Netty进阶
- 一、黏包半包的深入理解(本质原因:TCP是流式协议,消息无边界)
- 1、TCP滑动窗口
- 2、协议设计与解析
- 2.1、Redis协议
- 2.2、HTTP协议
- 2.3、自定义协议
- 2.3.1、自定义协议要求
- 2.3.2、自定义消息对象(编解码器、消息抽象类、具体消息类)
- 2.3.3、TestMessageCodec:测试案例
- 2.3.4、半包问题出现及解决
- 2.4、@Sharable:可共享handler
一、黏包半包的深入理解(本质原因:TCP是流式协议,消息无边界)

1、TCP滑动窗口
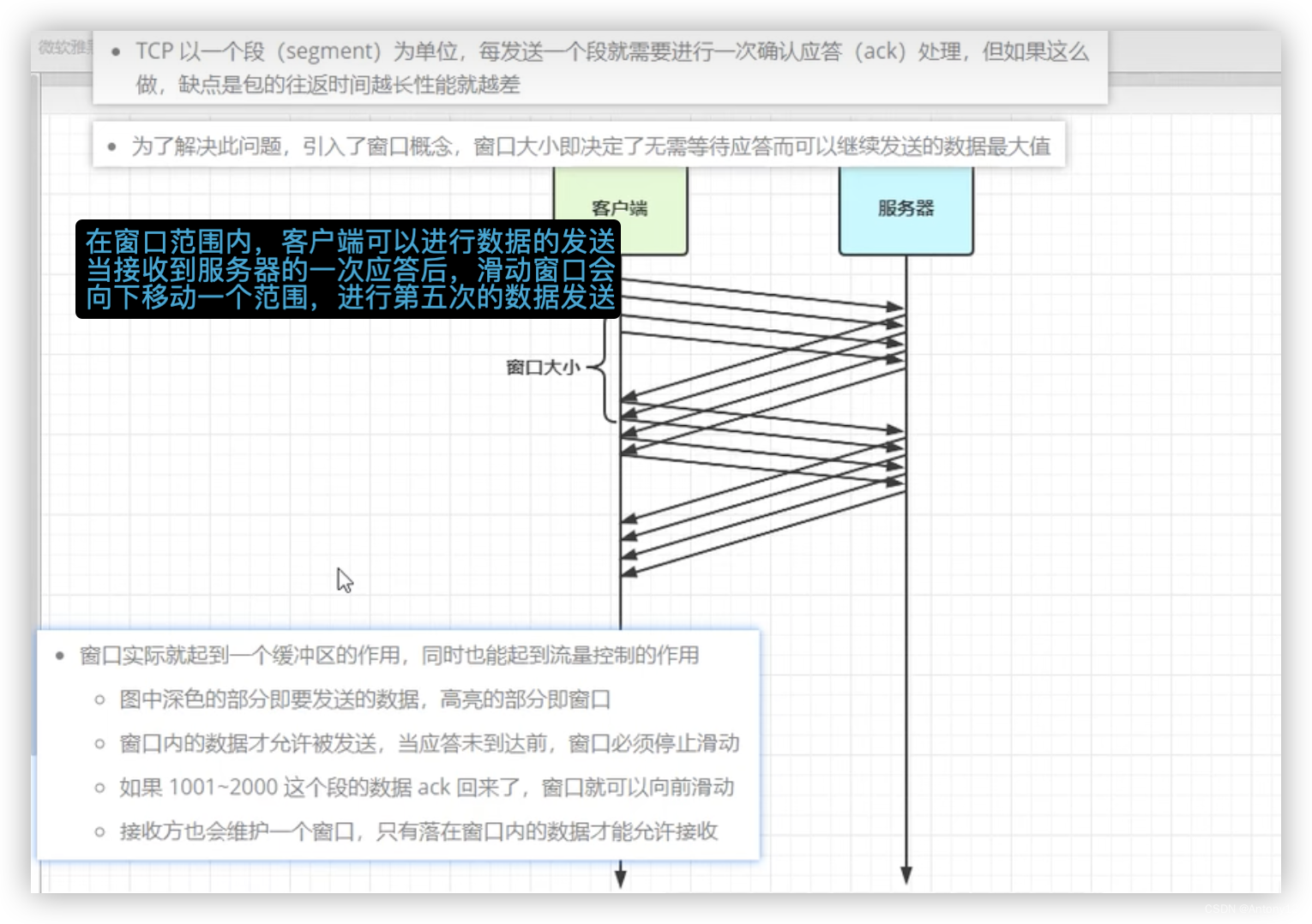
tcp层面分析黏包半包现象的原因:
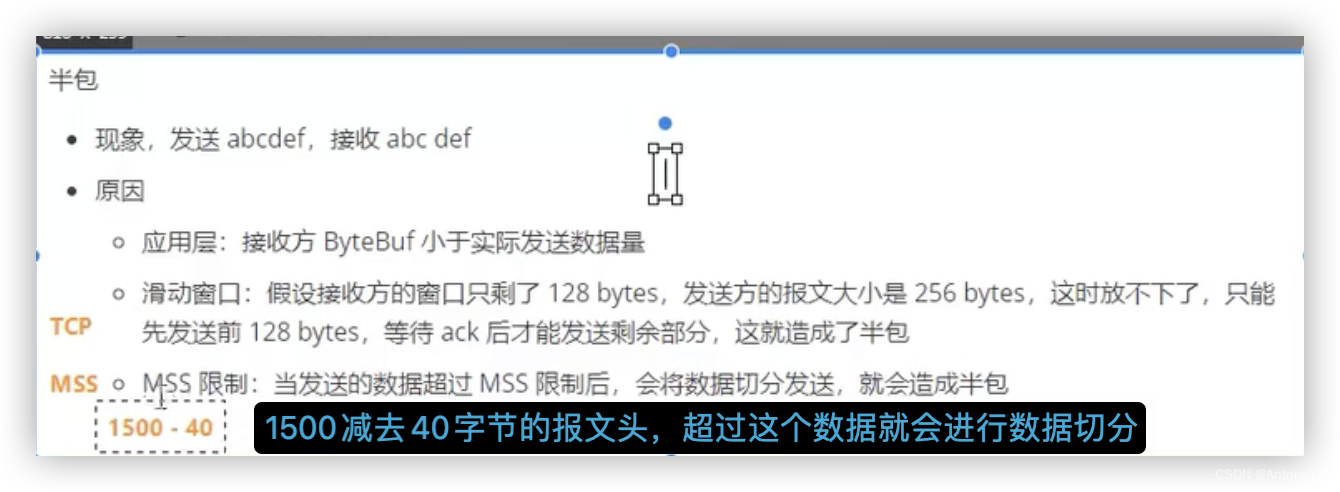
1)半包:
(1)(tcp层)当接收方的窗口用到一半时用完了,这时候去读就拿到的是半包数据
(2)(链路层)mss限制:当发送的数据超过Mss限制后,会将数据切分发送,就会造成半包
(3)(网络层)mtu 155-40
2)黏包(tcp层):
(1)当接收方的窗口范围较大有空闲时,就会过多的接收数据从而导致黏包
(2)Nagle算法:尽可能多的去发送数据,不要因为发送数据过少导致效率过低可能会造成黏包
2、协议设计与解析
2.1、Redis协议
(1)协议说明
redis对于整个命令会看成一个数组。
例:set key value
//举例:set name zhangsan //下面每个命令都由一个回车符、换行符分割 字节对应13,10
*3
$3
set
$4
name
$8
zhangsan
*3:首先需要让你发送数组的长度 *表示的是命令的数量,3则是命令组成的长度。
$3:$表示的是某个命令参数的长度,3表示该命令参数长度为3。
每个命令参数都由\r\n来进行分割
(2)案例
使用redis协议模拟与redis服务端进行通信,执行一条set、get命令
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis;
import io.netty.bootstrap.Bootstrap;
import io.netty.buffer.ByteBuf;
import io.netty.channel.Channel;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioSocketChannel;
import lombok.extern.slf4j.Slf4j;
import java.nio.charset.Charset;
/**
* @version 1.0
* @ClassName TestRedis
* @Description TODO 类描述
* @date 2024/4/30 3:58 下午
**/
@Slf4j
public class TestRedis {
public static void main(String[] args) throws InterruptedException {
byte[] LINE = {13, 10};//两个字节表示回车,换行
NioEventLoopGroup group = new NioEventLoopGroup();
Channel channel = new Bootstrap()
.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelActive(ChannelHandlerContext ctx){
//向redis服务端发送一个写指令:set name changlu
set(ctx);
//向redis服务端发送一个读指令:get name
get(ctx);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
log.debug("收到 {} , 消息为:{}", ctx.channel(), buf.toString(Charset.defaultCharset()));
super.channelRead(ctx, msg);
}
//执行set命令:set name changlu
private void set(ChannelHandlerContext ctx){
final ByteBuf buffer = ctx.alloc().buffer();
buffer.writeBytes("*3".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("$3".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("set".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("$4".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("name".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("$8".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("zhangsan".getBytes());
buffer.writeBytes(LINE);
ctx.writeAndFlush(buffer);
}
//执行get命令:get name
private void get(ChannelHandlerContext ctx){
final ByteBuf buffer = ctx.alloc().buffer();
buffer.writeBytes("*2".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("$3".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("get".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("$4".getBytes());
buffer.writeBytes(LINE);
buffer.writeBytes("name".getBytes());
buffer.writeBytes(LINE);
ctx.writeAndFlush(buffer);
}
});
}
}).connect("127.0.0.1", 6379).sync().channel();
log.debug("客户端连接成功:{}", channel);
channel.closeFuture().addListener(future -> {
group.shutdownGracefully();
});
}
}
结果展示:


2.2、HTTP协议
2.2.1、认识HttpServerCodec
HttpServerCodec:是一个编解码处理器,处理入站、出站处理器。入站处理器会对http请求进行解码
//CombinedChannelDuplexHandler组合其他两个handler,分别是InBound和OutBound 编解码处理器
public final class HttpServerCodec extends CombinedChannelDuplexHandler<HttpRequestDecoder, HttpResponseEncoder>
implements HttpServerUpgradeHandler.SourceCodec {
使用方式:
ch.pipeline().addLast(new HttpServerCodec());
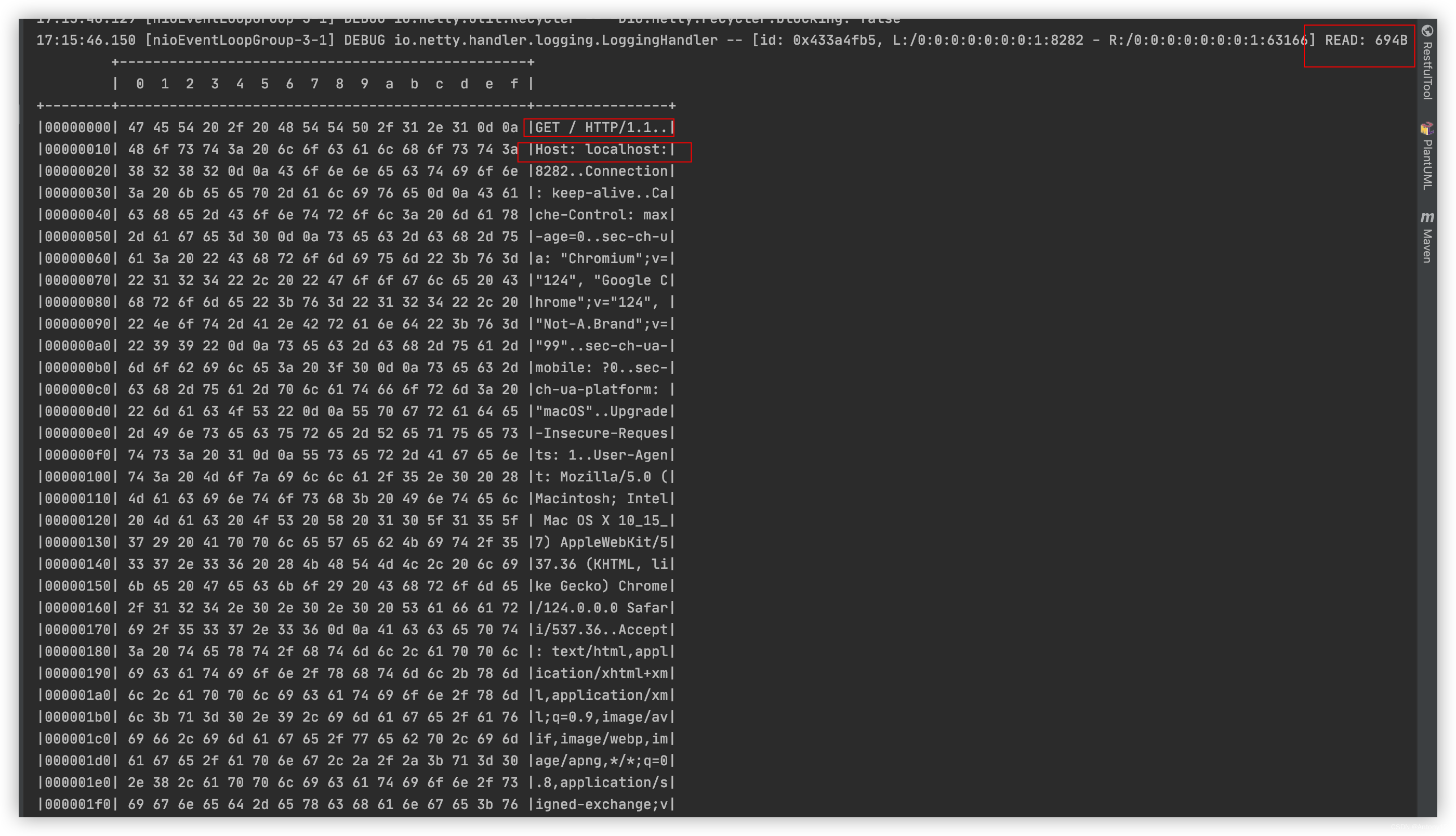
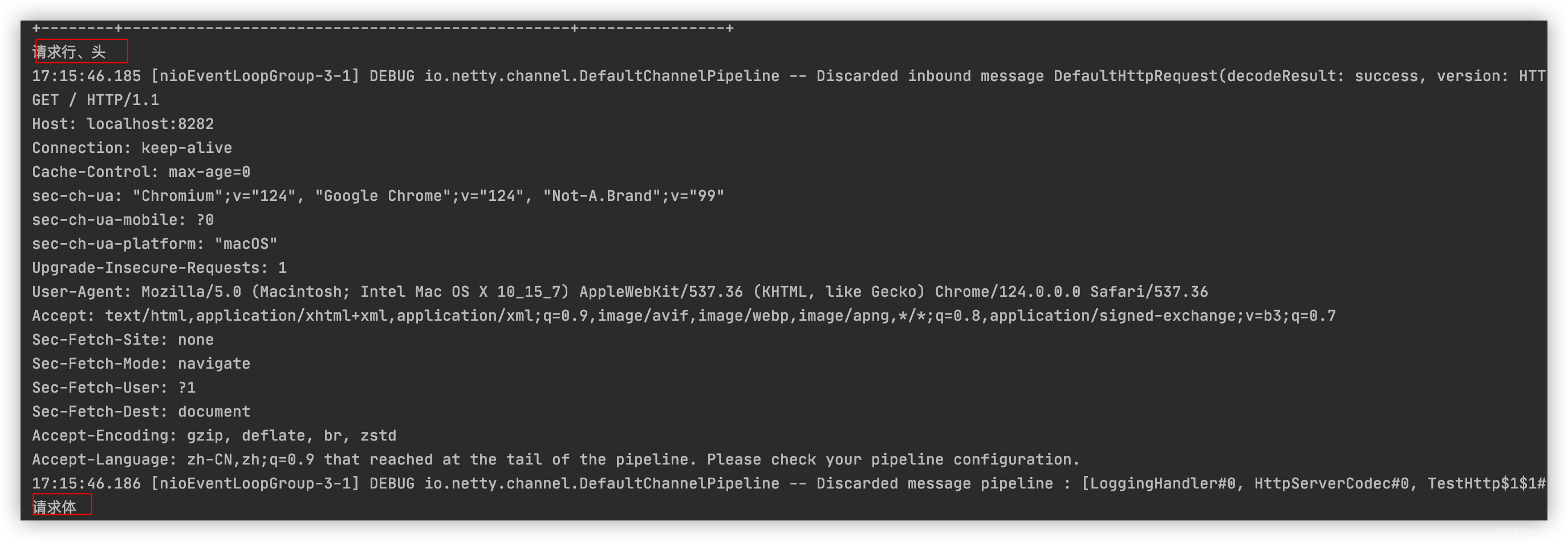
浏览器发送一次请求(无论什么方法请求)实际上会解析成两部分:
若是我们重写channelRead方法,那么一个http请求就会走两次该handler方法,每次执行方法其中的Object
msg分别为不同部分的解析对象DefaultHttpRequest:解析出来请求行和请求头。
LastHttpContent$1:表示请求体。(即便是get请求,请求体内容为空也会专门解析一个请求体对象)
情况一:若是想区分请求头、请求行走的handler那么就需要写一个简单的判断:
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//DefaultHttpRequest实现了HttpRequest接口
if (msg instanceof HttpRequest){
System.out.println("请求行、头");
//LastHttpContent实现了HttpContent接口
}else if (msg instanceof HttpContent){
System.out.println("请求体");
}
super.channelRead(ctx, msg);
}
});
情况二:若是我们只对某个特定类型感兴趣的话,例如只对解析出来的DefaultHttpRequest请求体对象感兴趣,可以实现一个SimpleChannelInboundHandler
//②若是只对HTTP请求的请求头感兴趣,那么实现SimpleChannelInboundHandler实例,指明感兴趣的请求对象为HttpRequest(实际就是DefaultHttpRequest)
ch.pipeline().addLast(new SimpleChannelInboundHandler<HttpRequest>() {
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpRequest msg) throws Exception {
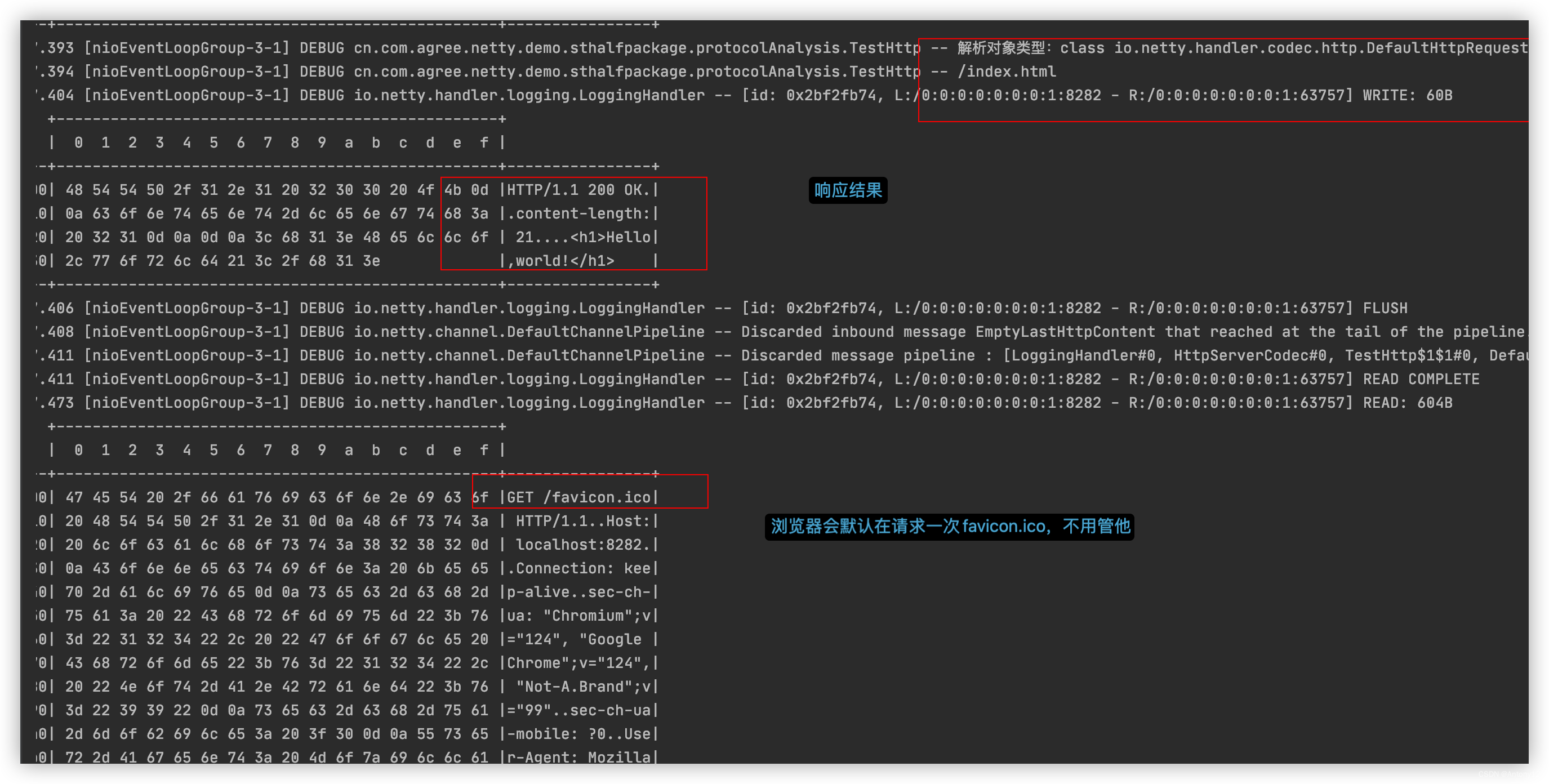
log.debug("解析对象类型:{}", msg.getClass());
log.debug(msg.uri());
//进行响应返回
//①构建响应对象
final DefaultFullHttpResponse response =
new DefaultFullHttpResponse(msg.protocolVersion(), HttpResponseStatus.OK);
// 响应内容
final byte[] content = "<h1>Hello,world!</h1>".getBytes();
//设置响应头:content-length:内容长度。不设置的话浏览器就不能够知道确切的响应内容大小则会造成一直没有处理完的现象
response.headers().setInt(HttpHeaderNames.CONTENT_LENGTH, content.length);
response.content().writeBytes(content);
//②写会响应
ctx.writeAndFlush(response);
}
});
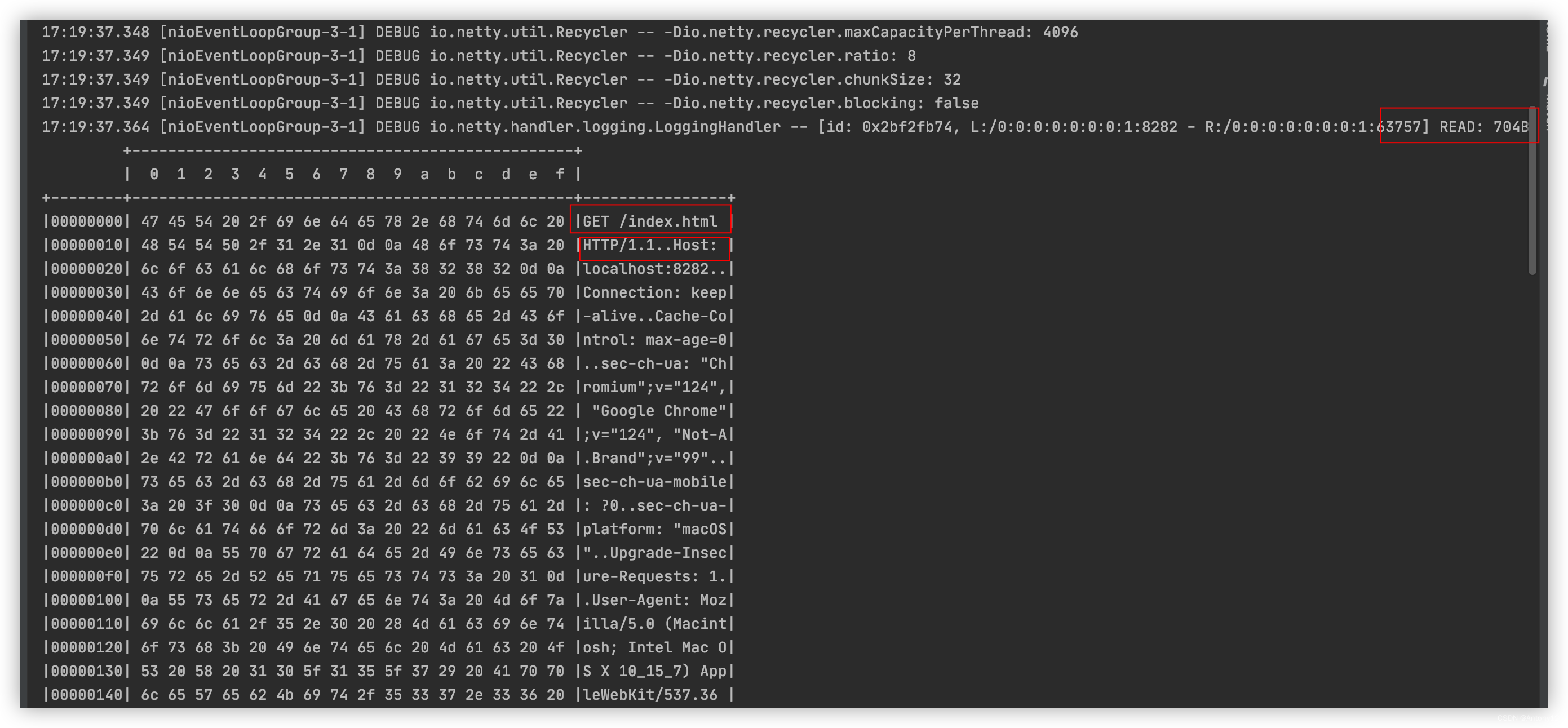
-
应该是由于没有指定Content-length,浏览器不能够保证当前内容是全部内容,就会出现一直转圈圈等待的效果,并且响应结果也不会出现。
-
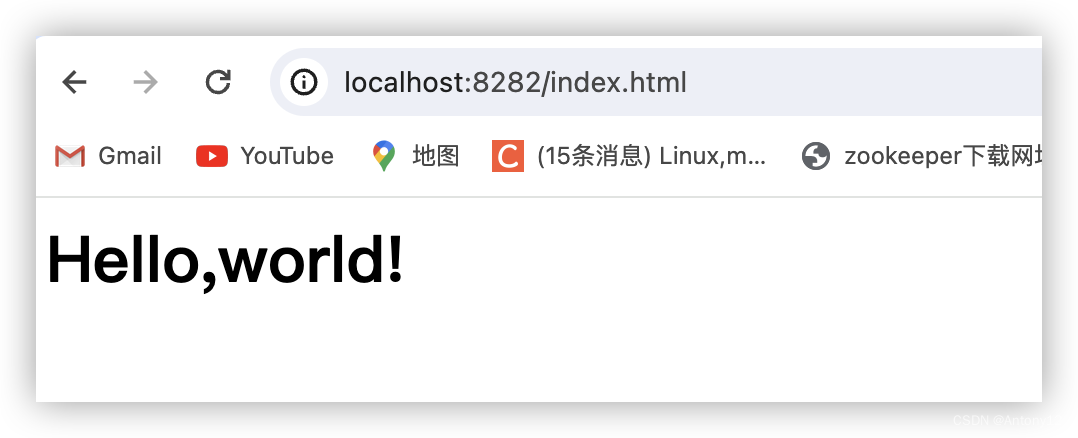
若是设置了的话就不会出现转圈圈现象以及检查response也会有内容:
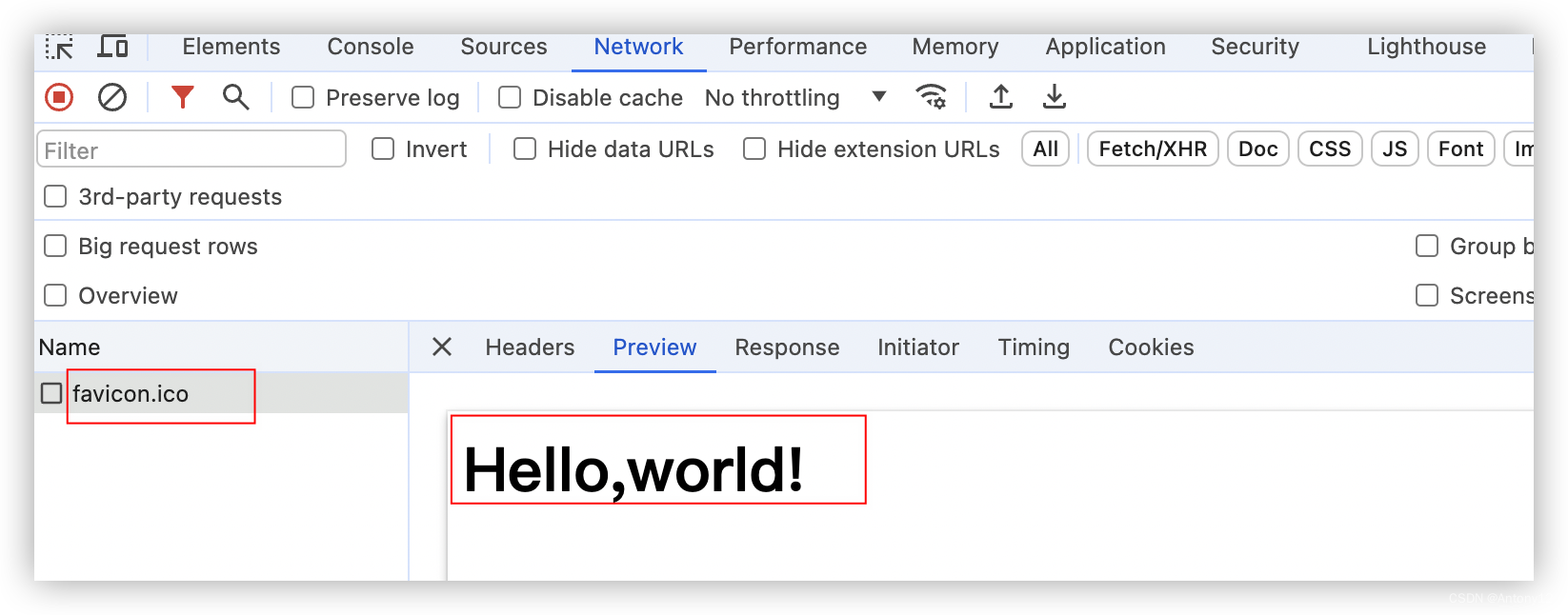
2.3、自定义协议
2.3.1、自定义协议要求
下面是自定义协议案例的协议内容:
魔数(四个字节):用来在第一时间判定是否是无效数据包
版本号(一个字节):可以支持协议的升级
序列化算法(一个字节):消息正文到底采用哪种序列化反序列化方式,可以由此扩展,例如:json、protobuf、hessian、jdk
指令类型(一个字节):是登录、注册、单聊、群聊... 跟业务相关
请求序号(四个字节):为了双工通信,提供异步能力
对齐填充(一个字节):除正文长度和消息正文凑满16个字节,也就是2的n次方
正文长度(四个字节):正文的长度
消息正文:正文内容(根据序列化算法进行序列化成字节)
-
魔数:一般发送的头几个都是数字都是魔数,例如Java的二进制字节码的起始8个字节就是魔数。
-
版本号:一般用于支持协议的升级,若是协议升级可能其中的字段或者其他内容有所更改。
-
序列化算法:一般指的是消息正文,对消息正文采用特殊的格式。JDK的话缺点就是不能跨平台;谷歌出品的protobuf,其与hession都是二进制的,其可读性不好,但是字节数占用最少性能更高。
-
指令类型:消息是个什么类型,这与业务相关。 请求序号:例如发送是1 2 3,但是由于网络或其他因素受到的时候不是1 2 3顺序。
-
正文长度:通过正文长度知道正文接下来需要读取多少字节
2.3.2、自定义消息对象(编解码器、消息抽象类、具体消息类)
- Message:消息抽象类,定义了消息相关的一些字段内容。
- LoginRequestMessage:一条业务消息,实现了Message抽象类,是登陆请求消息的抽象。
- MessageCodec:实现了ByteToMessageCodec执行器,需要传入一个泛型,该泛型就是你要将Bytebuf转换的对象,并且其中需要你重写编解码方法,也就是解析、封装你自定义的一些协议
Message:
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis.custom;
import lombok.Data;
import java.io.Serializable;
import java.util.HashMap;
import java.util.Map;
/**
* @version 1.0
* @ClassName Message
* @Description TODO 类描述
* @date 2024/4/30 5:56 下午
**/
@Data
public abstract class Message implements Serializable {
/**
* 根据消息类型字节,获得对应的消息 class
* @param messageType 消息类型字节
* @return 消息 class
*/
public static Class<? extends Message> getMessageClass(int messageType) {
return messageClasses.get(messageType);
}
private int sequenceId;
private int messageType;
public abstract int getMessageType();
public static final int LoginRequestMessage = 0;
private static final Map<Integer, Class<? extends Message>> messageClasses = new HashMap<>();
}
MessageCodec:实现了对自定义协议的编解码
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis.custom;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.ByteToMessageCodec;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.List;
/**
* @version 1.0
* @ClassName MessageCodec
* @Description TODO 类描述
* @date 2024/4/30 5:46 下午
**/
@Slf4j
public class MessageCodec extends ByteToMessageCodec<Message> {
/**
* 出站前将封装好的Message对象写入到ByteBuf中
*
* @param ctx
* @param msg 封装好的消息对象
* @param out 写入到消息对象中
* @throws Exception
*/
@Override
protected void encode(ChannelHandlerContext ctx, Message msg, ByteBuf out) throws Exception {
//1、4个字节的魔数
out.writeBytes(new byte[]{1, 2, 3, 4});
//2、1个字节版本号:1 表示版本1
out.writeByte(1);
//3、1个字节序列化算法:0 jdk;1 json
out.writeByte(0);
//4、1个字节指令类型:在Message对象中定义
out.writeByte(msg.getMessageType());
//5、4个字节:表示请求序号
out.writeInt(msg.getSequenceId());
//获取内容的字节数组(默认直接采用JDK对象序列化方式)
final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(msg);
final byte[] data = baos.toByteArray();
//(额外):为了满足2的N次方倍,要再加入一个字节凑满16个字节(除实际内容)
// 仅仅目的是为了对齐填充
out.writeByte(0xff);
//6、4个字节length内容长度
out.writeInt(data.length);
//7、写入内容
out.writeBytes(data);
}
/**
* 进行解码:之前怎么封装的就怎么取
*
* @param ctx
* @param in
* @param out
* @throws Exception
*/
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
final int magicNum = in.readInt();//魔术字
final byte version = in.readByte();//版本号
final byte serializerType = in.readByte();//序列号
final byte messageType = in.readByte();//消息类型
final int sequencedId = in.readInt();//请求序号
in.readByte();//填充号
final int length = in.readInt();//内容长度
final byte[] data = new byte[length];
// in.readBytes(data, 0, length);//内容(字节数组)
in.readBytes(data, 0, in.readableBytes());//内容(字节数组)
Message message = null;
//进行jdk序列化(字节数组转为对象)
if (serializerType == 0) {
final ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(data));
message = (Message) ois.readObject();
}
out.add(message);
log.debug("{}, {}, {}, {}, {}, {}", magicNum, version, messageType, sequencedId);
log.debug("{}", message);
}
}
LoginRequestMessage:
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis.custom;
/**
* @version 1.0
* @ClassName LoginRequestMessage
* @Description TODO 类描述
* @date 2024/5/6 2:44 下午
**/
import lombok.Data;
import lombok.ToString;
@Data
@ToString(callSuper = true)
public class LoginRequestMessage extends Message{
private String username;
private String password;
public LoginRequestMessage() {
}
public LoginRequestMessage(String username, String password) {
this.username = username;
this.password = password;
}
@Override
public int getMessageType() {
return LoginRequestMessage;
}
}
2.3.3、TestMessageCodec:测试案例
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis.custom;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.channel.embedded.EmbeddedChannel;
import io.netty.handler.logging.LoggingHandler;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.ArrayList;
/**
* @version 1.0
* @ClassName TestMessageCodec
* @Description TODO 类描述
* @date 2024/5/6 2:48 下午
**/
@Slf4j
public class TestMessageCodec {
@Test
public void test() throws Exception {
EmbeddedChannel embeddedChannel = new EmbeddedChannel(new LoggingHandler(), new MessageCodec());
//入站方法测试(编码):encode()
LoginRequestMessage loginRequestMessage = new LoginRequestMessage("张三", "1234565");
embeddedChannel.writeOutbound(loginRequestMessage);
//出站方法测试(解码):decode()
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer();
//根据协议来进行编码到ByteBuf中
new MessageCodec().encode(null,loginRequestMessage,byteBuf);
ArrayList<Object> list = new ArrayList<>();
//之后按照协议进行的ByteBuf进行解码取得一系列参数及对象
new MessageCodec().decode(null,byteBuf,list);
log.debug("解码得到的对象是:{}",list.get(0));
}
}
测试结果:

2.3.4、半包问题出现及解决
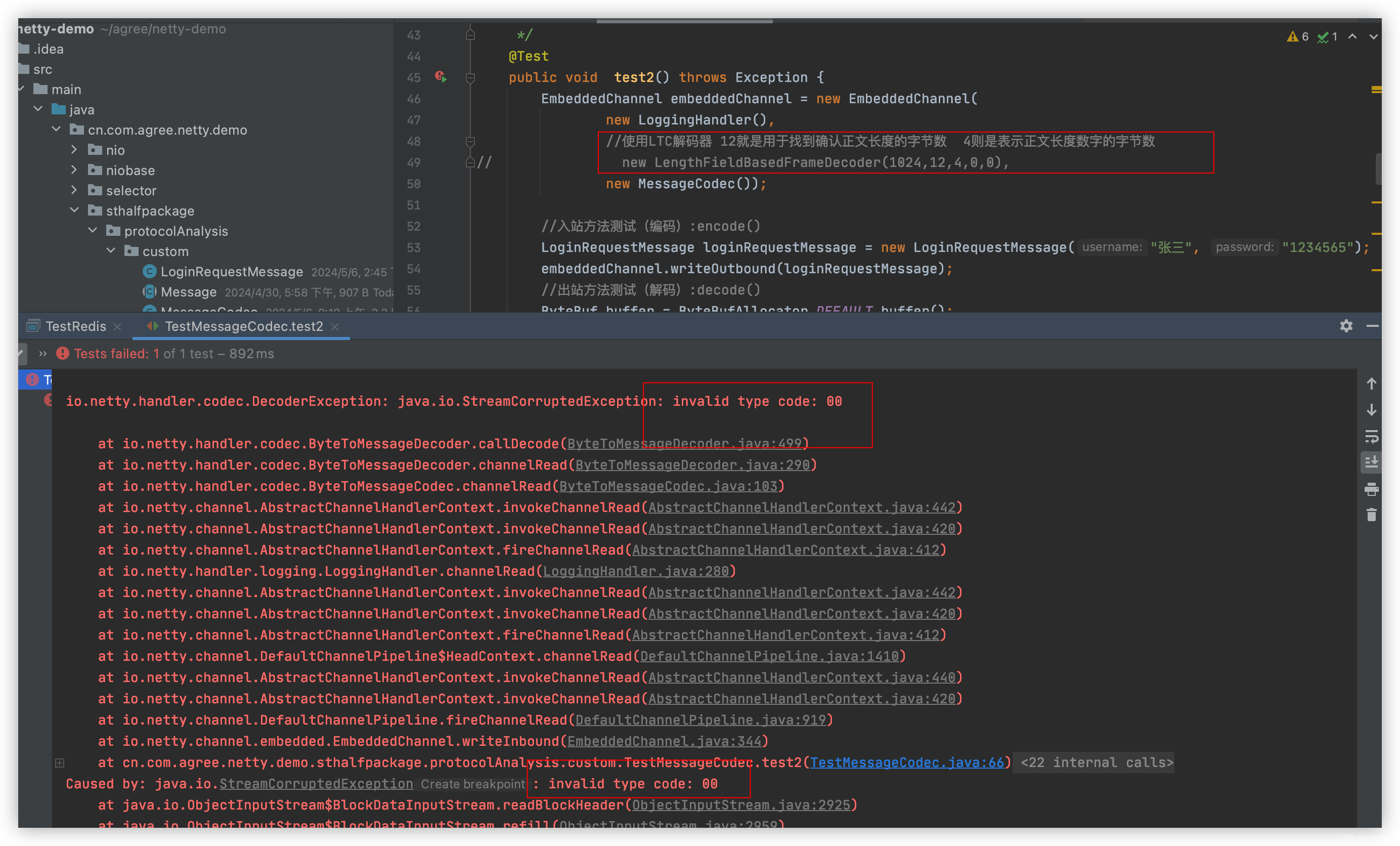
- 半包问题出现原因:若是我们将一个编码过后的ByteBuf分为两个包来入站,那么每发一个包就会走一个decode()也就是解码方法,那么此时可以肯定的是由于包没有发完整,序列化字符串肯定也不完整,那么此时进行解序列化肯定就会报错出现异常!
- 解决半包思路:我们可以使用LTC解码器来进行解决,按照指定的长度规则来进行解码,那么之前半包会走两次handler再使用了解码器之后,由于半包不完整就会进行等待继续接收包,直到取到完整的包才会走handler那么此时执行decode解码自然不会出现序列化问题!
代码(模拟半包):
/**
* 案例2:解码出现半包问题及解决方案,这里仅演示解码情况
* 问题描述:若是出现半包问题,那么可能就会出现接解析序列化异常!
* 解决方案:使用LTC(基于长度的帧解码器)来解决半包、黏包问题。
*/
@Test
public void test2() throws Exception {
EmbeddedChannel embeddedChannel = new EmbeddedChannel(
new LoggingHandler(),
//使用LTC解码器 12就是用于找到确认正文长度的字节数 4则是表示正文长度数字的字节数
// new LengthFieldBasedFrameDecoder(1024,12,4,0,0),
new MessageCodec());
//入站方法测试(编码):encode()
LoginRequestMessage loginRequestMessage = new LoginRequestMessage("张三", "1234565");
embeddedChannel.writeOutbound(loginRequestMessage);
//出站方法测试(解码):decode()
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
//根据协议来进行编码到ByteBuf中
new MessageCodec().encode(null,loginRequestMessage,buffer);
//进行切片将数据切分成两片
ByteBuf firSlice = buffer.slice(0, 100);
ByteBuf secSlice = buffer.slice(100, buffer.readableBytes() - 100);
//模拟入站操作,此时就会执行decode方法
embeddedChannel.writeInbound(firSlice);
ArrayList<Object> list = new ArrayList<>();
//之后按照协议进行的ByteBuf进行解码取得一系列参数及对象
new MessageCodec().decode(null,buffer,list);
log.debug("解码得到的对象是:{}",list.get(0));
}
结果:解析异常
加上LTC解码器 解决半包问题
代码:
/**
* 案例2:解码出现半包问题及解决方案,这里仅演示解码情况
* 问题描述:若是出现半包问题,那么可能就会出现接解析序列化异常!
* 解决方案:使用LTC(基于长度的帧解码器)来解决半包、黏包问题。
*/
@Test
public void test2() throws Exception {
EmbeddedChannel embeddedChannel = new EmbeddedChannel(
new LoggingHandler(),
//使用LTC解码器 12就是用于找到确认正文长度的字节数 4则是表示正文长度数字的字节数
new LengthFieldBasedFrameDecoder(1024,12,4,0,0),
new MessageCodec());
//入站方法测试(编码):encode()
LoginRequestMessage loginRequestMessage = new LoginRequestMessage("张三", "1234565");
embeddedChannel.writeOutbound(loginRequestMessage);
//出站方法测试(解码):decode()
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
//根据协议来进行编码到ByteBuf中
new MessageCodec().encode(null,loginRequestMessage,buffer);
//进行切片将数据切分成两片
ByteBuf firSlice = buffer.slice(0, 100);
ByteBuf secSlice = buffer.slice(100, buffer.readableBytes() - 100);
//模拟入站操作,此时就会执行decode方法
embeddedChannel.writeInbound(firSlice);
ArrayList<Object> list = new ArrayList<>();
buffer.retain();//引用计数加1
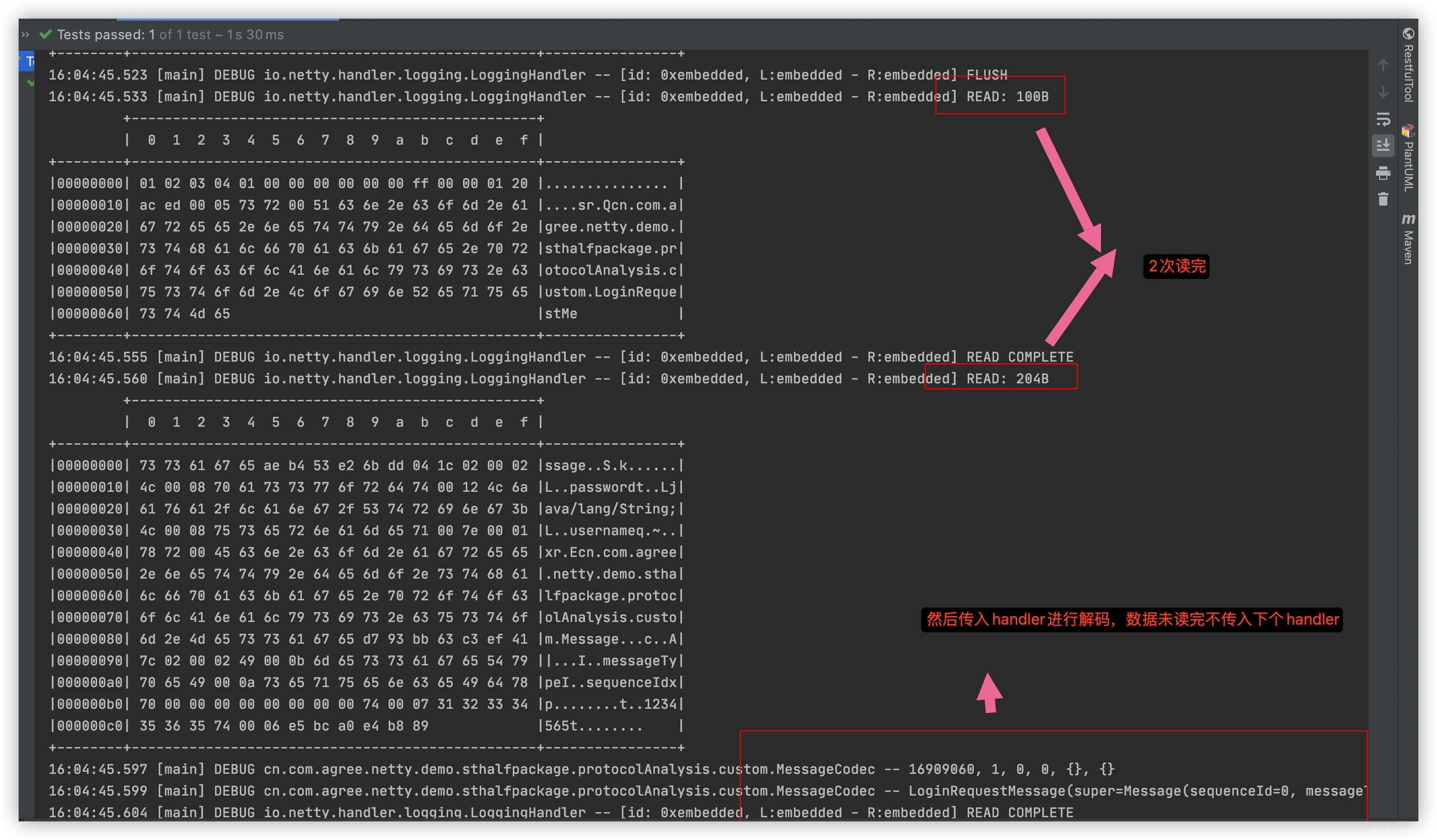
embeddedChannel.writeInbound(secSlice);//执行一次writeInbound实际上就会执行release()进行内存释放,由于这里为了避免释放,自此之前引用计数+1
}
结果:
2.4、@Sharable:可共享handler
- 我们之前编写代码时都会在初始化channel时添加执行器handler,添加的方式如下,我们可以看到每次都是添加到channel的pipeline管道对象中,那么就会有一个疑问:每个channel在创建之初都会添加新的handler到管道中吗?
//实际写服务端的handler
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler())
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){})
}
}
//EmbeddedChannel添加handler方式
final EmbeddedChannel channel = new EmbeddedChannel(
new LoggingHandler(),
new LengthFieldBasedFrameDecoder(1024, 12, 4, 0, 0),
new MessageCodec() //自定义的编解码器
);
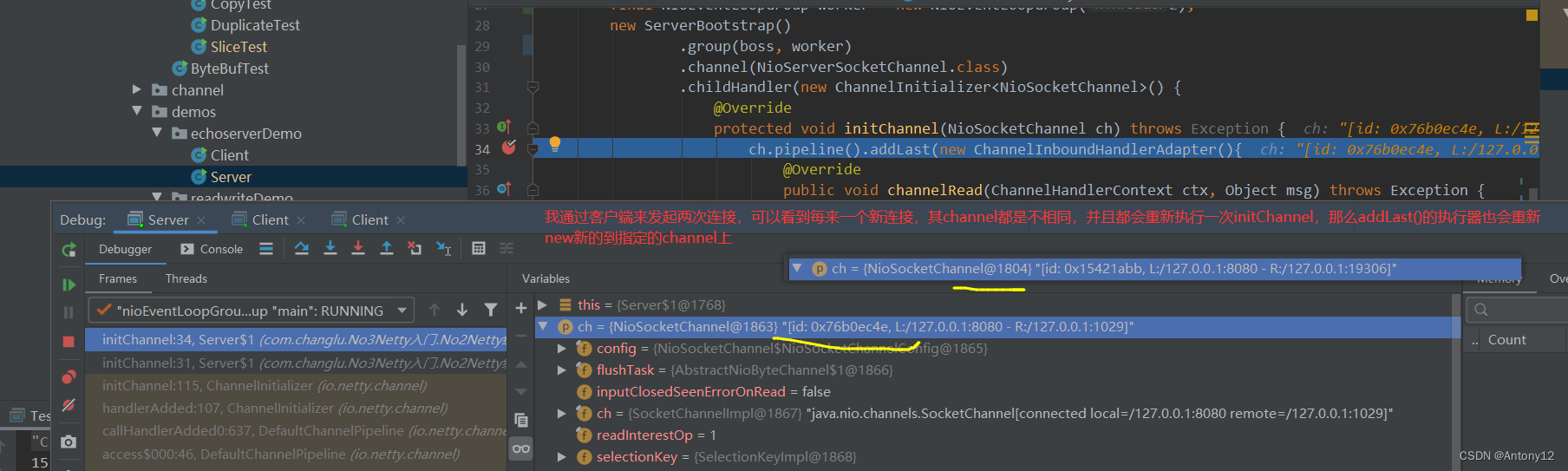
- 通过debug测试可以得出结论:若是我们直接在addLast()中添加新的handler,那么就是每初始化一个连接就会创建多个新的handler对象!
- 那么我们可以想到一个优化思路,既然如此那么为什么我们不提前直接new出来一个handler作为多个channel的共享执行器?对的确实可以,对于我们自定义的一些执行器我们可以清楚的知道有没有使用一些共享对象,有没有线程安全问题,而对于netty提供给我们的我们不能够确定,这时候nettty给了我们思路来看其提供的handler是否是可共享、是线程安全的:实际上就是@Sharable。
- 结论:如果netty提供给我们的handler是可共享的,就会标注该类为@Sharable,我们可以放心大胆的创建一个公共handler来被多个channel共同使用!
- 对于LoggingHandler是有该注解的,表示是可共享的!
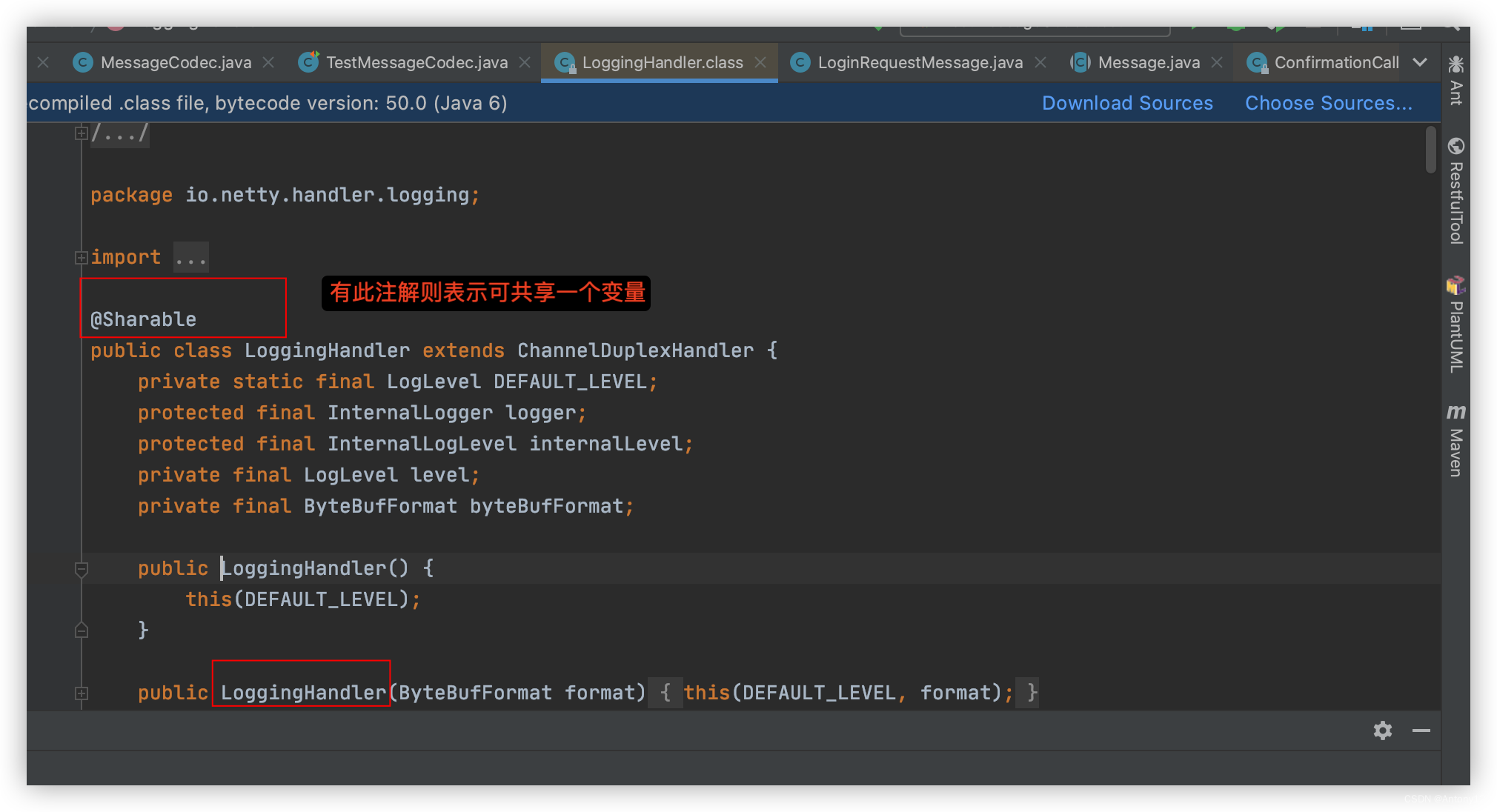
- ByteToMessageCodec的子类无法添加@Sharable,使用会报错
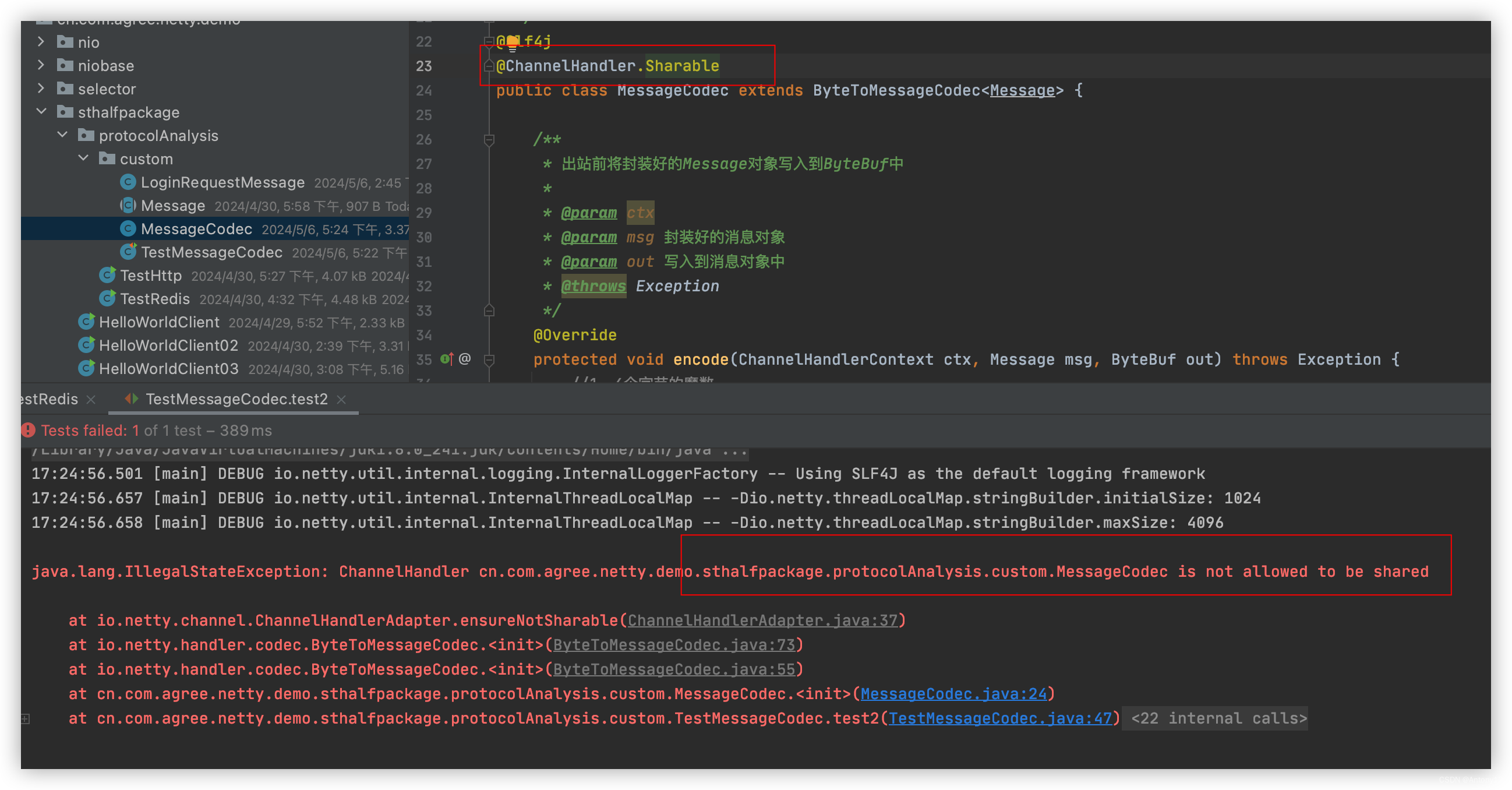
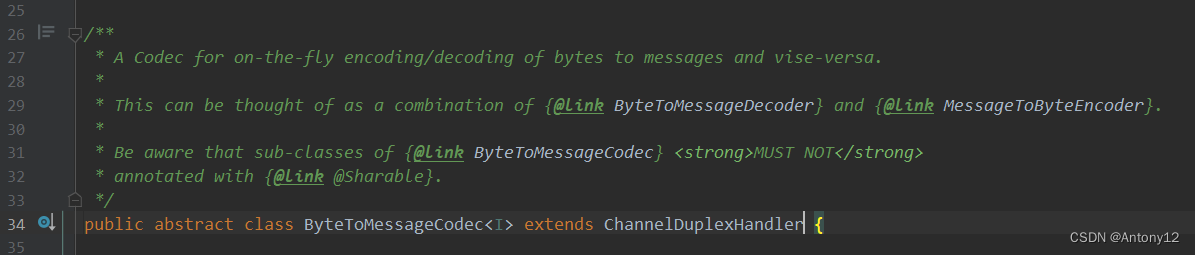
- 分析:netty框架设计者在设计ByteToMessageCodec类时设定就是实现该类的一些编解码器正常来说都会使用到一个公共变量存储及操作,其认为本该是不可共享的,如下代码注释说明,该类不允许被标注
- 解决方案:那么若是我们自定义的编解码器确实没有使用到公共变量,我们想将其标注为
@Sharable呢?可以将原本实现ByteToMessageCodec更改MessageToMessageCodec
package cn.com.agree.netty.demo.sthalfpackage.protocolAnalysis.custom;
/**
* @version 1.0
* @ClassName MessageCodecSharable
* @Description TODO 类描述
* @date 2024/5/6 5:31 下午
**/
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandler;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToMessageCodec;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.List;
@Slf4j
@ChannelHandler.Sharable
public class MessageCodecSharable extends MessageToMessageCodec<ByteBuf, Message> {
@Override
protected void encode(ChannelHandlerContext ctx, Message msg, List<Object> out) throws Exception {
final ByteBuf buffer = ctx.alloc().buffer();
//1、4个字节的魔数
buffer.writeBytes(new byte[]{1,2,3,4});
//2、1个字节版本号:1 表示版本1
buffer.writeByte(1);
//3、1个字节序列化算法:0 jdk;1 json
buffer.writeByte(0);
//4、1个字节指令类型:在Message对象中定义
buffer.writeByte(msg.getMessageType());
//5、4个字节:表示请求序号
buffer.writeInt(msg.getSequenceId());
//获取内容的字节数组(默认直接采用JDK对象序列化方式)
final ByteArrayOutputStream baos = new ByteArrayOutputStream();
final ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(msg);
final byte[] data = baos.toByteArray();
//(额外):为了满足2的N次方倍,要再加入一个字节凑满16个字节(除实际内容)
// 仅仅目的是为了对齐填充
buffer.writeByte(0xff);
//6、4个字节length内容长度
buffer.writeInt(data.length);
//7、写入内容
buffer.writeBytes(data);
out.add(buffer);
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
final int magicNum = in.readInt();//魔术字
final byte version = in.readByte();//版本号
final byte serializerType = in.readByte();//序列号
final byte messageType = in.readByte();//消息类型
final int sequencedId = in.readInt();//请求序号
in.readByte();//填充号
final int length = in.readInt();//内容长度
final byte[] data = new byte[length];
// in.readBytes(data, 0, length);//内容(字节数组)
in.readBytes(data, 0, in.readableBytes());//内容(字节数组)
Message message = null;
//进行jdk序列化(字节数组转为对象)
if (serializerType == 0) {
final ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(data));
message = (Message) ois.readObject();
}
out.add(message);
log.debug("{}, {}, {}, {}, {}, {}", magicNum, version, messageType, sequencedId);
log.debug("{}", message);
}
}
server端改进后的代码:
/**
* 案例2:解码出现半包问题及解决方案,这里仅演示解码情况
* 问题描述:若是出现半包问题,那么可能就会出现接解析序列化异常!
* 解决方案:使用LTC(基于长度的帧解码器)来解决半包、黏包问题。
*/
@Test
public void test2() throws Exception {
LoggingHandler loggingHandler = new LoggingHandler();
MessageCodecSharable messageCodecSharable = new MessageCodecSharable();
EmbeddedChannel embeddedChannel = new EmbeddedChannel(
loggingHandler,
//使用LTC解码器 12就是用于找到确认正文长度的字节数 4则是表示正文长度数字的字节数
new LengthFieldBasedFrameDecoder(1024,12,4,0,0),
messageCodecSharable);
//入站方法测试(编码):encode()
LoginRequestMessage loginRequestMessage = new LoginRequestMessage("张三", "1234565");
embeddedChannel.writeOutbound(loginRequestMessage);
//出站方法测试(解码):decode()
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
//根据协议来进行编码到ByteBuf中
new MessageCodec().encode(null,loginRequestMessage,buffer);
//进行切片将数据切分成两片
ByteBuf firSlice = buffer.slice(0, 100);
ByteBuf secSlice = buffer.slice(100, buffer.readableBytes() - 100);
//模拟入站操作,此时就会执行decode方法
embeddedChannel.writeInbound(firSlice);
ArrayList<Object> list = new ArrayList<>();
buffer.retain();//引用计数加1
embeddedChannel.writeInbound(secSlice);//执行一次writeInbound实际上就会执行release()进行内存释放,由于这里为了避免释放,自此之前引用计数+1
}




![Linux主机重启后报错:[FAILED] Failed to start Switch Root.](https://img-blog.csdnimg.cn/direct/9ef41a9007ac4c759147649a72270f8d.png)