业实践中积累的。为了证明所提出方法的有效性,作者在 WTS 数据集上进行了详细实验。具体来说,所提出的范式在2024年AI城市挑战赛 - 交通安全描述与分析中取得了第一名,为未来研究如何提升或适应LLM以应对类似的复杂、特定领域任务提供了有价值的见解和途径。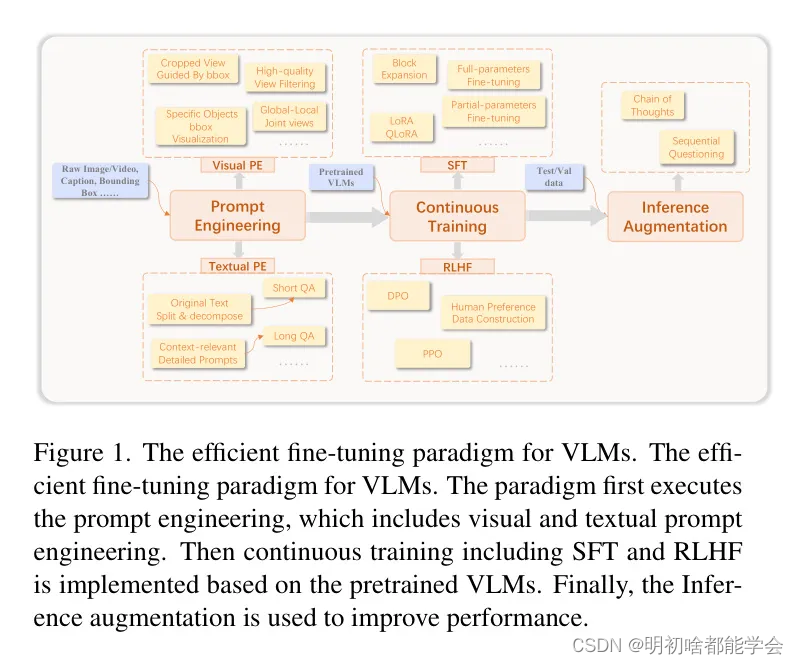
本文的贡献总结如下:
- 提出了一种针对特定领域任务的有效且全面的大型视觉-语言模型微调范式。
- 探索了视觉和文本提示工程,以构建信息丰富且精细的输入,用于训练和推理。
- 研究了VLMs中的块扩展适应性,在与LoRA [8]的比较中实现了更优的性能。
- 在WTS数据集上取得了最先进的表现,并详细探讨了影响微调效果的因素。
Related Work
Vision-Language Models
视觉-语言模型(VLMs)同时利用图像和文本数据,并在不同领域融合知识以获得更好的性能。CLIP [22]是一项开创性工作,通过设计一个预训练任务来匹配图像和文本标题,实现语言和图像的对齐。它在几个下游任务中展示了惊人的零样本迁移能力。近年来,随着大型语言模型的发展,将视觉编码器与自回归语言解码器结合已成为视觉-语言任务中的一种流行方法。这类方法可以从视觉感知和语言表达中受益,并实现更加多功能的模型。该领域的早期研究是Flamingo ,它利用门控交叉注意力接受交错的视觉和语言数据作为输入,并生成文本作为输出。BLIP-2 引入了一个轻量级但强大的模块Q-former,以有效地桥接图像和文本之间的模态差距,同时使用FlanT5 作为语言模型。在BLIP-2预训练的视觉组件基础上,Mini-GPT4 使用单个投影层将视觉特征与文本特征对齐,并输入到Vicuna [5]语言模型中。一个改进版本是MiniGPT-v2,它采用更简单的策略,直接将来自ViT [7]编码器的视觉标记投影到大语言解码器的特征空间中。LLaVA [14]采用了类似的模型结构,在编码的视觉特征后使用投影层。通过所提出的两阶段训练策略,LLaVA在视觉-语言任务中展示了令人印象深刻的能力,并且有许多基于它的工作。
VLMs in Driving
许多研究者尝试在驾驶领域应用视觉-语言模型,因为它们在视觉信号感知和语言理解方面表现出卓越的能力。先前的研究[29]在自动驾驶场景中对最先进的视觉-语言模型GPT4-V[20]进行了彻底评估,实验结果表明其性能卓越。Dolphins[18]是一种新型的视觉-语言模型,其中预训练的OpenFlamingo[1]作为基本结构,在驾驶领域表现出独特的行为。DriveGPT4[31]可以处理文本 Query 和多帧视频作为输入,并生成相应的回应,同时它还能预测低 Level 的车辆控制动作和信号。实验结果表明,DriveGPT4在某些情况下与GPT4-V相比具有可比较甚至更好的能力。
Methodology
NNPDF方法可以分为四个主要步骤:首先,生成原始实验数据的大量蒙特卡洛复制品,以足够精确地重现中心值、误差和相关关系。其次,在每个上述数据复制品上,通过神经网络对一组PDF参数进行训练(最小化)。PDF在初始演化尺度上进行参数化,然后通过DGLAP方程演化到实验数据尺度。由于PDF参数化是冗余的,因此最小化策略基于遗传算法以及基于梯度下降的最小化器。神经网络训练会在进入过度学习状态之前动态停止,即PDF在不同时拟合统计噪声的情况下学习实验数据背后的物理定律。一旦MC复制品的训练完成,就可以对PDF集合应用一组统计估计器,以评估结果统计的一致性。例如,可以明确验证与PDF参数化相关的稳定性。这组PDF集合(经过训练的神经网络)提供了底层PDF概率密度的表示,从中可以计算任何统计估计器。
Overview
CityLLaVA引入了一种高效的微调流水线,旨在增强对城市环境中的空间-时间理解并提供细粒度的感知。如图2所示,所提出的范式包括三个主要模块:视觉提示工程、文本提示工程(即文本QA构建)以及针对大型视觉-语言模型的高效微调。作者将依次介绍每个模块的细节。
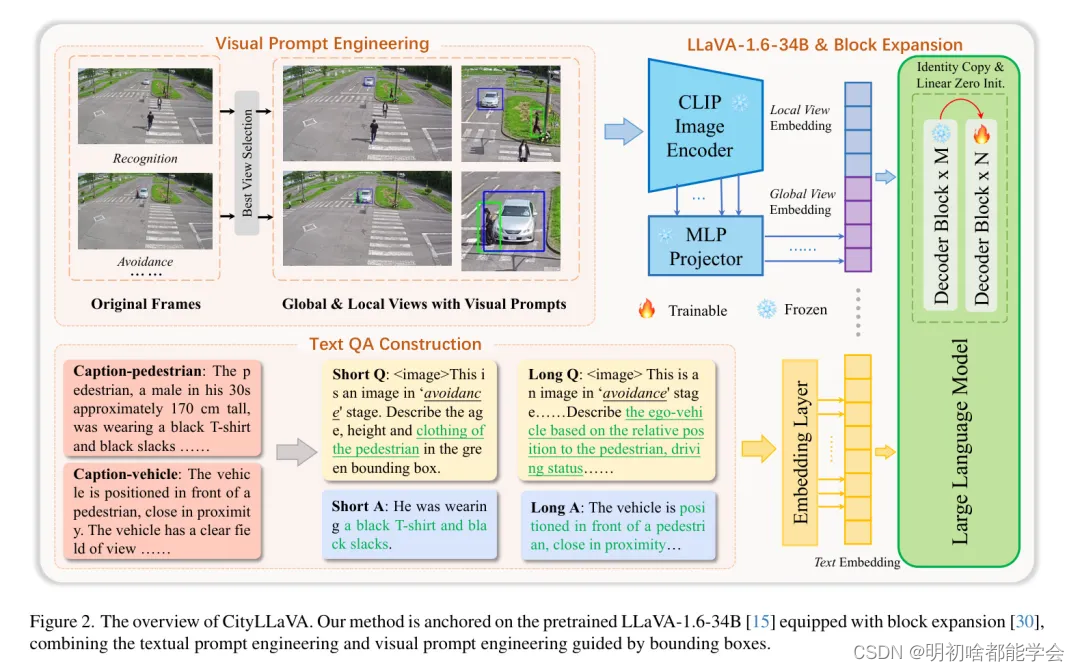
在本节中,作者详细阐述了数据过滤以及为监督微调(SFT)构建视觉-语言指令调优数据集的细节。对于微调,用于训练的项
H
H
H可以表示为一个元组:
[H = (X_v, X_q, X_t)]
其中
X
v
,
X
q
,
X
t
X_v, X_q, X_t
Xv,Xq,Xt分别表示视觉输入、文本指令和文本响应。后续章节将探讨它们的最佳构建方式。
Bounding-box Guided View Selection
WTS数据集包括两部分:a. WTS数据,这是一个多视角数据集,包含不确定数量的车辆视角和鸟瞰视角;b. 从BDD100K数据中筛选出的以行人为主的视频,仅包含车辆视角。考虑到WTS数据中某些视角下的相关车辆和行人可能不够清晰或体积较小,直接在多视角数据上微调视觉语言模型(VLMs)存在挑战。为了解决这个问题,作者引入了边界框引导的视角选择。最初,作者从WTS数据中过滤掉不符合官方推荐视角的鸟瞰视图。然后,数据被分割成元组
S
=
{
V
,
T
,
B
}
S=\{V, T, B\}
S={V,T,B},分别代表视频片段、描述和边界框,遵循官方制定的分段。对于训练数据集中的每个元组
S
S
S,作者根据边界框
B
B
B计算平均车辆面积
A
v
A_v
Av和平均行人面积
A
p
A_p
Ap。作者认为如果没有边界框,则面积为零。然后,作者应用以下标准来获取过滤后的元组数据
s
s
s,确保只有相关的视图被选用于模型训练:
其中
t
h
r
p
thr_p
thrp和
t
h
r
v
thr_v
thrv分别表示行人和车辆的面积阈值。
对于测试数据集,作者最初按场景将元组 S S S分组。在某个场景内,作者选择不仅在整个五个阶段都包含边界框,而且展示最大平均行人面积 A p A_p Ap的视频作为测试的最佳视角。这个过程确保选择最适合推理的视角。
Visual Prompt Engineering
在本节中,从两个方面详细阐述了视觉提示工程(VPE)。
视觉提示。视觉提示为提示工程引入了一种创新的方法。视觉语言模型(VLM)本质上是多模态的,提供了同时操纵视觉和文本模态的机会。像素空间中的一个简单的红色圆圈可以指导CLIP关注到感兴趣的区域,从而提高零样本指代表达式理解[25]的性能。ViP-LLava [3]还利用红色边界框或点箭头来增强VLM的区域级感知。在本文中,作者引入边界框矩形作为视觉提示,以定位感兴趣的行人和车辆,从而实现细粒度的视觉语言对齐和局部区域的信息提取。
作者通过在相应的视频帧上绘制放大的边界框来实现视觉提示。给定一个帧
I
I
I和其行人边界框
B
p
B_p
Bp,车辆边界框
B
v
B_v
Bv,作者用绿色矩形表示行人,蓝色矩形表示车辆。关键是要放大边界框,以确保它包含围绕行人与车辆感兴趣区域的整个区域,因为原始边界框可能只覆盖部分区域。给定一个边界框
B
B
B,放大后的可以表示为以下形式:
[
=
Scale
(
B
,
c
)
=
(
x
−
w
⋅
(
c
−
1
)
2
,
y
−
h
⋅
(
c
−
1
)
2
,
w
⋅
c
,
h
⋅
c
)
]
[= \text{Scale}(B, c) = (x - \frac{w \cdot (c - 1)}{2}, y - \frac{h \cdot (c - 1)}{2}, w \cdot c, h \cdot c)]
[=Scale(B,c)=(x−2w⋅(c−1),y−2h⋅(c−1),w⋅c,h⋅c)]
其中
c
c
c表示缩放系数,
x
x
x和
y
y
y分别表示左上角的坐标,
w
w
w和
h
h
h分别表示框的宽度和高度。默认
c
c
c设置为1.2。基于放大的边界框
B
p
=
(
x
p
,
y
p
,
w
p
,
h
p
)
B_p = (x_p, y_p, w_p, h_p)
Bp=(xp,yp,wp,hp)和
B
v
=
(
x
v
,
y
v
,
w
v
,
h
v
)
B_v = (x_v, y_v, w_v, h_v)
Bv=(xv,yv,wv,hv),作者可以生成带有视觉提示的增强帧
I
′
I'
I′,然后将其输入到VLM中。
全局-局部联合视角。为了增强对行人和车辆全局背景及特定兴趣点的理解,作者将增强后的帧
I
′
I'
I′及其由边界框引导的裁剪视图
I
m
I_m
Im进行拼接,作为联合视觉输入。先前的研究[12,15]表明,使用多裁剪视图与全视图图像的拼接作为视觉输入可以提升细粒度多模态理解的表现,并减少输出中的幻觉。然而,这种方式带来了更大的计算负担。此外,此过程中引入的视觉冗余可能对某些任务产生较少甚至没有改进。因此,作者将[15]中的多裁剪视图替换为由边界框引导的局部裁剪视图。这种替换使模型的注意力集中在关键区域,同时减少了不必要的视觉信息。给定边界框
B
p
B_p
Bp和
B
v
B_v
Bv,裁剪视图边界可以表示为:
[V_m = \text{Crop}(B_p, B_v) = (x_{\text{min}}, y_{\text{min}}, x_{\text{max}}, y_{\text{max}})]
[x_{\text{min}} = \min(x_p, x_v), \quad y_{\text{min}} = \min(y_p, y_v),]
[x_{\text{max}} = \max(x_p + w_p, x_v + w_v), \quad y_{\text{max}} = \max(y_p + h_p, y_v + h_v),]
其中
V
m
V_m
Vm表示裁剪视图的边界,可以理解为两个边界框的最小外接矩形。作者可以使用方程3中定义的
Scale
(
,
)
\text{Scale}(,)
Scale(,)来放大边界以获得更多的上下文属性:
[V_m = \text{Scale}(V_m, c^*)]
这里
c
∗
c^*
c∗设为1.5。最终的裁剪视图
I
m
I_m
Im可以表示为:
I
m
=
I
[
:
,
y
min
:
y
min
+
h
m
,
x
min
:
x
min
+
w
m
]
I_m = I[:, y_{\text{min}} : y_{\text{min}} + h_m, x_{\text{min}} : x_{\text{min}} + w_m]
Im=I[:,ymin:ymin+hm,xmin:xmin+wm]
其中
i
m
im
im,
y
m
ym
ym分别代表
V
m
V_m
Vm的左上角坐标,而
w
m
w_m
wm,
h
m
h_m
hm分别表示相应的宽度和高度。在训练和推理过程中,将
I
m
I_m
Im和
I
I
I都输入到视觉编码器中。
VPE的有效性。作者进行了一个简单的实验来验证作者视觉提示工程的有效性。作者使用文本提示"请描述行人的服装,在边界框[
x
x
x,
y
y
y,
h
h
h,
w
w
w]内"来Query原始的LLaVA-1.6-34B [15]在原始帧和增强或裁剪的帧下的输出,并比较不同设置下的输出准确性。如图3所示,作者提出的范式增强了特定物体和感兴趣区域的细粒度感知。顶部的子图说明所绘制的绿色矩形指导模型关注到可能与ego-vehicle发生碰撞的感兴趣行人。这些简单的视觉提示防止模型受到无关物体的干扰,建立了细粒度的视觉语言对齐。底部的子图展示了在由边界框引导的裁剪视图中推理时细节识别的改进。进行的实验表明,使用作者提出的视觉提示工程处理的数据集显示出增强的对齐性,这对模型的微调是有益的。

3.2.3 Textual Prompt Engineering
一个构建良好的提示对于视觉问题回答和视觉字幕生成至关重要,尤其是在需要详细描述时。通过提示工程,作者旨在找到一个不仅准确而且全面地概括描述内容的问题,而不仅仅是将“请提供视频中行人/车辆的详细描述”输入到模型中。
通过对描述进行维度分析,作者提炼出关键点,如身高、衣着、视线、相对位置、动作和环境。作者使用GPT-4v[20]来评估生成响应与真实情况的对应程度,识别不匹配和需要改进的区域。结果是精心设计的提示集,旨在引导模型生成高质量、与上下文相关的答案。
行人描述提示。这张图片展示了绿色框中行人与蓝色框中车辆的关系。根据年龄、身高、衣着、视线、相对于车辆的位置、运动状态、天气条件和道路环境,描述绿色框中的行人或离车辆最近的行人。
车辆描述提示。这张图片展示了蓝色框中车辆与绿色框中行人的关系。根据相对于行人的位置、驾驶状态、天气条件和道路环境,描述蓝色框中的车辆或离行人最近的车辆,并描述行人的年龄、身高和衣着。
对于车辆视角,作者使用“自车”代替“蓝色框中的车辆”,以增强提示的上下文相关性和特定性。
对于以下选项中的每个描述性文本,通过提供文本索引后跟字母a、b、c、d或e的格式来输出。每个选择应在新的一行上。
最后,作者构建了一个包含长QA和短QA对的图像-文本数据集。请注意,文本部分有两种不同的组成:(1)多轮QA,包括在第3.2.3节中定义的长QA和短QA对的多轮对话。(2)单轮QA,仅包括一个QA对的单轮对话。作者在第4.4节中比较了这两种方式的影响。
Model Architecture
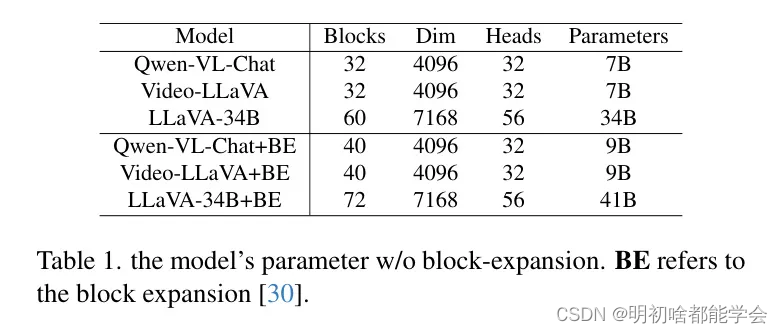
Qwen-VL-Chat [2]和Video-LLaVA [11]最初被选为这个视频理解任务的候选基准模型,因为它们的表现相对较好。这两个模型在数据处理过程中从每个阶段视频剪辑中均匀提取8帧作为输入。关于微调方法,受到LLaMA-Pro [30]的启发,作者使用块扩展而不是LoRA来微调基准模型。在块扩展方法中,一些零线性初始化的解码器块层(从VLM的LLM模块中身份复制)被交错插入到LLM主干中。在微调期间,只解冻这些重复块层的参数。这种方法展示了增强的学习能力,导致了性能指标的改进。LoRA与块扩展之间的详细比较可以在表5中找到。结果显示,Qwen-VL-Chat显著优于Video-LLaVA。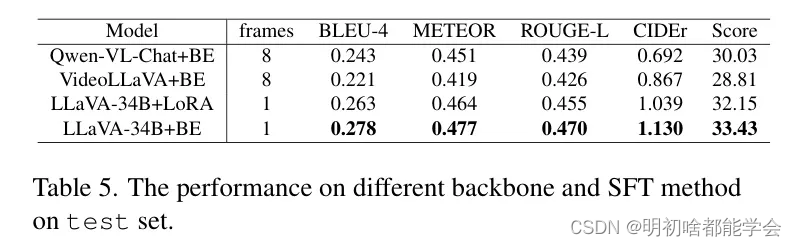
然而,观察到许多阶段视频剪辑包含的帧数少于8帧,有时甚至只有一帧。 这意味着作者可以
使用图像模型来处理这个任务。考虑到每个视频剪辑V的第一帧是手动标注的, 粗标注量
超过了余跟踪数据的质量,作者部署了最先进的VLM LLaVA-1.6-34B [15]。作者只使每
个视频剪辑V的第一帧作为输入, 并应用块扩展进行有效的微调。表1显示了应用块扩展的模
型参数数量。作者发现尽管LLaVA-1.6-34B使用单帧输入可能会失一些时间信息, 但更大
的参数尺寸有助于更精细地理解图像。
此外,作者尝试通过实施基于人类反馈的强化学习(RLHF)来提高模型的性能。以前的工作[26]显示,LLaVA可以通过减少幻觉来从RLHF中受益。然而,原始的RLHF基于PPO算法[24],这消耗了大量计算资源。由于Direct Preference Optimization(DPO)算法[23]在计算上更有效率,作者选择它作为替代。遵循以前的工作[33, 34],作者的目标是使用DPO减轻幻觉并提高性能。作者利用阶段描述的 GT 作为正面样本,以及SFT模型的输出作为负面样本,然后将它们输入到DPO中。不幸的是,DPO导致性能指标下降。在分析之后,作者发现性能下降的两个可能原因。首先,这个任务中的描述相对于其他数据集中的标题或回复来说相对较长,这使得DPO更难以对齐。其次,数据集中应用了各种标注模板,这可能会让DPO混淆,以至于模型不知道需要对齐哪个模板。因此,作者从这次挑战中移除了DPO训练。
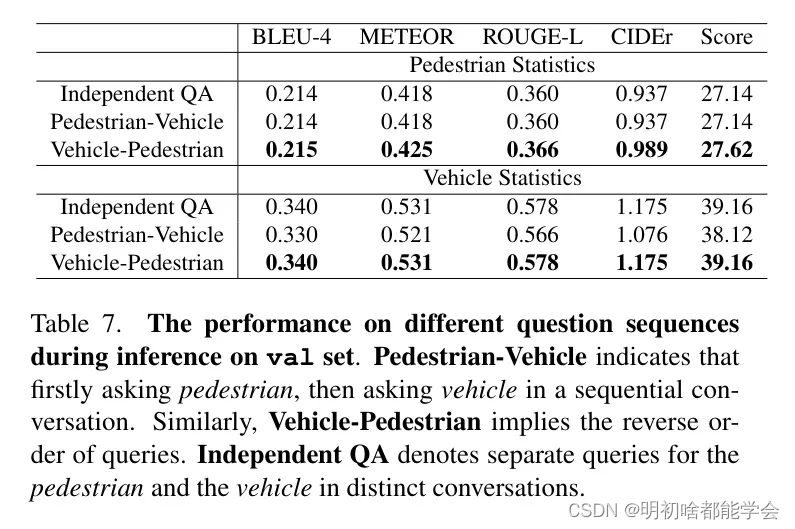
Harnessing Sequential Questioning
作者研究了仅在对单轮问答实例进行训练的模型上,顺序提问对模型性能的影响。尽管训练数据集中没有多轮问答对(即训练集中的项目没有同时包含在第3.2.3节中定义的“行人”提示和“车辆”提示的顺序问题-答案对),但作者的发现显示,当模型在推理过程中按特定顺序接受一系列问题的提问时,其回应的准确性有所提高。
作者发现一个普遍现象,即“车辆”得分平均高于“行人”得分。这种比较表明,模型针对“车辆”提示的输出在上下文属性、定位和注意力方面包含更精确的描述。因此,一种合理的做法是将“车辆”描述插入到“行人”提示中,提供增强的上下文以获得更精确的“行人”描述。上述策略可以概括为“首先询问‘车辆’,然后询问‘行人’”。
仅通过利用顺序提问,模型就能生成具有更高评估指标的输出,这可以被视为预测增强。关于问题顺序的详细实验结果分析见表7。请注意,只有特定的问题顺序才能提高模型性能。## 4 实验
在本节中,作者首先解释数据集和指标。随后,作者介绍作者的实现细节。作者还提供了关于消融研究的成果。
Dataset
本文使用了WTS数据集进行模型训练和评估。WTS是交通领域内最大的空间-时间细粒度视频理解数据集,旨在描述包括事故在内的多种模拟交通事件中车辆和行人的详细行为。WTS包含了来自130多种不同交通场景的1,200多个视频事件,结合了车与基础设施协同环境中的自车视角和固定高空摄像机视角。它为每个事件提供了详细的文本描述,覆盖了观察到的行为和上下文。此外,为了更广泛的研究应用,BDD100K中4,861个公开可访问的以行人为主的交通视频也提供了详细的文本标注。
由于WTS数据集中的验证集数量众多以及计算资源使用量大,作者在原始验证集的一个选定子集上进行了消融实验,该子集包含82个样本,共计301项。
Evaluation Metrics
作者对CityLLaVA使用BLEU-4、METEOR、ROUGE-L和CIDEr作为评估指标,将预测的描述与真实情况进行比较。更具体地说,这4个指标被用来计算最终的得分: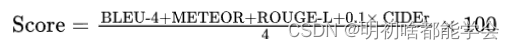
Implementation Details
训练。作者使用预训练的LLaVA-1.6-34B作为作者的主干网络。整个可复现的训练过程仅由SFT阶段组成。在SFT阶段,作者专注于训练辅助块,同时冻结其他部分。表3展示了作者用于微调CityLLaVA模型的超参数。对于CityLLaVA,整个SFT阶段使用NVIDIA 8×A100-80G GPU耗时7.8小时。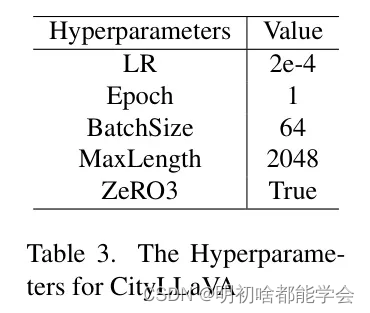
推理。作者使用第3.2.3节定义的提示来 Query 模型以获取行人和车辆的标题。在推理过程中,作者对LLaVA-1.6-34B实施了INT4量化。模型量化可以在不明显性能退化的情况下显著减少GPU内存使用。表4总结了推理过程中GPU资源使用的统计信息。所有评估都是在NVIDIA 8×A100-80G GPU上执行的。评估测试集所需的时间大约为1.7小时。作者的方法在2024 AI City Challenge Track 2中排名第一,得分为33.4308,如表2所示。