构造函数的主要作用对数据成员初始化,基类的构造函数是不能被继承的,在声明派生类时,派生类并没有把类的构造函数继承下来。因此,对继承过来的基类成员初始化的工作也要由派生类的构造函数完成;所以在派生类中不仅要考虑自身增加的数据成员的初始化,还要考虑基类的数据成员的初始化。
一、派生类的构造函数
解决方法则是,在执行派生类的构造函数时,调用基类的构造函数。
其一般形式为
派生类构造函数名 ( 总参数表列 ) : 基类构造函数名 ( 参数表列 )
{
派生类中新增数据成员初始化语句
}
这里通过人与学生类示例来演示,将Person类数据成员设置为保护成员,这样方便直接在派生类中调用。代码如下:
#include <iostream>
#include <string>
using namespace std;
// 基类 - 人类
class Person{
protected:
string name; // 姓名
int age; //年龄
char gender; //性别
public:
Person(){
name = "anonym";
age = 0;
gender = 0;
}
Person(string name, int age, char gender): name(name), age(age), gender(gender){}
};
// 派生类 - 学生
class Student: public Person{
private:
string school;
public:
Student(string name, int age, char gender, string school): Person(name, age, gender){
this->school = school;
}
void display(){
cout <<"name:" <<name <<endl;
cout <<"age:" <<age <<endl;
cout <<"gender:" <<(gender=='1'?"male":"female") <<endl;
cout <<"school:" <<school <<endl;
}
};
int main(){
Student s("Tom", 18, '1', "middle school");
s.display();
return 0;
}运行结果如下:
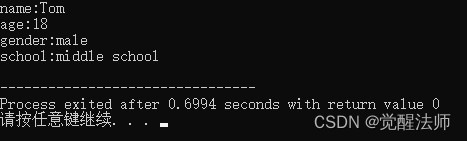
在建立一个对象时,执行构造函数的顺序:
- 派生类构造函数先调用基类构造函数;
- 再执行派生类构造函数本身(即派生类构造函数的函数体)。
二、有子对象的派生类的构造函数
在类对象中,数据成员都是标准类型(如int,char)或系统提供的类型(如string),但实际上,类的数据成员中还可以包含类对象。类对象中内嵌对象,即对象中的对象,称为子对象。
这里将学生对应的班长,先以Person类表示,在Student类中定义子对象并在派生类构造函数中初始化。代码如下:
#include <iostream>
#include <string>
using namespace std;
// 基类 - 人类
class Person{
protected:
string name; // 姓名
int age; //年龄
char gender; //性别
public:
Person(){
name = "anonym";
age = 0;
gender = 0;
}
Person(string name, int age, char gender): name(name), age(age), gender(gender){}
void display(){
cout <<"name:" <<name <<endl;
cout <<"age:" <<age <<endl;
cout <<"gender:" <<(gender=='1'?"male":"female") <<endl;
}
};
// 派生类 - 学生
class Student: public Person{
private:
Person monitor; // 定义子对象(班长)
string school;
public:
// 构造函数,并初始化基类和子对象
Student(string name, int age, char gender, string school, string m_name, int m_age, char m_gender):
Person(name, age, gender), school(school), monitor(m_name, m_age, m_gender){}
void display(){
cout <<"name:" <<name <<endl;
cout <<"age:" <<age <<endl;
cout <<"gender:" <<(gender=='1'?"male":"female") <<endl;
cout <<"school:" <<school <<endl;
cout <<endl <<"monitor:" <<endl;
monitor.display();
}
};
int main(){
Student s("Tom", 18, '1', "middle school", "John", 19, '1');
s.display();
return 0;
}运行结果如下:
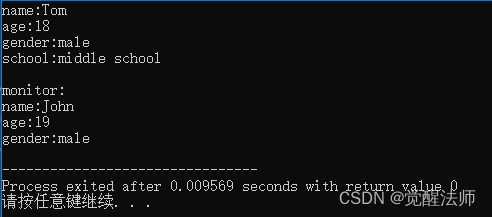
派生类构造函数的任务包括三部分:
- 对基类数据成员初始化;
- 对子对象数据成员初始化;
- 对派生类数据成员初始化。
定义派生类构造函数的一般形式:
派生类构造函数名 (总参数表列) : 基类构造函数名 (参数表列), 子对象名 (参数表列)
{
派生类中新增数据成员初始化语句
}
执行派生类构造函数的顺序:
- 调用基类构造函数,对基类数据成员初始化;
- 调用子对象构造函数,对子对象数据成员初始化;
- 再执行派生类构造函数本身,对派生类数据成员初始化。
三、多层派生时的构造函数
一个类不仅可以派生出一个派生类,派生类还可以继续派生,形成派生的层次结构。
这里在Person类和Student类基础上再定义一个Teacher类,其顺序是Person -> Student -> Teacher。示例代码如下:
#include <iostream>
#include <string>
using namespace std;
// 基类 - 人类
class Person{
protected:
string name; // 姓名
int age; //年龄
char gender; //性别
public:
Person(){
name = "anonym";
age = 0;
gender = 0;
}
Person(string name, int age, char gender): name(name), age(age), gender(gender){}
};
// 派生类 - 学生
class Student: public Person{
private:
string school;
public:
// 构造函数,并初始化基类
Student(string name, int age, char gender, string school):
Person(name, age, gender), school(school){}
string show_school(){
return school;
}
void display(){
cout <<"name:" <<name <<endl;
cout <<"age:" <<age <<endl;
cout <<"gender:" <<(gender=='1'?"male":"female") <<endl;
cout <<"school:" <<school <<endl;
cout <<endl;
}
};
class Teacher: public Student{
private:
string course; //课程
public:
// 构造函数,并初始化基类
Teacher(string name, int age, char gender, string school, string course):
Student(name, age, gender, school), course(course){}
void display(){
cout <<"name:" <<name <<endl;
cout <<"age:" <<age <<endl;
cout <<"gender:" <<(gender=='1'?"male":"female") <<endl;
cout <<"school:" <<show_school() <<endl;
cout <<"course:" <<course <<endl;
cout <<endl;
}
};
int main(){
Student s("Tom", 18, '1', "middle school"); //定义学生类对象
Teacher t("Lily", 30, '2', "middle school", "Mathematics"); //定义教师类对象
s.display(); // 显示学生信息
t.display(); //显示教师信息
return 0;
}运行结果如下:
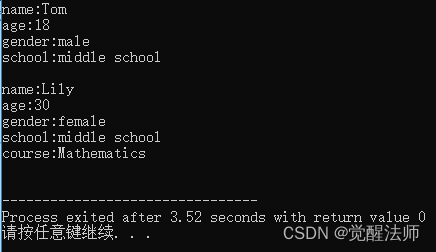
初始化顺序:
- 先初始化基类(Person)的数据成员;
- 再初始化派生类(Student)的数据成员;
- 最后再初始化派生类(Teacher)的数据成员。
四、派生类的析构函数
析构函数的作用是在对象撤销之前,进行必要的清理工作。当对象被删除时,系统会自动调用析构函数。
在派生类中析构函数不能被继承,也需要通过派生类的析构函数去调用基类的析构函数。在派生类中可以根据需要定义析构函数,用来对派生类中所增加的成员进行清理工作,基类的清理工作扔然由基类的析构函数完成。在执行派生类的析构函数时,系统会自动调用基类的析构函数和子对象的析构函数,对基类和子对象进行清理。
析构函数的调用顺序刚好与构造函数相反,析构函数是先调用派生类的析构函数,对派生类的成员进行清理,然后调用子对象的析构函数对子对象进行清理,最后调用基类的析构函数对基类进行清理。
这里将子对象中代码稍作修改,来演示析构函数执行顺序,示例代码如下:
#include <iostream>
#include <string>
using namespace std;
// 基类 - 人类
class Person{
protected:
string name; // 姓名
int age; //年龄
char gender; //性别
public:
Person(){
name = "anonym";
age = 0;
gender = 0;
}
Person(string name, int age, char gender): name(name), age(age), gender(gender){}
// 基类的析构函数
~Person(){
cout <<name <<", Person constructor" <<endl;
}
};
// 派生类 - 学生
class Student: public Person{
private:
Person monitor; // 定义子对象(班长)
string school;
public:
// 构造函数,并初始化基类和子对象
Student(string name, int age, char gender, string school, string m_name, int m_age, char m_gender):
Person(name, age, gender), school(school), monitor(m_name, m_age, m_gender){}
// 派生类的析构函数
~Student(){
cout <<name <<", Student constructor" <<endl;
}
};
int main(){
Student s("Tom", 18, '1', "middle school", "John", 19, '1');
return 0;
}运行结果如下:
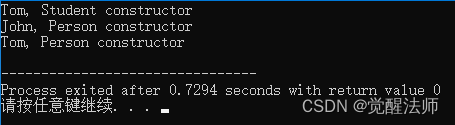
由图可见,基类(Person类)是最后执行的,子对象(John对象)是在基类之前执行,而最先执行的则是派生类(Student类)。
这个过程是确保了资源在正确的顺序中被释放。