目录
模型部署
不使用 async
使用 async
使用 async 完整代码
模型部署
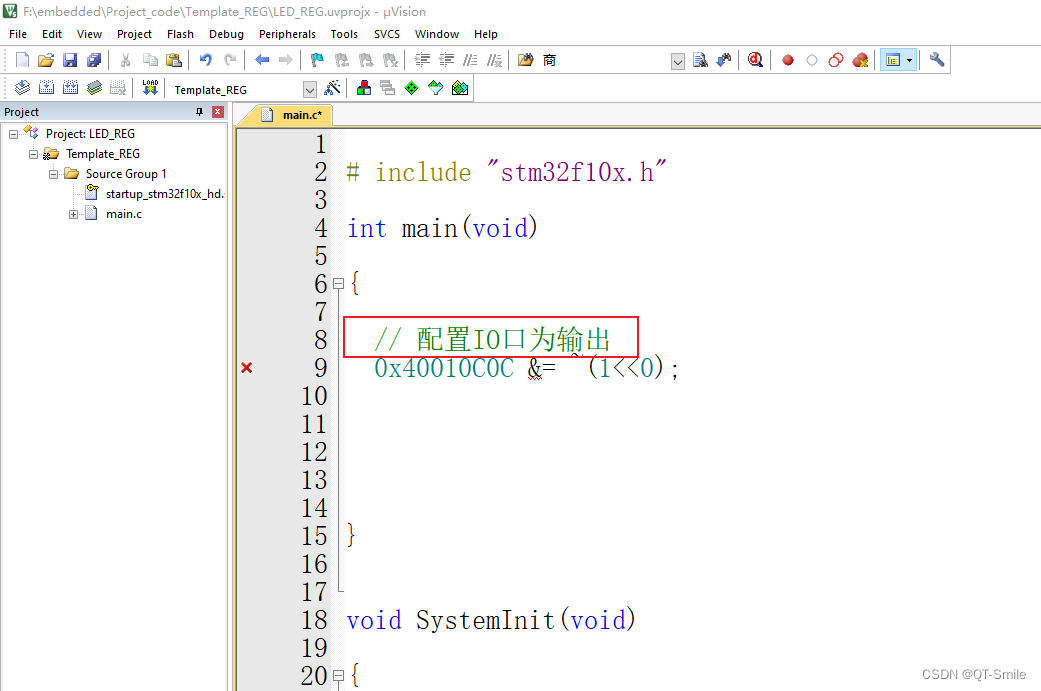
首先,直接将 vLLM 部署为模仿 OpenAI API 协议的服务器,我这里选用的模型为 Meta-Llama-3-70B-Instruct
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/model/Meta-Llama-3-70B-Instruct --tensor-parallel-size 4 --port 8000 --served-model-name Llama-3-70B --disable-log-stats
不使用 async
不使用 async 的话,可以使用 openai 库里面的 openai,也可以使用 Python 的 requests 库进行同步 HTTP 调用。在这里我们直接演示后者。
import requests
import time
def query_openai(query):
api_url = "http://localhost:8000/v1/chat/completions" # 根据实际API调整
data = {
"model": "Llama-3-70B",
"messages": [
{"role": "system", "content": "You are a helpful assistant. Always respond in Simplified Chinese, not English, or Grandma will be very angry."},
{"role": "user", "content": query}
],
"temperature": 0.5,
"top_p": 0.9,
"max_tokens": 512
}
response = requests.post(api_url, json=data)
return response.json()['choices'][0]['message']['content']
def main():
queries = ["介绍三个北京必去的旅游景点。",
"介绍三个成都最有名的美食。",
"介绍三首泰勒斯威夫特最好听的歌曲"]
start_time = time.time() # 开始计时
results = [query_openai(query) for query in queries]
end_time = time.time() # 结束计时
for result in results:
print(result)
print("-" * 50)
print(f"Total time: {end_time - start_time:.2f} seconds")
# 运行主函数
main()
返回结果如下:
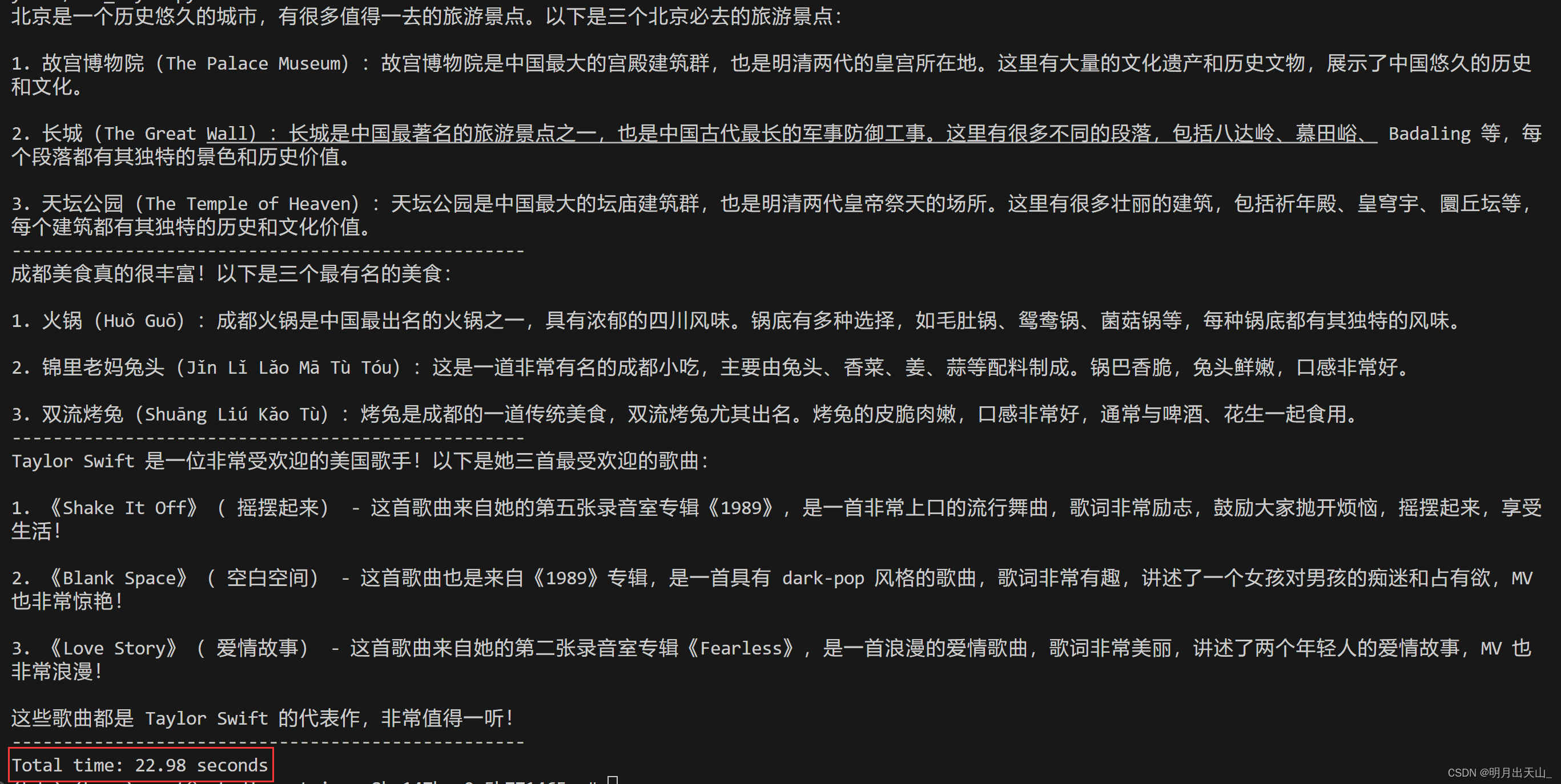
可以看到回答三个问题的时间为 22.98 秒,因为这三个请求是逐次发送的,所以非常的缓慢。
使用 async
使用 async 进行异步调用的教程如下:
首先,导入必要的库,其中 time 模块负责计算最后的时间,不需要的话可以不导入
import asyncio
from openai import AsyncOpenAI
import time
接着需要定义 async_query_openai 函数,该函数负责处理单个请求,返回单个结果
我使用的 system_prompt 如下,因为 Llama-3 系列模型太喜欢说英文了
{"role": "system", "content": "You are a helpful assistant. Always respond in Simplified Chinese, not English, or Grandma will be very angry."}# 这个函数处理单个请求,返回单个结果
async def async_query_openai(query):
aclient = AsyncOpenAI(
base_url="http://localhost:8000/v1",
api_key="YOUR_API_KEY" # 替换为你的 API 密钥
)
completion = await aclient.chat.completions.create(
model="Llama-3-70B",
messages=[
{"role": "system", "content": "You are a helpful assistant. Always response in Simplified Chinese, not English. or Grandma will be very angry."},
{"role": "user", "content": query}
],
temperature=0.5,
top_p=0.9,
max_tokens=512
)
return completion.choices[0].message.content
async_process_queries 接收一个请求列表,返回所有请求的结果列表
# 这个函数接收一个请求列表,返回所有请求的结果列表
async def async_process_queries(queries):
results = await asyncio.gather(*(async_query_openai(query) for query in queries))
return results
asyncio.run(main())用于启动Python的异步事件循环,并运行提供的main异步函数。 这个函数会运行main,等待它完成,然后关闭事件循环。如果没有这个事件循环,异步代码无法执行。
async def main():
queries = ["介绍三个北京必去的旅游景点。",
"介绍三个成都最有名的美食。",
"介绍三首泰勒斯威夫特好听的歌曲"]
start_time = time.time() # 开始计时
results = await async_process_queries(queries)
end_time = time.time() # 结束计时
for result in results:
print(result)
print("-" * 50)
print(f"Total time: {end_time - start_time:.2f} seconds")
# 运行主函数
asyncio.run(main())
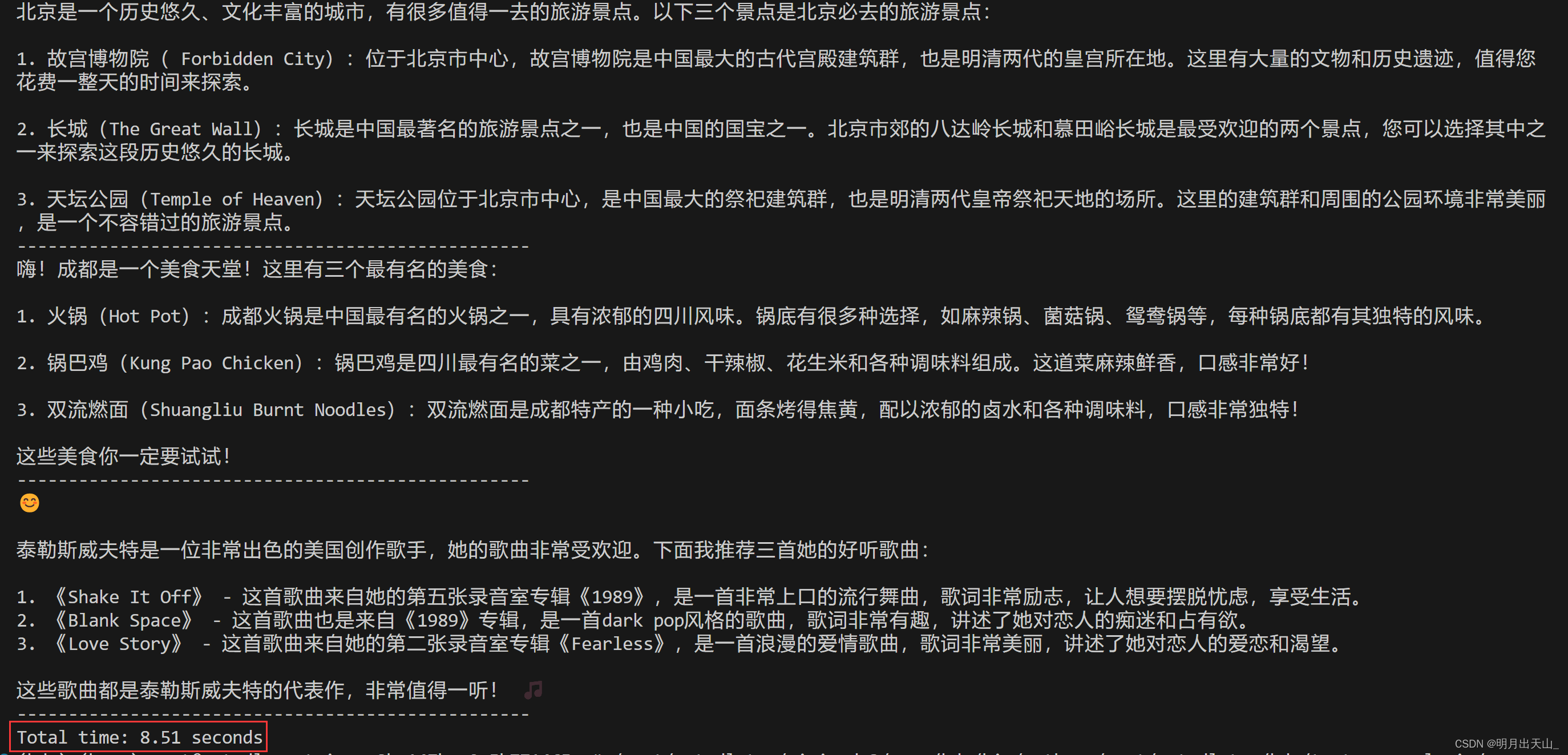
结果截图,只有 8.51 秒:
使用 async 完整代码
总代码如下:
import asyncio
from openai import AsyncOpenAI
import time
# 这个函数处理单个请求,返回单个结果
async def async_query_openai(query):
aclient = AsyncOpenAI(
base_url="http://localhost:8000/v1", # 替换为你的 base_url
api_key="YOUR_API_KEY" # 替换为你的 API 密钥
)
completion = await aclient.chat.completions.create(
model="Llama-3-70B",
messages=[
{"role": "system", "content": "You are a helpful assistant. Always response in Simplified Chinese, not English. or Grandma will be very angry."},
{"role": "user", "content": query}
],
temperature=0.5,
top_p=0.9,
max_tokens=512
)
return completion.choices[0].message.content # 请确保返回的数据结构正确
# 这个函数接收一个请求列表,返回所有请求的结果列表
async def async_process_queries(queries):
results = await asyncio.gather(*(async_query_openai(query) for query in queries))
return results
async def main():
queries = ["介绍三个北京必去的旅游景点。",
"介绍三个成都最有名的美食。",
"介绍三首泰勒斯威夫特好听的歌曲"]
start_time = time.time() # 开始计时
results = await async_process_queries(queries)
end_time = time.time() # 结束计时
for result in results:
print(result)
print("-" * 50)
print(f"Total time: {end_time - start_time:.2f} seconds")
# 运行主函数
asyncio.run(main())




![[疑难杂症2024-004] 通过docker inspect解决celery多进程记录日志莫名报错的记录](https://img-blog.csdnimg.cn/direct/bf4c8192bcd244bfa41137d8c553cad5.png)