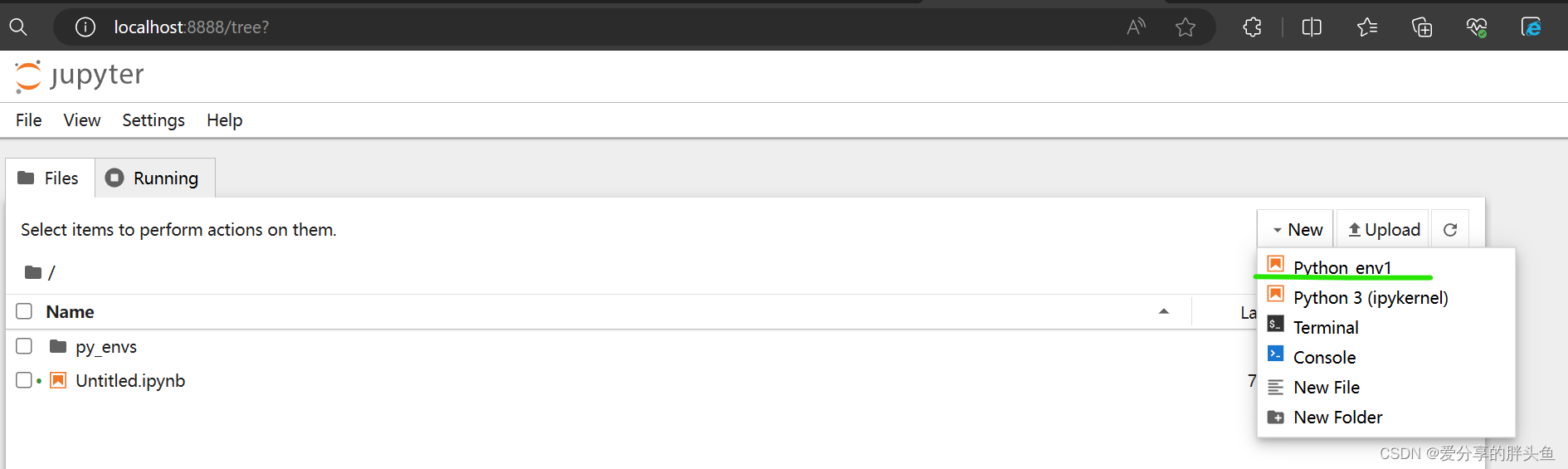
题目:填充NaN值 (Python)
给定一个包含三列的DataFrame:client_id、ranking、value
编写一个函数,将value列中的NaN值用相同client_id的前一个非NaN值填充,按升序排列。
如果不存在前一个client_id,则返回前一个值。
输入:
print(clients_df)
| client_id | ranking | value |
|---|---|---|
| 1001 | 1 | 1000 |
| 1001 | 2 | NaN |
| 1001 | 3 | 1200 |
| 1002 | 1 | 1500 |
| 1002 | 2 | 1250 |
| 1002 | 3 | NaN |
| 1003 | 1 | 1100 |
| 1003 | 2 | NaN |
输出:
| client_id | ranking | value |
|---|---|---|
| 1001 | 1 | 1000 |
| 1002 | 1 | 1500 |
| 1003 | 1 | 1100 |
| 1001 | 2 | 1000 |
| 1002 | 2 | 1250 |
| 1003 | 2 | 1100 |
| 1001 | 3 | 1200 |
| 1002 | 3 | 1250 |
答案
解题思路
该问题的关键在于确定每个NaN值应该被填充的值。我们需要按照client_id和ranking升序排列DataFrame,并逐行处理NaN值。
答案代码
import pandas as pd
def fill_nan(df):
df.sort_values(by=['client_id', 'ranking'], inplace=True) # 按client_id和ranking升序排列
df['value'] = df.groupby('client_id')['value'].ffill() # 使用前一个非NaN值填充NaN
return df
# 示例DataFrame
clients_df = pd.DataFrame({
'client_id': [1001, 1001, 1001, 1002, 1002, 1002, 1003, 1003],
'ranking': [1, 2, 3, 1, 2, 3, 1, 2],
'value': [1000, None, 1200, 1500, 1250, None, 1100, None]
})
print(fill_nan(clients_df))
groupby/sort_value/ffill
groupby()
官方文档:
pandas.DataFrame.groupby — pandas 2.2.2 documentation
语法说明:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,dropna=True)
by: 指定用于分组的列名或列名列表。axis: 指定分组的轴向,默认为 0 表示按行分组。level: 如果轴是多层索引的,则指定要在该级别上分组。as_index: 指定是否将分组键作为索引,默认为 True。dropna: 指定是否将 NaN 值排除在分组之外,默认为 True。
参数
axis: 在2.1.0之后的版本被移除。对于axis=1,使用frame.T.groupby(...)。
sort_values()
官方文档:pandas.DataFrame.sort_values — pandas 2.2.2 documentation
语法说明:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False)
by: 指定用于排序的列名或列名列表。axis: 指定排序的轴向,默认为 0 表示按行排序。ascending: 指定是否按升序排序,默认为 True。inplace: 指定是否在原地排序,默认为 False。
ffill()
官方文档 :pandas.DataFrame.ffill — pandas 2.2.2 documentation
语法说明:
DataFrame.ffill(axis=None, inplace=False, limit=None)
axis: 指定填充方向,默认为 None 表示沿着列的方向填充。inplace: 指定是否在原地填充,默认为 False。limit: 指定填充的最大连续 NaN 值的数量,默认为 None 表示不限制。
ffill是 “forward fill”,向前填充缺失值,与之相对应的是bfill,全称是 “backward fill”,意思是向后填充缺失值,即使用后一个非 NaN 值来填充缺失值。
更多详细答案可关注公众号查阅。