课程地址
最近做实验发现自己还是基础框架上掌握得不好,于是开始重学一遍PyTorch框架,这个是课程笔记,这个课还是讲的简略,我半小时的课听了一个半小时。
1. 张量
1.1 张量操作
(1)chunk:将一个张量分割为特定数目的张量,每个块都是输入张量的视图。
- 按维度0分割:
import torch
b = torch.rand([3, 2]) # 随机生成3x2维度的张量
print("b=", b)
c, d = torch.chunk(b, chunks=2) # 将b分割为c和d两个张量,默认沿着维度0去分割(按行分割)
print("c=", c)
print("d=", d) # 最后一个张量维度会稍微小一点,因为3不能被2整除
运行结果:
b= tensor([[0.7704, 0.8685],
[0.0165, 0.5076],
[0.2730, 0.2270]])
c= tensor([[0.7704, 0.8685],
[0.0165, 0.5076]])
d= tensor([[0.2730, 0.2270]])
- 按维度1分割:
import torch
b = torch.rand([3, 2]) # 随机生成3x2维度的张量
print("b=", b)
c, d = torch.chunk(b, chunks=2, dim=1) # 将b分割为c和d两个张量,默认沿着维度1去分割(按列分割)
print("c=", c)
print("d=", d) # 最后一个张量维度会稍微小一点,因为3不能被2整除
运行结果:
b= tensor([[0.1275, 0.9670],
[0.5189, 0.0748],
[0.6840, 0.7675]])
c= tensor([[0.1275],
[0.5189],
[0.6840]])
d= tensor([[0.9670],
[0.0748],
[0.7675]])
(2)dsplit:将具有三个或更多维度的张量按深度拆分为多个张量。
import torch
# 按深度划分(按最后一个维度划分),看打印结果
a = torch.arange(16.0).reshape(2, 2, 4)
print(a)
b = torch.dsplit(a, 2) # 均分两份
print(b)
c = torch.dsplit(a, [3, 6]) # 第一份是按最后一个维度取前三个值,第二份是6个
print(c)
d = torch.dsplit(a, [2, 4]) # 第一份是1个,第二份是4个
print(d)
e = torch.dsplit(a, [1, 1, 2]) # 第一份是1个,第二份是1个,第三分是2个
print(e)
运行结果:
tensor([[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.]],
[[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]])
(tensor([[[ 0., 1.],
[ 4., 5.]],
[[ 8., 9.],
[12., 13.]]]), tensor([[[ 2., 3.],
[ 6., 7.]],
[[10., 11.],
[14., 15.]]]))
(tensor([[[ 0., 1., 2.],
[ 4., 5., 6.]],
[[ 8., 9., 10.],
[12., 13., 14.]]]), tensor([[[ 3.],
[ 7.]],
[[11.],
[15.]]]), tensor([], size=(2, 2, 0)))
(tensor([[[ 0., 1.],
[ 4., 5.]],
[[ 8., 9.],
[12., 13.]]]), tensor([[[ 2., 3.],
[ 6., 7.]],
[[10., 11.],
[14., 15.]]]), tensor([], size=(2, 2, 0)))
(tensor([[[ 0.],
[ 4.]],
[[ 8.],
[12.]]]), tensor([], size=(2, 2, 0)), tensor([[[ 1.],
[ 5.]],
[[ 9.],
[13.]]]), tensor([[[ 2., 3.],
[ 6., 7.]],
[[10., 11.],
[14., 15.]]]))
(3)dstack:按深度顺序(沿第三轴)堆叠张量。
import torch
a = torch.tensor([1, 2, 3]) # 行向量
b = torch.tensor([4, 5, 6])
print(torch.dstack((a,b)))
a = torch.tensor([[1],[2],[3]]) # 列向量
b = torch.tensor([[4],[5],[6]])
print(torch.dstack((a,b)))
运行结果:
tensor([[[1, 4],
[2, 5],
[3, 6]]])
tensor([[[1, 4]],
[[2, 5]],
[[3, 6]]])
(4)hstack:按水平顺序堆叠张量(按列)
import torch
a = torch.tensor([1, 2, 3]) # 行向量
b = torch.tensor([4, 5, 6])
print(torch.hstack((a,b)))
a = torch.tensor([[1],[2],[3]]) # 列向量
b = torch.tensor([[4],[5],[6]])
print(torch.hstack((a,b)))
运行结果:
tensor([1, 2, 3, 4, 5, 6])
tensor([[1, 4],
[2, 5],
[3, 6]])
(5)gather:沿着某一个维度取变量(根据索引取变量,这个一看就晕,但是我找到了一篇比较好的文章讲解这个)
torch.gather() 和torch.sactter_()的用法简析,这个讲的最好,我就是按照这个学的
import torch
t = torch.tensor([[1, 2], [3, 4]])
a = torch.gather(t, 1, torch.tensor([[0, 0], [1, 0]])) # 按维度1和[[0, 0], [1, 0]]的下标取张量t的元素
# out[i,j] = t[i][a[i, j]]
# out[0,0] = t[0][a[0, 0]]=t[0][0]=1
# out[0,1] = t[0][a[0, 1]]=t[0][0]=1
# 所以out[0]=[1, 1]
# out[1,0] = t[1][a[1, 0]]=t[1][1]=4
# out[1,1] = t[1][a[1, 1]]=t[1][0]=3
# 所以out[1]=[4, 5]
# 所以out=[[1, 1], [4, 3]]
print(a)
a = torch.gather(t, 0, torch.tensor([[0, 0], [1, 0]])) # 按维度0和[[0, 0], [1, 0]]的下标取张量t的元素
# out[i,j] = t[a[i, j]][j]
# out[0,0] = t[a[0, 0]][0]=t[0][0]=1
# out[0,1] = t[a[0, 1]][1]=t[0][1]=2
# 所以out[0]=[1, 2]
# out[1,0] = t[a[1, 0]][0]=t[1][0]=3
# out[1,1] = t[a[1, 1]][1]=t[0][1]=2
# 所以out[1]=[3, 2]
# 所以out=[[1, 2], [3, 2]]
print(a)
运行结果:
tensor([[1, 1],
[4, 3]])
tensor([[1, 2],
[3, 2]])
(6)reshape:返回一个张量,其数据和元素数量与输入相同,但具有指定的形状,改变形状,不改变顺序,比如原来是从左到右,然后改成多行后,是按从左到右从上到下顺序重新改变形状。
import torch
a = torch.arange(4.) # 生成从0到3的一维张量
print(torch.reshape(a, (2, 2))) # 改成2X2张量
b = torch.tensor([[0, 1], [2, 3]])
print(torch.reshape(b, (-1,))) # -1,自动推断变成一维
运行结果:
tensor([[0., 1.],
[2., 3.]])
tensor([0, 1, 2, 3])
【注】一般在方法名后面加下划线的都是原地操作,内存位置不会发生改变
(7)scatter_: torch.gather() 和torch.sactter_()的用法简析,按索引张量更新元素。
import torch
src = torch.arange(1, 11).reshape((2, 5))
print(src)
index = torch.tensor([[0, 1, 2, 0]])
a = torch.zeros(3, 5, dtype=src.dtype) # 初始化一个和src张量数据类型一样的3X5的0张量,
# 这样方便观察,非0的部分就是修改过的
z = a.scatter_(0, index, src) # 按索引张量将src中的元素写入到z中,按维度0写入
# z[index[i][j],j]=src[i][j],index中i只有0,j从0到3
# z[index[0][0],0]=z[0,0]=src[0][0]=1
# z[index[0][1],1]=z[1,1]=src[1][1]=6
# z[index[0][2],2]=z[2,2]=src[2][2](i越界1个,相当于又变回0,索引只有(0,1),则2对应的应该是0,1,0的0,以此类推循环)=src[0][2]=3
# z[index[0][3],3]=z[0,3]=src[0][3]=4
print(z)
a = torch.zeros(3, 5, dtype=src.dtype)
z = a.scatter_(1, index, src) # 按索引张量将src中的元素写入到z中,按维度1写入
# z[i,index[i][j]]=src[i][j],index中只有0,j从0到3
# z[0,index[0][0]]=z[0,0]=src[0][0]=1
# z[0,index[0][1]]=z[0,1]=src[0][1]=2
# z[0,index[0][2]]=z[0,2]=src[0][2]=3
# z[0,index[0][3]]=z[0,0]=src[0][3]=4(被覆盖,最终z[0,0]=4)
print(z)
运行结果:
tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
tensor([[1, 0, 0, 4, 0],
[0, 2, 0, 0, 0],
[0, 0, 3, 0, 0]])
tensor([[4, 2, 3, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]])
(8)scatter_add_:以与 scatter_() 类似的方式,将张量 src 中的所有值添加到索引张量中指定的索引处的 self 中。
import torch
src = torch.ones((2, 5))
print(src)
index = torch.tensor([[0, 1, 2, 0, 0]])
z = torch.zeros(3, 5, dtype=src.dtype).scatter_add_(0, index, src) # 按维度0进行相加
print(z)
# z[index[i][j], j]=src[i][j],i只能为0,j从0到4
# z[index[0][0], 0]=z[0,0]=src[0][0]=1
# z[index[0][1], 1]=z[1,1]=src[0][1]=1
# z[index[0][2], 2]=z[2,2]=src[0][2]=1
# z[index[0][3], 3]=z[0,3]=src[0][3]=1
# z[index[0][4], 4]=z[0,4]=src[0][4]=1
运行结果:
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
tensor([[1., 0., 0., 1., 1.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.]])
(9)split:将张量划分为多块,每块都是原来张量的一部分。
import torch
a = torch.arange(10).reshape(5, 2)
print(a)
print(torch.split(a, 2)) # 分成两份,最后一份可能会少一点,要保证前面均分
print(torch.split(a, [1, 4])) # 按1:4比例划分,不指定参数默认按0维度(行)划分
运行结果:
tensor([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
(tensor([[0, 1],
[2, 3]]), tensor([[4, 5],
[6, 7]]), tensor([[8, 9]]))
(tensor([[0, 1]]), tensor([[2, 3],
[4, 5],
[6, 7],
[8, 9]]))
chunk和split的区别:【GPT回答】chunk 函数将张量均匀分成几块,每块大小相等。split 函数可以根据指定的大小或部分来分割张量,每个块的大小可以不相等。总的来说,如果您需要将张量均匀地分成几块,可以使用 chunk 函数。如果您需要更灵活地指定每个块的大小或部分,可以使用 split 函数。
(10)squeeze:将张量中所有维度为1的那个维度移除掉
import torch
a = torch.tensor([[[1, 2, 3], [1, 2, 3]]]) # 2x3x1张量
a = torch.squeeze(a) # 压缩维度为1的维度,变成2维张量,2X3
print(a)
a = torch.tensor([[[[1, 2, 3], [1, 2, 3]]]]) # 2x3x1x1张量
a = torch.squeeze(a) # 压缩维度为1的维度,变成2维张量,2X3
print(a)
# 压缩指定的维度为1的维度(PyTorch低于2.0版本,指定的维度不能是list(就是相当于用list的元素多次指定要压缩的维度为1的维度的索引),所以这里写dim = 2)
a = torch.tensor([[[[1, 2, 3], [1, 2, 3]]]]) # 2x3x1x1张量
a = torch.squeeze(a, dim=2) # 压缩维度为1的维度,且索引为2,变成3维张量,2X3x1
print(a)
运行结果:
tensor([[1, 2, 3],
[1, 2, 3]])
tensor([[1, 2, 3],
[1, 2, 3]])
tensor([[[[1, 2, 3],
[1, 2, 3]]]])
(11)stack:沿着某一个新的维度将一系列张量拼接起来。
import torch
a = torch.ones(3, 2) # 3x2 全是1的张量
b = torch.zeros(3, 2) # 3x3 全是0的张量
c = torch.stack([a, b]) # dim 默认为0,它们合并到新的张量的第0维,新的张量的元素分别是a, b,相当于最后是一个三维张量
print(c)
c = torch.stack([a, b], dim=1) # 按行拼接
print(c)
运行结果:
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
tensor([[[1., 1.],
[0., 0.]],
[[1., 1.],
[0., 0.]],
[[1., 1.],
[0., 0.]]])
进程已结束,退出代码0
它们是这样的张量(接下来的看法可能不对):

如果按维度0进行拼接,

(后面全是1),按0维度这样看就是
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
如果按维度1拼接,
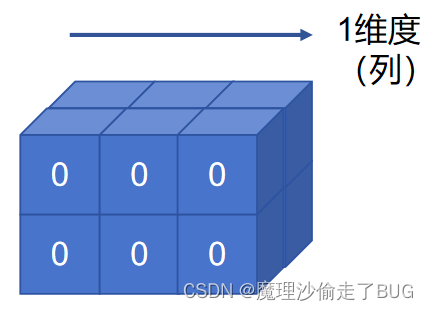
按1维度这样看就是
tensor([[[1., 1.],
[0., 0.]],
[[1., 1.],
[0., 0.]],
[[1., 1.],
[0., 0.]]])