目录
- 3. 无重复字符的最长子串
- 206. 反转链表
- 146. LRU 缓存
- 215. 数组中的第K个最大元素
- 25. K 个一组翻转链表
- 15. 三数之和
- 53. 最大子数组和
- 21. 合并两个有序链表
- 1. 两数之和
- 5. 最长回文子串
- 912. 排序数组
3. 无重复字符的最长子串
题目链接
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
stack=[]
max_cnt=0
for c in s:
while c in stack:
stack.pop(0)
stack.append(c)
if len(stack)>max_cnt:
max_cnt=len(stack)
return max_cnt
206. 反转链表
题目链接
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre=None
cur=head
while cur:
temp=cur.next
cur.next=pre
pre=cur
cur=temp
return pre
146. LRU 缓存
题目链接
用到的数据结构:哈希表+双向链表
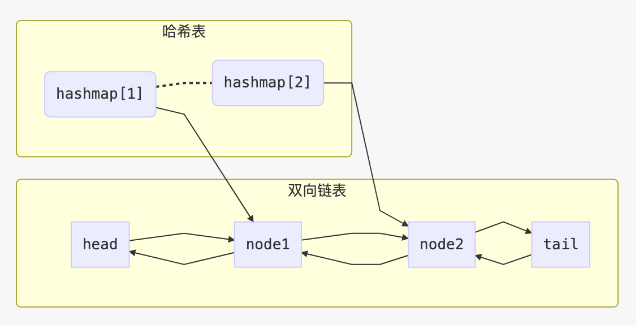
class ListNode:
def __init__(self,key=None,value=None):
self.key=key
self.value=value
self.pre=None
self.next=None
class LRUCache:
def __init__(self, capacity: int):
self.capacity=capacity
self.hashmap={}
self.head=ListNode()
self.tail=ListNode()
self.head.next=self.tail
self.tail.pre=self.head
def move_to_tail(self,key):
node=self.hashmap[key]
node.pre.next=node.next
node.next.pre=node.pre
node.next=self.tail
node.pre=self.tail.pre
self.tail.pre.next=node
self.tail.pre=node
def get(self, key: int) -> int:
if key in self.hashmap:
self.move_to_tail(key)
res=self.hashmap.get(key,-1)
if res==-1:
return res
else:
return res.value
def put(self, key: int, value: int) -> None:
if key in self.hashmap:
self.hashmap[key].value=value
self.move_to_tail(key)
else:
if len(self.hashmap)==self.capacity:
self.hashmap.pop(self.head.next.key)
self.head.next=self.head.next.next
self.head.next.pre=self.head
newNode=ListNode(key,value)
self.hashmap[key]=newNode
newNode.next=self.tail
newNode.pre=self.tail.pre
self.tail.pre.next=newNode
self.tail.pre=newNode
# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
注意:
- 本题的数据结构:哈希表+双向链表
self总是忘记写
215. 数组中的第K个最大元素
题目链接
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
return self.quickSelect(nums,k)
def quickSelect(self,nums,k):
pivot=random.choice(nums)
big,equal,small=[],[],[]
for num in nums:
if num > pivot:
big.append(num)
elif num<pivot:
small.append(num)
else:
equal.append(num)
if k<=len(big):
return self.quickSelect(big,k)
elif k>len(nums)-len(small):
return self.quickSelect(small,k-len(nums)+len(small))
else:
return pivot
25. K 个一组翻转链表
题目链接
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverse(self,head):
cur=head
pre=None
while cur:
temp=cur.next
cur.next=pre
pre=cur
cur=temp
return pre
def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
dummy=ListNode(next=head)
pre,end=dummy,dummy
while end.next:
for _ in range(k):
if end:
end=end.next
if not end:
break
temp=end.next
end.next=None
start=pre.next
pre.next=self.reverse(start)
start.next=temp
pre,end=start,start
return dummy.next
15. 三数之和
题目链接
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
res=[]
n=len(nums)
for i in range(n):
if nums[i]>0:
return res
if i>0 and nums[i]==nums[i-1]:
continue
L=i+1
R=n-1
while L<R:
if nums[i]+nums[L]+nums[R]==0:
res.append([nums[i],nums[L],nums[R]])
while L<R and nums[L]==nums[L+1]:
L+=1
while L<R and nums[R]==nums[R-1]:
R-=1
L+=1
R-=1
elif nums[i]+nums[L]+nums[R]>0:
R-=1
else:
L+=1
return res
53. 最大子数组和
题目链接
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
# dp[i]表示nums中下标从0到i的部分,最大的子数组和
n=len(nums)
if n==1:
return nums[0]
dp=[0]*n
dp[0]=nums[0]
for i in range(1,n):
if dp[i-1]>0:
dp[i]=dp[i-1]+nums[i]
else:
dp[i]=nums[i]
return max(dp)
21. 合并两个有序链表
题目链接
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
if not list1:
return list2
if not list2:
return list1
if list1.val<list2.val:
list1.next=self.mergeTwoLists(list1.next,list2)
return list1
else:
list2.next=self.mergeTwoLists(list2.next,list1)
return list2
1. 两数之和
题目链接
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashmap={}
for i,num in enumerate(nums):
if target-num in hashmap:
return [i,hashmap[target-num]]
hashmap[num]=i
return []
5. 最长回文子串
题目链接
class Solution:
def longestPalindrome(self, s: str) -> str:
n=len(s)
dp= [[False]*n for _ in range(n)]
begin=0
max_len=1
for i in range(n-1,-1,-1):
for j in range(i,n):
if s[i]==s[j] and (j-i<=2 or dp[i+1][j-1]):
dp[i][j]=True
if j-i+1>max_len:
max_len=j-i+1
begin=i
return s[begin:begin+max_len]
912. 排序数组
题目链接
- 快速排序
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
self.quick(nums, 0, len(nums) - 1)
return nums
def quick(self, nums, left, right):
if left >= right:
return nums
# 选择一个随机的索引作为pivot
pivot_index = random.randint(left, right)
# 将随机选择的pivot和最左侧的元素交换
nums[left], nums[pivot_index] = nums[pivot_index], nums[left]
pivot = nums[left]
left0, right0 = left, right
while left < right:
while left < right and nums[right] >= pivot:
right -= 1
while left < right and nums[left] <= pivot:
left += 1
nums[left], nums[right] = nums[right], nums[left]
# 恢复pivot到正确的位置
nums[left0], nums[left] = nums[left], nums[left0]
self.quick(nums, left + 1, right0)
self.quick(nums, left0, left - 1)
- 归并排序
class Solution:
# 合并两个有序数组
def merge(self,left,right):
merged=[]
i=j=0
while i<len(left) and j<len(right):
if left[i]<=right[j]:
merged.append(left[i])
i+=1
else:
merged.append(right[j])
j+=1
while i<len(left):
merged.append(left[i])
i+=1
while j<len(right):
merged.append(right[j])
j+=1
return merged
# 划分左右数组
def sortArray(self, nums: List[int]) -> List[int]:
if len(nums)<=1:
return nums
mid=len(nums)//2
left=self.sortArray(nums[:mid])
right=self.sortArray(nums[mid:])
return self.merge(left,right)
- 堆排序
class Solution:
def adjust(self,nums,parent,length):
"""
nums:待排序数组
parent:父结点的索引
length:参与调整的数组长度(结点个数)
"""
child=parent*2+1
while child<length:
if child+1<length and nums[child+1]>nums[child]:
child+=1
if nums[parent]<nums[child]:
nums[parent],nums[child]=nums[child],nums[parent]
parent=child
child=2*parent+1
else:
break
def sortArray(self, nums: List[int]) -> List[int]:
# 建立堆结构
for i in range(len(nums)//2-1,-1,-1):
self.adjust(nums,i,len(nums))
for i in range(len(nums)-1,0,-1):
nums[0],nums[i]=nums[i],nums[0]
self.adjust(nums,0,i)
return nums
- 冒泡排序
def bubble_sort(lis):
n = len(lis)
# 控制比较的轮数
for j in range(n - 1):
count = 0
# 控制每一轮的比较次数
# -1是为了让数组不要越界
# -j是每一轮结束之后, 我们就会少比一个数字
for i in range(n - 1 - j):
if lis[i] > lis[i + 1]:
lis[i], lis[i + 1] = lis[i + 1], lis[i]
count += 1
# 算法优化
# 如果遍历一遍发现没有数字交换,退出循环,说明数列是有序的
if count == 0:
break
总结:
- 快速排序、堆排序、归并排序的时间复杂度都是 O(nlogn);
- 快速排序、堆排序是不稳定的,归并排序、冒泡排序是稳定的。