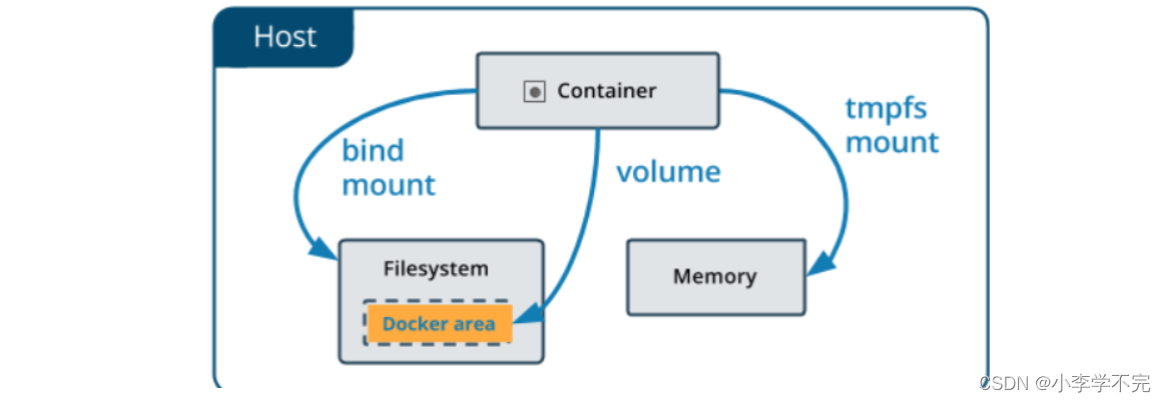
第一步:DDcolor介绍
DDColor 是最新的 SOTA 图像上色算法,能够对输入的黑白图像生成自然生动的彩色结果,使用 UNet 结构的骨干网络和图像解码器分别实现图像特征提取和特征图上采样,并利用 Transformer 结构的颜色解码器完成基于视觉语义的颜色查询,最终聚合输出彩色通道预测结果。

它甚至可以对动漫游戏中的风景进行着色/重新着色,将您的动画风景转变为逼真的现实生活风格!(图片来源:原神)

第二步:DDcolor网络结构
算法整体流程如下图,使用 UNet 结构的骨干网络和图像解码器分别实现图像特征提取和特征图上采样,并利用 Transformer 结构的颜色解码器完成基于视觉语义的颜色查询,最终聚合输出彩色通道预测结果。

第三步:模型代码展示
import os
import torch
from collections import OrderedDict
from os import path as osp
from tqdm import tqdm
import numpy as np
from basicsr.archs import build_network
from basicsr.losses import build_loss
from basicsr.metrics import calculate_metric
from basicsr.utils import get_root_logger, imwrite, tensor2img
from basicsr.utils.img_util import tensor_lab2rgb
from basicsr.utils.dist_util import master_only
from basicsr.utils.registry import MODEL_REGISTRY
from .base_model import BaseModel
from basicsr.metrics.custom_fid import INCEPTION_V3_FID, get_activations, calculate_activation_statistics, calculate_frechet_distance
from basicsr.utils.color_enhance import color_enhacne_blend
@MODEL_REGISTRY.register()
class ColorModel(BaseModel):
"""Colorization model for single image colorization."""
def __init__(self, opt):
super(ColorModel, self).__init__(opt)
# define network net_g
self.net_g = build_network(opt['network_g'])
self.net_g = self.model_to_device(self.net_g)
self.print_network(self.net_g)
# load pretrained model for net_g
load_path = self.opt['path'].get('pretrain_network_g', None)
if load_path is not None:
param_key = self.opt['path'].get('param_key_g', 'params')
self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)
if self.is_train:
self.init_training_settings()
def init_training_settings(self):
train_opt = self.opt['train']
self.ema_decay = train_opt.get('ema_decay', 0)
if self.ema_decay > 0:
logger = get_root_logger()
logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')
# define network net_g with Exponential Moving Average (EMA)
# net_g_ema is used only for testing on one GPU and saving
# There is no need to wrap with DistributedDataParallel
self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
# load pretrained model
load_path = self.opt['path'].get('pretrain_network_g', None)
if load_path is not None:
self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
else:
self.model_ema(0) # copy net_g weight
self.net_g_ema.eval()
# define network net_d
self.net_d = build_network(self.opt['network_d'])
self.net_d = self.model_to_device(self.net_d)
self.print_network(self.net_d)
# load pretrained model for net_d
load_path = self.opt['path'].get('pretrain_network_d', None)
if load_path is not None:
param_key = self.opt['path'].get('param_key_d', 'params')
self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key)
self.net_g.train()
self.net_d.train()
# define losses
if train_opt.get('pixel_opt'):
self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
else:
self.cri_pix = None
if train_opt.get('perceptual_opt'):
self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
else:
self.cri_perceptual = None
if train_opt.get('gan_opt'):
self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)
else:
self.cri_gan = None
if self.cri_pix is None and self.cri_perceptual is None:
raise ValueError('Both pixel and perceptual losses are None.')
if train_opt.get('colorfulness_opt'):
self.cri_colorfulness = build_loss(train_opt['colorfulness_opt']).to(self.device)
else:
self.cri_colorfulness = None
# set up optimizers and schedulers
self.setup_optimizers()
self.setup_schedulers()
# set real dataset cache for fid metric computing
self.real_mu, self.real_sigma = None, None
if self.opt['val'].get('metrics') is not None and self.opt['val']['metrics'].get('fid') is not None:
self._prepare_inception_model_fid()
def setup_optimizers(self):
train_opt = self.opt['train']
# optim_params_g = []
# for k, v in self.net_g.named_parameters():
# if v.requires_grad:
# optim_params_g.append(v)
# else:
# logger = get_root_logger()
# logger.warning(f'Params {k} will not be optimized.')
optim_params_g = self.net_g.parameters()
# optimizer g
optim_type = train_opt['optim_g'].pop('type')
self.optimizer_g = self.get_optimizer(optim_type, optim_params_g, **train_opt['optim_g'])
self.optimizers.append(self.optimizer_g)
# optimizer d
optim_type = train_opt['optim_d'].pop('type')
self.optimizer_d = self.get_optimizer(optim_type, self.net_d.parameters(), **train_opt['optim_d'])
self.optimizers.append(self.optimizer_d)
def feed_data(self, data):
self.lq = data['lq'].to(self.device)
self.lq_rgb = tensor_lab2rgb(torch.cat([self.lq, torch.zeros_like(self.lq), torch.zeros_like(self.lq)], dim=1))
if 'gt' in data:
self.gt = data['gt'].to(self.device)
self.gt_lab = torch.cat([self.lq, self.gt], dim=1)
self.gt_rgb = tensor_lab2rgb(self.gt_lab)
if self.opt['train'].get('color_enhance', False):
for i in range(self.gt_rgb.shape[0]):
self.gt_rgb[i] = color_enhacne_blend(self.gt_rgb[i], factor=self.opt['train'].get('color_enhance_factor'))
def optimize_parameters(self, current_iter):
# optimize net_g
for p in self.net_d.parameters():
p.requires_grad = False
self.optimizer_g.zero_grad()
self.output_ab = self.net_g(self.lq_rgb)
self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)
self.output_rgb = tensor_lab2rgb(self.output_lab)
l_g_total = 0
loss_dict = OrderedDict()
# pixel loss
if self.cri_pix:
l_g_pix = self.cri_pix(self.output_ab, self.gt)
l_g_total += l_g_pix
loss_dict['l_g_pix'] = l_g_pix
# perceptual loss
if self.cri_perceptual:
l_g_percep, l_g_style = self.cri_perceptual(self.output_rgb, self.gt_rgb)
if l_g_percep is not None:
l_g_total += l_g_percep
loss_dict['l_g_percep'] = l_g_percep
if l_g_style is not None:
l_g_total += l_g_style
loss_dict['l_g_style'] = l_g_style
# gan loss
if self.cri_gan:
fake_g_pred = self.net_d(self.output_rgb)
l_g_gan = self.cri_gan(fake_g_pred, target_is_real=True, is_disc=False)
l_g_total += l_g_gan
loss_dict['l_g_gan'] = l_g_gan
# colorfulness loss
if self.cri_colorfulness:
l_g_color = self.cri_colorfulness(self.output_rgb)
l_g_total += l_g_color
loss_dict['l_g_color'] = l_g_color
l_g_total.backward()
self.optimizer_g.step()
# optimize net_d
for p in self.net_d.parameters():
p.requires_grad = True
self.optimizer_d.zero_grad()
real_d_pred = self.net_d(self.gt_rgb)
fake_d_pred = self.net_d(self.output_rgb.detach())
l_d = self.cri_gan(real_d_pred, target_is_real=True, is_disc=True) + self.cri_gan(fake_d_pred, target_is_real=False, is_disc=True)
loss_dict['l_d'] = l_d
loss_dict['real_score'] = real_d_pred.detach().mean()
loss_dict['fake_score'] = fake_d_pred.detach().mean()
l_d.backward()
self.optimizer_d.step()
self.log_dict = self.reduce_loss_dict(loss_dict)
if self.ema_decay > 0:
self.model_ema(decay=self.ema_decay)
def get_current_visuals(self):
out_dict = OrderedDict()
out_dict['lq'] = self.lq_rgb.detach().cpu()
out_dict['result'] = self.output_rgb.detach().cpu()
if self.opt['logger'].get('save_snapshot_verbose', False): # only for verbose
self.output_lab_chroma = torch.cat([torch.ones_like(self.lq) * 50, self.output_ab], dim=1)
self.output_rgb_chroma = tensor_lab2rgb(self.output_lab_chroma)
out_dict['result_chroma'] = self.output_rgb_chroma.detach().cpu()
if hasattr(self, 'gt'):
out_dict['gt'] = self.gt_rgb.detach().cpu()
if self.opt['logger'].get('save_snapshot_verbose', False): # only for verbose
self.gt_lab_chroma = torch.cat([torch.ones_like(self.lq) * 50, self.gt], dim=1)
self.gt_rgb_chroma = tensor_lab2rgb(self.gt_lab_chroma)
out_dict['gt_chroma'] = self.gt_rgb_chroma.detach().cpu()
return out_dict
def test(self):
if hasattr(self, 'net_g_ema'):
self.net_g_ema.eval()
with torch.no_grad():
self.output_ab = self.net_g_ema(self.lq_rgb)
self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)
self.output_rgb = tensor_lab2rgb(self.output_lab)
else:
self.net_g.eval()
with torch.no_grad():
self.output_ab = self.net_g(self.lq_rgb)
self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)
self.output_rgb = tensor_lab2rgb(self.output_lab)
self.net_g.train()
def dist_validation(self, dataloader, current_iter, tb_logger, save_img):
if self.opt['rank'] == 0:
self.nondist_validation(dataloader, current_iter, tb_logger, save_img)
def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
dataset_name = dataloader.dataset.opt['name']
with_metrics = self.opt['val'].get('metrics') is not None
use_pbar = self.opt['val'].get('pbar', False)
if with_metrics and not hasattr(self, 'metric_results'): # only execute in the first run
self.metric_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}
# initialize the best metric results for each dataset_name (supporting multiple validation datasets)
if with_metrics:
self._initialize_best_metric_results(dataset_name)
# zero self.metric_results
if with_metrics:
self.metric_results = {metric: 0 for metric in self.metric_results}
metric_data = dict()
if use_pbar:
pbar = tqdm(total=len(dataloader), unit='image')
if self.opt['val']['metrics'].get('fid') is not None:
fake_acts_set, acts_set = [], []
for idx, val_data in enumerate(dataloader):
# if idx == 100:
# break
img_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]
if hasattr(self, 'gt'):
del self.gt
self.feed_data(val_data)
self.test()
visuals = self.get_current_visuals()
sr_img = tensor2img([visuals['result']])
metric_data['img'] = sr_img
if 'gt' in visuals:
gt_img = tensor2img([visuals['gt']])
metric_data['img2'] = gt_img
torch.cuda.empty_cache()
if save_img:
if self.opt['is_train']:
save_dir = osp.join(self.opt['path']['visualization'], img_name)
for key in visuals:
save_path = os.path.join(save_dir, '{}_{}.png'.format(current_iter, key))
img = tensor2img(visuals[key])
imwrite(img, save_path)
else:
if self.opt['val']['suffix']:
save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
f'{img_name}_{self.opt["val"]["suffix"]}.png')
else:
save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
f'{img_name}_{self.opt["name"]}.png')
imwrite(sr_img, save_img_path)
if with_metrics:
# calculate metrics
for name, opt_ in self.opt['val']['metrics'].items():
if name == 'fid':
pred, gt = visuals['result'].cuda(), visuals['gt'].cuda()
fake_act = get_activations(pred, self.inception_model_fid, 1)
fake_acts_set.append(fake_act)
if self.real_mu is None:
real_act = get_activations(gt, self.inception_model_fid, 1)
acts_set.append(real_act)
else:
self.metric_results[name] += calculate_metric(metric_data, opt_)
if use_pbar:
pbar.update(1)
pbar.set_description(f'Test {img_name}')
if use_pbar:
pbar.close()
if with_metrics:
if self.opt['val']['metrics'].get('fid') is not None:
if self.real_mu is None:
acts_set = np.concatenate(acts_set, 0)
self.real_mu, self.real_sigma = calculate_activation_statistics(acts_set)
fake_acts_set = np.concatenate(fake_acts_set, 0)
fake_mu, fake_sigma = calculate_activation_statistics(fake_acts_set)
fid_score = calculate_frechet_distance(self.real_mu, self.real_sigma, fake_mu, fake_sigma)
self.metric_results['fid'] = fid_score
for metric in self.metric_results.keys():
if metric != 'fid':
self.metric_results[metric] /= (idx + 1)
# update the best metric result
self._update_best_metric_result(dataset_name, metric, self.metric_results[metric], current_iter)
self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
def _log_validation_metric_values(self, current_iter, dataset_name, tb_logger):
log_str = f'Validation {dataset_name}\n'
for metric, value in self.metric_results.items():
log_str += f'\t # {metric}: {value:.4f}'
if hasattr(self, 'best_metric_results'):
log_str += (f'\tBest: {self.best_metric_results[dataset_name][metric]["val"]:.4f} @ '
f'{self.best_metric_results[dataset_name][metric]["iter"]} iter')
log_str += '\n'
logger = get_root_logger()
logger.info(log_str)
if tb_logger:
for metric, value in self.metric_results.items():
tb_logger.add_scalar(f'metrics/{dataset_name}/{metric}', value, current_iter)
def _prepare_inception_model_fid(self, path='pretrain/inception_v3_google-1a9a5a14.pth'):
incep_state_dict = torch.load(path, map_location='cpu')
block_idx = INCEPTION_V3_FID.BLOCK_INDEX_BY_DIM[2048]
self.inception_model_fid = INCEPTION_V3_FID(incep_state_dict, [block_idx])
self.inception_model_fid.cuda()
self.inception_model_fid.eval()
@master_only
def save_training_images(self, current_iter):
visuals = self.get_current_visuals()
save_dir = osp.join(self.opt['root_path'], 'experiments', self.opt['name'], 'training_images_snapshot')
os.makedirs(save_dir, exist_ok=True)
for key in visuals:
save_path = os.path.join(save_dir, '{}_{}.png'.format(current_iter, key))
img = tensor2img(visuals[key])
imwrite(img, save_path)
def save(self, epoch, current_iter):
if hasattr(self, 'net_g_ema'):
self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])
else:
self.save_network(self.net_g, 'net_g', current_iter)
self.save_network(self.net_d, 'net_d', current_iter)
self.save_training_state(epoch, current_iter)
第四步:运行


第五步:整个工程的内容

代码的下载路径(新窗口打开链接):基于深度学习神经网络的AI图片上色DDcolor系统源码

有问题可以私信或者留言,有问必答