前言
测试gpu前需要安装Anaconda、pytorch、tmux、nvitop。
单gpu
代码
import numpy as np
from tqdm import tqdm
'''
@Project :gpu-test
@File :gpu_stress.py
@Author :xxx
@Date :2024/4/20 16:13
'''
import argparse
import time
import torch
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='One gpu test')
parser.add_argument('--size', type=int, required=False, default=10, help='矩阵的大小')
parser.add_argument('--gpu', type=int, required=False, default=0, help='gpu的编号')
parser.add_argument('--minu', type=int, required=False, default=1, help='运行时长:分')
parser.add_argument('--verbose', type=int, required=False, default=10, help='进度条:运行时长的10%更新进度条')
args = parser.parse_args()
# 设置要运行的时长(分钟)
duration_mins = args.minu
verbose = args.verbose
torch.cuda.set_device(args.gpu)
size = args.size
# 测试 GPU 计算耗时
A = torch.ones(size, size).to('cuda')
B = torch.ones(size, size).to('cuda')
start_time = time.time()
current_time = start_time
#创建一个进度条
ratio = verbose/100 #计算当前进度
with tqdm(total=100) as pbar:
pbar.set_description("Processing")
while (current_time - start_time) / 60 < duration_mins:
C = torch.inner(A, B)
current_time = time.time()
if np.round(((current_time - start_time)/60)/duration_mins,1) == np.round(ratio,1):
pbar.update(verbose)#更新进度条
ratio += verbose/100
total_duration_seconds = current_time - start_time
total_duration_hours = total_duration_seconds / 3600
print(f"GPU RUN TIME: {total_duration_hours:.2f} 小时")
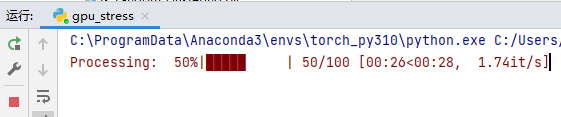
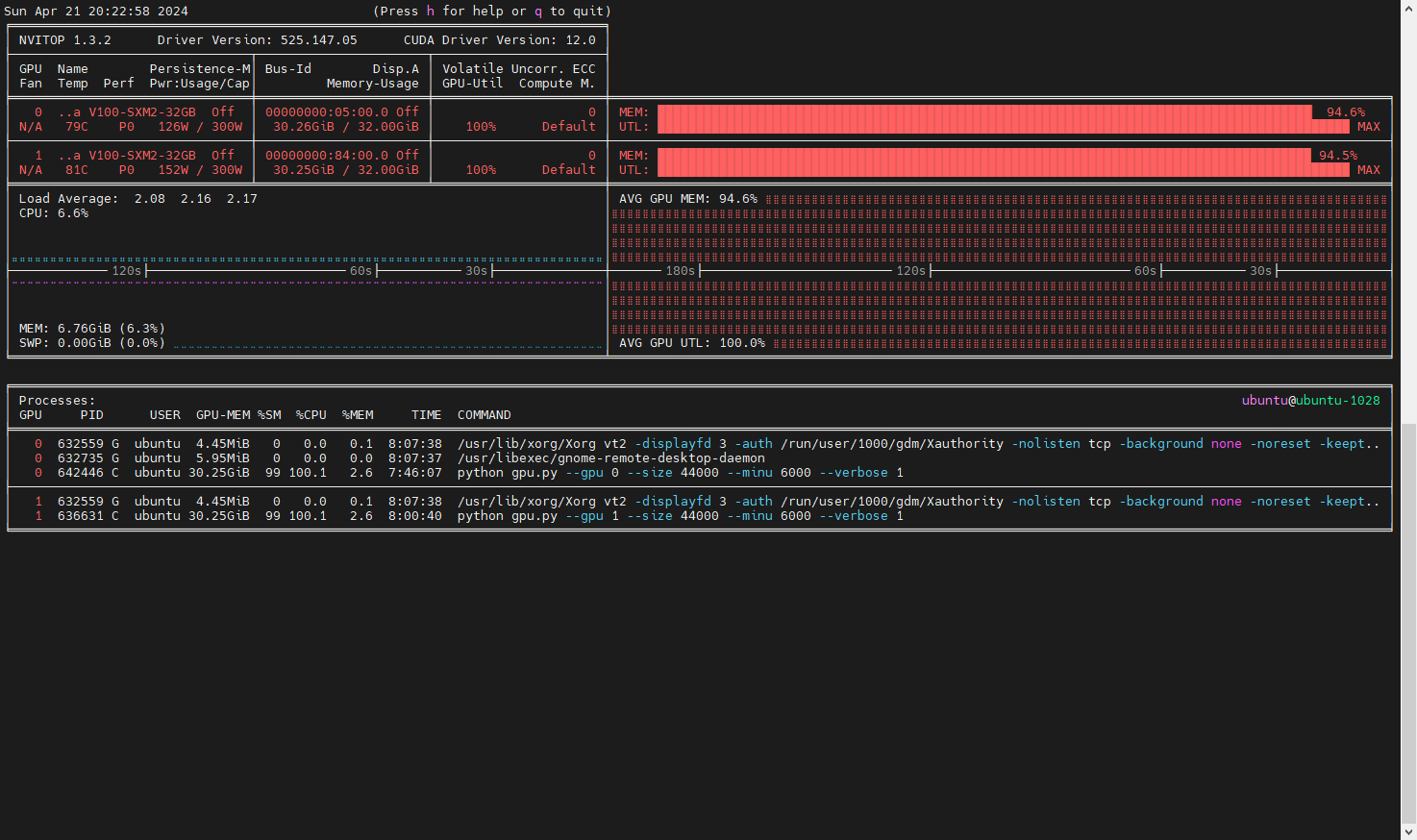
运行命令
python gpu.py --gpu 0 --size 44000 --minu 6000
python gpu.py --gpu 1 --size 44000 --minu 6000
参数说明:
- gpu:显卡编号
- size:矩阵大小,如果双卡32G显存,可以设置参数为44000,其他情况慢慢试
- minu:运行时长,单位-分钟
多gpu并行
代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
@Project :gpu-test
@File :gpus_stress.py
@Author :xxx
@Date :2024/4/20 16:13
'''
import argparse
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from tqdm import tqdm
def train_model(duration_mins, num_gpus,verbose):
duration_secs = duration_mins * 60
size = args.size
data = torch.ones(size, size).to('cuda')
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(size, size)
def forward(self, x):
return self.fc1(x)
model = MyModel().to('cuda')
model = nn.DataParallel(model, device_ids=list(range(num_gpus)))
optimizer = optim.SGD(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
start_time = time.time()
current_time = start_time
# 创建一个进度条
ratio = verbose / 100 # 计算当前进度
with tqdm(total=100) as pbar:
pbar.set_description("Processing")
while (current_time - start_time) < duration_secs:
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, data)
loss.backward()
optimizer.step()
current_time = time.time()
if np.round(((current_time - start_time) / 60) / duration_mins, 1) == np.round(ratio, 1):
pbar.update(verbose) # 更新进度条
ratio += verbose / 100
total_duration_hours = (current_time - start_time) / 3600
print(f"GPU RUN TIME: {total_duration_hours:.2f} hours")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Multi-GPU Training')
parser.add_argument('--minu', type=int, default=1, help='Duration in minutes')
parser.add_argument('--gpus', type=int, default=1, help='Number of GPUs to use')
parser.add_argument('--size', type=int, required=False, default=1, help='size')
parser.add_argument('--verbose', type=int, required=False, default=10, help='进度条:运行时长的10%更新进度条')
args = parser.parse_args()
train_model(args.minu, args.gpus, args.verbose)
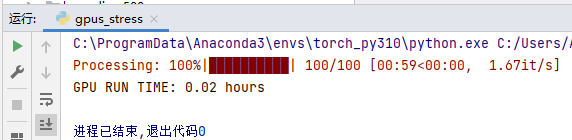

运行命令
32g显存的显卡执行以下命令
python gpus.py --gpus 2 --size 30000 --minu 6000
参数说明:
- gpus:可用显卡数量
- size:矩阵大小,如果双卡32G显存,可以设置参数为30000,其他情况慢慢试
- minu:运行时长,单位-分钟






![P1873 [COCI 2011/2012 #5] EKO / 砍树](https://img-blog.csdnimg.cn/direct/062dfb3cfa394d45bdd095464d7ba573.png)