基于pytorch hook机制,生成一次前后向的timeline
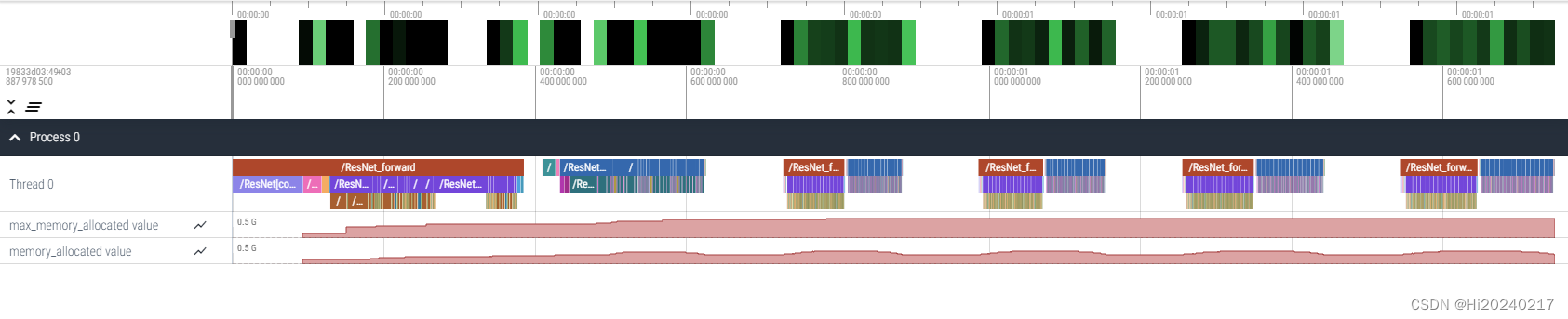
- 一.效果图
- 二.代码
- 三.运行以上代码,生成timeline.json,打开https://ui.perfetto.dev/,导入该文件,可看到以上效果
本文通过pytorch hook机制,拦截所有子module的forward和backward,统计执行时间及内存使用情况
一.效果图
二.代码
import os
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
import torch
import torchvision.models as models
import time
import threading
def singleeton(cls):
instance = {}
def _singleton(*args, **kwargs):
if cls not in instance:
instance[cls] = cls(*args, **kwargs)
return instance[cls]
return _singleton
@singleeton
class TimeLineContext(object):
def __init__(self) -> None:
self.content = "[\n"
def close(self):
fo = open(f"timeline.json", "w")
body = self.content[:-2] + "]\n"
fo.write(body)
fo.close()
def write(self, message):
self.content += message
self.content += ",\n"
class TimeLine:
def __init__(self, title, rank):
self.ctx = TimeLineContext()
self.rank = rank
self.title = title
self.beg = time.time() * 1000 * 1000
self.pid = os.getpid()
self.tid = threading.current_thread().ident
self.ctx.write(
"{"
+ f'"name": "{self.title}","cat": "operator", "ph": "B", "pid": {self.rank}, "tid": {self.tid}, "ts": {self.beg}'
+ "}")
def __del__(self):
self.end = time.time() * 1000 * 1000
self.ctx.write(
"{"
+ f'"name": "{self.title}","cat": "operator", "ph": "E", "pid": {self.rank}, "tid": {self.tid}, "ts": {self.end}'
+ "}")
self.ctx.write(
"{"
+ f'"name": "{"memory_allocated"}","cat": "memory_allocated", "ph": "C", "pid": {self.rank}, "tid": 100, "ts": {self.end}, "args": {{"value": {torch.cuda.memory_allocated(self.rank)}}}'
+ "}")
self.ctx.write(
"{"
+ f'"name": "{"max_memory_allocated"}","cat": "max_memory_allocated", "ph": "C", "pid": {self.rank}, "tid": 100, "ts": {self.end}, "args": {{"value": {torch.cuda.max_memory_allocated(self.rank)}}}'
+ "}")
class TimelineHook(object):
def __init__(self, net):
self.hooks = []
self.timing = {}
output_dict = {}
self.get_submodule_recrusicve(model, "", output_dict)
for name, module in output_dict.items():
if name.endswith("Sequential"):
continue
self.hooks.append(
module.register_forward_pre_hook(
self.build_hook_handler(f"{name}_forward", False)
)
)
self.hooks.append(
module.register_forward_hook(self.build_hook_handler(f"{name}_forward", True))
)
self.hooks.append(
module.register_full_backward_pre_hook(
self.build_hook_handler(f"{name}_backward", False)
)
)
self.hooks.append(
module.register_full_backward_hook(
self.build_hook_handler(f"{name}_backward", True)
)
)
def get_submodule_recrusicve(self,module, prefix, output_dict):
prefix = prefix + "/" + type(module).__name__
output_dict[prefix] = module
for name, submodule in module.named_children():
self.get_submodule_recrusicve(submodule, f"{prefix}[{name}]", output_dict)
def build_hook_handler(self, name, finish=False):
def hook(module, *args, **kwargs):
if finish == False:
self.timing[name] = TimeLine(name, 0)
else:
# torch.cuda.synchronize()
del self.timing[name]
return hook
def remove(self):
for hook in self.hooks:
hook.remove()
model = models.resnet50(pretrained=False, num_classes=10).cuda()
hooks = TimelineHook(model)
input = torch.randn(1, 3, 224, 224).cuda()
label = torch.tensor([1]).cuda()
for _ in range(5):
output = model(input)
print(output.shape)
loss = torch.nn.functional.cross_entropy(output, label)
loss.backward()
time.sleep(0.1)
hooks.remove()
TimeLineContext().close()