引言
今天带来论文Longformer: The Long-Document Transformer的笔记。
基于Transformer的模型由于其自注意力操作而无法处理长序列,该操作随着序列长度呈二次扩展。为了解决这一限制,本篇工作提出了Longformer,其注意力机制随着序列长度呈线性扩展。同时提出了三种稀疏注意力降低计算复杂度,分别是滑动窗口注意力、扩张滑动窗口注意力和全局注意力。
总体介绍
Longformer是一种改进的Transformer架构,具有一个自注意力操作,其随着序列长度线性扩展,使其适用于处理长文档。其注意力机制结合了窗口化的局部上下文自注意力和端到端任务驱动的全局注意力,编码了关于任务的归纳偏见。
相关工作
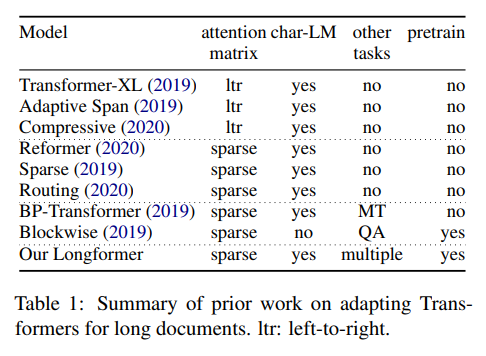
长文档Transformer 表1总结了最近关于长文档的先前工作。已经探索了两种自注意力方法。第一种是从左到右(ltr)的方法,逐块处理文档并从左到右移动。虽然这种模型在自回归语言建模中取得了成功,但对于从双向上下文中受益的任务来说并不适用于迁移学习方法。
作者的工作属于另一种一般方法,即定义某种形式的稀疏注意力模式,并避免计算完整的二次注意力矩阵乘法。与作者注意力模式最相似的模型是 Sparse-Transformer,它使用由BlockSparse提供的8x8大小块的一种扩张滑动窗口形式)。
一些模型尝试了除自回归语言建模之外的任务,这是一大进步,因为可以认为将语言建模作为主要评估方法导致了具有有限适用性的模型的发展。BPTransformer在机器翻译(MT)上进行评估,但没有探索预训练微调设置。分块注意力对其模型进行了预训练,并在问答上进行了评估。然而,由于评估不包括语言建模,并且QA数据集的文档相对较短,因此这种模型在长文档任务上的有效性尚未被探究。
长文档的任务特定模型 已经开发了许多针对512限制的预训练转换器模型的任务特定方法。最简单的方法只是截断文档,通常用于分类。另一种方法将文档划分为长度为512的块(可以重叠),分别处理每个块,然后将激活与特定任务模型结合起来。一种流行的适用于多跳和开放域QA任务的第三种方法使用两阶段模型,第一阶段检索相关文档,然后将其传递到第二阶段进行答案提取。所有这些方法都存在由于截断或来自两阶段方法的级联错误而导致的信息丢失。相比之下,Longformer可以处理长序列而无需截断或分块,这使我们能够采用一种更简单的方法,将可用上下文连接起来并在一次传递中处理它。
Longformer
原始Transformer模型具有 O ( n 2 ) O(n^2) O(n2)的时间和内存复杂度的自注意力组件,其中n是输入序列的长度。为了解决这一挑战,作者根据指定彼此关注的输入位置对的"注意力模式"对完整的自注意力矩阵进行了稀疏化。与完整的自注意力不同,作者提出的注意力模式与输入序列呈线性关系,使其适用于更长的序列。
注意力模式
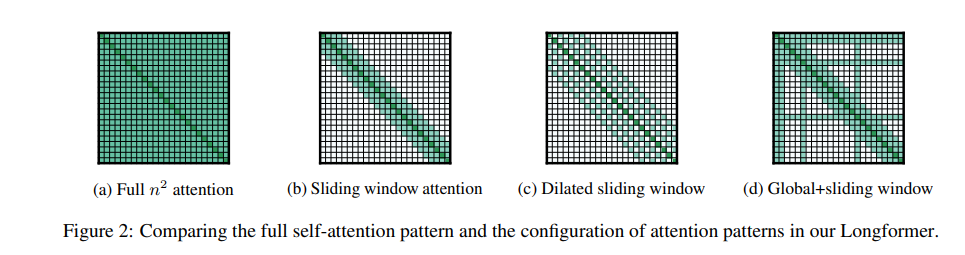
滑动窗口(Sliding Window) 基于局部上下文的重要性,注意力模式采用围绕每个标记的固定大小窗口的注意力。使用多个堆叠层的这种窗口注意力会产生一个大的感受野,顶层可以访问所有输入位置,并具有构建跨整个输入的信息的表示的能力,类似于CNN。给定固定的窗口大小 w w w,每个标记都会关注其两侧 1 2 w \frac{1}{2}w 21w个标记(图2b)。这种模式的计算复杂性为 O ( n × w ) O(n×w) O(n×w),与输入序列长度 n n n呈线性关系。
在具有 l l l层的Transformer中,顶层的感受野大小为 l × w l \times w l×w(假设对于所有层 w w w是固定的)。根据应用程序的不同,可能为每个层使用不同的 w w w值更好,以在效率和模型表示能力之间取得平衡。
扩张滑动窗口 为了进一步增加感受野而不增加计算量,滑动窗口可以"扩张"。这类似于扩张卷积神经网络,其中窗口具有大小为扩张值 d d d的间隔。假设对于所有层都是固定的 d d d和 w w w,那么感受野大小为 l × d × w l×d×w l×d×w,即使对于较小的 d d d值,也可以触及成千上万个标记。在多头注意力中,每个注意力头计算不同的注意力分数。每个头部具有不同的扩张配置的设置可以通过允许一些没有扩张的头部关注局部上下文,而其他具有扩张的头部专注于更长的上下文,从而提高性能。
全局注意力 在最先进的基于BERT风格的自然语言任务模型中,最佳的输入表示因任务而异,对于语言建模也有所不同。对于掩码语言建模,模型使用局部上下文来预测被掩码的单词,而对于分类,模型将整个序列的表示聚合到一个特殊标记中。对于问答(QA),问题和文档被连接在一起,使模型可以通过自注意力比较问题和文档。
滑动窗口和扩张注意力不足以学习特定任务的表示。因此,在少数预选的输入位置上添加"全局注意力"。重要的是,使这种注意力操作是对称的:即具有全局注意力的标记会关注整个序列中的所有标记,而序列中的所有标记也会关注它。图2d显示了一个示例,其中滑动窗口注意力在自定义位置的少数标记上具有全局注意力。例如,在分类任务中,全局注意力用于[CLS]标记,而在QA中,全局注意力则放在所有问题标记上。由于这些标记的数量相对较小且独立于
n
n
n,因此结合局部和全局注意力的复杂度仍然为
O
(
n
)
O(n)
O(n)。虽然指定全局注意力是与任务相关的,但这是一种向模型的注意力添加归纳偏差的简单方式,比起使用复杂架构将信息跨越较小的输入块组合的现有任务特定方法要简单得多。
线性投影用于全局注意力 回顾一下,给定线性投影
Q
Q
Q、
K
K
K、
V
V
V,Transformer模型计算注意力分数如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
(1)
\text{Attention}(Q,K,V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}}\right) V \tag 1
Attention(Q,K,V)=softmax(dkQKT)V(1)
使用两组投影,
Q
s
Q_s
Qs、
K
s
K_s
Ks、
V
s
V_s
Vs,来计算滑动窗口注意力的注意力分数,使用
Q
g
Q_g
Qg、
K
g
K_g
Kg、
V
g
V_g
Vg来计算全局注意力的注意力分数。额外的投影提供了对不同类型的注意力进行建模的灵活性。
Q
g
Q_g
Qg、
K
g
K_g
Kg、
V
g
V_g
Vg都初始化为与
Q
s
Q_s
Qs、
K
s
K_s
Ks、
V
s
V_s
Vs匹配的值。
实现
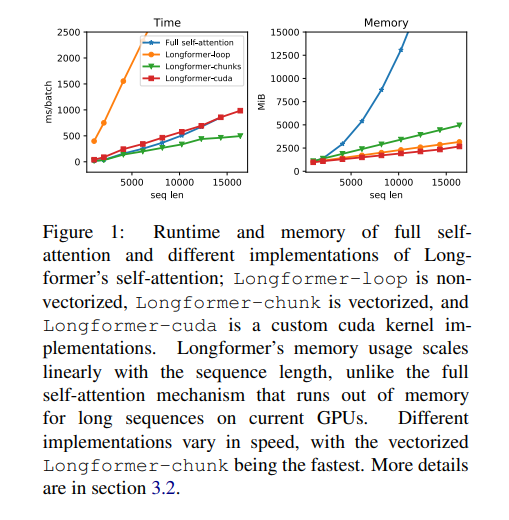
在常规的Transformer模型中,注意力分数的计算如公式1所示。昂贵的操作是矩阵乘法 Q K T QK^T QKT,因为 Q Q Q和 K K K都有 n n n(序列长度)个投影。对于Longformer,扩张滑动窗口注意力仅计算 Q K T QK^T QKT的一定数量的对角线。如图1所示,这使得内存使用量线性增加,而与完全自注意力相比,后者是二次增加。然而,实现它需要一种带状矩阵乘法的形式,这在现有的深度学习库(如PyTorch/Tensorflow)中不受支持。
图1比较了三种不同实现方式的性能:loop是一个内存高效的PyTorch实现,支持扩张但速度非常慢,仅用于测试;chunks仅支持非扩张情况,并用于预训练/微调设置;cuda是作者完全功能齐全、高度优化的自定义CUDA内核,使用了TVM实现,并用于语言建模实验。
实验
略
结论
作者提出了Longformer,这是一个基于Transformer的模型,可扩展处理长文档。Longformer采用了一种注意力模式,结合了局部和全局信息,同时随着序列长度线性扩展。
实现细节
实现Longformer的扩张滑动窗口注意力需要一种带状矩阵乘法(矩阵乘法,其中输出除了某些对角线外全部为零)的形式,这种形式在现有的深度学习库如PyTorch/Tensorflow中没有直接支持。图1比较了三种不同实现方式的运行时和内存情况。
Longformer-loop是一个朴素的实现,它在循环中分别计算每个对角线。它在内存效率上很高,因为它只计算非零值,但速度非常慢,因此无法使用。仅用于测试,因为它易于实现,但不用于运行实验。
Longformer-chunks仅支持非扩张情况。它将Q和K分块为大小为w且重叠大小为 1 2 w \frac{1}{2}w 21w的块,将这些块相乘,然后屏蔽掉对角线。这非常高效,因为它使用了PyTorch的单个矩阵乘法操作,但它消耗的内存量是完全优化的实现应该消耗的两倍,因为它计算了一些零值。由于计算效率高,这种实现最适用于预训练/微调情况。
Longformer-cuda是作者使用TVM实现的自定义CUDA内核。它是注意力的完全功能实现,内存效率最高,并且与高度优化的全自注意力一样快。主要将此实现用于自回归语言建模实验,因为它具有内存效率(允许处理最长序列)和支持扩张(字符级语言建模实验所需)。
Tensor Virtual Machine(TVM) TVM是作者使用的一个深度学习编译器堆栈,它将函数的高级描述编译成优化的特定设备的代码。使用TVM,使用高级Python构造带状矩阵乘法,然后TVM生成相应的CUDA代码并将其编译为适用于GPU的代码。
总结
⭐ 作者提出随着序列长度线性增长的稀疏注意力机制,并提供了自定义CUDA内核实现。