目录
1. 概念介绍
2. Spark SQL与Hive的区别
3. 数据结构分类
4. 特点
4.1 易整合
4.2 统一的数据访问方式
4.3 兼容hive
4.4 提供标准的数据连接
5 Spark的数据模型介绍
1. 概念介绍
sparkSQl是spark专门针对结构化数据(DataFrame和DataSets)处理的一个组件,可以快速简单的处理结构化数据,他可以加载结构化数据,将其映射成表,利用SQL进行数据处理
sparkSQL 其实是对spark-core处理结构化数据的底层原理进行了封装
底层的物理执行计划还是spark-core的执行过程2. Spark SQL与Hive的区别
hive是单独的一个组件,他的执行过程是:
提交SQL --> 语法解析校验 --> 生成逻辑执行计划 --> 绑定元数据 --> 优化逻辑代码 --> 生成物理执行计划(MR)
-
Shark
-
运行的模式是hive on spark
-
会将hivesql转换为spark的rdd
-
shark是基于hive开的,维护麻烦,2015年停止维护
-
-
sparkSQL
-
是spark团建独立开发的工具,2014年发布1.0版本
-
sparkSQL工具对spark的兼容性更好,优化性能得到提升
-
sparkSQL本质也是将sql语句转化为rdd执行,catalyst引擎负责将sql转化为rdd
-
sparkSQL可以连接使用hive的metastore服务,管理表的元数据
-
3. 数据结构分类
-
结构数据(DataFrame)
-
就是表结构数据,有行列组成,并且描述了数据的属性(字段)和类型,表信息
-
String int
-
-
半结构化数据 spark中可以通过方法将半结构化数据转化为结构化数据(DataFrame)
-
xml和json
-
描述数据的存储结构,但是无法描述数据的类型
-
<name>zhansan</name>
<age>18</age>
{
name:zhangsan
}-
非结构化数据 rdd可以处理
-
文本,图片,视频
-
4. 特点
4.1 易整合
sparkSQL 可以在spark的编程中,将SQL和算子进混合使用,使编程更加的灵活
val res = spark.sql("select * from tb_user")
res.map()4.2 统一的数据访问方式
sparkSQL为各种不同类型的数据源提供统一的访问方式,可以跨各类数据源进行join,支持的数据源如:csv,tcv(tab键作为分隔符),hive,Avro,Parquet,orc(列式存储文件格式,本身就是有结构的),json,jdbc
-
使用read方法可以读取hdfs数据,mysql数据,不同类型的文件数据(json,csv,orc)
-
使用write方法可以写入hdfs,mysql不同类型的文件
4.3 兼容hive
sparkSQL支持hiveSQL语法以及hive的SerDes,UDFs,并且允许访问已经存在的hive数仓数据
4.4 提供标准的数据连接
sparkSQL的server模式,可以为各类bi工具提供标准的JDBC、ODBC连接
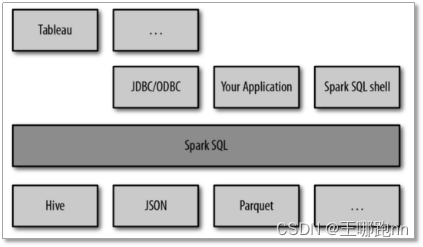
SparkSQL可以看做一个转换层,向下对接各种不同的结构化数据源,向上提供不同的数据访问方式
5 Spark的数据模型介绍
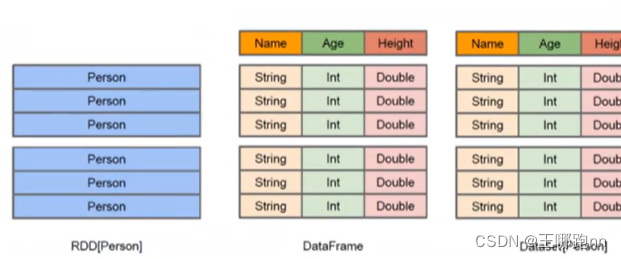
spark封装一个基础数据模型(数据类型)rdd
然后根据rdd进行再次封装,得到新的数据类型 dataframe
然后根据dataframe再次封装得到了dataset类型
-
rdd 弹性分布式集合 使用python,java,scala,c,R.
[1,zhangsan,20,2,lisi,22]-
Dataframe 类型 结构化数据 行列,表信息(数据的属性(字段)和类型) 使用python,java,scala,c,R
-
row类 行数据 rdd中一个列表元素
-
schema类 表信息
-
[
row1=[1,zhangsan,20],
row2=[1,lisi,22]
]
schema
{
id:int,
name:string,
age:int
}-
datasets类型 结构化数据 java,scala
-
row类 一行数据 一个dataframe
-
schema类 表信息
-
从dataset中取出一行数据可以当作dataframe类型操作
-
[
row1=[1,zhangsan,20],
row2=[1,lisi,22]
]
schema
{
id:int,
name:string,
age:int
}
row1 可以当做dataframe进行操作