目录
Abstract
1 Introduction
2 Related Work
3 Background and Spark Basics
4 Cost Model Basic Bricks
4.1 Cluster Abastraction and Cost Model Parameters
4.2 Read
4.3 Write
4.4 Shuffle Read
4.5 Broadcast
5 Modeling GPSJ Queries
5.1 Statistics and Selectivity Estimates
5.2 The SC() Task Type
5.3 The SB() Task Type
5.4 The SJ() Task Type
5.5 The BJ() Task Type
5.6 The GB() Task Type
5.7 Handling Stragglers
Abstract
本文我们为Spark SQL提出了一个新的cost model。这个cost model涵盖了广义的Projection、Selection、Join(GPSJ)查询。cost model考虑了网络和IO成本,以及最相关的CPU成本。执行成本是从Spark生成的物理执行计划开始计算的。Spark在执行GPSJ查询时采用的操作集合是基于集群和应用参数以及一组数据库统计数据来进行代价的分析建模的。在三个基准测试和两个不同规模和不同计算特征的集群上进行的实验结果表明,我们的模型可以估计实际执行时间,平均误差约为20%。这样的精度足以让系统在执行时间差有限的情况下选择最有效的方案。如果分析模型与我们的离散处理策略相结合,误差可以降低到14%。
1 Introduction
大数据改变了数据处理和分析的方式。需要处理的数据量及其多样性推动了一系列解决方案和平台的发展。在这种情况下,Apache Hadoop是在过去几年中比其他任何框架都更受欢迎的框架。Hadoop的第一个版本被严格限制在mapreduce编程范式中。MapReduce需要熟练的程序员,因此Hadoop设计师试图通过提供更高级和易于使用的编程环境来减轻用户的压力,例如Pig和hive——第一个基于Hadoop和MapReduce的SQL系统。
Spark是一个快速且通用的计算引擎,用于运行在Hadoop上的大规模数据处理。它通过支持transformation的流水线构建在MapReduce范例之上。通过这种方式,它减少了将数据写回磁盘的次数,并且可以比MapReduce[1]快几个数量级,同时保留了容错功能。Spark可以处理存储在多个存储引擎(如MongoDB、Cassandra)中的数据。在这项工作中,我们将重点关注Hadoop(和HDFS),这是迄今为止Spark最常用的架构。特别是,Spark包含了一个基于SQL的子系统:标准的SQL查询被根据Spark命令重写,并在集群上并行执行。Spark SQL的性能允许对大数据进行在线计算,许多OLAP供应商(如Tableau和Micro Strategy)已经提供了与他们系统的连接。
尽管Spark已经被广泛采用,但它仍在开发中,并在不断发展。Spark SQL引擎不能被认为像传统的关系dbms那样成熟,许多性能改进仍然是可能的。特别是,负责将SQL查询转换为Spark命令序列的模块Catalyst[2]仍然依赖于基于规则的优化器,并且关于预测运行SQL查询的成本的成本模型所做的工作很少。
在本文中,我们提出了一个Spark SQL的成本模型,该模型涵盖了在[3]中首次研究的GPSJ(广义投影/选择/连接)查询类。GPSJ查询由join、selection predicates和aggregation组成。由于这三个操作符不一定都必须出现,因此我们的成本模型也涵盖了简单的selection和join查询。尽管已经为通用MapReduce应用程序开发了其他成本模型,但据我们所知,这是第一个考虑到Spark计算范式和Spark SQL的结果。更详细地说,我们的成本模型有以下特点:
-
它依赖于数量有限的任务类型,这些任务类型如果组合得当,可以对一系列SQL查询进行建模。由于这些任务类型的行为是已知的,它们的成本模型可以被分析塑造,从而提供准确的估计。
-
它不需要旨在捕获通用作业行为的复杂作业配置文件(例如,[4]),而是基于一小部分集群和应用程序特性以及db统计数据来进行估计。
-
成本函数根据Spark成本对SQL执行计划进行建模。这允许对执行成本进行sql感知的评估。我们相信将成本评估转移到更概念化的层次可以帮助sql用户更好地理解系统行为。
-
返回的成本不是逻辑成本,而是考虑到集群特性的实际执行时间。这样就支持集群性能分析和集群调优。
虽然这个成本模型是专门为Spark构建的(在任务类型和系统行为方面),但它可以推广到其他大数据SQL引擎,如HIVE和Impala。我们的方法的新颖性超越了Spark SQL的界限;它代表了一种在大数据平台上计算执行SQL查询成本的原始方法。
执行时间是通过将执行由Catalyst生成的物理计划代码的树的节点所需的时间相加得到的。成本模型基于磁盘访问时间和跨集群节点传输数据所花费的网络时间。我们还考虑了数据序列化/反序列化和压缩的CPU时间。这些成本是由磁盘吞吐量隐式计算的。正如在[1]中所解释的,spark的工作负载主要是一次性的,如SQL查询产生的工作负载,要么是网络绑定的,要么是磁盘绑定的,而CPU可能成为序列化和压缩成本方面的瓶颈。对于通常受cpu限制的multi-pass2工作负载来说,情况并非如此。在不同规模和不同计算特征的集群上的实验结果表明,该模型可以估计实际执行时间,平均误差在20%左右。这样的精度足以让系统在执行时间差有限的情况下选择最有效的方案。如果分析模型与离散体处理策略相结合,误差可以降低到14%。
cost model可用于多种情况,从估计给定集群和应用程序配置的查询执行时间,到清楚地了解不同配置下的查询性能。这些是工作负载管理、容量规划和系统调优中的关键信息。我们的成本模型也是将Catalyst转变为完全基于成本的优化器的第一步,即使考虑了自适应执行,也可以比较不同物理计划的执行成本。
本文的主要贡献有:(1)建立了覆盖GPSJ查询表达性的分析成本模型;(2)大量的测试(总的来说,我们运行了1000多个查询),从几个不同的角度分析了它的准确性。对3个基准和2个群集进行了测试。
论文结构如下:第2节报道相关文献;第3节提供了Spark的背景知识,并描述了如何在Spark上执行GPSJ查询;成本模型的定义见第4节和第5节;第6节报告实验结果;第七部分,得出结论。
2 Related Work
关于预测SQL引擎性能的成本模型的文献可以追溯到70年代中期,当时第一个查询优化器被开发出来。在[5]中,作者提出了关系DBMS System R的成本模型:考虑了过滤、投影和连接操作。根据获取的磁盘页面计算成本,并对谓词选择性进行了一组基本假设。集中式SQL引擎的成本模型的有效性取决于可用统计数据的质量。例如,从基本属性和表基数转向直方图[6],可以在存在倾斜分布数据的情况下提高选择性谓词的准确性。当从集中式dbms传递到分布式dbms[7]时,还必须考虑通信时间。网络的拓扑结构在定义不同成本组成部分的权重方面起着核心作用:虽然传输成本在广域网中通常占主导地位[8],但为LAN设计的成本模型也必须考虑本地访问成本。并行dbms又向前迈进了一步,它要求成本模型考虑到资源争用和数据依赖[9]。
面向大数据平台的SQL引擎数量在不断增长。Hive是第一个提供类似sql的查询语言的解决方案,称为HiveQL[10]。Hive将HiveQL查询编译成一系列的MapReduce作业,这意味着高延迟。为了解决这个问题,已经有多个方向的解决方案被探索了:Tez可以将定向无环图(dag)作为单个作业运行,从而减少启动作业的延迟;很快,使用传统的MPP DBMS运行时而不是mapreduce。Spark SQL依赖于Catalyst优化器将SQL查询转换为可在Spark通用引擎上执行的优化dag,其执行速度比MapReduce快得多。本文分析的Catalyst版本主要是基于规则的;自2.3.0发布以来,Catalyst利用了统计数据和一个简单的成本模型。例如,对于连接排序,成本函数根据返回的行数估计逻辑成本。
我们强调,我们提出的不是一个基于成本的优化器,而是一个成本模型。基于成本的优化器不必计算查询的全部成本,无论是绝对成本还是相对成本(例如,查询计划1优于查询计划2)。此外,基于成本的优化器实现查询计划转换(通常基于规则),该转换利用特定查询部分(例如,连接)的成本来做出选择并创建优化计划。相反,我们的成本模型根据Catalyst(即Spark查询优化器)提供的物理计划计算绝对查询成本(以秒为a单位)。在第6.5节中,我们证明了我们的成本模型返回的绝对成本足够精确,可以在可行的执行计划中选择最佳执行计划。关闭循环和更改实际的Spark计划不在本文的讨论范围之内。参考Hive[11],我们的成本模型与Hive优化器计算的成本之间的主要区别是:
-
Hive不计算整个查询成本,而是计算它正在优化的特定部分的成本。
-
Hive成本是在物理操作树上计算的,忽略了集群配置。因此。对于不同的集群和使用不同资源的执行,优化器的选择是相同的。
-
Hive对读写磁盘吞吐量做了更简单的假设,这些假设是固定的,并且不随磁盘上并发的进程而变化。
-
Hive优化器支持更大的SQL操作符集,例如UNION ALL和OUTER JOIN,这些操作符不能被建模为GPSJ。
相似性方面,我们采用了相同的Hive统计数据。特别是,Hive考虑表基数和属性基数,而不考虑属性值分布。Impala和Spark的优化器做出了类似的假设,除了Spark在其2018年版本(ver. 2.3.0)开始收集直方图[12]。与Spark不同的是,MapReduce的成本模型相关的研究工作和结果要多得多[13]。在[14]中,作者提出了MapReduce的分析模型,该模型除了考虑任务执行时间外,还考虑了并行执行造成的延迟:由于共享资源的占用而导致的排队延迟和由于任务之间的优先约束而导致的同步延迟。Herodotou[4]提出了一个性能模型来描述Hadoop 1.x中MapReduce作业的执行情况。这个性能模型描述了在更细粒度的map和reduce任务内的数据流和成本信息。根据Herodotou的模型,整个作业的执行时间是所有map和reduce阶段的成本之和,没有考虑同步和排队延迟。与前一个模型类似,我们的模型在重点考虑了单个执行阶段的细节,并通过考虑管道和资源争用来考虑排队和同步延迟。Spark SQL上下文中出现了许多差异:参考[14],任务之间的优先图来自输入中提供的查询的物理执行树,并且必须根据Spark如何实现SQL操作符来分析。考虑到Spark使用一组有限且已知的任务类型来执行GPSJ查询,并且DB统计数据是可用的,我们能够提供它们的详细建模。与[4]不同的是,我们不需要一个通用的工作概况来描述任务类型。这是因为,与一般的MapReduce作业不同,我们建模的SQL查询具有查询执行计划的详细描述,以及允许我们分析导出这些参数的DB统计信息。考虑到Spark使用一组有限且已知的任务类型来执行GPSJ查询,并且DB统计数据是可用的,我们能够提供它们的详细建模。与[4]不同的是,我们不需要一个通用的工作概况来描述任务类型。这是因为,与一般的MapReduce作业不同,我们建模的SQL查询具有查询执行计划的详细描述,以及允许我们分析导出这些参数的DB统计信息。
3 Background and Spark Basics
Spark是一个与Hadoop兼容的并行计算框架。Spark的架构由一个driver和一组executor组成。driver与集群资源管理器(Yarn)协商资源,并在executos之间分配。executors负责对数据执行操作。数据在整个集群中分布,并以弹性分布式数据集RDD的形式组织。一个RDD是一组不可变的分布式元素,被称为分区,可以被并行处理。分区可以来自于存储(HDFS),也可以是之前操作的结果(内存中)。Spark提供了一组丰富的操作符来操作后期的RDD。操作符可以分为transformation和action。transformation可以在每个RDD分区上的内存中执行,而action要么将结果返回给驱动程序,要么使用shuffle将分布在几个RDD分区中的数据组合在一起。除了RDD之外,Spark还引入了操作的lazy evaluation估概念,即Spark不会立即计算操作结果,但它会跟踪应用于RDD的操作序列,直到触发一个操作。Spark计算范式通过启用内存中的流水线(根据Volcano模型[17])来克服基于MapReduce的后续转换,这些转换不需要shuffle。
在最高的抽象层次上,Spark计算被组织在job中:job是在RDD请求action时创建的;它由称为stage的更简单的执行单元组成,通过有向无环图连接在一起。stage仍然是一个逻辑工作单元,因为它是由应用于输入RDD的transformation管道组成的。用于在每个RDD分区上执行一个stage的物理工作单元称为task。任务分布在集群上并并行执行。
Spark SQL[2]是Spark的模块,它可以对存储在Hadoop中的结构化数据执行SQL查询。它为数据提供了一个关系抽象层,并提供了一种类似sql的语言来查询数据。Spark SQL的核心是Catalyst[2],它是一个可扩展的优化器,负责将声明性SQL查询转换为一组jobs。给定一个SQL查询,Catalyst执行典型的优化步骤:分析和验证、逻辑优化、物理优化和代码生成。
物理优化创建一个或多个物理方案,然后选择最佳方案。在撰写本文时,这一阶段主要是基于规则的:它利用一个简单的代价函数,以便在可用的join算法中选择一个join算法[2]。Spark join算法值得特别提及,因为它们在GPSJ查询中非常重要:
-
Broadcast join:仅当要连接的两个表中的一个适合内存时才能使用。在这种情况下,较小的表被广播到每个执行器,以便每个任务都可以执行大表的分区与内存中可用的广播数据之间的join。
-
Shuffle join:两个表都在join属性上排序/hash,然后拆分为数据量固定的chunks。chunks保存在executors的本地磁盘上。当shuffle执行时,两个table中所有在join属性上有相同range的chunks会被传送到同一个reducer task上,在这个task中会验证join的谓词,并将过滤后的数据存回本地磁盘上。
我们的cost model针对一个给定的Spark物理执行计划(见图1)计算查询执行时间。通过组合三个基本SQL操作符:选择、连接和广义投影,成本模型涵盖了广泛的查询类别。这三个操作符的组合决定了在[3]中首次研究的GPSJ (generalized Projection/Selection/Join)查询。GPSJ是在一组在join x: psx上的selection s上的广义projection p。广义投影算子pP;M ðRÞ是消重投影的扩展,其中P表示关系R上的聚合模式,即group-by属性集,M表示应用于R中属性的聚合算子集。因此,GPSJ表达式扩展了具有聚合、分组和组选择的选择连接表达式。GPSJ查询是OLAP应用程序中最常见的查询类。这三种操作符并不是强制性的,因此我们的成本模型也涵盖了简单的选择查询和连接查询。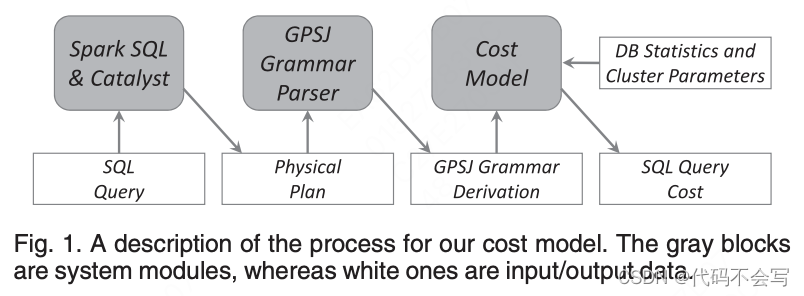
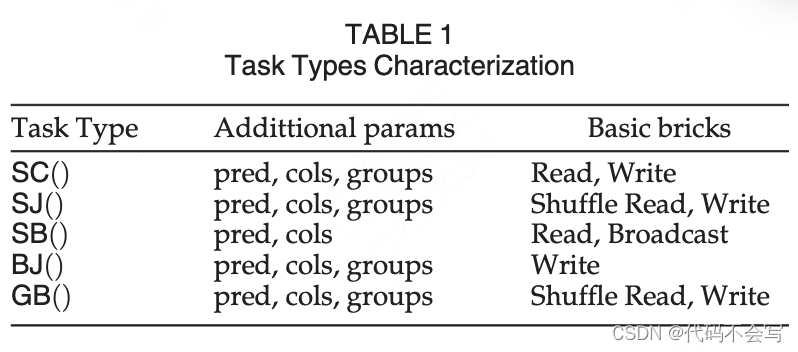
每一个用Spark物理执行计划建模的GPSJ查询都可以表示为一棵树,其节点将操作应用于一个或多个输入表,输入可以是物理的或是它的子树执行的结果。可行的树由图2所示的上下文无关的语法编码,我们称之为GPSJ语法。可行树(即GPSJ语法派生)可以由以下5种类型的task组成:
-
table scan SC()
-
table scan and broadcast SB()
-
shuffle join SJ()
-
broadcast join BJ()
-
group by GB()
SC()和SB()总是执行树里的叶子节点因为它们处理关系table所在的物理存储。SJ()和BJ()是树的中间节点,可以用来构建左深执行树。最后GB(),如果存在的话,会是最后一个执行的task。为了更清晰地描述,在图2中,我们省略了表征任务类型的参数,但不影响树的结构。表1列举除了这些参数:pred是一个可选的filterng/join谓词,cols是实际检索的列的自己,groups表示一个通用projection操作的group-by集合。SC(),SJ()和BJ()可以执行grouping因为Catalyst可能会出于优化的目的将GB()下推。这个语法定义了task执行的pipeline。特别是,如图2所示,SC()、SJ()和BJ()的最后一个参数是一个名为pipe的boolan值。当pipe设置为true时,task不会将数据回写到磁盘,因为父任务类型可以在pipeline中执行。pipeline任务类型只能在broadcast join之前使用,因为所有其他的任务类型要么对应于树的叶子节点(SC、SB),要么需要shuffle(GB、SJ)。在GPSJ语法中,类似的约束是通过使用<Expr3>实现的,它只会作为SB的参数。

Example 1. 下面的GPSJ查询来自于TPC-H benchmark,是我们用来测试的benchmark之一。这个查询统计特定细分市场在给定时间内的总收入,并针对单个订单和发货优先级进行分组。
图3为Catalyst选择的Spark物理执行计划的一个图形化表示。这个树是一个GPSJ语法派生。每个树的节点对应于一个应用到节点子树产生的关系表的任务类型。
在被选择的物理执行计划中,orders和customer(N1和N2节点)是通过一个SC()任务类型从HDFS中初始化的,该任务还在shuffle-writing数据到executor磁盘之前对数据执行了filter和project。N3执行了两表的shuffle join。同样的join类型在N5中也使用了,其中从N3来的结果再一次和N4中从HDFS中检索、filter和project得到的lineitem执行了join。N5中每一个RDD分区结果也本地基于l_orderkey和o_orderdate执行了一次本地的分组,来减少最后一个算子的开销(group-by的push down减少了需要shuffle的数据量)。通用的projection(即group by)在最终的N6节点执行。

我们需要重申一下,包含n个table的GPSJ查询的物理执行计划树最多有2n个节点。n个节点(SC或是SB)需要用来访问表,n-1个节点(SJ或是BJ)需要join table,最后一个GB节点可能会用来执行Group by子句。由于Spark只会生产左深树,树的深度最多为n+1,左深树会生产最深的物理执行计划书,如果是平衡树则深度会减少到[log2(n)] + 1。
4 Cost Model Basic Bricks
对于基于网络和磁盘访问成本的模型来说,精确地对transformation和action进行建模会导致不必要的复杂性。出于这个原因,我们将重点放在一组basic brick上,它们在GPSJ查询计算中使用并决定成本。值得注意的是,这些bricks的抽象层次甚至低于transformation和action。每个brick对单个RDD分区上的操作执行进行建模,同时仍然考虑并行执行所带来的资源争用。Basic Brick与sql无关,只需要知道Spark和集群参数(参见表2)。第4.2到4.5节描述了每个brick的执行成本,并为它们定义了一个成本函数。
4.1 Cluster Abastraction and Cost Model Parameters
如图4所示,一个集群由均匀分布在R个机架上的N个节点组成,每个节点有C个cores。假设所有的机架/节点在硬件上是等价的。数据以block为单元存储在HDFS文件系统上,其冗余因子为rf(默认为3)。磁盘的吞吐量在精确计算执行时间方面起着核心作用,它通过两个函数来建模:![]()
和![]()
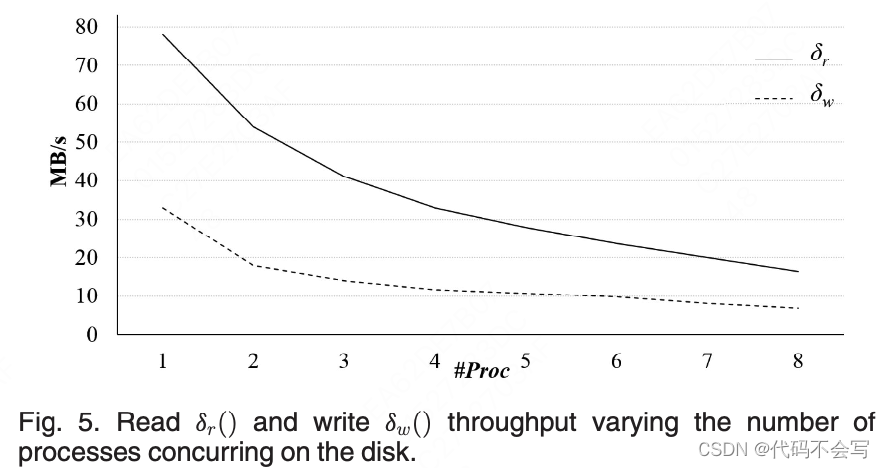
,以MB/s为单位返回每个进程的吞吐量。函数值是通过必须在每个集群上执行的调优测试获得的。特别是,我们考虑了从磁盘加载数据并使它们在RDD中可用以进行进一步处理所需的总时间,以便磁盘吞吐量隐式地包含用于序列化和解压缩的CPU时间。图5显示了我们用于测试的两个集群之一的两个函数的值。由于(共享)磁盘资源的争用,读写数据的进程数量增加,读/写吞吐量降低。
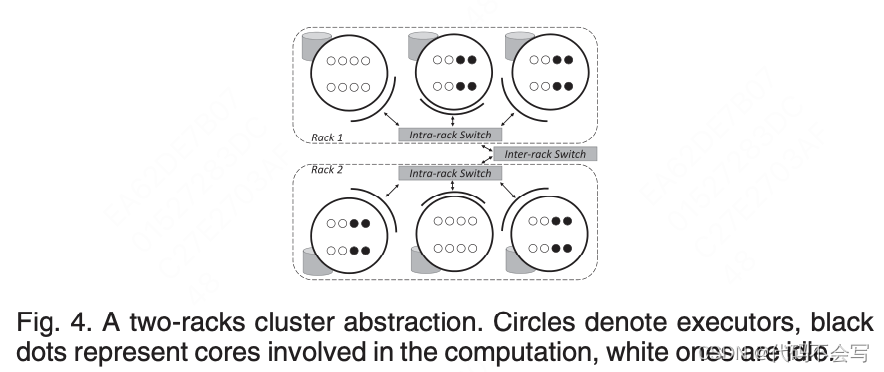
集群中的节点通过网络连接,我们采用了一个对于每个连接都有带宽限制的端到端的网络模型。和磁盘行为类似,网络吞吐量也依赖于在一组节点时间并发传输的进程数。可以假设机架内网络速率(IntraRSpeed)高于或等于机架间网络速率(ExtraRSpeed)。网络每进程吞吐量的公式为:
需要注意的是网络和磁盘的性能都需要在节点级别计算,而不是以core级别,因为它们可以利用在同一节点上的所有core资源。
每一个运行在集群上的Spark应用都有自己的一组资源和参数。在我们的模型中,我们假设,资源一旦分配后就不能在执行过程中修改。需要定义的两个主要资源是executor的个数(#E)和每个executor上core(#EC)的数量。每一个应用都会有一个应用driver,它运行在集群中和executor不一样的节点上。处于确定shuffle执行时长的考虑,我们同样会考虑shuffle buckets的数量#SB(默认#SB=200)。我们最后会假设每个shuffle的bucket在读取时正好适配executor的内存,这样数据就不需要再溢出到磁盘了。
由于RDD partition的数量通常比计算可用的core数量高,资源管理器会在多个wave中在core上调度task。
定义1(Wave):wave代表以相同方式并行执行的task集合,executor中的每个core执行一个task。每个task会处理一个不同的RDD分区。同一个wave中所有的执行应该具有相似的行为。
很明显,由于所有的执行core在wave期间并行工作并且行为相似,因此运行wave所需的时间可以估计为在单个内核上运行任务所需的时间。
4.2 Read
由于Spark执行了数据本地性策略,它总是会从最近的位置加载RDD分区。当执行器从本地磁盘、从同一机架的节点磁盘或从不同机架的节点磁盘读取RDD分区时,读取时间会有所不同。Read(Size, X)基于给定的Size计算RDD分区的读取时间,且依赖于数据存储位置X。X∈{L, R, C}分别代表本地Local、机架Rack和集群Cluster。一方面,如果数据是本地读取的,则不需要通过网络传输,另一方面,对于机架和集群的访问,必须考虑传输时间。由于磁盘读取和数据传输是pipeline的,所以总体时间是这两个组成成分的最大值。
Read(Size, X) = MAX(ReadTx; TransTx)
在本地wave中,RDD分区从本地磁盘读取,没有数据会进行网络传输(即,TransTl=0)。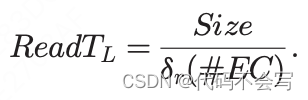
ReadTl是一个core从进程吞吐量为![]()
的本地磁盘读取一个大小为Size的RDD partition所需要花费的时间。ReadTl考虑了在同一个executor上的多个#EC导致的磁盘资源竞争。
在一个rack wave中,每个executor core从它机架的一个不承载executor的节点上接收一个RDD partition(即,#RN-#RE nodes)。executor的磁盘不涉及,因为,如果请求的RDD分区的副本存储在它上面,那基于数据本地性原则,它会在一个local wave中被读取。如果所有的节点都有executor,那么所有的wave都会是local的。在5.2小节中,我们建立了一个local/rack/cluster wave的概率模型。
平均每个非executor节点会服务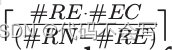
个请求,其中#RE*#EC是rack中并行执行的进程/core的数量。因此: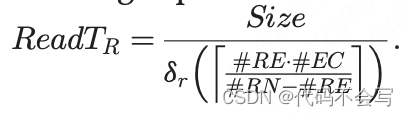
在rack和cluster wave中,必须考虑网络开销。特别地,在一个executor上执行rack wave,它的每一个#EC core都会从rack中#RN-#RE非执行器节点上接收到一个RDD partition。假设RDD partition在机架节点中均匀分布,共享节点之间连接的core的数量限制为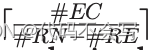
。因此,在每一个网络连接中传输数据所需的时间为: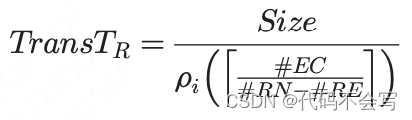
Example 2. 在如图4所示的集群中。#R=2,#RN=3, #RE=2, #EC=4。在一次rack wave中,每一个core精确地从唯一的非executor节点读取一个本rack中的RDD partition。因此,这样的节点负责从其磁盘获取8个分区。每个进程的磁盘吞吐量为:
回顾4.1节讨论的网络模型,节点通过点到点的连接连接在一起,每一个连接都有固定的带宽限制。没有分配executor的节点,一旦读取了这8个RDD分区,就会将数据传递给同机架中2个分配了executor的节点。每个进程的网络吞吐量为: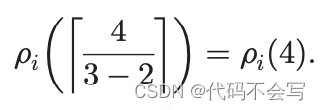
一个类似的模型可以被应用到cluster wave,其中每个没有executor的节点可能会接收到一个其他机架中executor中所有core的请求(即,(#R-1)*#RE*#EC)。这些请求实际上会分配到当前rack以外的,没有承载executor的(#R-1)*#RE*#EC个节点上。没有承载eecutor的节点上每个进程的磁盘吞吐量为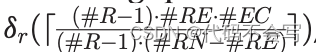
,因此访问磁盘所需的时间为: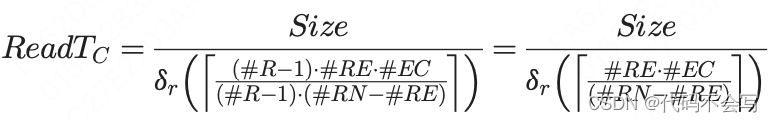
在cluster wave期间,#EC个partition并行地从集群中其他机架的不承载executor的(#R-1)*#RE*#EC个节点传输而来,因此core共享的节点到节点的网络连接的限制为![]()
。每一个独立的网络连接所需要的传输数据的时间为: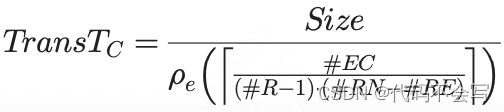
4.3 Write
一旦在内存中读取和处理完成,每一个RDD partition都会写回到本地磁盘。Write(Size)计算了每个executor写Size MB数据到磁盘所需要的时间。磁盘写的吞吐量取决于executor core的数量。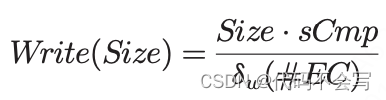
该公式嵌入了数据保存到磁盘之前执行的压缩而导致大小所见的比例(例如,sCmp=0.6)。这是Spark中的一个配置选项。
4.4 Shuffle Read
当执行Shuffle read时,Spark会生成#SB任务,它负责处理shuffle write阶段产生的#SB buckets。每一个bucket均匀地分布在executor上,即,每一个executor会存储bucket的一部分。SRead(Size)将读取一个独立的Szie MB大小的bucket所需的时间进行了建模。
数据bucket的读取和传输到executor的过程是pipeline执行的,因此,对应于Volcano模型,加载时间是这两项操作所需时间的最大值。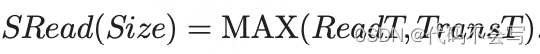
我们强调,所有且仅包含executor的集群节点参与shuffle read。每个执行器都以相同的方式运行,由于没有数据副本,因此无法应用数据本地性。此外,每个bucket都是在全部executor中分布的。每个executor会为每个bucket存储ExecBucketSize=Size/#E MB的数据。每一个core向所有executor并行请求bucket部分,且每个executor必须满足大小为ExecBucketSize的#E*#EC(#EC来源于local cores,(#E-1)*#EC来源于远程cores)个请求。考虑到请求的并行性,读取时间为: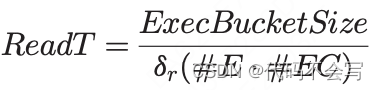
至于网络时间,我们再次强调,每个executor的角色是对等的,每个节点到节点的连接由#EC个进程共享(即,每个executor的core请求所有其他executor的bucket部分)。由于同样的原因,每个连接上发送和接收的进程数相同,因此发送和接收的时间相同。假设机架间网络速度低于机架内网络速度,我们可以使用机架间网络吞吐量来约束完成传输所需的时间,除非所有的v个executor都分配在同一机架中。这是有概率发生的:
如果executor的个数大于一个rack中节点的个数,那么概率为0。如果不是这种情况,那么概率模型给出了集群中有#RN个节点的机架分配v个executor的概率。
因此,传输时间可以按以下公式计算: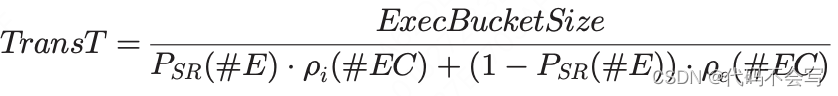
Example 3. 在一个#R=2, #RN=3, #E=2的集群中,2个executor被分配到同一个机架的概率为: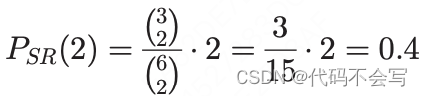
其中3和15分别是executor分配到单个rack和整个集群的分配方法总数。
4.5 Broadcast
在一个RDD(a)上的broadcast分为两个步骤:
-
在应用driver上collect RDD的所有分区,每个分区的大小为Size
-
将整个RDD发送给executor以供后续计算
完成一次broadcast所需的时间是所有步骤的时间加和,因为只有当整个RDD加载到应用程序驱动程序上时,它才会将RDD发送回执行程序。
Broadcast(Szie) = CollectT + DistributeT
#E*#EC个分区可以并行collect(即,每个executor core执行一个),且每个node-driver的网络连接被#EC个进程共享。和shuffle read的场景类似,网络吞吐量可以通过机架间的网络限制,除非executor和应用driver都在同一个cluster中实例化。CollectT可以按一下公式计算: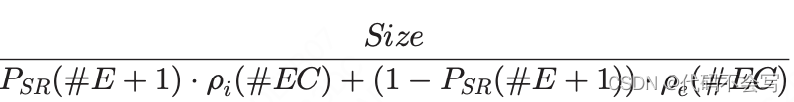
对应于broadcast中的第二步,从cost model的角度来看,我们需要针对#E*#EC(即,并行collect的所有数据)个RDD分区的分发cost。由于application driver会给每一个节点发送collect到的数据,因此每个网络连接上只有一个进程是active的。DistributeT可以按以下公式计算: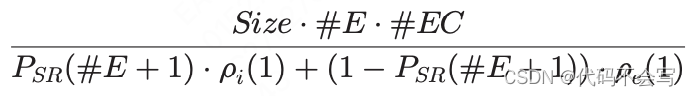
DistributeT不是分发整个RDD所需要的时间,而是将collect到的数据分布到wave中的时间。正如我们在5.3节展示的,我们始终使用这样的值来计算总时间。
5 Modeling GPSJ Queries
在本节中,我们将描述如何用前一节描述的basic bricks来建模GPSJ查询执行计划。执行时间对物理执行计划树上的节点执行时间进行了加和。每个节点对应于一个任务类型,每个任务类型对应于一个特定的cost function(见5.2-5.6小节),这个function返回cost以及输出的关系表的features。树的深度遍历保证了计算节点时其输入表的feature就绪。1
5.1 Statistics and Selectivity Estimates
创建cost model需要从DB收集统计信息来确定谓词的选择率和table大小。这一类topic的文献非常广泛。estimate的准确性严格取决于所收集到的信息和对数据分布做出的假设。根据集中查询cost model,本文假设属性值的一致性、属性值的独立性和join containment[19](join predicates和独立predicates之间的相关性,simple containment=具有相关性,base containment=不具有相关性)。
一个表t包含一组属性t.Attr。对于每个表我们会收集它的基数t.Card和它的未压缩文件格式下的大小t.Size。我们同样会收集基于压缩文件格式的平均大小所见fcmp,和存储表是HDFS partition的平均大小t.PSize。尽管partition size是一个HDFS参数(通常是128MB,这里是partition还是bucket???),它的实际大小可能变化很大,当表很小或者通过Spark命令创建表并且没有进行压缩时,它的实际大小可能比理论大小小得多。
对于每一个属性a∈t.Attr,我们会收集它的distinct value a.Card,以及它的平均长度a.Len,单位为bytes。基于前面的统计信息,并考虑论文[21]和[5],我们可以推断出conjunctive selection predicate Sel(t, pred)的选择率、equi-join![]()
的基数JCard(t1, t2, pred)和大小JSize(t1, t2, pred)
我们同样能推断在属性cols ∈ t.Attri上的projection Proj(t, cols)的长度缩短百分比。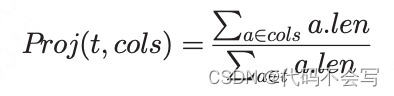
利用Cardenas公式可以得到由广义投影(即包含分组因子)引起的基数减少的估计
例如,在一个表t上,先执行一个过滤谓词pred,再基于group进行分组,可以被定义为: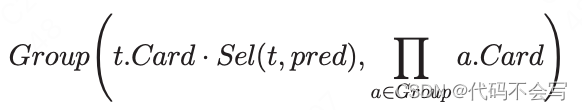
Sel()、Proj()、Group()如果对应的参数没有被设置的话,默认为1。
5.2 The SC() Task Type
一个Scan task会访问存储在HDFS上的表t。函数SC(t, pred, cols, groups, pipe)返回执行任务所需要的时间。此任务类型执行的基本操作如下:
-
获取t存储在内存中的RDD分区。过程包括访问HDFS来检索RDD分区,并将它们发送给负责处理的executors。只有在数据不在executor本地时才需要通过网络传输数据,由于Spark采用了Volcano风格的pull模型,因此sacn时间是访问和传输时间中的最大值。
-
基于谓词pred对表元组进行过滤(可选)。由于Catalyst执行了selection push down,一旦元组对于后续的计算不再有用,就会执行过滤。如果文件格式支持过滤,Spark会将过滤下推到源文件层,根本不会读取不需要使用的元组。
-
通过丢弃不需要的列来执行Project(可选)。由于Catalyst有projection push down,因此每当一列对进一步计算不再有用时,就会执行列对齐。当底层文件格式(例如Parquet)支持时,Spark可以将projection推入源文件,在这种情况下,根本不会读取未使用的列。
-
当Catalyst下推广义投影来减少后续处理的数据量时,执行Aggregating(可选)。
-
将剩余的元组(可选)写入磁盘,以便进一步细化或保存最终结果。当broadcast join是pipeline时(即管道=T),可以避免写入。
根据我们的cost model,只有1、4操作必须直接建模,而2、3会影响性能因为它们减少了要写回磁盘的数据量。
构成表t的RDD分区数量为: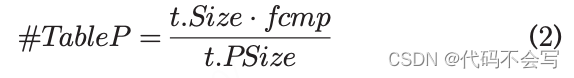
如果表是以压缩格式存储那么 0 < fcmp < 1,否则fcmp=1。每一个RDD分区都对应着从磁盘获取的RSize=t.Psize的bytes。当filter和projection被下推到数据源时,每个RDD分区需要读取的数据量会减少为 RSize=t.PSize * Sel(t, pred) * Proj(t, cols)。
数据获取会在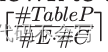
个waves中执行。我们区分了3种类型的waves,即L-local,R-rack,C-cluster,这取决于要处理的RDD分区的存储位置,和负责获取它的执行器。给定一个RDD分区p,执行器需要在本地的(PL)、在其机架(PR)或其他任何地方(PC)获取p的概率取决于集群拓扑,可以通过以下公式计算:
在公式3中,比值给出了executor被安排在集群中没有存储p副本的节点上的概率,分母为整个集群上分配的executor的数量。在公式4中,x∈{1,...,min(#R, rf)}是有至少一个p的副本rf在其任意节点上的rack的数量,y∈{1,...,min(#R, #E)}是有至少一个executor的rack的数量。比值给出了y个机架在#R-x个机架上的分配率(即节点中没有p的副本的机架),分母是在y机架上分配的总数。这样的比值必须考虑x机架分配到rf副本之一的概率p(即,Ppart(x)),以及y机架至少分配到一个executor(即,Pexe(y))。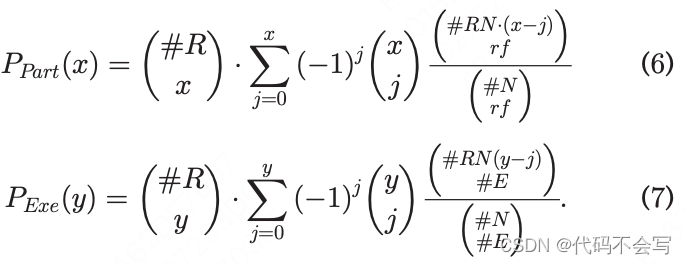
公式6中,采用了inclusion-exclusion原则,来计算给定x个机架,至少包含一个rf副本的概率p。这个概率再乘以(#R x),因为选择任何x个机架概率都相同。
一旦一个RDD分区被读取,操作2到4会在它的元组上执行,且WSize bytes会被写回到磁盘,其中
如果不需要执行grouping,那么数据的读写都可以pipeline执行,否则写只能在所有的数据加载且分组之后才能执行。前者的执行时间是读和写时间的最大值。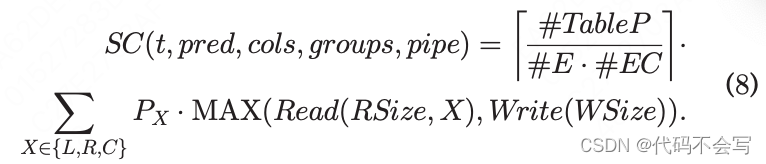
在第二种场景,两个时间需要进行加和。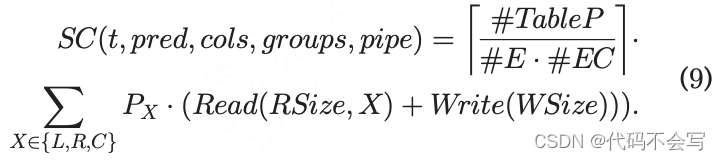
在公式8和9中,如果数据一定不会写到磁盘上(即,pipe=T),那么WSize=0。
表3列举了结果值表t'的features。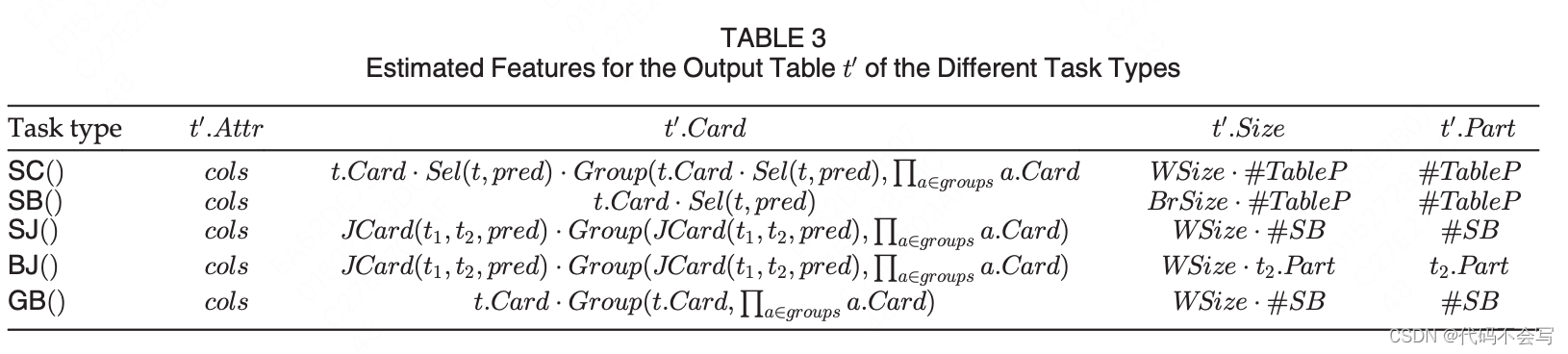
5.3 The SB() Task Type
一个Scan&Broadcast任务访问一个存储在HDFS中的表t并将它发送给应用driver来collect RDD分区,并将整个表发送给所有的executors。函数SB(t, pred, cols)返回执行所需的时间。
数据获取步骤是和SC()任务类型一样的。我们引用前面的公式2-5来进行建模。每个需要广播的RDD partition的size可能会被filter和projection predicates减少: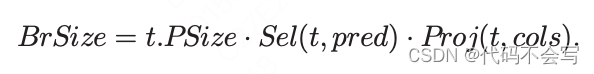
注意,由于数据的filter和projection要么发生在内存里或是直接读取磁盘的时候,它们不会直接影响task cost。由于数据获取和广播是pipline执行的,执行时间是:
参考表3。
5.4 The SJ() Task Type
Shuffle Join会执行两个表t1和t2的join,它们的分区已经预先被hash到了#SB个buckets中。输入RDD分区存储在executor的本地磁盘中。函数SJ(t1, t2, pred, cols, groups, pipe)返回执行该任务所需要的时间。在一个wave中SJ()任务执行的操作是:
-
Shuffle Read:获取t1和t2对应的buckets。bucket存储在executor所在节点。
-
Join:一旦t1和t2的对应buckets都完全可用,pred谓词就会用来合并元组
-
Project(optional):在接下来的查询中无用的列会被丢弃掉。只有cols中的列才会被返回
-
Aggregating(optional):为了减少在进一步处理中需要处理的数据量,聚合Catalyst下推广义投影时的元组。
-
Writing(optional):往磁盘里写入剩余的元组。当broadcast join是pipeline执行时,没有写操作。
在相应buckets的所有元组加载之前,Join不能启动。因此,执行一个wave所需的时间是shuffle读取和写回(如果需要的话)处理过的元组所需时间的总和。
每一个wave要读取的数据量为: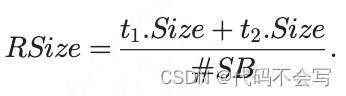
每个core在每个wave中写回磁盘的数据量为:
如果数据不写回磁盘那么WSize=0。整体的时间是所有wave所需时间的加和: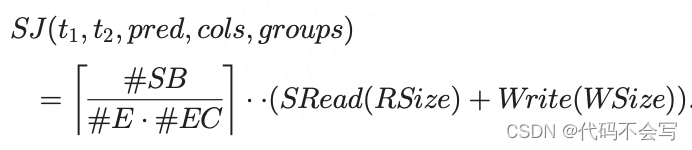
参考表3。
5.5 The BJ() Task Type
Broadcast join执行两个表t1和t2的join,前提是当其中一个表,假设是t1小到可以广播且完全保存在executor的内存中时。函数BJ(t1, t2, pred, cols, groups, pipe)返回执行该任务需要的时间。就我们模型的目的而言,唯一相关的操作是将数据写回磁盘。这是因为加载这两个表的成本已经在执行树上的子节点上被衡量了。基于GPSJ语法(见图2):t1是通过SB()任务类型加载的,而t2要么是由之前的操作(即SJ(), BJ())生成的,或是通过SC()操作加载进来的。和shuffle join filtering类似,projection和grouping可能会选择性地在内存中执行。
Broadcast join总是通过pipeline连接到其他操作,scan,shuffle join或是broadcast join,因此它需要的wave数量取决于t2的分区数量。每个core在每个wave中写入的数据量为:
完成此操作所需要的时间是wave所需时间的加和
参考表3。
5.6 The GB() Task Type
Group by执行最后的分组。输入表t的元组之前已经被hash到了#SB个buckets。输入RDD分区存储在executor的本地磁盘上。函数GB(t, pred, cols, groups)返回执行任务所需要的时间,GB()任务的操作如下:
-
从表t执行Shuffle Read对应的buckets。每个bucket的部分都存储在每个executor上
-
基于groups属性进行分组并对于cols-groups剩下的列进行聚合。
-
聚合元组回写到磁盘上
Grouping操作在所有对应的buckets都加载完之前不能启动。因此,执行一个wave所需要的时间是shuffle reading和writing处理后元组的时间加和。每一个wave需要读取的数据量为: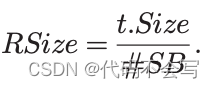
每个wave需要写回到磁盘的数据量是: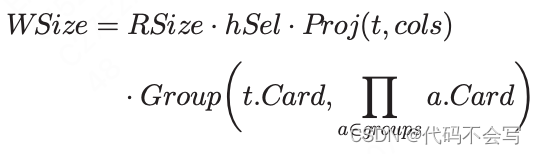
其中hSel是一个对于所有子句的常量选择率因素(hSel默认为0.33);如果没有pred,hsel会被设置为1。尽管这个简单的估计通常和实际的选择率不同,但它是商业系统的标准解决方案。精确的估计意味着与我们的框架不一致的假设[23]。总的时间是所有wave所花时间的总和:
参考表3.
5.7 Handling Stragglers
到目前为止提供的计算GPSJ查询成本的cost model假设集群资源足以运行工作负载,不会发生任何掉队查询。straggler是指由于分配的资源不足而导致任务比同类任务执行的更差的任务。掉队概率与集群/节点的负载以及相应的资源争用程度密切相关。我们强调,我们的模型在定义网络和磁盘吞吐量时考虑了资源争用,但当资源不足时,性能可能以不可预测的方式降低。论文[25]已经研究了几种技术来减少和防止掉队效应。Spark本身实现了一种推测执行技术,即在不同的节点运行一个可能是掉队任务的副本,结果将从第一个结束的任务中获取。
为掉队任务构建一个分析模型的挑战是很大的,受限于task-node和task-task之间交互的复杂性,因此我们的模型会通过向基本任务成本估计中添加一个基于调度配置信息为每个任务类型TT∈{SC, SB, SJ, BJ, GB}计算的额外成本,来考虑调度任务。构建配置信息需要收集给定任务类型TT的一组task的执行时间。Load定义了用于执行任务的资源数量,以集群executor的百分比为单位,Load.Ex=#E/#N,executor cores Load.C=#EC/#C。
定义2(Straggler)一个task ![]()
如果满足一下条件那么我们就称之为straggler:![]()
β代表straggler的sensitivity。