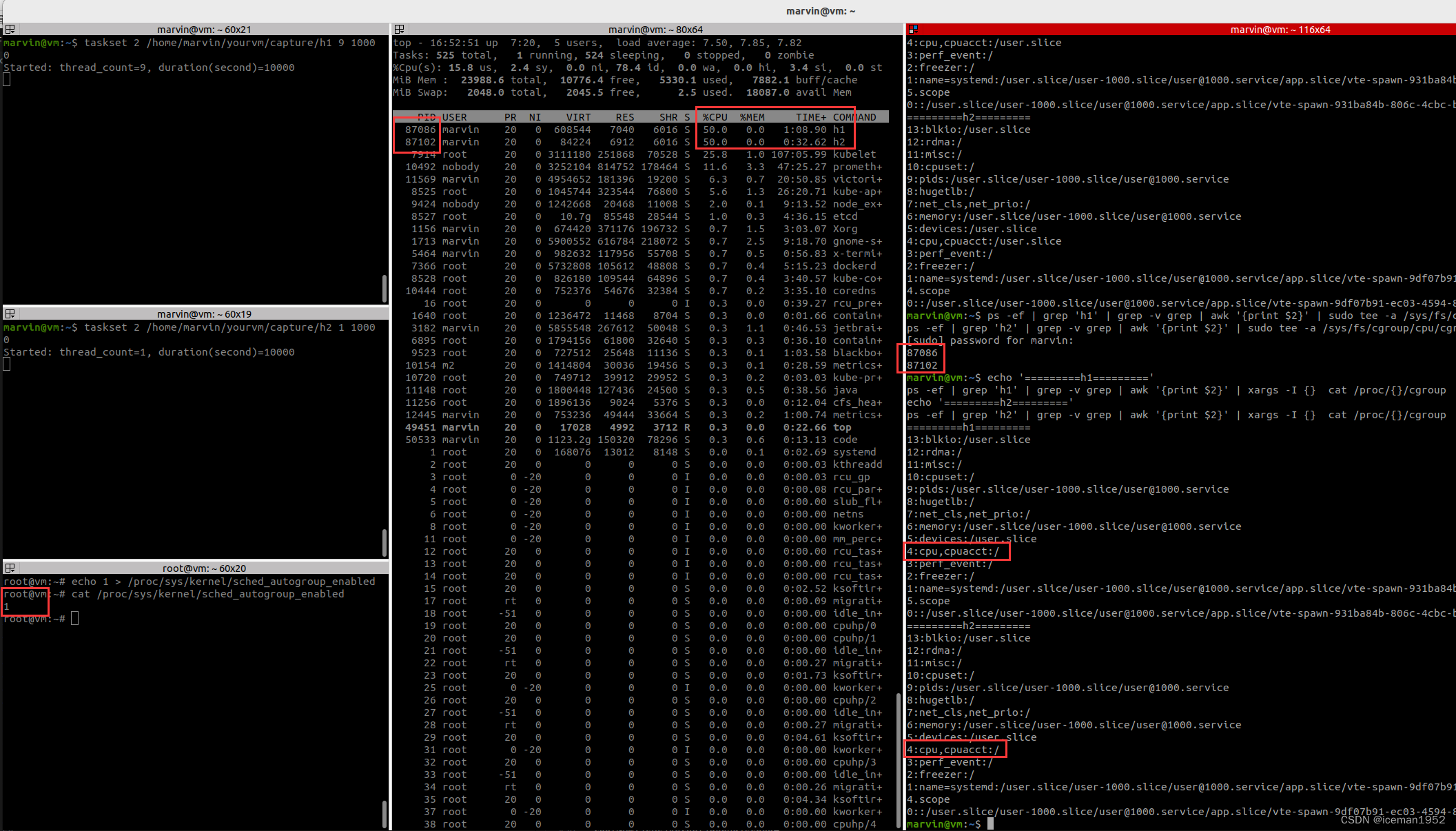
之前的文章中,我们对中证1000指数进行了顶和底的标注。这一篇我们将利用这份标注数据,实现机器学习预测顶和底,并探讨一些机器学习的原理。
我们选取的特征非常简单–上影线和WR(William’s R)的一个变种。选取这两个因子,是基于东吴证券高子剑在2020年6月的一份研报:上下影线,蜡烛好还是威廉好?。
他们的结论是,根据这两类指标的变种得到的综合因子,在2009到2020年4月,以全A为样本,进行5组分层多空测试,得到年化收益为15.86%,最大回撤仅为3.68%,可以说具有非常明显的信号意义。

在上一篇文章中,我们提到机器学习总是把要解决的问题归类为两类,一类是回归,一类是分类。如果要预测的target取值处在连续实数域上,这往往是个回归问题;如果target的值域为有限个离散状态,则是一个分类问题。

然而,具体问题总是复杂许多。初学者会觉得,既然股价的取值是在连续实数域上,因此可以把它看成回归问题,使用类似LSTM之类的神经网络来预测股价。但实际上由于金融数据的噪声问题,这么做并没有什么道理。
很可能只有在构建资产定价模型时,才可以当成回归来处理,也就是,根据公司的基本面和宏观经济指标来确定公司的市值,进而推算出股价。这本质上跟预测落杉叽的房价是同样的问题。
如果我们要构建时序方向上的预测信号呢?很可能只能用我这里的方法,不去预测每一个bar的涨跌和价格,而是改为预测顶和底,最终实现买在底部,卖出在顶部。
安装XgBoost
我们一般通过conda来安装它的Python包,但pip(需要版本在21.3以上)也是可以的。
conda install -c conda-forge py-xgboost
在Windows上安装时,还需要额外安装VC的分发包。
如果你的机器安装有支持cuda的GPU,那么conda会自动安装带GPU支持的xgboost。
不过,GPU对xgboost的加速并没有对CNN这样的神经网络那么明显。也就是说,即使有GPU,xgboost也只会在某些阶段利用到GPU加速,总体上可能会快几倍而已。考虑到我们的标注数据本身比较小,这个加速并不重要。
数据构造
经过顶底数据标注之后,我们已经获得了一份如下格式的数据:
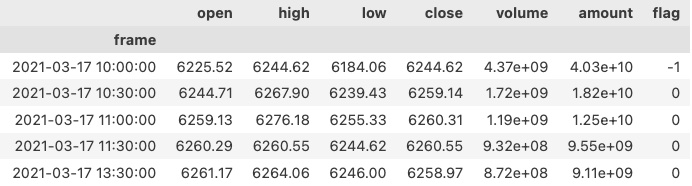
这份数据包括了标签(即flag一列),但没有我们要的特征工程数据。因此,我们要先从OHLC数据中提取出特征。
我们决定先从最简单的特征提取–上影线和WR(William’s R)的一个变种。选取这两个因子,是基于东吴证券高子剑在2020年6月的一份研报:上下影线,蜡烛好还是威廉好?。
他们的结论是,根据这两类指标的变种tr得到的综合因子,在2009到2020年4月,以全A为样本,进行5组分层多空测试,得到年化收益为15.86%,最大回撤仅为3.68%,可以说具有非常明显的信号意义。
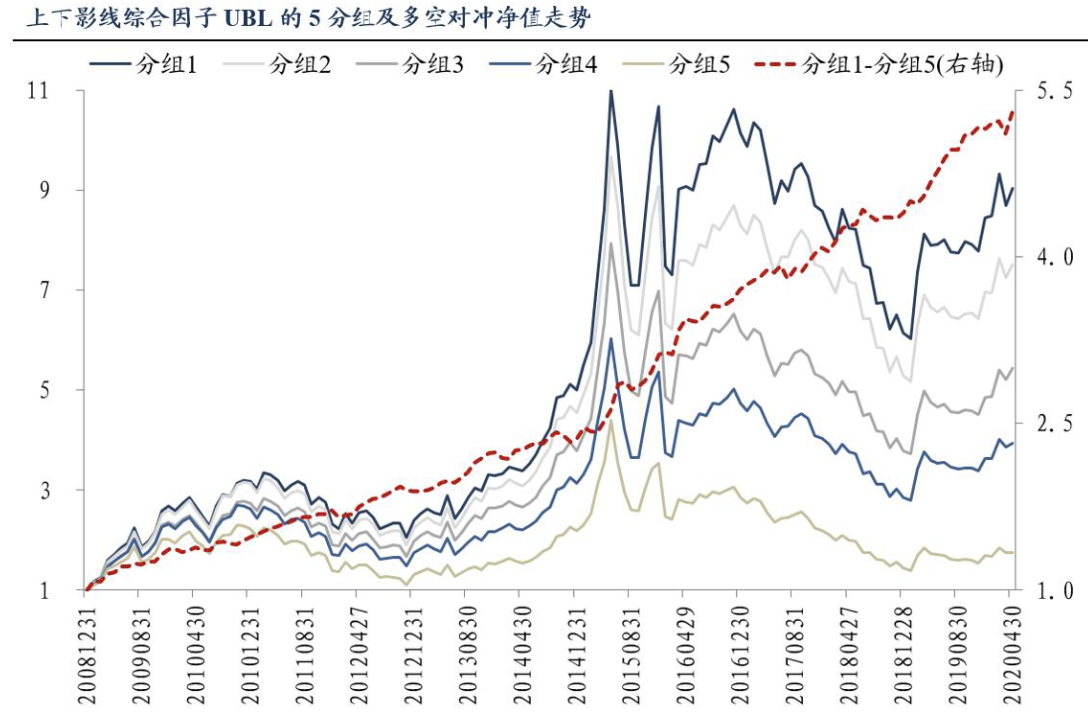
基于这个基础,我们改用机器学习的方法来做一遍。我们用来提取上下影线和WR的方法如下:
def wr_up(bars):
h, c, l = bars["high"], bars["low"], bars["close"]
shadow = h - c
# 技巧:避免产生除零错误,且不影响结果正确
return shadow/(h - l + 1e-7)
def wr_down(bars):
h, c, l = bars["high"], bars["low"], bars["close"]
shadow = c - l
return shadow/(h - l + 1e-7)
def upper_shadow(bars):
h, c, l = bars["high"], bars["low"], bars["close"]
o = bars["open"]
shadow = h - np.maximum(o, c)
return shadow/(h - l + 1e-7)
def lower_shadow(bars):
h, c, l = bars["high"], bars["low"], bars["close"]
o = bars["open"]
shadow = np.minimum(o, c) - l
return shadow/(h - l + 1e-7)
xgboost是基于树模型的,对数据的正则化本来没有要求,不过,为了便于分析和对比,我们对这四个指标都进行了归一化处理,使得数据的取值都在[0,1]之间。
如果是上下影线,值为0.5时,表明影线占了当天振幅的一半高度。如果为1,则当天收T线或者倒T(也称为墓碑线)。
William’s R 是美国作家(不要脸一下,就是博主这一类型)、股市投资家拉里.威廉在1973年出版的《我如何赚得一百万》中首先发表的一个振荡类指标,它的公式是:
W % R = H n − C n H n − L n x 100 % W\%R = \frac{H_n - C_n}{H_n - L_n} x 100\% W%R=Hn−LnHn−Cnx100%
计算向下支撑的公式略。
n是区间长度,一般设置为14天。这样 H n H_n Hn即为14天以来的最高价。其它变量依次类推。如果我们把n设置为1天,就回归成类似于上下影线的一个指标。
与K线上下影计算方法不同之处是,它只使用收盘价,而不是像上下影线那样,使用收盘价与开盘价的最大者(计算上影线时)或者最小者(计算下影线时)。
这里还有一些技巧,比如我们使用了numpy的ufunc之一, maximum来挑选开盘价和收盘价中的最大者。另一个显而易见的方法是:
np.select([c>o, o<c], [c, o])
但此处使用ufunc会得到加速。
接下来,我们就可以构建训练数据集了:
data = {
"label": raw["flag"].values,
"data": np.vstack(
(wr_up(bars),
wr_down(bars),
upper_shadow(bars),
lower_shadow(bars)
)
).T
}
bars是numpy structured array, 包含了OHLC数据和flag,由之前的raw变量转换过来。
最终我们生成了一个字典,训练数据存放在"data"下,标签数据存放在"label"下。使用了np.vstack来将特征合并起来。这些函数在《量化交易中的Numpy与Pandas》课程中有讲解。
接下来,我们引入sklearn的中的方法,将上述数据集切分为训练集和测试集,然后进行训练:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test =
train_test_split(..., test_size=.2)
我们保留了20%的数据作为测试数据。
bst = XGBClassifier(n_estimators=3, max_depth=2, learning_rate=0.5)
# fit model
bst.fit(X_train, y_train)
# make predictions
preds = bst.predict(X_test)
现在,训练完成,并且我们在测试数据集上进行了预测。接下来,我们希望知道这个模型的有效性。为此我们要引入sklearn.metrics中的一些度量方法:
from sklearn.metrics import *
acc = accuracy_score(y_test,preds)
print(f"ACC: {acc:.3f}")
recall = recall_score(y_test,preds, average='weighted')
print(f"Recall:{recall:.1%}")
f1 = f1_score(y_test,preds, average='weighted')
print(f"F1-score: {f1:.1%}")
pre = precision_score(y_test,preds, average='weighted')
print(f"Precesion:{pre:.1%}")
mx = confusion_matrix(y_test,preds)
我们得到的结果看上去很完美:
ACC: 0.930
Recall:93.0%
F1-score: 89.6%
Precesion:86.5%
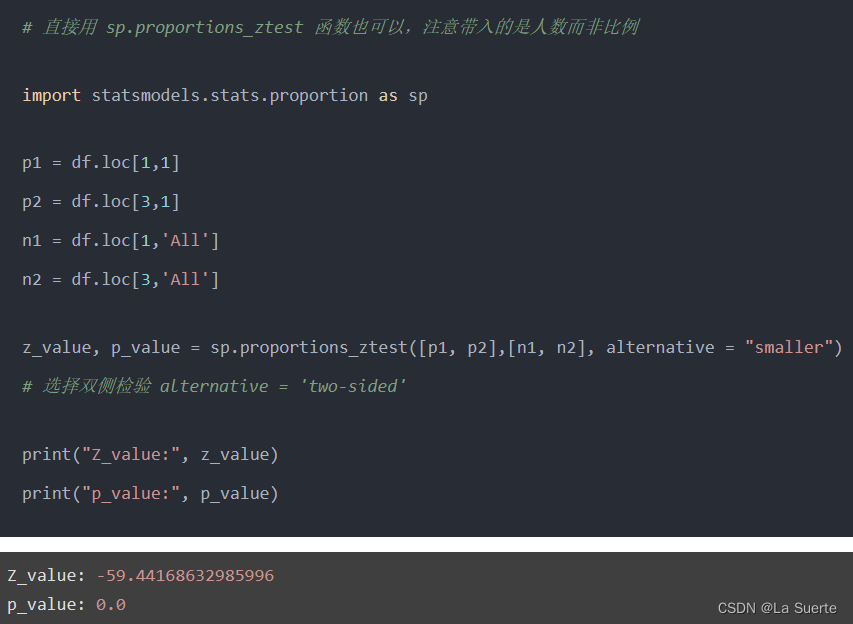
但是,这些数据能表明模型真的有效吗?幸福会不会来得太容易?所以,我们还得往下深挖一层,看看实际的预测效果究竟如何。在分析大量样本预测结果时,我们有一个利器,称为困惑矩阵(confusion matrix)。

我们要将矩阵mx可视化。人类,无论男人还是女人,都是视觉动物。我们无可救药地偏好各种色图。
sns.heatmap(mx/np.sum(mx), cmap="YlGnBu",
annot=True, fmt=".1%")
我们会得到这样一张图:
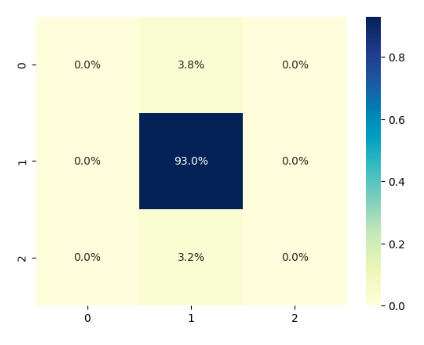
这张图表明:大约有3.8%的0类数据,被错误分类为标签1;大约有3.2%的2类数据,被错误地分类为标签1;所有的1类数据,都正确地分类为1。
从这张图我们还可以知道,这是一个严重有偏的数据集。但我们最为关注的第0类(对应于flag = -1)和第2类(对应于flag = 1),它没能正确识别。当然,它也没错到把第0类识别为第2类,或者相反。
不过,无论如何,我们有了一个好的开端。随着我们往训练数据里加入更多的数据行、更多的特征,并且使得数据按类别均匀分布后,这个模型一定会有提升。
不过,在改进之前,我们还需要掌握更多关于xgboost及评估指标的理论知识。下期见!
转载自从因子分析到机器学习策略