目录
1、Kafka 消费方式
2、Kafka 消费者工作流程
2.1、消费者工作流程
2.2、消费组者说明
1、消费者组
2、消费者组初始化流程
3、消费者 API
3.1、独立消费者-订阅主题
3.2、独立消费者-订阅分区
3.3、消费组
4、分区的分配策略以及再平衡
4.1、Range 策略
1、Range 分区分配策略示例
2、Range 分区分配再平衡示例
4.2、RoundRobin 策略
1、RoundRobin 分区分配策略示例
2、RoundRobin 分区分配再平衡示例
4.3、Sticky 策略
1、Sticky分区分配示例
2、Sticky 分区分配再平衡示例
5、offset 位移
5.1、自动提交 offset
5.2、手动提交 offset
1、同步提交 offset
2、异步提交 offset
5.3、指定 Offset 消费
1、任意指定 offset 位移开始消费
2、指定时间消费
6、数据积压
注:示例代码使用的语言是Python
1、Kafka 消费方式
1、pull(拉)模 式:
- consumer采用从broker中主动拉取数据。
- Kafka采用这种方式
- 缺点:
- pull模式不足之处是,如 果Kafka没有数 据,消费者可能会陷入循环中,一直返回 空数据。
2、push(推)模式:
Kafka没有采用这种方式,因为由broker 决定消息发送速率,很难适应所有消费者的 消费速率。若推送的速度是100m/s, Consumer1、Consumer2就来不及处理消息。
2、Kafka 消费者工作流程
2.1、消费者工作流程

2.2、消费组者说明
1、消费者组
- Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件:是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 如果向消费组中添加更多的消费者,超过 主题分区数量,则有一部分消费者就会闲 置,不会接收任何消息。
- 消费者组之间互不影响。所 有的消费者都属于某个消费 者组,即消费者组是逻辑上 的一个订阅者。
2、消费者组初始化流程
- coordinator:辅助实现消费者组的初始化和分区的分配。
- coordinator节点选择 = groupid的hashcode值 % 50( __consumer_offsets的分区数量)
- 例如: groupid的hashcode值 = 3,3% 50 = 3 (50是默认分区数),那么__consumer_offsets 主题的3号分区,在哪个broker上,就选择这个节点的coordinator 作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
- 每个消费者都会和coordinator保持心跳(默认3秒),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡或者消费者处理的时间过长(max.poll.interval.ms 5分钟),也会触发再平衡。
3、消费者 API
3.1、独立消费者-订阅主题
- 示例: 创建一个独立消费者,消费 first 主题中数据
- 注意:在消费者 API 代码中必须配置消费者组 id(JAVA)【Python中可不指定消费组ID,会默认生成】。命令行启动消费者不填写消费者组 id 会被自动填写随机的消费者组 id。
"""
独立消费者,指定消费组id
"""
import time
from kafka3 import KafkaConsumer, KafkaProducer
class Serializer:
@staticmethod
def deserialize_bytes(deserialized_data: bytes):
# 将bytes类型反序列化为str类型
data = str(deserialized_data, "utf-8")
return data
@staticmethod
def serialize_str(serialize_data: str):
# 将str类型序列化为bytes类型
serialized_data = bytes(serialize_data, 'utf-8')
return serialized_data
def comsumer(*topics, filter=None, group_id="test", enable_auto_commit=False):
"""
:fuction: 消费者, 完成数据消费
:param topic: 需要消费数据的所在的topic, 可以消费多个topic
:param filter: 过滤器 过滤展示/消费指定行为, 匹配方式为模糊匹配
:param group_id: 消费组id 默认test
:param enable_auto_commit: 是否自动提交消费,默认False
:return:
"""
print("开始消费数据......")
consumer = KafkaConsumer(*topics,
bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
group_id=group_id,
enable_auto_commit=enable_auto_commit
)
for message in consumer:
# print(eval(str(message.value, "utf-8")), end="\n")
print(Serializer.deserialize_bytes(message.value))
print(f"消费消息的时间戳: {message.timestamp}")
print(f"消息所在的topic: {message.topic}; 消息所在的分区: {message.partition}; 消息的偏移量: {message.offset}; "
f"消息key值: {message.key}; 消费的时间: {time.strftime('%Y-%m-%d %H:%M:%S'), int(round(time.time() * 1000))}\n")
if __name__ == '__main__':
topic = "first"
comsumer(topic)3.2、独立消费者-订阅分区
示例:创建一个独立消费者,消费 first 主题 0 号分区的数据。
"""
独立消费者,指定消费组id
指定分区消费数据
"""
import time
from kafka3 import KafkaConsumer, KafkaProducer, TopicPartition, KafkaClient
class Serializer:
@staticmethod
def deserialize_bytes(deserialized_data: bytes):
# 将bytes类型反序列化为str类型
data = str(deserialized_data, "utf-8")
return data
@staticmethod
def serialize_str(serialize_data: str):
# 将str类型序列化为bytes类型
serialized_data = bytes(serialize_data, 'utf-8')
return serialized_data
def comsumer(*topics, partition=0, filter=None, group_id="test", enable_auto_commit=False):
"""
:fuction: 消费者, 完成数据消费
:param topic: 需要消费数据的所在的topic, 可以消费多个topic
:param partition: 消费指定分区数据,默认0
:param filter: 过滤器 过滤展示/消费指定行为, 匹配方式为模糊匹配
:param group_id: 消费组id 默认test
:param enable_auto_commit: 是否自动提交消费,默认False
:return:
"""
print("开始消费数据......")
consumer_config = {
'bootstrap_servers': ["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
'client_id': group_id,
'enable_auto_commit': enable_auto_commit
}
consumer = KafkaConsumer(**consumer_config)
# 分配分区0给消费者
consumer.assign([TopicPartition(topic, partition) for topic in topics])
for message in consumer:
print(Serializer.deserialize_bytes(message.value))
print(f"消费消息的时间戳: {message.timestamp}")
print(f"消息所在的topic: {message.topic}; 消息所在的分区: {message.partition}; 消息的偏移量: {message.offset}; "
f"消息key值: {message.key}; 消费的时间: {time.strftime('%Y-%m-%d %H:%M:%S'), int(round(time.time() * 1000))}\n")
3.3、消费组
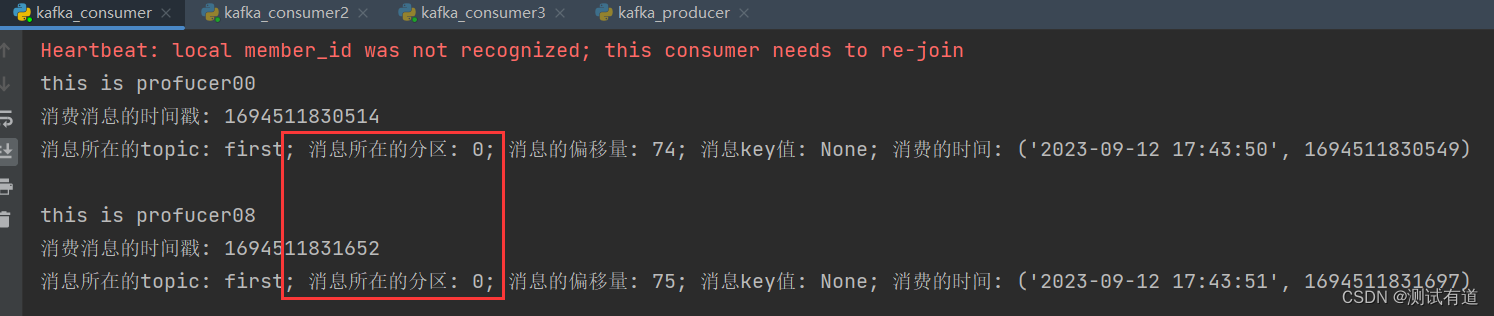
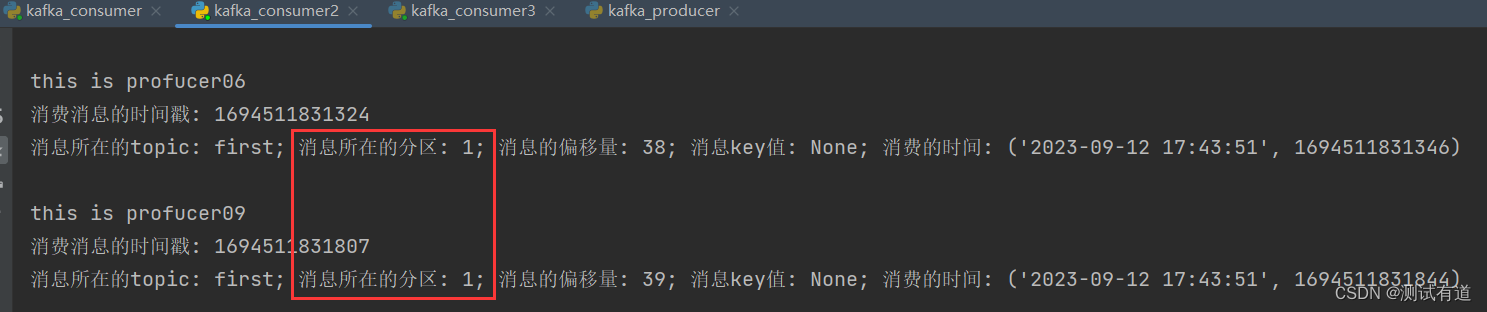
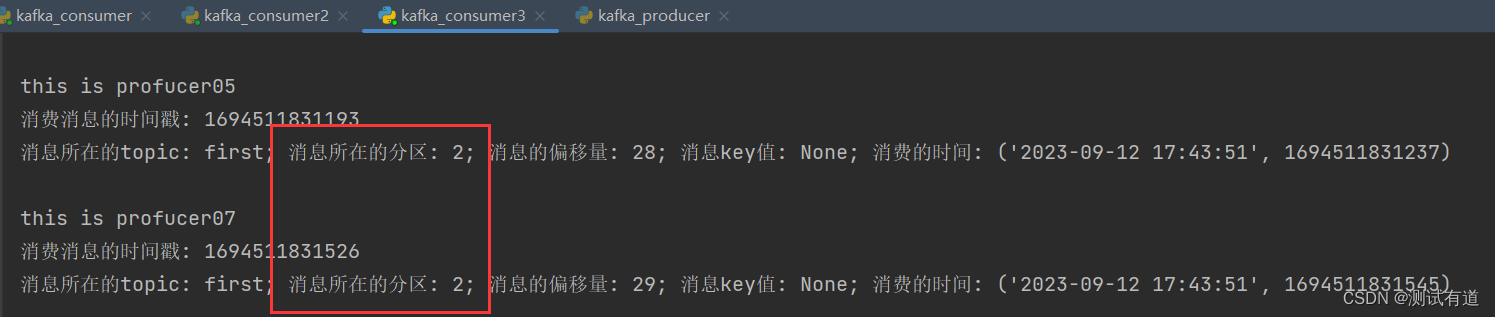
- 示例:测试同一个主题的分区数据,只能由一个消费者组中的一个消费。
1、案例实操
- 1、复制两份份基础消费者的代码,在 pycharm中同时启动,即可启动同一个消费者组中 的三个消费者。
- 2、启动代码中的生产者发送消息,在 pycharm 控制台即可看到三个消费者在消费不同 分区的数据(如果只发送到一个分区,可以在发送时增加延迟代码 Thread.sleep(2);)。
4、分区的分配策略以及再平衡
- 1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个 partition的数据。
- 2、Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。 可以通过配置参数partition.assignment.strategy,修改分区的分配策略。
- 默认策略是Range + CooperativeSticky。Kafka可以同时使用 多个分区分配策略。(JAVA)
- 默认策略是Range + RoundRobin。(Python)
注:下面这些默认参数配置是JAVA的,与Python的默认配置略有不同

【Python的默认配置如下】
'max_poll_interval_ms': 300000,
'session_timeout_ms': 10000,
'heartbeat_interval_ms': 3000,
4.1、Range 策略
Range 是对每个 topic 而言的。
- 首先对同一个 topic 里面的分区按照序号进行排序,并 对消费者按照字母顺序进行排序。
- 假如现在有 10 个分区,3 个消费者,排序后的分区将会 是0,1,2,3,4,5,6,7,8,9;消费者排序完之后将会是C0,C1,C2。
- 例如,10/3 = 3 余 1 ,那么 消费者 C0 便会多 消费 1 个分区。 11/3=3余2,那么C0和C1分别多 消费一个。
- 通过 partitions数/consumer数 来决定每个消费者应该 消费几个分区。如果有余数,那么前面几个消费者将会多 消费 1 个分区。
注意:如果只是针对 1 个 topic 而言,C0消费者多消费1 个分区影响不是很大。但是如果有 N 多个 topic,那么针对每 个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消 费的分区会比其他消费者明显多消费 N 个分区。 容易产生数据倾斜!
1、Range 分区分配策略示例
- 1、修改主题 first 为 7 个分区。
- 注意:分区数可以增加,但是不能减少。
bin/kafka-topics.sh --bootstrap-server node1:9092 --alter --topic first --partitions 7
- 2、设置分区分配策略为Range。
# 设置分区分配策略为Range
partition_assignment_strategy = (RangePartitionAssignor,)
consumer = KafkaConsumer(*topics,
bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
group_id=group_id,
enable_auto_commit=enable_auto_commit,
partition_assignment_strategy=partition_assignment_strategy
)- 3、复制 CustomConsumer 类,创建 CustomConsumer2。这样可以由三个消费者 CustomConsumer、CustomConsumer1、CustomConsumer2 组成消费者组,组名都为“test”, 同时启动 3 个消费者。
- 4、启动 CustomProducer 生产者,发送 500 条消息,随机发送到不同的分区。
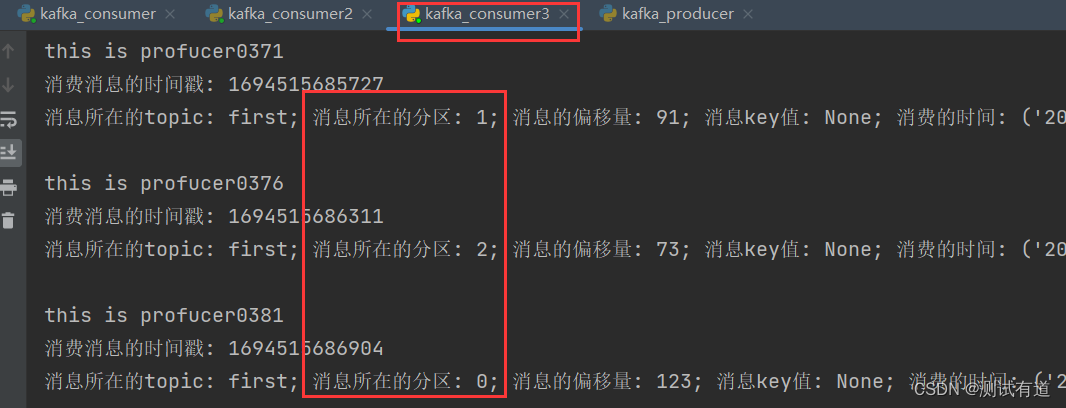
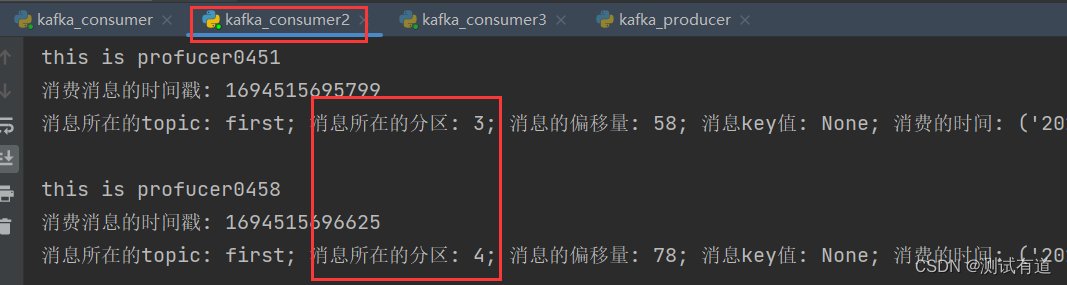
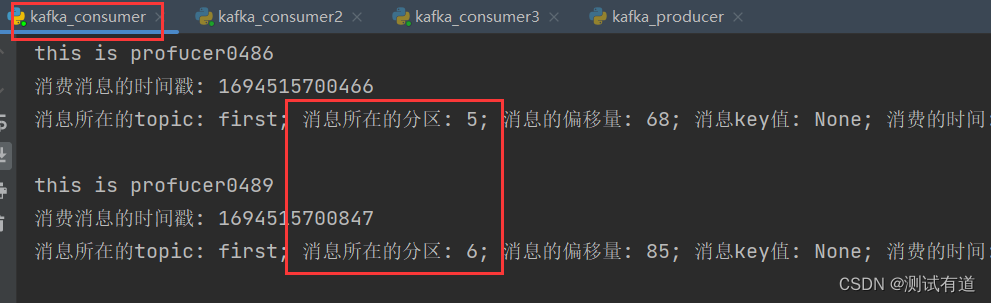
- 5、观察3 个消费者分别消费哪些分区的数据。
- 可以看到consumer3消费了:0、1、2分区;consumer2消费了:3、4分区;consumer消费了:5、6分区
2、Range 分区分配再平衡示例
1、停止掉 0 号消费者,快速重新发送消息观看结果(10s 以内)。
- 1 号消费者:消费到 0、1、2号分区数据。
- 2 号消费者:消费到 3、4、5、6 号分区数据。
- 0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需 要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
2、再次重新发送消息观看结果(10s 以后)。
- 1 号消费者:消费到 0、1、2、3 号分区数据。
- 2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
4.2、RoundRobin 策略
- RoundRobin 针对集群中所有Topic而言。
- RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序,最后 通过轮询算法来分配 partition 给到各个消费者。
1、RoundRobin 分区分配策略示例
- 1、依次在 CustomConsumer、CustomConsumer1、CustomConsumer2 三个消费者代 码中修改分区分配策略为 RoundRobin。
# 设置分区分配策略为RoundRobinPartitionAssignor
partition_assignment_strategy = (RoundRobinPartitionAssignor,)
consumer = KafkaConsumer(*topics,
bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
group_id=group_id,
enable_auto_commit=enable_auto_commit,
partition_assignment_strategy=partition_assignment_strategy
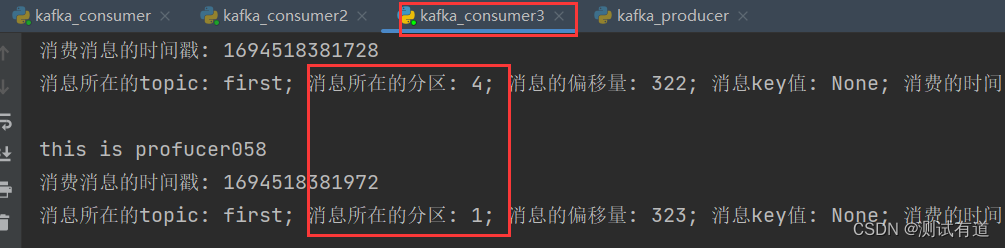
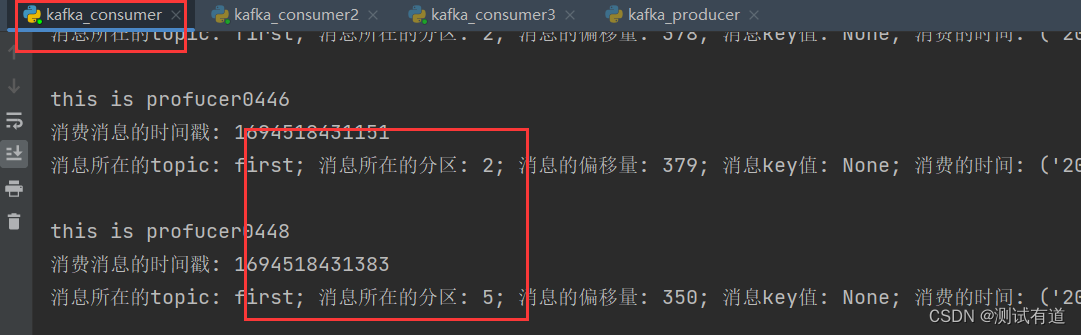
)- 2、重启 3 个消费者,重复发送消息的步骤,观看分区结果。
- 可以看到consumer3消费了:1、4分区;consumer2消费了:0、3、6分区;consumer消费了:2、5分区

2、RoundRobin 分区分配再平衡示例
1、停止掉 0 号消费者,快速重新发送消息观看结果(10s 以内)。
- 1 号消费者:消费到 0、2、4、6号分区数据
- 2 号消费者:消费到 1、3、5 号分区数据
- 0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 2 和 5 号分区数据, 分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 10s 来判断它是否退出,所以需 要等待,时间到了 10s 后,判断它真的退出就会把任务分配给其他 broker 执行。
2、再次重新发送消息观看结果(10s 以后)。
- 1 号消费者:消费到 0、2、4、6 号分区数据
- 2 号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
4.3、Sticky 策略
- 粘性分区定义:可以理解为分配的结果带有“粘性的”。即在执行一次新的分配之前, 考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
- 粘性分区是 Kafka 从 0.11.x 版本开始引入这种分配策略,首先会尽量均衡的放置分区 到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分 区不变化。
示例 :设置主题为 first,7 个分区;准备 3 个消费者,采用粘性分区策略,并进行消费,观察 消费分配情况。然后再停止其中一个消费者,再次观察消费分配情况。
1、Sticky分区分配示例
注意:kafka-python3库中没有Sticky分区策略,以下的示例是JAVA示例
- 1、修改分区分配策略为粘性。
- 注意:3 个消费者都应该注释掉,之后重启 3 个消费者,如果出现报错,全部停止等 会再重启,或者修改为全新的消费者组。
// 修改分区分配策略
ArrayList<String> startegys = new ArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
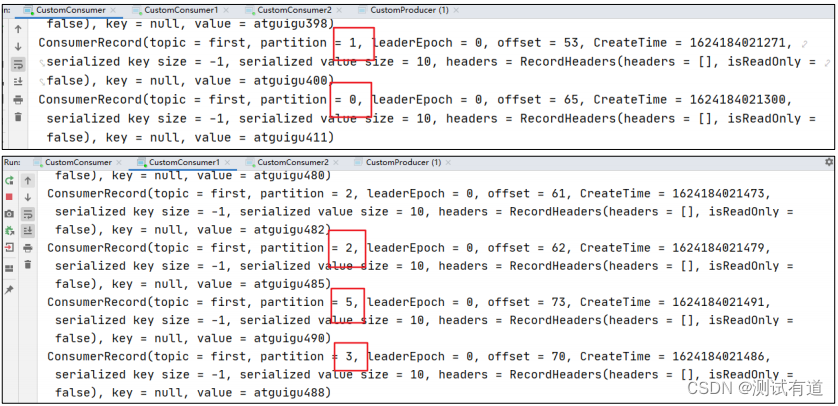
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);- 2、使用同样的生产者发送 500 条消息。
- 可以看到会尽量保持分区的个数近似划分分区。

2、Sticky 分区分配再平衡示例
1、停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内)。
- 1 号消费者:消费到 2、5、3 号分区数据。
- 2 号消费者:消费到 4、6 号分区数据。
- 0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别 由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需 要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
2、再次重新发送消息观看结果(45s 以后)。
- 1 号消费者:消费到 2、3、5 号分区数据。
- 2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
5、offset 位移
说明:kafka 0.9版本之前。consumer默认将offset保存在zookeeper中,从0.9版本开始,consumer默认将offset保存在kafka一个内置的topic中,该topic为__consumer_offsets
__consumer_offsets :里面采用 key 和 value 的方式存储数据。key 是 group.id+topic+ 分区号,value 就是当前 offset 的值。每隔一段时间,kafka 内部会对这个 topic 进行 compact,也就是每个 group.id+topic+分区号就保留最新数据。
5.1、自动提交 offset
- 自动提交offset的相关参数(JAVA):
- enable.auto.commit:是否开启自动提交offset功能,默认是true
- auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
- 自动提交offset的相关参数(Python):
'enable_auto_commit': True,
'auto_commit_interval_ms': 5000,
代码示例(Python)
# 设置自动提交
enable_auto_commit = True
# 设置提交时间周期1000ms
auto_commit_interval_ms = 1000
consumer = KafkaConsumer(*topics,
bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
group_id=group_id,
partition_assignment_strategy=partition_assignment_strategy,
enable_auto_commit=enable_auto_commit,
auto_commit_interval_ms=auto_commit_interval_ms
)5.2、手动提交 offset
- 虽然自动提交offset十分简单便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因 此Kafka还提供了手动提交offset的API。
- 手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相 同点是,都会将本次提交的一批数据最高的偏移量提交;不同点是,同步提交阻塞当前线程,一直到提交成 功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而异步提交则没有失败重试机制,故 有可能提交失败。
- commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据
- commitAsync(异步提交) :发送完提交offset请求后,就开始消费下一批数据了。
1、同步提交 offset
- 由于同步提交 offset 有失败重试机制,故更加可靠,但是由于一直等待提交结果,提 交的效率比较低。以下为同步提交 offset 的示例。
consumer_config = {
'bootstrap_servers': ["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
'group_id': group_id,
'enable_auto_commit': False
}
consumer = KafkaConsumer(*topics, **consumer_config)
# 设置offset同步提交
consumer.commit()
2、异步提交 offset
- 虽然同步提交 offset 更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此 吞吐量会受到很大的影响。因此更多的情况下,会选用异步提交 offset 的方式。
- 以下为异步提交 offset 的示例:
consumer_config = {
'bootstrap_servers': ["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],
'group_id': group_id,
'enable_auto_commit': False
}
consumer = KafkaConsumer(*topics, **consumer_config)
# 设置offse异步提交
consumer.commit_async()5.3、指定 Offset 消费
- auto.offset.reset = earliest | latest | none 默认是 latest。(JAVA);参数:auto_offset_reset 默认是 latest。(Python)
- 当 Kafka 中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量 时(例如该数据已被删除),该怎么办?
- earliest:自动将偏移量重置为最早的偏移量,--from-beginning。
- latest(默认值):自动将偏移量重置为最新偏移量。
- none:如果未找到消费者组的先前偏移量,则向消费者抛出异常。
1、任意指定 offset 位移开始消费
assignment = consumer.assignment()
while len(assignment) == 0:
consumer.poll() # 获取分区分配情况
assignment = consumer.assignment()
for partition in assignment:
consumer.seek(partition, 600) # 设置偏移量为 600,2、指定时间消费
在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。 例如要求按照时间消费前一天的数据,就需要指定时间消费。
assignment = consumer.assignment()
while len(assignment) == 0:
consumer.poll() # 获取分区分配情况
assignment = consumer.assignment()
# 指定从什么时间开始消费
assign_time = int(time.time() - 24*60*60) * 1000
for partition in assignment:
timestamps = {}
timestamps[partition] = assign_time
# 通过指定的时间戳,获取每个分区中时间戳对应offset
topic_partition_timestamp = consumer.offsets_for_times(timestamps)
for topic_partition, timestamps_offset in topic_partition_timestamp.items():
if timestamps_offset and timestamps_offset:
# 通过获取到与时间戳对应的offset,然后指定每个分区从offset开始消费
consumer.seek(topic_partition, timestamps_offset[0])6、数据积压
如果消费端出现数据积压问题,可能是以下两个原因导致的:
- 1、如果是kafka消费能力不足,则可以考虑增加topic的分区数,并且同时提升消费组的消费者梳理,消费者数=分区数。
- 2、如果是消费者处理速度比生产速度快,也会造成数据积压,提高每批次拉取的数量。
通过以下两个参数调整: