原文地址:building-a-u-net-with-tensorflow-and-keras
2024 年 4 月 11 日
计算机视觉有几个子学科,图像分割就是其中之一。如果您要分割图像,则需要在像素级别决定图像中可见的内容(执行分类时),或者从像素级别的图像中推断相关的实值信息(执行回归时)。
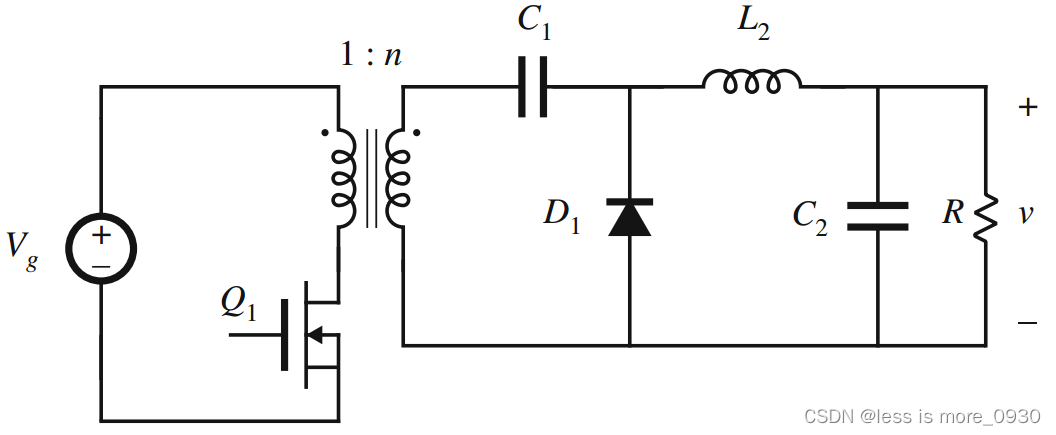
图像分割社区中最著名的架构之一是U-Net。全卷积架构以其形状命名,首先收缩图像,然后扩展为结果。虽然此收缩路径构建了学习特征的层次结构,但跳跃连接有助于将这些特征转换回扩展路径中的相关模型输出。
虽然您可以通过单击此链接了解有关 U-net 架构的更多信息,但本文重点介绍实际实现。我们将学习从头开始构建U-Net架构。将使用 TensorFlow 和 Keras 来完成此操作。首先,我们将简要介绍 U-Net 的高层组件。接下来是实施 U-Net 的分步教程。最后,我们将从头开始在 Oxford-IIIT Pet 数据集上训练网络,展示可以实现的目标以及如何进一步改进。
所以,读完本教程后,您将了解:
- U-Net 架构是什么以及它的组件是什么。
- 如何使用 TensorFlow 和 Keras 自行构建 U-Net。
- 通过实施您可以实现哪些绩效以及如何进一步改进。
什么是 U-网络?
当你向计算机视觉工程师询问图像分割问题时,很可能会在他们的解释中提到 U-Net 这个术语。U-Net 因其形状而得名,是一种卷积架构,最初由 Ronneberger 等人(2015 年)提出,用于生物医学领域。更具体地说,它用于细胞分割,与该领域以前使用的方法相比,效果非常好。
U-Net 由三个组件组组成:
- 收缩路径。在下图左侧可以看到,卷积层和池化层用于对图像进行缩样,有时甚至可以将图像缩小一半。收缩路径学习不同粒度的特征层次。
- 扩展路径在右侧,你会看到一组上采样层(无论是简单的插值层还是转置卷积层),它们会对输入图像的分辨率进行上采样。换句话说,网络会尝试从缩小的输入构建更高分辨率的输出。
- 跳过连接 除了将低层特征图作为上采样过程的输入外,U-Net 还接收来自收缩路径同层的信息。这样做是为了缓解 U 网最底层的信息瓶颈,如果不通过跳转连接使用,就可以有效地 "丢弃 "来自高层特征的信号。
请注意,在最初的 U-Net 架构中,输出的宽度和高度低于输入的宽度和高度(572x572 像素对 388x388 像素)。这种情况源于架构,可以通过使用其他默认架构(如 ResNet)作为主干架构来避免。
有了 U-Net 这样的架构,就可以学习对特定图像重要的特征,同时利用这些信息生成更高分辨率的输出。代表像素级类别索引的地图就是这样的输出。通过进一步阅读,你将学会如何构建 U-Net!

使用 Tensorflow 和 Keras 构建 U-Net
现在,你已经了解了 U-Net 的高级工作原理,是时候构建一个了。打开集成开发环境,创建一个 Python 文件(如 unet.py)或打开一个 Jupyter Notebook。同时确保已经安装了接下来的先决条件。然后我们就可以开始编写代码了!
先决条件
要运行代码,你必须在环境中安装一些依赖项。
首先,你需要最新版本的 Python 3.x。
此外,你还需要 tensorflow 和 matplotlib。这些都可以通过 pip 包管理器安装。安装完成后,你就可以开始使用了!
导入
import os
import tensorflow
from tensorflow.keras.layers import Conv2D,\
MaxPool2D, Conv2DTranspose, Input, Activation,\
Concatenate, CenterCrop
from tensorflow.keras import Model
from tensorflow.keras.initializers import HeNormal
from tensorflow.keras.optimizers import schedules, Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.utils import plot_model
import tensorflow_datasets as tfds
import matplotlib.pyplot as pltU-Net 配置定义
在我看来,将各种配置选项分散在整个模型中是一种糟糕的做法。相反,我更喜欢将它们定义在一个定义中,这样我就可以在整个模型中重复使用它们(如果我需要将模型部署到生产环境中,我可以通过一个 JSON 环境变量提供我的配置,该变量可以很容易地作为 dict 读入 Python)。下面就是配置定义的样子。下面,我们将讨论组件:
'''
U-NET CONFIGURATION
'''
def configuration():
''' Get configuration. '''
return dict(
data_train_prc = 80,
data_val_prc = 90,
data_test_prc = 100,
num_filters_start = 64,
num_unet_blocks = 3,
num_filters_end = 3,
input_width = 100,
input_height = 100,
mask_width = 60,
mask_height = 60,
input_dim = 3,
optimizer = Adam,
loss = SparseCategoricalCrossentropy,
initializer = HeNormal(),
batch_size = 50,
buffer_size = 50,
num_epochs = 50,
metrics = ['accuracy'],
dataset_path = os.path.join(os.getcwd(), 'data'),
class_weights = tensorflow.constant([1.0, 1.0, 2.0]),
validation_sub_splits = 5,
lr_schedule_percentages = [0.2, 0.5, 0.8],
lr_schedule_values = [3e-4, 1e-4, 1e-5, 1e-6],
lr_schedule_class = schedules.PiecewiseConstantDecay
)- 回想一下,数据集必须分成训练集、验证集和测试集。训练集是最大的也是最主要的数据集,可以让你在训练过程中进行前后传递和优化。但是,由于你已经看过这个数据集,因此在训练过程中会使用验证集来评估每个历时后的性能。最后,由于模型最终也可能在验证集上过拟合,因此还有一个测试集,但在训练过程中根本不会使用。相反,测试集用于模型评估,以确定模型是否能在未见过的数据上表现良好。如果能做到这一点,那么它也更有可能在现实世界中发挥作用。
- 在模型配置中,data_train_prc、data_val_prc 和 data_test_prc 用于表示特定分割结束的百分比。在上面的配置中,80、90 和 100 表示 0-80% 的数据集将用于训练,80-90%(即总共 10%)用于验证,90-100%(也是 10%)用于测试。稍后你会发现,以这种方式指定数据集是很有好处的,因为 tfds.load 允许我们重新组合两个数据集(训练/测试),并将它们分成三个!
- 第一个 U-net 卷积块生成的特征图数量为 64。你的网络将总共由 3 个 U-Net 块组成(上面的草图有 5 个,但我们发现 3 个在此数据集上效果更好),并在最终的 1x1 卷积层中生成 3 个特征图。之所以设置为 3,是因为我们的数据集有三种可能的类别可以分配给每个像素,换句话说,它应该等于你的数据集中的类别数。
- 输入图像的宽度和高度均为 100 像素。输入图像的维度为 3 个通道(RGB 图像)。
- 输出掩码的宽度和高度为 60 像素。事实上,在最初的 U-Net 架构中,输入和输出的尺寸并不相等!
- 在模型方面,我们使用了亚当优化器、稀疏分类交叉熵和 He normal 初始化。对于 Adam 优化器,我们使用了一种名为 PiecewiseConstantDecay 的学习率计划。该计划可确保学习率在经过预定的训练时间后设置为预先设定的值。我们从 3e-4(即 0.0003)的学习率开始,在训练时间达到 20%、50% 和 80% 后,学习率分别降至 1e-4、1e-5 和 1e-6。降低学习率可以帮助你更好地达到最佳状态。
- 在训练方面,我们生成 50 个像素的批次,以 50 个缓冲区的大小进行洗牌,并对模型进行 50 次训练。
- 作为附加指标,我们使用准确率。
- 我们的数据集位于当前工作目录下的 data 子文件夹中。5 个子文件夹用于验证。
- 在使用不平衡数据集进行训练时,最好为目标预测分配类权重。这将使代表性不足的权重更加重要。
U-Net 构建模块
回顾一下,U-Net 是由一个收缩路径和一个扩展路径组成的,前者本身是由卷积块构建的,后者则是由上采样块构建的。在每一层中(除了收缩路径的最后一层,它与扩展路径的首层相连),卷积块的输出通过跳转连接与上采样块相连。
我们将首先构建一个卷积块,并在收缩路径中创建多个卷积块。然后,对上采样块和扩展路径进行同样的操作。
卷积块
下面是 conv_block 的结构:
'''
U-NET BUILDING BLOCKS
'''
def conv_block(x, filters, last_block):
'''
U-Net convolutional block.
Used for downsampling in the contracting path.
'''
config = configuration()
# First Conv segment
x = Conv2D(filters, (3, 3),\
kernel_initializer=config.get("initializer"))(x)
x = Activation("relu")(x)
# Second Conv segment
x = Conv2D(filters, (3, 3),\
kernel_initializer=config.get("initializer"))(x)
x = Activation("relu")(x)
# Keep Conv output for skip input
skip_input = x
# Apply pooling if not last block
if not last_block:
x = MaxPool2D((2, 2), strides=(2,2))(x)
return x, skip_input根据 Ronneberger 等人(2015 年)的论文,每个卷积块都由两个 3x3 卷积块组成,每个卷积块的输出都经过 ReLU 激活。根据配置,使用 He 初始化(因为我们使用 ReLU 激活)。
从上图可以看出,在每一级,卷积块中的卷积输出都会作为跳过连接传递到相应级别上采样块中的第一个上采样层。
最大池化应用于相同的输出,以便下一个卷积块可以使用该输出。

在上面的代码中,我们可以看到卷积层的输出被分配给了 skip_input。随后,如果这不是最后一个卷积块,你会看到 MaxPool2D 被应用,池大小为 2x2,步长为 2。
处理后的张量 x 和跳转连接 skip_input 都会返回。请注意,这也发生在最后一层!重要的是我们如何处理返回的值,你会发现在创建完整的收缩路径时,如果是最后一层,我们就不会使用跳转连接。
收缩路径和跳转连接
让我们创建另一个名为 contracting_path 的定义。在这个定义中,你将构建属于收缩路径的卷积块。根据你上面的代码,这些卷积块将在它们的层次结构中执行特征学习,然后执行最大池化,使 Tensors 为下一个卷积块做好准备。
在最初的 U-Net 中,在每个 "下采样步骤"(即最大池化,虽然严格来说,常规卷积也是下采样步骤),特征通道的数量都会翻倍。
在创建收缩路径时需要考虑到这一点。这就是为什么要使用实用函数 compute_number_of_filters(下一步将定义该函数)来计算每个卷积块中使用的滤波器数量。如果起始滤波器数为 64 个,那么对于今天构建的 3 块 U-Net 而言(根据模型配置),滤波器数将分别为 64、128 和 256 个。对于 Ronneberger 等人(2014 年)的原始 5 块 U-Net 而言,则是 64、128、256、512 和 1024。
接着,创建一个列表,用于存储卷积提供的张量。它可以作为跳转连接的容器。
现在,是创建实际数据块的时候了。通过使用 enumerate,你可以创建一个输出(索引、值)的枚举器,然后创建一个 for 循环,提供块编号(索引)和特定块中过滤器的数量(block_num_filters)。在循环中,你要检查它是否是最后一个块,并让输入通过卷积块,根据卷积块的级别设置滤波器的数量。
然后,如果不是最后一个区块,则将 skip_input 添加到 skip_inputs 容器中。
最后,我们将同时返回 x(现在已经通过了整个收缩路径)和在此过程中产生的 skip_inputs 跳转连接张量。
def contracting_path(x):
'''
U-Net contracting path.
Initializes multiple convolutional blocks for
downsampling.
'''
config = configuration()
# Compute the number of feature map filters per block
num_filters = [compute_number_of_filters(index)\
for index in range(config.get("num_unet_blocks"))]
# Create container for the skip input Tensors
skip_inputs = []
# Pass input x through all convolutional blocks and
# add skip input Tensor to skip_inputs if not last block
for index, block_num_filters in enumerate(num_filters):
last_block = index == len(num_filters)-1
x, skip_input = conv_block(x, block_num_filters,\
last_block)
if not last_block:
skip_inputs.append(skip_input)
return x, skip_inputs实用功能:计算特征图的数量
在 contracting_path 定义中,你使用了 compute_number_of_filters 来计算特定卷积块中必须使用的滤波器数量/必须生成的特征图数量。
这个实用功能其实很简单:将第一个卷积块中的滤波器数量(根据模型配置为 64 个)乘以 2^{level}。例如,在第三级(索引 = 2),你的卷积块有 64 * 2² = 256 个滤波器。
def compute_number_of_filters(block_number):
'''
Compute the number of filters for a specific
U-Net block given its position in the contracting path.
'''
return configuration().get("num_filters_start") * (2 ** block_number)上采样块
到目前为止,你已经创建了对输入数据进行下采样的代码。现在是时候为扩展路径构建模块了。让我们添加另一个定义,称之为 upconv_block。它需要一些输入、预期的滤波器数量、与上采样块的层次级别相对应的跳过输入张量,以及关于它是否是最后一个块的信息。

根据 U-Net 的设计,第一步是进行上采样。例如,在上图中,52x52x512 张量被上采样为 104x104x512 张量
在计算机视觉模型中,有两种主要的上采样方法:
- 插值法。这是一种经典方法,Ronneberger 等人(2015 年)就采用了这种方法。使用插值函数(如双三次插值)来计算缺失的像素。在 TensorFlow 和 Keras 中,"上采样 "模块涵盖了这一功能。
- 通过转置卷积的学习式上采样。另一种方法是使用转置卷积,即反向卷积。它们不是使用学习到的内核/滤波器对较大的图像进行降采样,而是使用学习到的内核/滤波器对图像进行升采样!在 TensorFlow 中,这些都是通过 [ConvXDTranspose] 来表示的。你将使用这种类型的上采样,因为它(1)在当今更为常见,(2)使整个模型尽可能使用可训练参数。
因此,输入张量 x 的第一个处理过程就是通过 Conv2DTranspose 进行上采样。
请注意,任意层级 L 的卷积块输出的前两个维度的形状要大于相应上采样块的这些维度的形状。例如,在下面的示例中,136x136 像素的跳转连接必须与 104x104 像素的张量连接。
Ronneberger 等人(2015 年)在他们最初的 U-Net 实现中,通过从卷积块生成的特征图中提取中心裁剪来缓解这一问题。该中心裁剪的宽度和高度与上采样张量相同;在我们的案例中,宽度和高度为 104x104 像素。现在,可以将两个张量连接起来。

要进行这种裁剪,你需要使用 TensorFlow 的 CenterCrop 图层,使用上采样张量指定的目标宽度和高度对跳过输入进行中心裁剪。
然后,使用 "连接 "层将裁剪后的跳过输入与上采样张量连接起来,之后就可以继续处理整个输入了。根据 Ronneberger 等人(2015 年)的研究和上面的引文,这需要使用两次 3x3 卷积,然后分别使用 ReLU 激活。
最后,在最后一层,应用 1x1 卷积(保留宽度和高度维度),输出一个张量,第三维度为 C。这里的 C 代表所需的类别数--我们在模型配置中将其设为 num_filters_end,而事实上,这就是今天数据集的三个类别!:)
下面是创建上采样块的代码:
def upconv_block(x, filters, skip_input, last_block = False):
'''
U-Net upsampling block.
Used for upsampling in the expansive path.
'''
config = configuration()
# Perform upsampling
x = Conv2DTranspose(filters//2, (2, 2), strides=(2, 2),\
kernel_initializer=config.get("initializer"))(x)
shp = x.shape
# Crop the skip input, keep the center
cropped_skip_input = CenterCrop(height = x.shape[1],\
width = x.shape[2])(skip_input)
# Concatenate skip input with x
concat_input = Concatenate(axis=-1)([cropped_skip_input, x])
# First Conv segment
x = Conv2D(filters//2, (3, 3),
kernel_initializer=config.get("initializer"))(concat_input)
x = Activation("relu")(x)
# Second Conv segment
x = Conv2D(filters//2, (3, 3),
kernel_initializer=config.get("initializer"))(x)
x = Activation("relu")(x)
# Prepare output if last block
if last_block:
x = Conv2D(config.get("num_filters_end"), (1, 1),
kernel_initializer=config.get("initializer"))(x)
return x使用跳转连接的扩展路径
与收缩路径一样,你也需要在扩展路径中组成上采样层。
与收缩路径类似,你也需要计算扩展路径中区块的滤波器数量。不过,这次你要从末端开始计算,即从区块数减一开始计算,因为你要从高滤波器数计算到低滤波器数。
然后,对滤波器的数量进行迭代,计算它是否是最后一个区块,并计算出跳过输入的电平,然后将张量通过上采样区块。
现在,如果你将张量输入到所有的区块(如果它们是组成的),它们就会完整地通过收缩路径和扩张路径。是时候将 U-Net 组件拼接在一起了!
def expansive_path(x, skip_inputs):
'''
U-Net expansive path.
Initializes multiple upsampling blocks for upsampling.
'''
num_filters = [compute_number_of_filters(index)\
for index in range(configuration()\
.get("num_unet_blocks")-1, 0, -1)]
skip_max_index = len(skip_inputs) - 1
for index, block_num_filters in enumerate(num_filters):
skip_index = skip_max_index - index
last_block = index == len(num_filters)-1
x = upconv_block(x, block_num_filters,\
skip_inputs[skip_index], last_block)
return xU-Net 生成器
我们现在要创建的 build_unet 定义。
这是一个相对简单的定义。它通过配置输入数据的高度、宽度和维度来构建输入形状,然后将其传递给输入层--这是 TensorFlow 表示输入数据的方式。
然后,你的输入会通过收缩路径(contracting_path),该路径会产生收缩数据和每个卷积块的跳转连接输出。
然后,这些数据被送入 expansive_path,产生扩展数据。请注意,我们选择明确不对 Softmax 激活函数建模,因为我们会按照 TensorFlow 的规定将其推送到损失函数中。最后,我们以输入数据为起点,以扩展数据为终点,初始化模型类。该模型被命名为 U-Net。
def build_unet():
''' Construct U-Net. '''
config = configuration()
input_shape = (config.get("input_height"),\
config.get("input_width"), config.get("input_dim"))
# Construct input layer
input_data = Input(shape=input_shape)
# Construct Contracting path
contracted_data, skip_inputs = contracting_path(input_data)
# Construct Expansive path
expanded_data = expansive_path(contracted_data, skip_inputs)
# Define model
model = Model(input_data, expanded_data, name="U-Net")
return modelU-Net 训练流程定义
现在你已经创建了模型构建模块,是时候开始创建 U-Net 训练定义了。你将创建这些定义:
- 初始化模型
- 加载数据集。
- 数据预处理
- 训练回调
- 数据可视化
初始化模型
你已经有了创建模型的定义。然而,这只是一个骨架--因为模型需要用损失函数初始化,优化器需要配置,等等。
因此,让我们创建一个名为 init_model 的定义来完成这些工作。它接受每个历元的步数,这些步数来自稍后添加的数据集配置。
'''
U-NET TRAINING PROCESS BUILDING BLOCKS
'''
def init_model(steps_per_epoch):
'''
Initialize a U-Net model.
'''
config = configuration()
model = build_unet()
# Retrieve compilation input
loss_init = config.get("loss")(from_logits=True)
metrics = config.get("metrics")
num_epochs = config.get("num_epochs")
# Construct LR schedule
boundaries = [int(num_epochs * percentage * steps_per_epoch)\
for percentage in config.get("lr_schedule_percentages")]
lr_schedule = config.get("lr_schedule_class")(boundaries, config.get("lr_schedule_values"))
# Init optimizer
optimizer_init = config.get("optimizer")(learning_rate = lr_schedule)
# Compile the model
model.compile(loss=loss_init, optimizer=optimizer_init, metrics=metrics)
# Plot the model
plot_model(model, to_file="unet.png")
# Print model summary
model.summary()
return model这就是你的模型的外观。

加载数据集
为了训练模型,将使用 Parkhi 等人(2012 年)发表的牛津理工学院宠物数据集。
我们之所以使用它,是因为它在 TensorFlow 数据集中可用,使加载更加容易,还因为它具有开箱即用的最大分割能力。例如,下面是一张输入图像和相应的分割掩码:
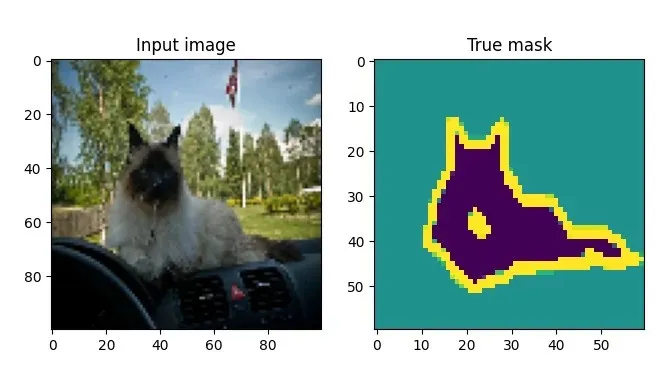
加载数据集非常简单。由于 TensorFlow 数据集只包含训练和测试数据,而且需要三个分片(train、val 和 test),因此需要根据模型配置重新定义分片,并将其传递给 tfds.load。通过返回 info(with_info=True),以后就能读取一些有趣的元数据。
def load_dataset():
''' Return dataset with info. '''
config = configuration()
# Retrieve percentages
train = config.get("data_train_prc")
val = config.get("data_val_prc")
test = config.get("data_test_prc")
# Redefine splits over full dataset
splits = [f'train[:{train}%]+test[:{train}%]',\
f'train[{train}%:{val}%]+test[{train}%:{val}%]',\
f'train[{val}%:{test}%]+test[{val}%:{test}%]']
# Return data
return tfds.load('oxford_iiit_pet:3.*.*', split=splits, data_dir=configuration()\
.get("dataset_path"), with_info=True) 数据集预处理
在深度学习模型中使用数据集之前,需要对其进行预处理。这就是为什么今天的教程也需要你编写一些预处理代码。更准确地说,你将执行以下预处理
- 样本级预处理,包括图像归一化。
- 数据扩增,人为增加数据集的大小。
- 计算样本权重,以平衡分割掩码中代表性过高和过低的类别。
- 在数据集层面进行预处理,结合前面所有要点。
现在,让我们为每个要点编写代码。
执行图像归一化只需将 Tensors 转换为 float32 格式,然后除以 255.0。除此之外,还要从遮罩的类别中减去 1,因为它们的范围是 1-3,而我们希望它们的范围是 0-2:
def normalize_sample(input_image, input_mask):
''' Normalize input image and mask class. '''
# Cast image to float32 and divide by 255
input_image = tensorflow.cast(input_image, tensorflow.float32) / 255.0
# Bring classes into range [0, 2]
input_mask -= 1
return input_image, input_mask接下来,你将在样本级预处理的定义中实现这一点。输入图像会被调整到模型配置中指定的大小,掩码也是如此。最后,对输入图像和掩码进行归一化处理并返回。
def preprocess_sample(data_sample):
''' Resize and normalize dataset samples. '''
config = configuration()
# Resize image
input_image = tensorflow.image.resize(data_sample['image'],\
(config.get("input_width"), config.get("input_height")))
# Resize mask
input_mask = tensorflow.image.resize(data_sample['segmentation_mask'],\
(config.get("mask_width"), config.get("mask_height")))
# Normalize input image and mask
input_image, input_mask = normalize_sample(input_image, input_mask)
return input_image, input_mask数据增强允许 TensorFlow 对输入张量执行任意图像处理。在今天的教程中,你将通过水平和垂直随机翻转样本来实现数据增强。我们在所有调用中使用相同的种子,以确保输入和标签以相同的方式进行处理。
def data_augmentation(inputs, labels):
''' Perform data augmentation. '''
# Use the same seed for deterministic randomness over both inputs and labels.
seed = 36
# Feed data through layers
inputs = tensorflow.image.random_flip_left_right(inputs, seed=seed)
inputs = tensorflow.image.random_flip_up_down(inputs, seed=seed)
labels = tensorflow.image.random_flip_left_right(labels, seed=seed)
labels = tensorflow.image.random_flip_up_down(labels, seed=seed)
return inputs, labels接下来是计算样本权重。给定每个类的权重后,通过 reduce_sum 计算这些类权重的相对权重。然后,计算每个类的样本权重,并将其作为一个额外数组返回,供 model.fit 使用。
def compute_sample_weights(image, mask):
''' Compute sample weights for the image given class. '''
# Compute relative weight of class
class_weights = configuration().get("class_weights")
class_weights = class_weights/tensorflow.reduce_sum(class_weights)
# Compute same-shaped Tensor as mask with sample weights per
# mask element.
sample_weights = tensorflow.gather(class_weights,indices=\
tensorflow.cast(mask, tensorflow.int32))
return image, mask, sample_weights最后,你可以在数据集级预处理中结合上述所有定义。根据数据集类型的不同,预处理的方式也不同:
在预处理训练数据或验证数据时,要进行预处理、数据扩充和类加权,包括一些实用处理,以改进训练过程。
在对测试数据进行预处理时,则不需要实用功能和类加权,因为在测试过程中,模型并没有经过训练。
def preprocess_dataset(data, dataset_type, dataset_info):
''' Fully preprocess dataset given dataset type. '''
config = configuration()
batch_size = config.get("batch_size")
buffer_size = config.get("buffer_size")
# Preprocess data given dataset type.
if dataset_type == "train" or dataset_type == "val":
# 1. Perform preprocessing
# 2. Cache dataset for improved performance
# 3. Shuffle dataset
# 4. Generate batches
# 5. Repeat
# 6. Perform data augmentation
# 7. Add sample weights
# 8. Prefetch new data before it being necessary.
return (data
.map(preprocess_sample)
.cache()
.shuffle(buffer_size)
.batch(batch_size)
.repeat()
.map(data_augmentation)
.map(compute_sample_weights)
.prefetch(buffer_size=tensorflow.data.AUTOTUNE))
else:
# 1. Perform preprocessing
# 2. Generate batches
return (data
.map(preprocess_sample)
.batch(batch_size))训练回调
剩下的就是编写一些实用函数了。如果你熟悉 TensorFlow,很可能知道 Keras 的回调。这些回调可用于在训练过程的特定步骤中执行某些操作。
我们将使用这些回调将 TensorBoard 日志集成到模型中。这样,你就能在训练过程中和训练结束后评估进度和模型训练情况。
def training_callbacks():
''' Retrieve initialized callbacks for model.fit '''
return [
TensorBoard(
log_dir=os.path.join(os.getcwd(), "unet_logs"),
histogram_freq=1,
write_images=True
)
]数据可视化
最后一个实用功能与数据可视化有关。我们想了解模型的性能如何,因此要构建一个可视化工具,显示源图像、实际遮罩、预测遮罩以及叠加在源图像上的预测遮罩。为此,我们需要创建一个函数,根据模型预测生成遮罩:
def probs_to_mask(probs):
''' Convert Softmax output into mask. '''
pred_mask = tensorflow.argmax(probs, axis=2)
return pred_mask在第三个维度上,它只需获取最大值的类索引并返回它。事实上,这等同于挑选一个类。
你可以将其整合到生成图中,使用 Matplotlib 生成包含源图像、实际遮罩、预测遮罩和叠加的四幅图:
def generate_plot(img_input, mask_truth, mask_probs):
''' Generate a plot of input, truthy mask and probability mask. '''
fig, axs = plt.subplots(1, 4)
fig.set_size_inches(16, 6)
# Plot the input image
axs[0].imshow(img_input)
axs[0].set_title("Input image")
# Plot the truthy mask
axs[1].imshow(mask_truth)
axs[1].set_title("True mask")
# Plot the predicted mask
predicted_mask = probs_to_mask(mask_probs)
axs[2].imshow(predicted_mask)
axs[2].set_title("Predicted mask")
# Plot the overlay
config = configuration()
img_input_resized = tensorflow.image.resize(img_input, (config.get("mask_width"), config.get("mask_height")))
axs[3].imshow(img_input_resized)
axs[3].imshow(predicted_mask, alpha=0.5)
axs[3].set_title("Overlay")
# Show the plot
plt.show()将所有内容合并为一个可运行的示例
最后一步是将所有内容合并成一个有效的示例
def main():
''' Run full training procedure. '''
# Load config
config = configuration()
batch_size = config.get("batch_size")
validation_sub_splits = config.get("validation_sub_splits")
num_epochs = config.get("num_epochs")
# Load data
(training_data, validation_data, testing_data), info = load_dataset()
# Make training data ready for model.fit and model.evaluate
train_batches = preprocess_dataset(training_data, "train", info)
val_batches = preprocess_dataset(validation_data, "val", info)
test_batches = preprocess_dataset(testing_data, "test", info)
# Compute data-dependent variables
train_num_samples = tensorflow.data.experimental.cardinality(training_data).numpy()
val_num_samples = tensorflow.data.experimental.cardinality(validation_data).numpy()
steps_per_epoch = train_num_samples // batch_size
val_steps_per_epoch = val_num_samples // batch_size // validation_sub_splits
# Initialize model
model = init_model(steps_per_epoch)
# Train the model
model.fit(train_batches, epochs=num_epochs, batch_size=batch_size,\
steps_per_epoch=steps_per_epoch, verbose=1,
validation_steps=val_steps_per_epoch, callbacks=training_callbacks(),\
validation_data=val_batches)
# Test the model
score = model.evaluate(test_batches, verbose=0)
print(f'Test loss: {score[0]} / Test accuracy: {score[1]}')
# Take first batch from the test images and plot them
for images, masks in test_batches.take(1):
# Generate prediction for each image
predicted_masks = model.predict(images)
# Plot each image and masks in batch
for index, (image, mask) in enumerate(zip(images, masks)):
generate_plot(image, mask, predicted_masks[index])
if index > 4:
break
if __name__ == '__main__':
main()训练我们的 U-Net
现在,让我们来训练模型!打开终端,导航到 Python 脚本所在的位置,然后运行它。你会发现训练过程很快就开始了。
当我从头开始训练 U-Net 时,也就是使用 He 初始化的权重时,训练 U-Net 的结果是这样的:

训练精度(橙色)和验证精度(蓝色)。

使用我们的模型生成的图像分割示例
回想一下,训练完成后,模型会从测试集中提取一些示例并输出结果。下面是 U-Net 生成的结果:

通过模型预训练提高模型性能
事实上,虽然有些示例(狗)的叠加效果很好,但其他示例(其中一只猫)的预测效果却差很多。
造成这种情况的关键原因之一是数据集的大小--尽管宠物数据集相对较大,但与其他更真实的数据集相比,宠物数据集实在太小了。虽然数据扩增可能会改善结果,但它并不是一种可以解决所有问题的神奇方法。
不过,除了增加数据集的大小外,还有一种方法也可以奏效,那就是不要从随机初始化权重开始。相反,对模型进行预训练是个好主意,例如使用 ImageNet 数据集。这样,你的模型就已经学会了检测特定模式,并允许你用它们来初始化你的模型。