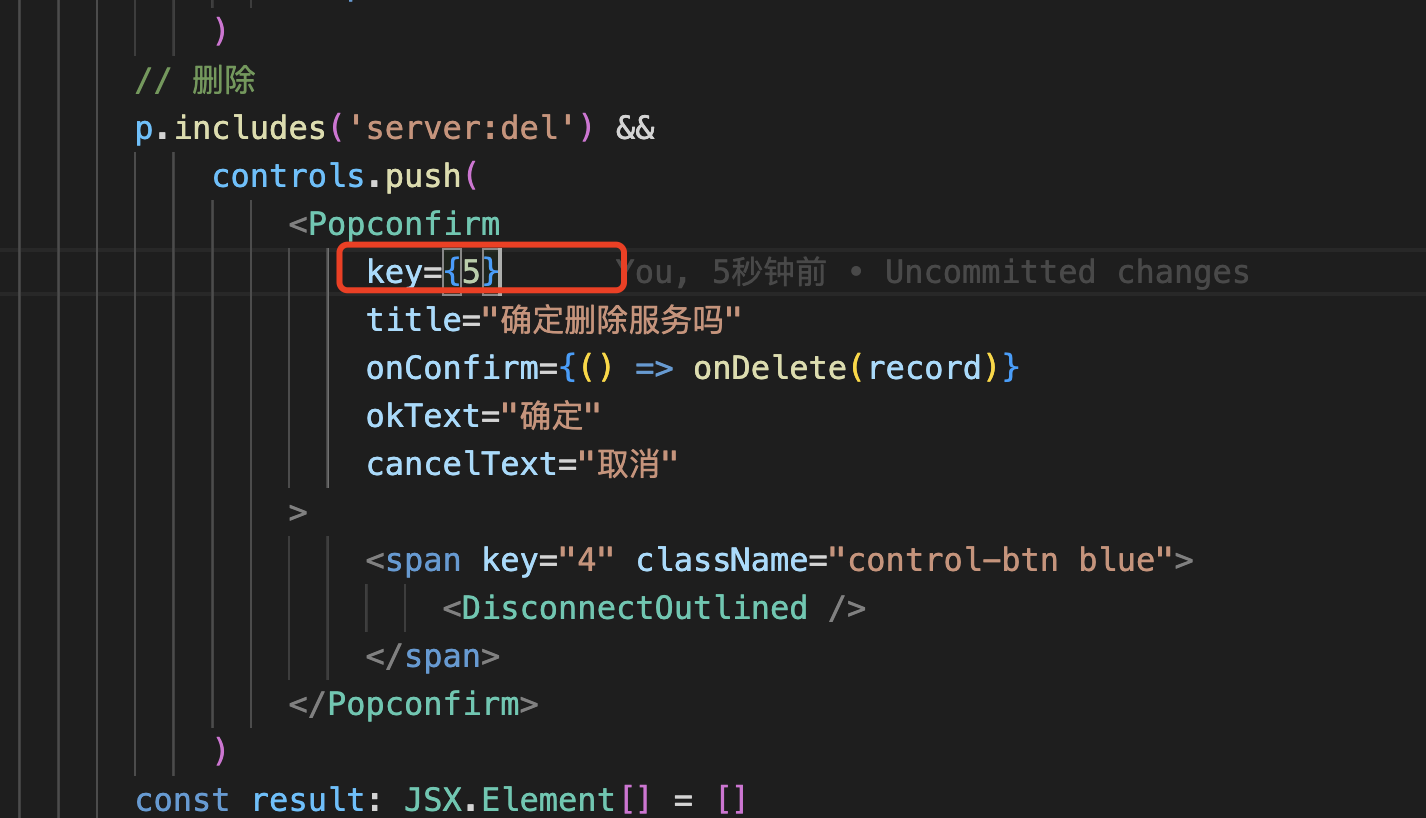
Prometheus
- 发布应用之后,就有持续运维的事情,就是平台监控
- Prometheus 是一个云原生的日志监控平台,是一个实时标准的一个技术
- 它是著名的 cncf 里的一个重要的开源项目

- 上面整个图片是在云原生应用及K8s应用架构下的一个日志监控的一个标准的解决方案
- 中间火炬图标就是 Prometheus, 从左向右来看
- Short-lived jobs, 这里有一个job概念,它能执行这种一次性或者是多次的
- 定时的导入一些触发一些 metrics 收集的任务, 注意,这是k8s里面的job
- 可以认为是个定时任务, 然后它通过一个Pushgetaway发送一些pull的请求
- 这个请求去拉什么数据呢?在下面Prometheus 配置文件里,会有一些Jobs, 这里是Prometheus的Jobs
- 还有这个exporter,也就是我们的日志导出器,也是非常关键的一个组件
- 它能够在K8s的worker node上去导出一些CPU的这个数据,这个叫Prometheus的一些目标
- 然后通过这个拉取的方式,这些数据会被拉取到 Prometheus server
- 这些数据不仅是在 work node 上的数据,也可以是 K8s 应用中的数据
- 拉取数据库后存储在 TSDB (时序数据库中) 中,所以时序数据库和关系性数据库的区别是什么呢?
- 关系性数据库,像mysql这样的数据库
- 它比较适合存这个数据这种有关联关系的这种复杂查询的这种依赖关系的这种数据
- 像一些监控的数据,它往往是按照一定的时序发生的,所以它叫时序数据库
- 正因为它是时序时序数据库,所以它的每个K8s集群里面的时序的时间保持一致,需要安装NTP这个server服务器
- 这个时序数据库存在咱们的这个node上,当然Prometheus本身也是运行在K8s平台上的
- 收集数据后,它就已经有了K8s集群的一些字段和数据了,或者是应用的一些数据都可以存在这里
- 有了数据之后,可以做展示,展示的方式呢,它是通过 PromQL 查询语言去从这个数据库里面查询数据
- 之后展示在 Prometheus 自身的 web UI 里面,同时也可以把这些数据展示到
- Grafana 这个更专业的做数据可视化的这么一个平台,当然也可以通过接口把数据转到你们自己的web平台里面去
- 还有push alerts 告警,比如说出现了一些事件之后,通过 Alertmanager 发邮件
- 这就是一个非常经典的云原生的一个日志监控的一个解决方案
- 目前业界所有的互联网大公司都会基于这么一套流程去实现日志的收集
- 我们会从K8s这个node上收取日志,然后展示在Grafana里面
- 会在K8s上的应用程序,加上一些日志收集的插件,把数据吐到这个Prometheus服务器
- 这样,在这个监控平台上可以看到这个应用的日志,主要关注:系统集群日志和应用日志
- Prometheus 比传统监控方案的什么好处
- 具有由 metric 名称和键/值对标识的时间序列数据的多维数据模型
- 有一个灵活的查询语言,不用写很复杂的代码即可查询,输入key value
- 不依赖分布式存储,只和本地磁盘有关
- 通过 HTTP 的服务拉取时间序列数据
- 也支持推送的方式来添加时间序列数据
- 还支持通过服务发现或静态配置发现目标
- 多种图形和仪表板支持
- 对比ELK写elastic的语法会比较复杂,但是Prometheus相对来讲更简单
安装时间同步工具
-
集群都是有很多数据,要实现监控,需要知道监控的指标: 比如,磁盘CPU内存,还有网络的一些异常情况
-
在这种情况下就需要部署一些能够采集到监控指标的一些服务,我们使用 Node Exporter 来进行集群的任务
-
我们要实现集群的系统时间同步,这个是非常重要,在每个node节点不管是master还是work node上都要执行
-
安装
- 在Centos 8 以下版本执行
- $
yum -y install ntp - $
systemctl enable ntpd - $
ntpdate time1.aliyun.com
- $
- 在 Centos 9 安装
- $
sudo dnf install chrony - $
sudo systemctl start chronyd - $
sudo systemctl enable chronyd - $
sudo vi /etc/chrony.confserver ntp1.aliyun.com iburst - $
sudo systemctl restart chronyd - 之后检查时间和时区
- $
timedatectl查看是否是 Time zone: Asia/Shanghai (CST, +0800),如果不是,执行下面 - $
timedatectl set-timezone Asia/Shanghai
- $
- $
- 在Centos 8 以下版本执行
-
注意,我们用的是时序数据库,时间一定要同步,不同步时间,数据会有问题
部署基础服务抓取数据
1 )概述
- node-exporter用于提供*NIX内核的硬件以及系统指标
- 采集服务器层面的运行指标,包括机器的 loadavg、filesystem、meminfo等
2 )说明
- 此次部署大概分为几个部分
- namespace 命名空间
- 所有服务都会安装在这个命名空间之内
- 保证集群在运行时不会占用其他命名空间的资源
- node-exporter
- daemonset 它是一个后台服务 :9100/metrics 部署在9100端口 能够采集到很多数据
- service 创建了一个 service
- kube-state-metrics
- serviceAccount 这里有 clusterrole, serviceaccount, clusterrolebinding
- clusterrole 通过定义一个集群的角色告诉大家能访问K8s中的什么资源
- serviceaccount 就是账户名称
- clusterrolebinding 就是把角色和账户绑定在一起,也就是这个账户具备这个角色的所有权限
- deploy 这是专门收集日志的组件
- service 部署服务,暴露端口
- 备注
- K8s本质是跑在node节点上的一堆容器组成的服务,本身也要被监控
- serviceAccount 这里有 clusterrole, serviceaccount, clusterrolebinding
- node disk monitor
- 监视Node的磁盘占用情况
- 镜像:
- giantswarm/tiny-tools:latest 工具类,从 work node 抓取变量
- dockermuenster/caddy:0.9.3
- 类型是daemonset,每个node上都会部署一份
- namespace 命名空间
3 )一键部署
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: prometheus-node-exporter
namespace: monitoring
labels:
app: prometheus
component: node-exporter
spec:
selector:
matchLabels:
app: prometheus
component: node-exporter
template:
metadata:
name: prometheus-node-exporter
labels:
app: prometheus
component: node-exporter
spec:
containers:
- image: prom/node-exporter:v0.14.0
name: prometheus-node-exporter
ports:
- name: prom-node-exp
#^ must be an IANA_SVC_NAME (at most 15 characters, ..)
containerPort: 9100
hostPort: 9100
hostNetwork: true
hostPID: true
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: prometheus-node-exporter
namespace: monitoring
labels:
app: prometheus
component: node-exporter
spec:
clusterIP: None
ports:
- name: prometheus-node-exporter
port: 9100
protocol: TCP
selector:
app: prometheus
component: node-exporter
type: ClusterIP
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources:
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitoring
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
# image: gcr.io/google_containers/kube-state-metrics:v0.5.0
image: registry.cn-beijing.aliyuncs.com/qua-io-coreos/kube-state-metrics:v1.3.0
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: monitoring
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-directory-size-metrics
namespace: monitoring
annotations:
description: |
This `DaemonSet` provides metrics in Prometheus format about disk usage on the nodes.
The container `read-du` reads in sizes of all directories below /mnt and writes that to `/tmp/metrics`. It only reports directories larger then `100M` for now.
The other container `caddy` just hands out the contents of that file on request via `http` on `/metrics` at port `9102` which are the defaults for Prometheus.
These are scheduled on every node in the Kubernetes cluster.
To choose directories from the node to check, just mount them on the `read-du` container below `/mnt`.
spec:
selector:
matchLabels:
app: node-directory-size-metrics
template:
metadata:
labels:
app: node-directory-size-metrics
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9102'
description: |
This `Pod` provides metrics in Prometheus format about disk usage on the node.
The container `read-du` reads in sizes of all directories below /mnt and writes that to `/tmp/metrics`. It only reports directories larger then `100M` for now.
The other container `caddy` just hands out the contents of that file on request on `/metrics` at port `9102` which are the defaults for Prometheus.
This `Pod` is scheduled on every node in the Kubernetes cluster.
To choose directories from the node to check just mount them on `read-du` below `/mnt`.
spec:
containers:
- name: read-du
image: giantswarm/tiny-tools:latest
imagePullPolicy: IfNotPresent
command:
- fish
- --command
- |
touch /tmp/metrics-temp
while true
for directory in (du --bytes --separate-dirs --threshold=100M /mnt)
echo $directory | read size path
echo "node_directory_size_bytes{path=\"$path\"} $size" \
>> /tmp/metrics-temp
end
mv /tmp/metrics-temp /tmp/metrics
sleep 300
end
volumeMounts:
- name: host-fs-var
mountPath: /mnt/var
readOnly: true
- name: metrics
mountPath: /tmp
- name: caddy
image: dockermuenster/caddy:0.9.3
command:
- "caddy"
- "-port=9102"
- "-root=/var/www"
ports:
- containerPort: 9102
volumeMounts:
- name: metrics
mountPath: /var/www
volumes:
- name: host-fs-var
hostPath:
path: /var
- name: metrics
emptyDir:
medium: Memory