使用Neo4j和Langchain创建知识图谱
知识图谱是组织和整合信息的强大工具。通过使用实体作为节点和关系作为边缘,它们提供了一种系统的知识表示方法。这种有条理的表示有利于简化查询、分析和推理,使知识图在搜索引擎、推荐系统、自然语言处理和人工智能等各个领域中不可或缺。
在人工智能领域,知识图谱通过提供补充的上下文洞察,在提高机器学习模型的效率方面发挥着关键作用。它们通过在各种单词和短语之间建立联系来促进对自然语言的更深入理解。此外,它们还为人工智能系统提供了大量可以有效利用的结构化信息,从而能够开发出更加动态和精明的人工智能系统。
开发和维护知识图谱是一项复杂的工作,需要从不同来源提取和验证信息,并用新数据不断更新图谱。尽管存在困难,但知识图谱的潜在优势使其成为持续研究和创新的焦点。
使用Neo4j创建和实现知识图
创建知识图遵循一个结构化的过程,从建立最小可行图(MVG)开始,然后逐步扩展它。大致的简化过程如下:
1. 摘要:最初,从文档中摘录相关信息,这些数据被解析并结构化为可管理的块,作为知识图中的节点。
2. 增强:数据在提取后进行增强,以丰富其价值。嵌入被添加到每个块中,为信息提供额外的上下文和深度。这一步对于使图更加健壮和能够产生更丰富的见解至关重要。
3. 扩展:一旦数据得到增强,图就可以进行扩展了。这涉及到将节点彼此连接起来,以扩展图中的上下文和关系。
4. 迭代改进:提取、增强和扩展的过程可以根据需要重复,结合额外的文件、外部数据源和用户反馈,不断改进和提高图表的相关性和准确性。这种迭代方法确保知识图随着时间的推移而发展,以合并新信息并满足不断变化的分析需求。
5. 可视化分析:在最后阶段,地址节点可以添加到图表中,从而可以在相应文件的背景下对空间关系进行可视化分析和探索。
通过遵循这种结构化的方法并结合你的文件中的相关数据,可以创建一个全面的动态知识图谱。这样的图表不仅有助于更深入地了解企业信息披露,还有助于在各个领域做出明智的决策。
这里是一个例子,使用Neo4j和Langchain从《博伽梵歌》论文PDF开发基本知识图谱
让我们来分析一下如何使用《博伽梵歌》电子版来创建一个基本的知识图谱。这篇由斯瓦米·西瓦南达所写的文章充满了丰富的信息,我们可以用知识图谱来组织。我们将使用Neo4j(它帮助我们管理和构建图形)和Langchain(它帮助我们处理文本)。
首先,使用Neo4j创建一个免费帐户。对于本例,我们将使用免费层,它允许创建一个实例。
凭据文件将包含在后续代码中需要使用的以下详细信息:
# Wait 60 seconds before connecting using these details, or login to https://console.neo4j.io to validate the Aura Instance is available
NEO4J_URI=value
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=value
AURA_INSTANCEID=value
AURA_INSTANCENAME=Instance01引用相应的库
from dotenv import load_dotenv
import os
# Common data processing
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import PyPDFLoader从PDF中提取文本:第一步是加载PDF文件并将其页面拆分为可管理的文本块。我们使用来自langchain库的PyPDFLoader模块来完成此任务。
# Load PDF file
loader = PyPDFLoader("path/to/your/pdf/file.pdf")
pages = loader.load_and_split()将文本分割成块:接下来,我们将提取的文本分割成更小的块,以方便进一步处理。来自langchain的
RecursiveCharacterTextSplitter类被用于此目的。
# Split pages into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
chunks = text_splitter.split_documents(pages)创建一个矢量存储,在Neo4j中生成嵌入和存储:我们创建一个Neo4jVector对象来将文本块的嵌入存储在Neo4j图形数据库中。这允许我们在以后有效地检索和操作嵌入。
# Warning control
import warnings
warnings.filterwarnings("ignore")
# Load from environment from the credentials file
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
NEO4J_DATABASE = 'neo4j'
# Global constants
VECTOR_INDEX_NAME = 'pdf_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)# Create Neo4j vector store
neo4j_vector_store = Neo4jVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=chunks,
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)构建关系:我们在图中的块之间建立关系,指示它们的顺序以及它们与父PDF文档的关联。
# Create a PDF node
cypher = """
MERGE (p:PDF {name: $pdfName})
RETURN p
"""
kg.query(cypher, params={'pdfName': "path/to/your/pdf/file.pdf"})
# Connect chunks to their parent PDF with a PART_OF relationship
cypher = """
MATCH (c:Chunk), (p:PDF)
WHERE p.name = $pdfName
MERGE (c)-[newRelationship:PART_OF]->(p)
RETURN count(newRelationship)
"""
kg.query(cypher, params={'pdfName': "path/to/your/pdf/file.pdf"})
# Create a NEXT relationship between subsequent chunks
cypher = """
MATCH (c1:Chunk), (c2:Chunk)
WHERE c1.chunkSeqId = c2.chunkSeqId - 1
MERGE (c1)-[r:NEXT]->(c2)
RETURN count(r)
"""
kg.query(cypher)问答:最后,我们可以利用构造好的知识图来执行问答任务。我们从矢量存储中创建检索器和聊天机器人问答链,以根据PDF文档的内容回答问题。
# Create a retriever from the vector store
retriever = neo4j_vector_store.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain = RetrievalQAWithSourcesChain.from_chain_type(
OpenAI(temperature=0),
chain_type="stuff",
retriever=retriever
)
# Ask a question
question = "What is the main topic of this PDF document?"
answer = chain(
{"question": question},
return_only_outputs=True,
)
print(textwrap.fill(answer["answer"]))下面是一些在neo4j中检查数据的查询
节点数
# Returns the node count
kg.query("""
MATCH (n)
RETURN count(n) as nodeCount
""")打印模式
kg.refresh_schema()
print(kg.schema)显示索引
kg.query("SHOW INDEXES")样本输出
Neo4j仪表盘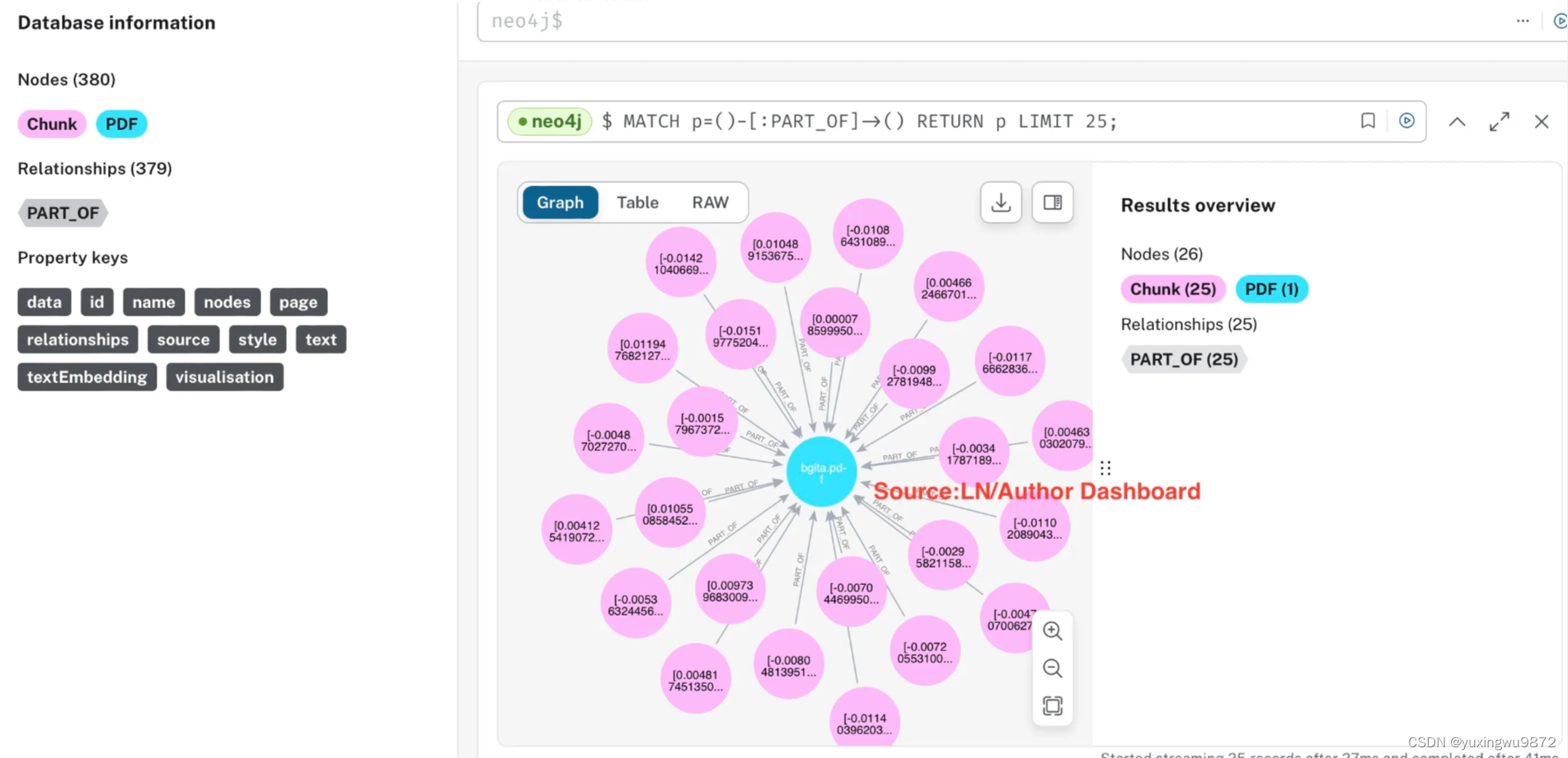
问答输出

使用知识图谱以及Neo4j和Langchain等工具,我们可以将复杂的非结构化文本转换为更容易分析的结构化、相互关联的数据。这个过程可以应用于各种类型的信息,从财务报告到精神文本。这个例子是如何创建知识图的基本说明。随着我们继续探索和发展这项技术,我们可以发现理解和解释数据的新方法。