目录
一.介绍
二.实际工作
A.图像阴影去除
B.图像去雨
C.存储模块的开发
三.网络结构
A.内存扩充
B.损失函数设计
四.实验
A.与最先进方法的比较
B.MemoryNet消融研究
五.结论
CVPR2023 MemoryNet 记忆增强是图像恢复所需要的一切
论文地址https://arxiv.org/abs/2309.01377
摘要
图像恢复是一个低层次的视觉任务,大多数CNN方法被设计为一个黑盒子,缺乏透明度和内部美学。虽然已经提出了一些将传统优化算法与DNN相结合的方法,但它们都有一定的局限性。在本文中,我们提出了一个三粒度的记忆层和对比学习称为MemoryNet,具体来说,将样本分为积极的,消极的,和实际的三个样本进行对比学习,其中记忆层能够保持图像的深层特征,对比学习收敛学习的特征,以平衡。在Derain/Deshadow/Deflur任务上的实验表明,这些方法能有效地提高恢复性能。此外,本文的模型在三种不同退化类型的数据集上都获得了显著的PSNR、SSIM增益,这有力地证明了恢复的图像是真实感的。
一.介绍
图像恢复是一个低层次的视觉任务,它指的是退化图像的恢复。近年来,计算机视觉技术的飞速发展使得越来越多的图像退化任务成为可能,包括超分辨率、单幅图像去雾、图像去阴影、图像去雨等。
图像复原是一个非常令人不安的问题,因为存在无限多的可行解。图像先验用于[1]-[7]将解空间限制为有效/自然图像。然而,设计这样的先验是一项具有挑战性的任务,并且通常不能推广。为了改善这个问题,最近的最先进的方法[8]-[16]采用卷积神经网络(CNN)通过捕获自然图像来隐式地学习更一般的先验大规模数据统计。基于CNN的方法的模型设计是其性能优于其他方法的主要原因。随着生成对抗网络的成功,已经引入了一些用于失真图像恢复的生成模型,例如图像修复[17]-[21],图像阴影去除[22],图像雨去除[26],[28]和图像云去除[27]。以图像去阴影为例,这些方法将失真恢复问题归结为寻找合适的变形和预测稠密网格,取得了较好的效果。然而,现有的努力主要集中在模型的结构,一个机会,被广泛忽视的是记忆学习方法。
我们认为图像恢复研究存在两个问题:第一,当模型收敛时,暴露出一个局限性问题:性能不能显著提高,此时模型仍然饱和。出乎意料的是,这些限制不能通过简单地添加更多层来解决。事实上,当训练数据集给定时,它的分布是客观的和固定的。出乎意料的是,这些限制不能通过简单地添加更多层来解决。
因此,如何在保持原有底层网络不变的情况下,让网络学习到更多的潜在信息,是一个非常难解决的问题。第二,阴影去除不像图像修复,整个区域都是白色阴影,它必须在保留原始图像特征的情况下对半暗区域进行某些操作,这很难实现,因为需要考虑阴影区域下的真实的图像信息。因此,我们设计了MemoryNet,具体分为记忆增强和对比学习。一方面,为了解决上述第一个问题,本文引入了一个新的记忆增强模块,MA(记忆增强)额外建模一个可学习的潜在属性变量,以记住代表性结构的原型模式在一个全球范围内,通常涵盖了不同的身份样本。通过预测增加这种记忆可能性,可以增加模型对未见过类的置信度。MA还传达了从先前查看的样本中学习到的额外域级低频信息,用于协作决策,避免了类似GAP的语义抽象。为了获得更多的细节,我们通过阅读内存来重新收集特征到预定义的由粗到细的原型索引中以进行进一步的相似性度量。与在两幅图像中搜索相关的区分区域不同,这种原型对齐是轻量级的,类似于多级哈希。记忆增强网络很好地增强了图像去阴影的应用效果,证明了它在消融研究中的有效性。另一方面,为了解决第二个问题,我们设计了一个弱监督学习的对比学习网络,如图2所示。我们将图像去阴影任务定义为一个三级分类问题,对应于正样本(干净样本),标准样本(去阴影样本)和负样本(阴影样本),全局特征作为锚点,使模型能够区分全局特征和局部特征是否来自同一图像。因此,对比学习通过对比学习上边界和下边界将锚定图像约束为闭合图像,这有助于恢复网络接近正图像,同时避免负图像。
我们在图像去阴影/图像去雨/图像去模糊三个任务上进行了大量的实验,都取得了令人满意的结果。本文的结果如图1所示。这项工作的主要贡献是:
1)在本文中,一个新的端到端的网络名为MemoryNet的图像恢复,它产生的上下文丰富和空间准确的输出。
2)在本文中,我们设计了一种新的记忆增强层,它模拟一个可学习的潜在属性变量,以记住全局代表性的结构原型模式。
3)我们对三个典型的图像恢复任务进行了广泛的实验,即,合成图像去阴影,真实的图像去噪,图像去模糊,表明我们提出的MemoryNet取得了很大的效果,同时保持了有吸引力的计算复杂度。此外,我们提供详细的消融研究,定性结果和泛化测试。

Fig. 1.MemoryNet的图像阴影去除和图像去重的结果

图2.MemoryNet的结构,分为记忆增强网络和对比学习。
二.实际工作
A.图像阴影去除
虽然本文的主要贡献是提出了一个数据集SRD,但DeshadowNet [23]最早的弱监督第一个具有完全自动端到端实现阴影去除的最大特征(A New Dataset for Shadow Removal)。为了共同利用彼此进步的好处,ST-CGAN [22]提供了一个多任务处理的视角,与所有其他现有方法不同,因为它以端到端的方式一起学习检测和消除。通过估计线性变换函数,SID和DSC [38],[39]创建深度网络来照亮阴影区域。半阴影(half shadow)RSI-GAN [40]创建了一个广泛的框架,使用多个GAN来挖掘照明和残差数据,以消除阴影。DHAN [41]使用双层聚合网络(DHAN)来消除边界伪影。自动曝光[42],[44]旨在挖掘阴影和非阴影区域的上下文信息。
弱监督阴影去除根据MaskshadowGAN [43],阴影去除挑战的先前深度学习方法是有监督的配对数据。然而,获取匹配的数据集可能是一个挑战。根据LG-shadow [46]在实际实践中,CNN训练更倾向于不成对的数据,因为它更容易训练。SpA-Former [50]建议基于注意力机制的Transformer网络与Transformer一起学习阴影空间注意力图。
无监督学习阴影去除
G2R [48]利用了阴影照片经常有阴影和非阴影区域的事实。通过使用这种技术,可以裁剪阴影和未阴影补丁的集合,为网络训练提供不成对的数据,提供三个子网络模块的可能性:阴影产生,阴影消除和阴影细化。阴影消除任务由TC-GAN [49]以无监督的方式执行。对比了基于循环一致性的双向映射方法和基于GAN的无监督阴影去除方法。
B.图像去雨
监督去雨注意力机制被引入到生成器和生成器中,它还在多个时间步上生成注意力图,并识别原始图中网络必须注意的区域:雨点及其周围环境。NEDNet [29]的编码器—解码器架构引用了非局部增强,它成功地去除了不同密度的雨,同时完美地保持了图像细节。Yang [30]提出了一种新的流水线:为了完成去雨,首先检测雨的位置,然后估计雨线,最后去除背景层。Ren [31]提供了一个起点:该模型由六个阶段组成,每个阶段分为两个模型,并接收初始降雨图和在其之前的步骤中产生的降水图的拼接作为输入。
半监督雨水去除Wei和Huang [32],[33]提出了半监督模型,可以记录不同的雨水退化原型,并通过自监督学习更新它们。
无监督雨水提取Guo [34]提出了无监督注意机制引导的雨水提取模型E.他们对下雨和无雨地图的空间域使用注意力机制,并使用带有两个约束分支的CycleGAN循环结构来消除降雨。
C.存储模块的开发
董功[53]首先将内存模块引入异常检测任务,认为Encoder可以作为查询生成器;解码器的输入是Memory模块生成的大小为(H,W,C)的新特征图,用于重建生成的图像,可以解释为重建Encoder特征图,生成的新特征图包含更多关于正常帧的信息,这使得解码器对异常帧进行重构,重构后得到较大的重构误差。Park [54]的核心思想是丰富Auto Encoder中的正常帧信息,以便在测试时更好地区分正常帧和异常帧,达到视频异常检测的目的。MMOS [62]是一项非常重要的任务,他们认为最重要的环节是用于模拟/存储降雨退化过程的不同降雨模式的中间存储器模块。具体地说,z(x)相当于一个查询,在内存中找到最相关的项目,并将它们与软注意力联合收割机结合起来,作为除雨任务的指导。Chen F [55]是存储模块的一个端口,用于行人重新识别的任务。
三.网络结构
MemoryNet受到[51]-[54]的启发,如图2所示.该网络主要由两部分组成。第一部分是内存扩充部分,它由两个编解码器网络和一个残差网络组成。本文使用编码器-解码器来学习多尺度上下文信息,而最后阶段对原始图像分辨率进行操作以保留精细的空间细节。第二部分是对比学习网络。
我们不是简单地级联多个阶段,而是在每两个阶段之间添加一个监督注意模块。在真实的图像的监督下,我们的模块重新调整前一阶段的特征图,然后将其传递到下一阶段。此外,我们引入了一个跨阶段的功能融合机制,在该机制中,早期子网络的中间多尺度上下文功能有助于巩固后期子网络的中间功能。
A.内存扩充
1)如何检测异常区域?:我们把模糊看作是一种异常模式,因此我们应该检测出哪里是异常的,并把异常的细化为正常的。在这种直觉下,我们将联合收割机异常检测和完成代理结合起来。此基线对于Transformer框架是可行的。在这里,我们将阴影img定义为异常,将干净img定义为正常。我们遵循传统的异常检测的编码器和解码器结构,首先将干净的图像发送到内存增强的编码器/解码器以记录正常模式。你可以按照[56]来进行这样的结构。你不需要改变原始框架的基本编码器/解码器,只需要在其中插入内存和监督。经过训练这个异常检测阶段,编码器和解码器满足重建能力,而内存记录正常模式。当我们发送了一个模糊的img,这个模型是无法恢复它的清洁。
2)如何将异常转为正常?:其基本思想类似于上下文编码器/解码器,因为我们将去阴影称为类似于完成的代理任务。在训练阶段,我们已经知道编码器在去阴影方面很弱,因为我们只使用干净的imgs训练它。因此,我们引入一个潜在的上下文回归恢复模糊区域。
3)记忆增强:记忆增强的结构如图3所示。然而,当输入是不规则帧时,由于CNN模型的高表征能力,重建误差是最小的,这会导致结果是错误的。这个问题通过在编码器和解码器中添加存储器模块来解决,这使得编码器和解码器能够记录正常帧属性,并削弱CNN的表征能力,以便区分正常和异常帧。在这项研究中,我们重新制定了基于分类的排名检索的最终CNN层的可解释概率处理。然后,为了减少领域偏差,我们构建了一个层次化的记忆调整和对齐模块。

图三.译码器和编码器中的内存扩充结构
记忆模块包含由具有固定特征维数C的度量M ∈ RN × C记录的N个原型。N是Memory项的数量,根据需要调整的超参数,并且存储器寻址计算每个查询相对于所有存储器项的权重,然后使用基于注意力的寻址算子来访问存储器,即,然后使用存储器读取器将每个图像分配给备用原型:
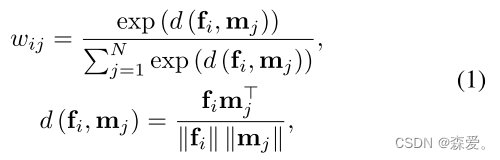
其中fi和mj是来自输入f的特征和原型切片原型度量M。wij是用于测量fi和mj之间的余弦相似度d(—,—)的归一化权重。因此,从特征f分配的原型可以计算为h:
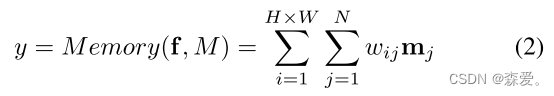
我们构建了图2所示的记忆增强。MA(记忆增强)由原型M组成的分层语义组成,即,部分实例语义,以避免过度抽象。实例原型和语义原型是从前面的低级别原型中总结出来的。因此,当跨越原型的存储槽中的各种语义差异时,M被共享以表示所有通用概念样本。具体来说,我们定义原型度量M为2×(P× I × S ×Nc)×C shape,其中P、I和S分别是为部件、实例和语义层预定义的原型数,Nc是类别数。在总结语义原型之前,为两种模态复制每个部件和实例原型。因此,对于内部模态空缺,我们将单个模态保留在较低级别的代表性模态部分和实例原型中,然后在语义级别上将它们联合对齐。如图2所示,每个较高级别的原型项都可以总结其较低的范围。例如,实例原型子度量Min的第i行mins,i可以被视为加权子段Mpart。
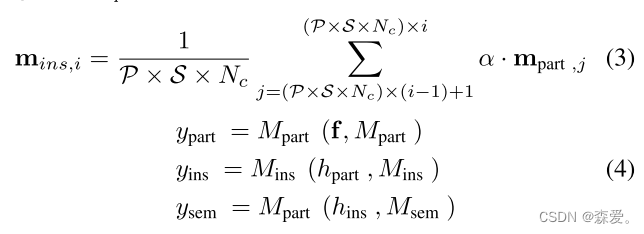
经过训练后的异常检测阶段,编码器和解码器满足重建能力,而存储器记录正常模式。当我们发送了一个模糊的img,这个模型是无法恢复它的清洁。因此,每个阶段的encode输入为:

其中SFe表示浅特征融合产物。同时,在这个记忆增强阶段,异常特征和正常特征被重构,我们称之为Lrecon,定义如下:
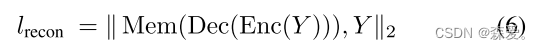
B.损失函数设计
下面是MemoryNet的损失函数:
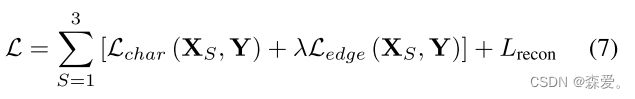
其中Y表示地面实况图像,Lchar是Charbonnier损失:
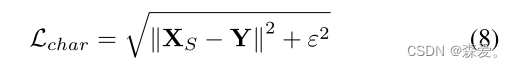
对于所有的实验,常数Δ λ经验性地设置为10(3)。此外,Ledge是边缘损失,定义为:
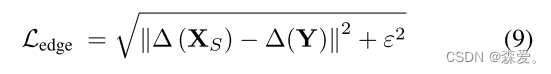
四.实验
实现细节 我们的CR-MemoryNet是一个端到端的可训练模型,不需要任何预训练。它使用PyTorch 1.8.0和NVIDIA GTX 3090 GPU实现。在本文中,我们选择了三个评价指标,PSNR和SSIM,和RMSE。
阴影去除 本文使用的数据集是ISTD [22]。我们根据经验使用Adam优化器来优化我们的网络。在我们的实验中,我们将第一个动量值、第二个动量值的权重分别设置为0.9、0.999和5 × 10 − 4。ISTD包括540个测试三元组和1330个训练三元组的阴影、阴影掩蔽和非阴影图片。对于训练和测试,SRD分别包含2680和408对图像。
真实的除雨 我们使用DeRainDrop数据集[25]进行训练和测试。它提供861个图像对用于训练,并具有两个测试数据集(即,测试A和测试B)。TestA是testB的子集,其中包含58对对齐良好的图像。TestB有249个图像对,其中一小部分图像没有完全对齐。
图像去模糊 对于图像去模糊,类似于[51],[64]—[66],我们使用GoPro [67]中的2,103个图像对训练我们的模型,与预定义的模糊内核不同,这两个数据集是在涉及真实世界退化因素的真实的场景中生成的,例如相机响应函数和人类意识动态模糊。
A.与最先进方法的比较
1)阴影消除:我们的方法与现有的方法进行了比较,包括Yang [37],Guo [35],Gong [36],DeShadowNet [23],STC—GAN [22],DSC [39],Mask—ShadowGAN [43],RIS—GAN [40],DHAN [41],SID [38],LG—shadow [46],G2R [48],DC—ShadowNet [24],Auto—exp [42],SpA—Former [50],CANet [44].我们采用均方根误差(RMSE),结构相似性指数(SSIM)和峰值信噪比(PSNR)在LAB颜色空间作为评价指标。表1分别报告了ISTD数据集上不同阴影去除方法的RMSE、SSIM和PSNR值[22]。定量比较如图4所示。MemoryNet在部分阴影、非部分阴影和无阴影区域的PSNR上都取得了最好的性能,本文的RMSE在无阴影区域也取得了最好的性能,总体上优于SOTA。SID [38]和G2R [48]可能会错误地处理相对较暗的非阴影区域,从而导致一些错误估计。事实证明,他们的模型未能充分利用阴影掩模信息,即使他们的网络输入包含阴影掩模。Auto—exp [42]和CANet [44]使用三元组数据集(输入,掩码,目标),在指标方面表现良好。但在实际应用中是否有必要获得阴影的掩模。从应用的角度来看,这是没有实际价值的。本文的训练只需要成对的数据,测试只需要一个简单的阴影图,具有很强的实际意义。
表1基于ISTD的图像阴影去除性能比较。(红标代表排名第一,蓝标代表排名第二)


见图4。ISTD数据集上图像去阴影的视觉性能比较
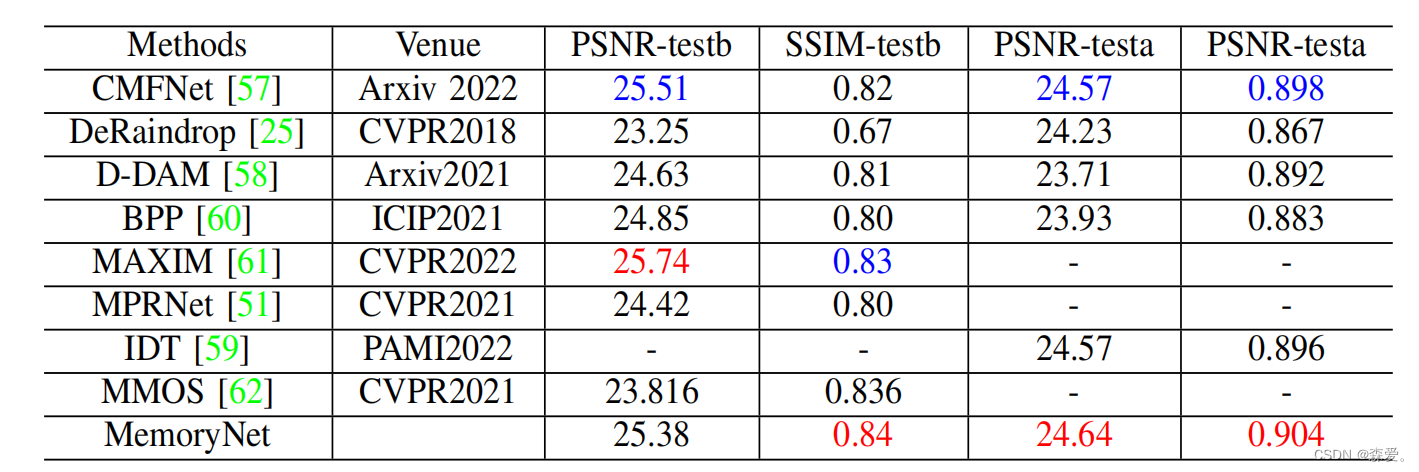
2)雨水去除:如表II和图5所示,我们报告了DeRainDrop testB和testa数据集上雨水去除的PSNR/SSIM评分方法。我们的方法与现有方法进行了比较,包括CMFNet [57],D-DAM [58],BPP [60],Maxim [61],IDT [59]。我们的MemoryNet在测试b上获得了最好的最佳SSIM分数(0.84)和第二好的PSNR分数(25.38)dB,在测试a上获得了最好的SSIM分数(0.904)和最好的PSNR(24.64)dB。图中显示了DeRainDrop test-b图像的可视化结果,这很好地证明了我们的方法有效地去除了雨滴,并且恢复的图像在视觉上比其他模型更接近真实的图像。为了与同样使用内存模块的除雨网络MMOS [62]进行比较,我们也在MMOS上进行了除雨实验,但结果是现实的,MMOS在真实的除雨数据集上效果不佳,我们假设这可能是由于在真实数据计算中,噪声数据的使用没有成功与目标网络生成的伪标签配对。
表二雨滴(TESTA和TESTB)除雨性能对比红色代表排名第一,蓝色代表排名第二

图五.Raindrop数据集上图像去噪的视觉性能比较
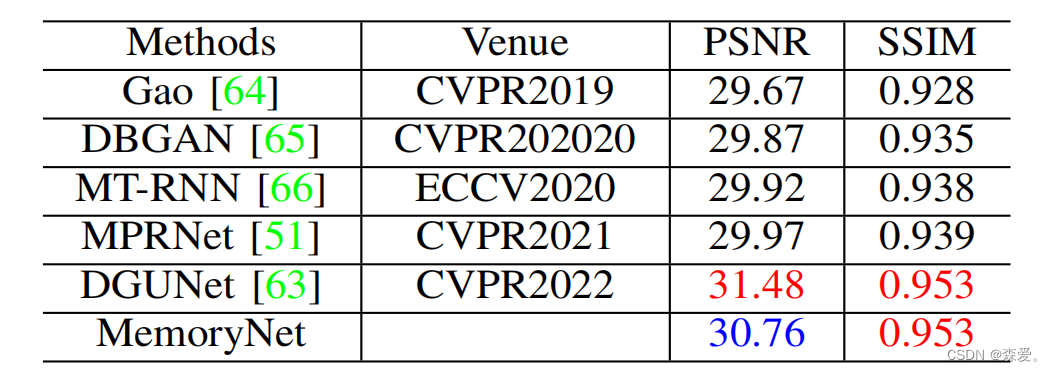
3)图像去模糊:在表III和图6中,我们报告了去模糊任务的PSNR/SSIM评分方法。我们比较了几个非常有竞争力的算法,包括Gao [64],DBGAN [65],MT—RNN [66],MPRNet [51]和DGUNet [63],定量评估结果如表III所示,尽管我们的MemoryNet没有达到最佳性能,但评估得分仍然令人满意。这意味着所提出的模型可以处理发生的退化,并且DGUNet的结果和指标是迄今为止最好的,这在很大程度上要归功于其梯度策略,它们将其集成到近端梯度下降(PGD)算法的梯度下降步骤中,从而推动其处理复杂和真实世界的图像退化。
表3GOPRO数据集上图像去毛刺的性能比较)。红色代表排名第一,蓝色代表排名第二

见图6。GOPRO数据集上图像去模糊的视觉性能比较
B.MemoryNet消融研究
记忆增强的定量比较
为了验证本文提出的记忆增强和比较学习的有效性,我们对ISTD数据集进行了消融研究,如图7和表IV所示。因为每个Memory项计算与所有查询的余弦相似度,并且相似度完成,所以我们替换我们的Memory层,一个用于三分支,一个用于两分支,一个用于单分支。我们进行了消融实验,以检查它是否是成功的记忆增强,和表显示,记忆增强是更适合在本研究中的三阶段恢复网络。为了更好地可视化本文提出的内存所扮演的角色,我们在一个轻量级网络中进行了特征可视化,如图7所示,输入是一张模态照片,第一层先经过Memory增强,然后是卷积层,如图所示,我们可以看到添加内存后的特征图更适合网络传播,而未添加存储器的原始特征图明显偏离原始图像。
表4 ISTD数据集阴影消除的消融研究


见图7。内存增强层的特征可视化,左边是第一层未经任何处理的特征图,右边是第一层经过内存增强后的特征图
对比学习的定量比较
对比学习与生成学习不同,它不需要关注实例的繁琐细节,而只需要学习在抽象语义层面上区分特征空间上的数据,因此模型及其优化变得更简单,具有更强的泛化能力。在这项研究中,我们在残差网络后面添加了对比学习,将其转换为一个编码器,目标是学习一个编码器,该编码器编码同类的类似数据,同时使各类数据的编码结果尽可能不同。如表IV所示,本文中的比较学习在去阴影等任务中很有帮助,可以更好地改进指标。本文将记忆网络和对比学习相结合,可以明显地提高PSNR到33.44,SSIM到0.986,RMSE到6.03。
五.结论
本文提出了一种通用的图像恢复网络MemoryNet,它由记忆增强和对比学习网络组成。它可以恢复退化图像,包括阴影,雨和模糊。这三个实验表明,这些方法是有效的,在提高恢复性能。此外,本文的模型在三种不同退化类型的数据集上都获得了显著的PSNR、SSIM增益,这有力地证明了恢复的图像是真实感的。在未来,我们将尝试更多不同的恢复任务,如图像增强,条纹消除等。