持久化操作
什么是持久化,为什么要持久化
Spark中最重要的功能之一是跨操作在内存中持久化(或缓存)数据集。当您持久化RDD时,每个节点将其计算的任何分区存储在内存中,并在该数据集(或从该数据集派生的数据集)上的其他操作中重用这些分区。这使得未来的行动更快(通常超过10倍)。缓存是迭代算法和快速交互使用的关键工具。
可以使用persist()或cache()方法将RDD标记为持久化。第一次在动作中计算时,它将保存在节点的内存中。Spark的缓存是容错的——如果RDD的任何分区丢失,它将使用最初创建它的转换自动重新计算。
持久化的方法就是rdd.persist()或者rdd.cache()。
持久化策略
可以通过persist(StoreageLevle的对象)来指定持久化策略,eg:StorageLevel.MEMORY_ONLY。
| 持久化策略 | 含义 | |
| MEMORY_ONLY(默认) | rdd中的数据,以未经序列化的java对象格式,存储在内存中。如果内存不足,剩余的部分不持久化,使用的时候,没有持久化的那一部分数据重新加载。这种效率是最高,但是是对内存要求最高的。 | |
| MEMORY_ONLY_SER |
| |
| MEMORY_AND_DISK | 和MEMORY_ONLY相比就多了一个disk,内存存不下的数据存储在磁盘中。 | |
| MEMEORY_AND_DISK_SER | 比MEMORY_AND_DISK多了个序列化。 | |
| DISK_ONLY | 就是MEMORY_ONLY对应,都保存在磁盘,效率太差,一般不用。 | |
| xxx_2 | 就是上述多个策略后面加了一个_2,比如MEMORY_ONLY_2,MEMORY_AND_DISK_SER_2等等,就多了一个replicate而已,备份,所以性能会下降,但是容错或者高可用加强了。所以需要在二者直接做权衡。如果说要求数据具备高可用,同时容错的时间花费比从新计算花费时间少,此时便可以使用,否则一般不用。 | |
| HEAP_OFF(experimental) | 使用非Spark的内存,也即堆外内存,比如Tachyon,HBase、Redis等等内存来补充spark数据的缓存。 |
如何选择一款合适的持久化策略
第一就选择默认MEMORY_ONLY,因为性能最高嘛,但是对空间要求最高;如果空间满足不了,退而求其次,选择MEMORY_ONLY_SER,此时性能还是蛮高的,相比较于MEMORY_ONLY的主要性能开销就是序列化和反序列化;如果内存满足不了,直接跨越MEMORY_AND_DISK,选择MEMEORY_AND_DISK_SER,因为到这一步,说明数据蛮大的,要想提高性能,关键就是基于内存的计算,所以应该尽可能的在内存中存储对象;DISK_ONLY不用,xx_2的使用如果说要求数据具备高可用,同时容错的时间花费比从新计算花费时间少,此时便可以使用,否则一般不用。
持久化和非持久化性能比较
object _05SparkPersistOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_05SparkPersistOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
//读取外部数据(文件125M大小)
var start = System.currentTimeMillis()
val lines = sc.textFile("file:///E:/data/spark/core/sequences.txt")
var count = lines.count()
println("没有持久化:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.persist(StorageLevel.MEMORY_AND_DISK) //lines.cache()
start = System.currentTimeMillis()
count = lines.count()
println("持久化之后:#######lines' count: " + count + ", cost time: " + (System.currentTimeMillis() - start) + "ms")
lines.unpersist()//卸载持久化数据
sc.stop()
}
}RDD检查点机制
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志),也不能丢掉, 当某个节点某个 executor 宕机了,上面cache 的RDD就会丢掉, 需要通过依赖链重放计算出来,不同的是checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
如果存在以下场景,则比较适合使用检查点机制:
1)DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
2)在宽依赖上做Checkpoint获得的收益更大。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wc").setMaster("spark://CentOS1:7077")
val sc = new SparkContext(conf)
val spark = SparkSession.builder().config(conf).getOrCreate()
val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8),("a",33),("c",6)),3)
sc.setCheckpointDir("hdfs://CentOS1:9000/checkpoint")
rdd.checkpoint()
rdd.collect
println(rdd.collect.toBuffer)
}
}共享变量
概述
通常,当传递给Spark操作(如map或reduce)的函数在远程集群节点上执行时,它将在函数中使用的所有变量的单独副本上工作。这些变量被复制到每台机器上,对远程机器上变量的更新不会传播回驱动程序。跨任务支持通用的读写共享变量将是低效的(低效). 然而,Spark确实为两种常见的使用模式提供了两种有限类型的共享变量:广播变量和累加器。
就是说,为了能够更加高效的在driver和算子之间共享数据,spark提供了两种有限的共享变量,一者广播变量,一者累加器。
broadcast广播变量
说明
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么只是每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
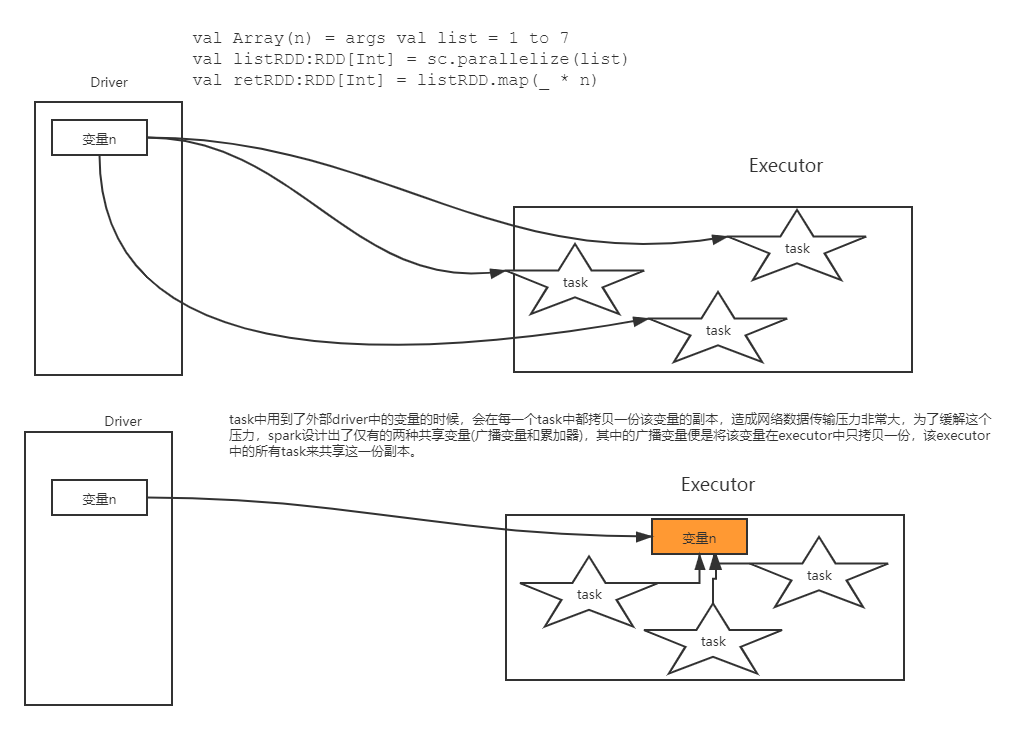
图-23 广播变量图
如何使用广播变量呢?对普通遍历进行包装即可。
val num:Any = xxx
val numBC:Broadcast[Any] = sc.broadcast(num)
调用
val n = numBC.value
编码操作
val conf = new SparkConf()
conf.setMaster("local[*]").setAppName("brocast")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val list = List("hello hadoop")
val broadCast = sc.broadcast(list)
val lineRDD = sc.textFile("E:\\word.txt")
lineRDD.filter { x => broadCast.value.contains(x) }.foreach(println)
sc.stop()定义广播变量注意点
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改。
注意事项
1)能不能将一个RDD使用广播变量广播出去?不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2)广播变量只能在Driver端定义,不能在Executor端定义。
3)在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4)如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5)如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
accumulator累加器
说明
accumulator累加器的概念和mr中出现的counter计数器的概念有异曲同工之妙,对某些具备某些特征的数据进行累加。累加器的一个好处是,不需要修改程序的业务逻辑来完成数据累加,同时也不需要额外的触发一个action job来完成累加,反之必须要添加新的业务逻辑,必须要触发一个新的action job来完成,显然这个accumulator的操作性能更佳!
累加的使用:
构建一个累加器
val accu = sc.longAccumuator()
累加的操作
accu.add(参数)
获取累加器的结果,累加器的获取,必须需要action的触发
val ret = accu.value
编码操作
1)使用非累加器完成某些特征数据的累加求解:
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/work/data/accu.txt")
val words = lines.flatMap(_.split("\\s+"))
//统计每个单词出现的次数
val rbk = words.map((_, 1)).reduceByKey(_+_)
rbk.foreach(println)
println("=============额外的统计=================")
//统计其中的is出现的次数
rbk.filter{case (word, count) => word == "is"}.foreach(println)
Thread.sleep(10000000)
sc.stop()执行结果如图-24所示。

图-24 非累加器执行结果
2)使用累加器完成上述案例:
val conf = new SparkConf()
.setAppName(s"${AccumulatorOps.getClass.getSimpleName}")
.setMaster("local[*]")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/E:/work/data/accu.txt")
val words = lines.flatMap(_.split("\\s+"))
//统计每个单词出现的次数
val accumulator = sc.longAccumulator
val rbk = words.map(word => {
if(word == "is")
accumulator.add(1)
(word, 1)
}).reduceByKey(_+_)
rbk.foreach(println)
println("================使用累加器===================")
println("is: " + accumulator.value)
Thread.sleep(10000000)
sc.stop()执行结果入下图-25所示。

图-25 累加器执行结果
3)总结:使用累加器也能够完成上述的操作,而且只使用了一个action操作。
注意
1)累加器的调用,也就是accumulator.value必须要在action之后被调用,也就是说累加器必须在action触发之后。
2)多次使用同一个累加器,应该尽量做到用完即重置:accumulator.reset
3)尽量给累加器指定name,方便我们在web-ui上面进行查看,如图-26所示。

图-26 有名字的累加器
自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。实现自定义类型累加器需要继承AccumulatorV2并至少覆写下例中出现的方法,下面这个累加器可以用于在程序运行过程中统计单词出现的次数,最终以HashMap[String,Int]的形式返回。
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
class CustomerAcc extends AccumulatorV2[String, mutable.HashMap[String, Int]] {
private val _hashAcc = new mutable.HashMap[String, Int]()
// 检测是否为空
override def isZero: Boolean = {
_hashAcc.isEmpty
}
// 拷贝一个新的累加器,
//有可能多个task同时往初始值里写值,有可能出现线程安全问题,此时最好加锁
override def copy(): AccumulatorV2[String, mutable.HashMap[String, Int]] = {
val newAcc = new CustomerAcc()
_hashAcc.synchronized {
newAcc._hashAcc ++= (_hashAcc)
}
newAcc
}
// 重置一个累加器
override def reset(): Unit = {
_hashAcc.clear()
}
// 每一个分区中用于添加数据的方法 小SUM
override def add(v: String): Unit = {
_hashAcc.get(v) match {
case None => _hashAcc += ((v, 1))
case Some(a) => _hashAcc += ((v, a + 1))
}
}
// 合并每一个分区的输出 总sum
override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Int]]): Unit = {
other match {
case o: AccumulatorV2[String, mutable.HashMap[String, Int]] => {
for ((k, v) <- o.value) {
_hashAcc.get(k) match {
case None => _hashAcc += ((k, v))
case Some(a) => _hashAcc += ((k, a + v))
}
}
}
}
}
// 输出值
override def value: mutable.HashMap[String, Int] = {
_hashAcc
}
}注册使用:
object CustomerAcc {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("partittoner").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
val abc = "HIII"
val hashAcc = new CustomerAcc()
sc.register(hashAcc, "abc")
val rdd = sc.makeRDD(Array("a", "b", "c", "a", "b", "c", "d"))
rdd.foreach(hashAcc.add(_))
for ((k, v) <- hashAcc.value) {
println("【" + k + ":" + v + "】")
}
sc.stop()
}
}