梯度下降法总是在同一点收敛吗?
梯度下降法并不总是在同一点收敛。梯度下降法的收敛取决于多个因素,包括初始参数的选择、学习率的设置、损失函数的形状等。
以下是一些影响梯度下降法收敛行为的关键因素:
1.初始参数: 初始参数的选择可能影响梯度下降法的收敛。不同的初始参数可能导致不同的局部极小值或鞍点。
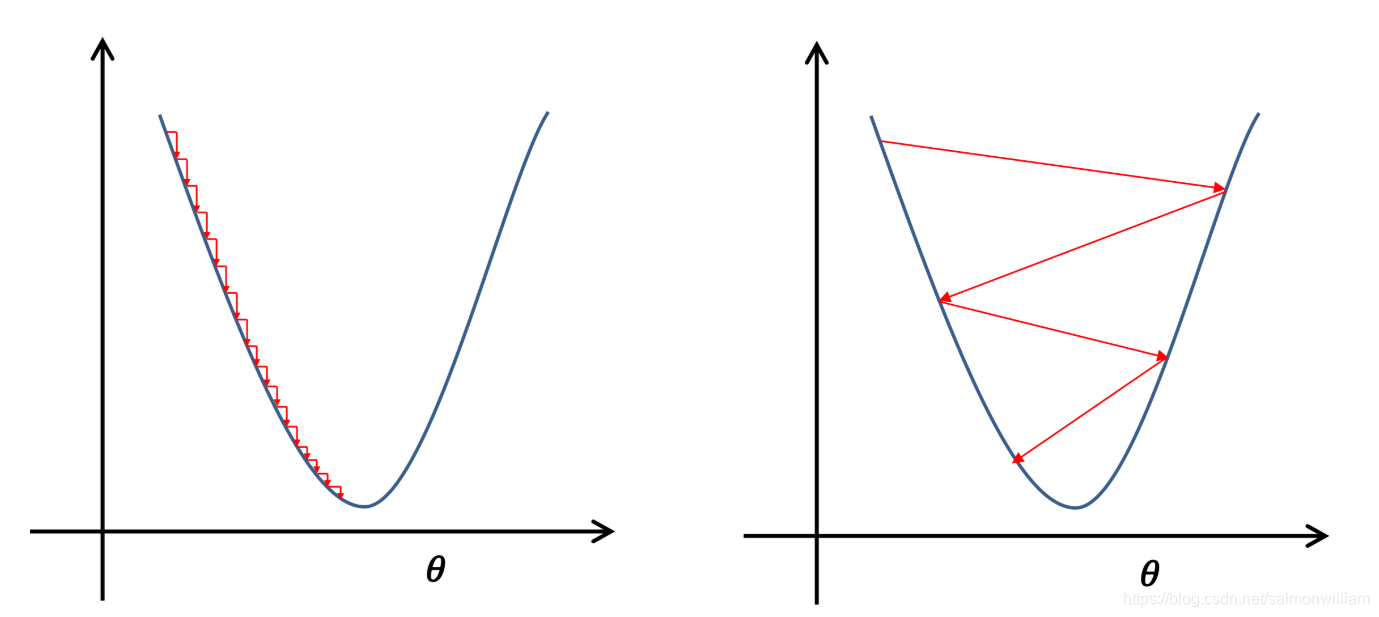
在上图曲线中由于选取的初始参数不同,则会得到不同的最优点。
2.学习率: 学习率决定了每次迭代中参数更新的步长。如果学习率设置得太大,可能会导致梯度下降法在最小值附近震荡或发散;如果学习率设置得太小,可能导致收敛速度过慢。
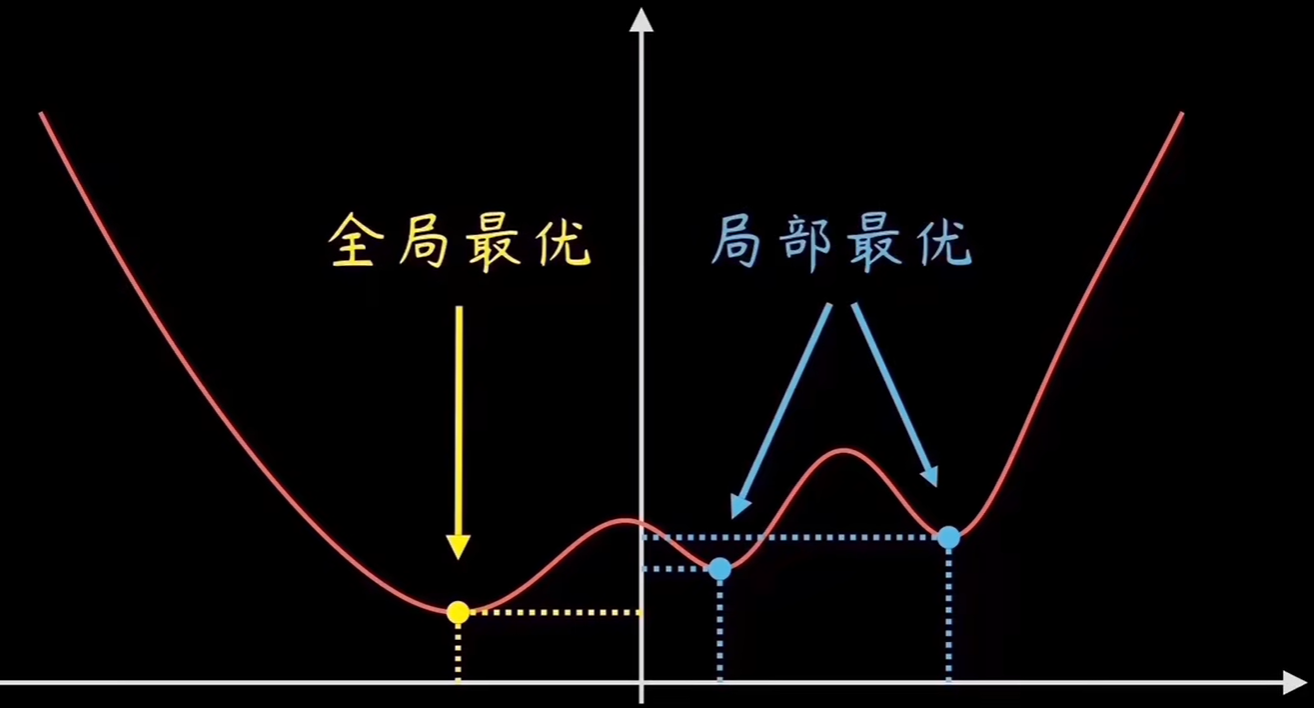
3.损失函数的形状: 损失函数的形状对于梯度下降的性能也很重要。如果损失函数具有多个局部极小值,梯度下降法可能会陷入局部最小值,而无法达到全局最小值。
4.批量大小: 在随机梯度下降(SGD)和小批量梯度下降(Mini-batch GD)中,批量大小的选择也可能影响收敛性。不同的批量大小可能导致不同的收敛行为。
5.优化算法: 梯度下降法有多种变体,如随机梯度下降(SGD)、动量法、Adam 等。不同的优化算法可能对于不同类型的问题和数据表现更好。
总体而言,梯度下降法是一个迭代优化过程,其收敛性在很大程度上取决于问题的性质和超参数的选择。有时候,也可能会在一定程度上遇到局部最小值或鞍点。因此,研究者们通过调整超参数、尝试不同的优化算法等方式来提高梯度下降法的性能。