📝前言:
这篇文章主要想讲解一下python中的正则表达式:
1,什么是正则表达式
2,re模块三匹配
3,元字符匹配
4,具体示例
🎬个人简介:努力学习ing
📋个人专栏:C语言入门基础以及python入门基础
🎀CSDN主页 愚润求学
🌄每日鸡汤:天生我材必有用,千金散尽还复来
文章目录
- 一,什么是正则表达式
- 二,re模块三匹配
- 1,match()
- 2,search()
- 3,findall()
- 4,总结
- 三,元字符匹配
- 1,单字符匹配
- 2,数量匹配
- 3,边界匹配
- 四,具体示例
- 例一
- 例二
- 例三
一,什么是正则表达式
正则表达式(Regular Expression)是一种用于处理字符串的强大工具,它可以用来检查字符串是否符合某种模式、提取字符串中的特定部分或者替换字符串中的某些内容。
比如在某些场景,我们在输入邮箱的时候,如果我们的输入不符合邮箱地址的规则,则会被提示错误输入。
二,re模块三匹配
下面是三种常用来匹配的函数
1,match()
match()函数用于从字符串的开头开始匹配正则表达式。(如果第一个字符就不匹配则直接返回None)
如果匹配成功,返回一个匹配对象(包含匹配的信息);如果匹配失败,返回None。
函数原型:
re.match(pattern, string, flags=0)
pattern: 匹配的正则表达式(匹配规则)
string: 要匹配的字符串
flags: 可选参数,用于控制匹配方式,如是否忽略大小写、是否多行匹配等。
示例:
import re
a = "hello world! hello world."
print(re.match('hello', a))
输出:
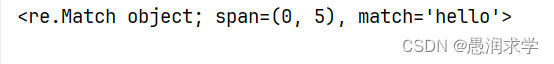
(这个span(0,5)是不包括5下标的)
2,search()
search()函数用于在字符串中搜索与正则表达式匹配的子字符串。如果找到匹配项,返回一个匹配对象;如果找不到匹配项,返回None。
函数原型:
re.search(pattern, string, flags=0)
(参数与match()相同。)
示例:
import re
a = "hello world! hello world."
print(re.search('llo', a))
输出:
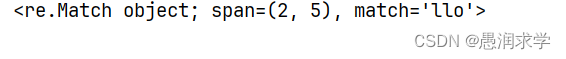
3,findall()
findall()函数用于在字符串中查找所有与正则表达式匹配的子字符串,并返回一个包含所有匹配项的列表。
函数原型:
re.findall(pattern, string, flags=0)
(参数与match()和search()相同。)
示例:
import re
a = "hello world! hello world."
print(re.findall('llo', a))
输出:

4,总结
●
match(): 从字符串的开头开始匹配,如果开头不匹配则返回None。匹配成功则返回第一个匹配项(包含信息),匹配失败则返回None
●search(): 在字符串中搜索与正则表达式匹配的子字符串,返回第一个匹配项(包含信息),失败返回None。
●findall(): 在字符串中查找所有与正则表达式匹配的子字符串,并返回一个包含所有匹配项的列表,找不到则返回一个空列表。
三,元字符匹配
正则表达式的核心是用于构建模式的元字符。元字符是一些具有特殊含义的字符,可以用来匹配某一类字符。使用元字符构建一个模式,然后使用这个模式来处理字符串。
为了创建一个正则表达式,你通常需要在字符串前面添加一个r前缀。这个前缀告诉Python解释器这是一个原始字符串(raw string)
1,单字符匹配
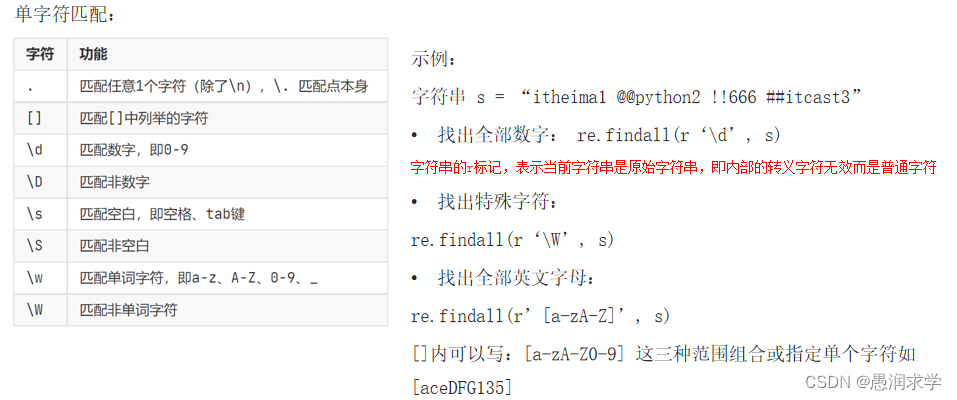
2,数量匹配
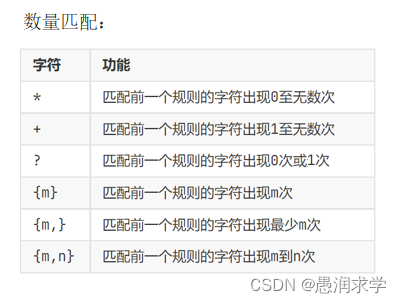
如:
\d*:匹配0个或者无数个数字
[0-9]+:匹配1个或者无数个0-9之间的数字)
[^0]:匹配除了0以外的所有字符
[^a-zA-Z]:匹配除了字母a-z和A-Z以外的所有字符。(a-z和A-Z之间最好不要加,)
注意:{m,n}之间不要加逗号:a{1,2},b{1,3}【错误的】
3,边界匹配
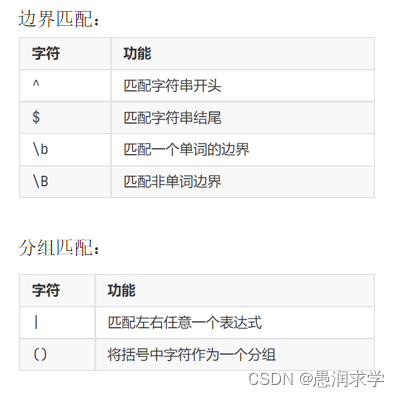
^[0-9]+$:从头开始匹配到结尾,中间出现1个或无数个0-9之间的数字
():把()内要匹配的当一个整体来匹配
|:意思就是或,如:com|136|qq就是指这里匹配com或者136或者
四,具体示例
例一
匹配账号,只能由字母和数字组成,长度限制6到10位:
principle1 = r'^[0-9a-zA-Z]{6,10}$'
示例:
import re
principle1 = r'^[0-9a-zA-Z]{6,10}$'
text1 = "2005abc"
text2 = "200504@abc"
match_obj1, match_obj2 = re.match(principle1, text1), re.match(principle1, text2)
print(f"text1匹配的结果是:{match_obj1}\ntext2匹配的结果是{match_obj2}")
输出结果:

例二
匹配QQ号,要求纯数字,长度5-11,第一位不为0:
principle2 = r'^[1-9][0-9]{4,10}$'
例三
匹配邮箱地址
要求:
1,邮箱地址的格式:用户名+@+域名
2,用户名是由数字、字母、_或-组成
3,只允许qq、163、gmail这三种邮箱地址
提示:
如126.com是域名,.edu.com也是域名……
答案:
principle3 = r'^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$'
[\w-]+表示出现a-zA-Z0-9_和-字符最少1个,最多不限
(\.[\w-]+)*,表示出现组合.和a-zA-Z0-9_-的组合最少0次,最多不限
用于匹配如:abc.def@……
@表示匹配@符号
(qq|163|gmail)表示只匹配这3个邮箱提供商
(\.[\w-]+)+表示组合.和a-zA-Z0-9_-的组合最少1次,最多不限
如:3369134@abc.def.com
🌈我的分享也就到此结束啦🌈
要是我的分享也能对你的学习起到帮助,那简直是太酷啦!
若有不足,还请大家多多指正,我们一起学习交流!
📢公主,王子:点赞👍→收藏⭐→关注🔍
感谢大家的观看和支持!祝大家都能得偿所愿,天天开心!!!




![[SpringBoot] JWT令牌——登录校验](https://img-blog.csdnimg.cn/direct/f3e15d2da1614faab321b80c96743d14.png)