场景
探讨了一个回归任务——预测住房价格,用到了线性回归、决策树以及随机森林等各种算法。本次中我们将把注意力转向分类系统。我们曾经对MNIST进行了分类任务,这次我们重新回到这里,细致的再来一次。
开始
获取数据
Scikit-Learn提供了许多助手功能来帮助你下载流行的数据集。MNIST也是其中之一。获取之:
import pandas as pd
from sklearn.datasets import fetch_openml
# 加载 MNIST 数据集
mnist = fetch_openml('mnist_784', version=1, as_frame=True)
# 将数据集转换为 DataFrame
mnist_data = pd.concat([mnist.data, mnist.target], axis=1)
# 保存到本地 CSV 文件
mnist_data.to_csv('mnist_dataset.csv', index=False)
mnist_data = pd.read_csv('mnist_dataset.csv')
# 分离特征和目标变量
X = mnist_data.drop(columns=['class']) # 删除标签列获取特征
y = mnist_data['class'] # 直接使用正确的列名获取标签
print(X.shape)
print(y.shape)
结果是:
(70000, 784)
(70000,)
共有7万张图片,每张图片有784个特征。因为图片是28×28像素,每个特征代表了一个像素点的强度,从0(白色)到255(黑色)。先来看看数据集中的一个数字,你只需要随手抓取一个实例的特征向量,将其重新形成一个28×28数组,然后将其显示出来:
import matplotlib
import matplotlib.pyplot as plt
some_digit = X.iloc[36000].values # 使用 .iloc 并转换为数组
some_digit_image = some_digit.reshape(28, 28) # 重塑为 28x28 形状
# 使用 matplotlib 显示图像
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary, interpolation="nearest")
plt.axis("off") # 不显示坐标轴
plt.show() # 显示图像
print(y.iloc[36000])
显示出来是
 y也是9,说明标签是没错的。
y也是9,说明标签是没错的。
事实上MNIST数据集已经分成训练集(前6万张图像)和测试集(最后1万张图像)了:
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
同样,我们先将训练集数据洗牌,这样能保证交叉验证时所有的折叠都差不多。此外,有些机器学习算法对训练实例的顺序敏感,如果连续输入许多相似的实例,可能导致执行性能不佳。给数据集洗牌正是为了确保这种情况不会发生:[
# 生成随机排列:
# np.random.permutation(60000) 生成一个从 0 到 59999 的整数数组,这些整数被随机排列。这个数组的长度与你打算训练的数据集的样本数量相匹配。
# 使用随机索引打乱数据:
# X_train[shuffle_index] 和 y_train[shuffle_index] 则使用这个随机生成的索引数组来重新排列 X_train 和 y_train。这确保了特征集和标签集的顺序被同步打乱。由于 shuffle_index 是随机生成的,每个样本及其对应的标签都被随机分配到新的位置。
# 具体的作用包括:
# 防止模型学习数据的顺序:有时候数据可能会按照某种特定的顺序(如类别排序、时间排序等)进行排列。如果模型在这样的数据上训练,可能会错误地学习到这种顺序,而不是学习预测的实际规律。
# 改善交叉验证的效果:在使用交叉验证技术评估模型时,打乱数据可以确保每次分割都尽可能随机,避免由于数据分布不均造成的偏差。
# 均衡批处理效果:在采用批处理训练(如梯度下降)时,如果批内数据太过相似,可能导致训练不稳定或偏向某种特定的数据特征。打乱数据确保每个批次都尽可能地多样化。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
训练一个二元分类器
现在,先简化问题,只尝试识别一个数字——比如数字5。那么这个“数字9检测器”就是一个二元分类器的例子,它只能区分两个类别:9和非9。先为此分类任务创建目标向量:
y_train_9 = (y_train == 9)
y_test_9 = (y_test == 9)
SGDClassifier
随机梯度下降(SGD)分类器是一种流行的机器学习算法,主要用于线性分类和回归问题。SGD 是适用于大规模和高维数据集的优化技术。
SGD 工作原理基于梯度下降算法,该算法通过计算损失函数(J(X))的梯度来更新模型的权重。与传统的梯度下降方法每次使用整个数据集来计算梯度不同,SGD 每次只随机选择一个训练样本来计算梯度并更新模型。
效率:每次迭代只处理一个数据点,大大减少了计算量。
快速迭代:不需要等待整个数据集的梯度计算,因此每个更新都能更快地执行。
适应性:因为每次更新都使用最新的数据,SGD 能够适应数据的在线和非静态分布变化。
优点
扩展性:由于其处理数据的方式,SGD 特别适合于大规模数据集。
在线学习:SGD 可以一边生成数据一边完成模型训练,适合于需要在线学习的应用场景。
处理稀疏数据:SGD 在处理稀疏特征数据时效果很好,因为稀疏数据中的零梯度不会对权重更新产生影响。
逃离局部最小值:由于每次更新只基于部分数据,其随机性有助于模型逃离局部最小值,尽管这也可能导致最终结果的不稳定。
缺点
参数敏感:SGD 的性能高度依赖于参数配置,如学习率和调度策略。
收敛问题:由于其更新随机性,SGD 的收敛过程可能会比批量梯度下降更嘈杂和不稳定。
需要多次迭代:可能需要较多的迭代次数来接近最优解。
特征缩放敏感:SGD 对特征的缩放很敏感,不同的特征量级可能导致训练过程不稳定。
训练并且验证
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_9)
sgd_clf.predict([some_digit])
结果是:
[ True]
代表是9,看来猜对了。那么,下面评估一下这个模型的性能。
性能考核
使用交叉验证测量精度
StratifiedKFold 是一种交叉验证方法,它保证每个折叠(fold)中各类的比例与整体数据集中的比例相同。这对于处理不平衡数据集特别有用,可以保证在训练和验证过程中每个类别的样本都得到合理的表示。
手动实现的交叉验证
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42)
for train_index, test_index in skfolds.split(X_train, y_train_9):
# 克隆分类器:使用clone(sgd_clf)克隆原始的SGD分类器,这样每次都使用一个未经训练的新分类器,避免之前训练的干扰。
clone_clf = clone(sgd_clf)
# 索引训练集和测试集:根据StratifiedKFold提供的索引分割原始的训练数据X_train和对应的标签y_train_9。
X_train_folds = X_train[train_index]
y_train_folds = (y_train_9[train_index])
X_test_fold = X_train[test_index]
y_test_fold = (y_train_9[test_index])
clone_clf.fit(X_train_folds, y_train_folds)
# 预测测试集:在当前折叠的测试集上运行分类器进行预测。
# 评估模型:计算正确预测的数量并计算此折的准确率。
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))
评估
正在使用整个训练集数据来进行交叉验证。在这里,cv=3 参数指的是将 X_train 和 y_train_9 划分成3个不同的部分来进行交叉验证。
from sklearn.model_selection import cross_val_score
result = cross_val_score(sgd_clf, X_train, y_train_9, cv=3, scoring="accuracy")
print(result)
验证结果
[0.9419 0.9196 0.9542]
所有折叠交叉验证的准确率超过90%? 我们需要对照以下,我们弄一个非9的分类器:这个分类器的设计初衷是为了不预测任何输入数据为数字9。
import numpy as np
from sklearn.base import BaseEstimator
class Never9Classifier(BaseEstimator):
def fit(self, X, y=None):
pass
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
never_9_classifier = Never9Classifier()
result = cross_val_score(never_9_classifier, X_train, y_train_9, cv=3, scoring="accuracy")
print(result)
结果有点秀:
[0.90135 0.90055 0.90065]
没错,准确率超过90%!这是因为只有大约10%的图像是数字9,所以如果你猜一张图不是9,90%的时间都是正确的,简直超越了大预言家!这说明准确率通常无法成为分类器的首要性能指标。
混淆矩阵
混淆矩阵是一个非常有用的工具,用于评估分类模型的性能,特别是在多类分类问题中。可以直观地看到模型在不同类别上的表现如何。混淆矩阵是一个表格,其行代表实际的类别,而列代表预测的类别。对于一个二分类问题,混淆矩阵通常包括以下四个部分:
真正类(True Positives, TP):模型正确预测为正类的数量。
假正类(False Positives, FP):模型错误预测为正类的数量(实际为负类)。
真负类(True Negatives, TN):模型正确预测为负类的数量。
假负类(False Negatives, FN):模型错误预测为负类的数量(实际为正类)。
总体思路就是统计A类别实例被分成为B类别的次数。例如,要想知道分类器将数字3和数字9混淆多少次,只需要通过混淆矩阵的第9行第3列来查看。要计算混淆矩阵,需要先有一组预测才能将其与实际目标进行比较。当然可以通过测试集来进行预测,但是现在先不要动它(测试集最好留到项目最后准备启动分类器时再使用)。作为替代,可以使用cross_val_predict()函数:
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_9, cv=3)
与cross_val_score()函数一样,cross_val_predict()函数同样执行K-fold交叉验证,但返回的不是评估分数,而是每个折叠的预测。这意味着对于每个实例都可以得到一个干净的预测
现在,可以使用confusion_matrix()函数来获取混淆矩阵了。只需要给出目标类别(y_train_9)和预测类别(y_train_pred)即可:
from sklearn.metrics import confusion_matrix
result = confusion_matrix(y_train_9, y_train_pred)
print(result)
其结果是:
[[51894 2157]
[ 1121 4828]]
真负类(True Negatives, TN): 51894 这个数值位于矩阵的左上角,表示模型正确预测的负类数量(即预测为非9,实际也为非9的样本数)。
假正类(False Positives, FP): 2157 这个数值位于矩阵的右上角,表示模型错误地预测为正类的数量(即预测为9,但实际为非9的样本数)。
假负类(False Negatives, FN): 1121 这个数值位于矩阵的左下角,表示模型错误地预测为负类的数量(即预测为非9,但实际为9的样本数)。
真正类(True Positives, TP): 4828 这个数值位于矩阵的右下角,表示模型正确预测的正类数量(即预测为9,实际也为9的样本数)。
这是一个完美的分类器的情况
y_train_perfect_predictions = y_train_9
result = confusion_matrix(y_train_9, y_train_perfect_predictions)
print(result)
[[54051 0]
[ 0 5949]]
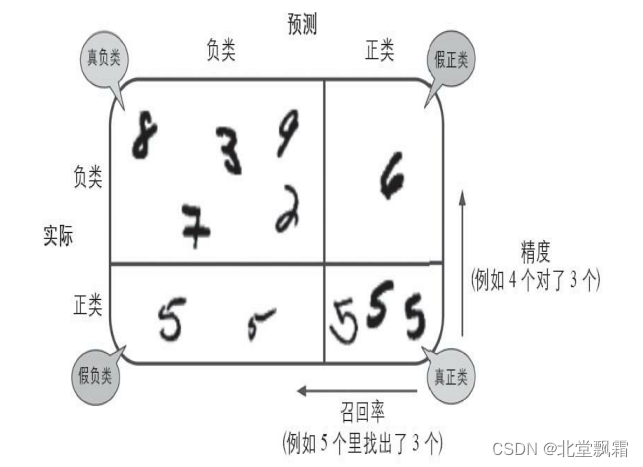
一个完美的分类器只有真正类和真负类,所以它的混淆矩阵只会在其对角线(左上到右下)上有非零值,混淆矩阵能提供大量信息,但有时你可能希望指标更简洁一些。正类预测的准确率是一个有意思的指标,它也称为分类器的精度
精度
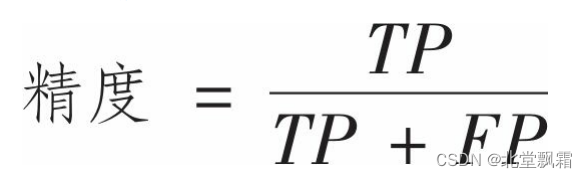
TP是真正类的数量,FP是假正类的数量。做一个单独的正类预测,并确保它是正确的,就可以得到完美精度(精度=1/1=100%)。但这没什么意义,因为分类器会忽略这个正类实例之外的所有内容。因此,精度通常与另一个指标一起使用,这个指标就是召回率(recall),也称为灵敏度(sensitivity)或者真正类率(TPR):它是分类器正确检测到的正类实例的比率
召回率
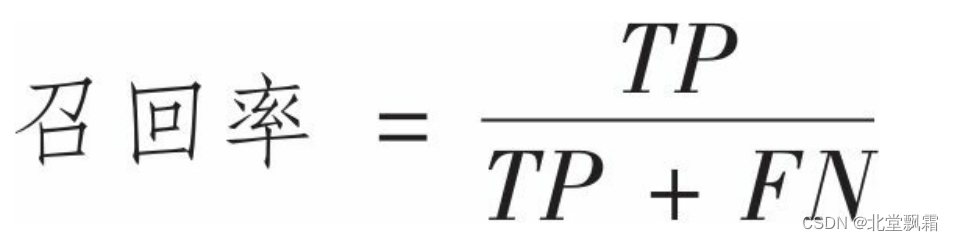
FN是假负类的数量。
精度和召回率
Scikit-Learn提供了计算多种分类器指标的函数,精度和召回率也是其一:
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_train_9, y_train_pred)
recall = recall_score(y_train_9, y_train_pred)
print(precision)
print(recall)
这次结果并不是很好,只有69%的时间是准确的,并且也只有70%的数字9被它检测出来了。
0.6901477032949197
0.7147419734409144
因此我们可以很方便地将精度和召回率组合成一个单一的指标,称为F1分数。当你需要一个简单的方法来比较两种分类器时,这是个非常不错的指标。F1分数是精度和召回率的谐波平均值。正常的平均值平等对待所有的值,而谐波平均值会给予较低的值更高的权重。因此,只有当召回率和精度都很高时,分类器才能得到较高的F1分数。
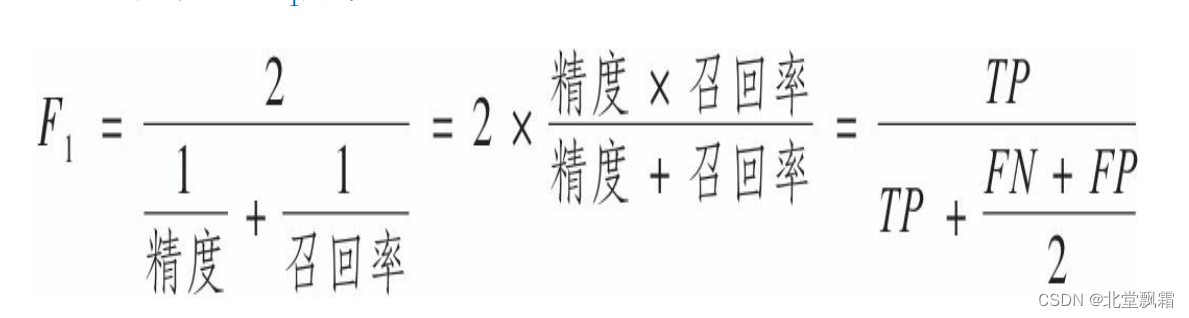
要计算F1分数,只需要调用f1_score()即可:
from sklearn.metrics import f1_score
f1 = f1_score(y_train_9, y_train_pred)
print(f1)
f1为
0.7525732694272019
F分数是精确率和召回率的调和平均值,通常用来评估分类器的综合性能,特别是当你希望分类器在这两个方面表现均衡时。
精确率和召回率的权衡
精确率 (Precision): 是指分类器预测为正的样本中实际为正的比例。高精确率意味着分类器在预测正样本时更加可信,误报率较低。
召回率 (Recall): 是指所有实际正样本中,被分类器正确预测为正的比例。高召回率意味着分类器能够捕捉到更多的正样本,遗漏率较低。
儿童安全视频检测:在这种场景中,你会更偏好高精确率而可能牺牲召回率。这是因为你希望确保所有通过分类器的视频都是对儿童安全的,即便这意味着拒绝了一些实际上无害的视频。在这里,一个假阳性(即错误地将不安全的视频标记为安全)的后果可能远比假阴性(即错误地将安全的视频标记为不安全)来得严重。在某些情况下,尤其是当后果严重或者需要极高准确度的场景中,可能需要在自动分类器后设置一个人工审核步骤。例如,在儿童安全视频检测中,即使使用了高精确率的分类器,也可能需要人工复查分类器的选择,以确保没有不适宜内容误入
商店防盗检测:在这种情况下,你可能更倾向于高召回率,哪怕精确率不高。原因在于你希望尽可能捕捉到所有的潜在偷窃行为,即便这导致了一些误报(安全人员接收到一些非窃贼的报警)。在这里,一个假阴性(即错过一个真正的窃贼)的代价比假阳性(即错误标记一个顾客为窃贼)更不可接受。
阈值
阈值(Threshold)是一个决定性因素,它在决策函数的输出和最终的类别预测之间起着桥梁的作用。阈值的设置对于模型的精确率(Precision)和召回率(Recall)有着直接影响。
阈值的作用
分类决策的基础:
在二分类模型中,表示样本属于正类的可能性。阈值是一个设定的界限,当模型输出超过这个界限时,样本被划分为正类;否则,被划分为负类。
精确率与召回率的调节器:
提高阈值:当你提高阈值时,只有那些模型非常确信是正类的样本才会被预测为正类。这通常会提高精确率(较少的假正类),但可能降低召回率(错过一些真正的正类样本)。
降低阈值:降低阈值使得更多的样本被划分为正类,这可以提高召回率(捕捉更多的正类样本),但同时可能降低精确率(增加假正类的数量)。
阈值的选择
阈值的选择取决于具体应用场景的需求:
高精确率的需求:在某些应用中,如儿童视频过滤,一个错误的正类预测(将不适当的内容误标为适当)可能带来严重后果。在这种情况下,可能会设定较高的阈值,以确保只有最有可能是正类的样本被分类为正类。
高召回率的需求:在其他情况下,如疾病筛查或欺诈检测,错过任何一个正类可能都会有严重的负面影响。因此,可能会设定较低的阈值,以尽可能捕获所有的正类案例。
Scikit-Learn不允许直接设置阈值,但是可以访问它用于预测的决策分数。不是调用分类器的predict()方法,而是调用decision_function()方法,这个方法返回每个实例的分数,然后就可以根据这些分数,使用任意阈值进行预测了:
y_scores = sgd_clf.decision_function([some_digit])
print(y_scores)
threshold = 0
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred)
结果:很遗憾 预测错误
[-4830.47129297]
[False]
如果分数是正数,意味着模型认为样本位于决策边界的正侧,通常对应于模型预测的正类(例如,类别1)。
如果分数是负数,意味着模型认为样本位于决策边界的负侧,通常对应于模型预测的负类(例如,类别0)。
模型的判断:模型非常有信心地认为这个样本不属于正类。换句话说,这个分数反映了模型对其预测负类的高度确定性。
预测结果:由于分数远低于阈值,所以预测结果 y_some_digit_pred 为 [False],即模型预测这不是一个正类的实例。
当我们直接将阈值降到-10000时候,那么召回率增加了,但是精度大大降低了!
那么要如何决定使用什么阈值呢?首先,使用cross_val_predict()函数获取训练集中所有实例的分数,但是这次需要它返回的是决策分数而不是预测结果:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_9, cv=3, method="decision_function")
有了这些分数,可以使用precision_recall_curve()函数来计算所有可能的阈值的精度和召回率
precisions, recalls, thresholds = precision_recall_curve(y_train_9, y_scores)
precision_recall_curve详细解释
precision_recall_curve
功能:precision_recall_curve 函数计算在不同阈值设置下的精确率(precision)和召回率(recall)。这个函数返回三个数组:precisions、recalls、和 thresholds。每个数组的元素都对应于一个特定的决策阈值。
用途:此函数主要用于评估模型在各种阈值水平上的表现,并帮助选择最佳的阈值,以平衡精确率和召回率。这对于处理那些精确率和召回率权衡特别重要的情况非常有用,如欺诈检测或疾病筛查。
输出:
precisions:每个阈值对应的精确率。
recalls:每个阈值对应的召回率。
thresholds:用于计算上述精确率和召回率的决策阈值数组。
precision_score 和 recall_score
功能:这些函数计算在给定的预测结果和真实标签上的精确率和召回率。它们提供了单一的指标值,通常基于默认或指定的阈值(例如,决策函数输出大于0则预测为正类)。
用途:这些函数用于快速获取模型在特定阈值(通常是默认阈值)下的性能指标。它们适用于模型性能的快速评估,尤其是在阈值已确定的情况下。
输出:
precision_score:给定阈值下的精确率。
recall_score:给定阈值下的召回率。
区别
灵活性:precision_recall_curve 提供了一个全面的视图,展示了随着阈值变化精确率和召回率是如何变化的,而 precision_score 和 recall_score 通常基于单一、固定的阈值来计算这些指标。
用途:如果你需要理解不同阈值对模型性能的影响,precision_recall_curve 是更合适的工具。相反,如果你只需要快速检查或报告模型在特定设置下的性能,使用 precision_score 和 recall_score 更为简便。
最后,使用Matplotlib绘制精度和召回率相对于阈值的函数图
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel("Threshold")
plt.legend(loc="upper left")
plt.ylim([0, 1])
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()
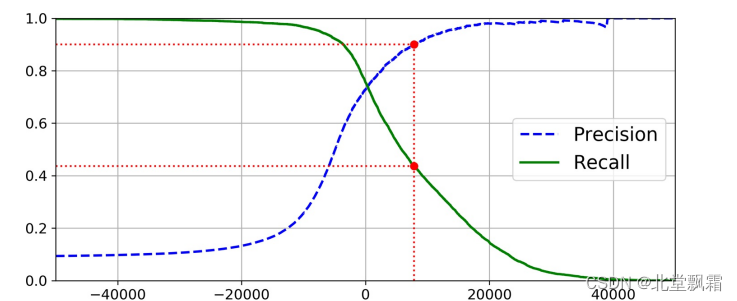
总结是:
从80%的召回率往右,精度开始急剧下降。你可能会尽量在这个陡降之前选择一个精度/召回率权衡——比如召回率60%。当然,如何选择取决于你的项目。假设你决定瞄准90%的精度目标。
y_train_pred_90 = (y_scores > 70000)
precision = precision_score(y_train_9, y_train_pred_90)
recall = recall_score(y_train_9, y_train_pred_90)
print(precision)
print(recall)
好了,现在有一个90%精度的分类器了(或者足够接近)!创建任意一个你想要的精度的分类器是相当容易的事情:只要阈值足够高即可!然而,如果召回率太低,精度再高,其实也不怎么有用!如果有人说:“我们需要99%的精度。”你就应该问:“召回率是多少?”
多类别分类器
在机器学习中,有些算法如随机梯度下降(SGD)分类器、随机森林分类器和朴素贝叶斯分类器能够直接处理多类别问题。然而,一些其他算法,比如逻辑回归和支持向量机(SVM),本质上是二分类器,它们需要特定的策略来处理多类别分类。
:
一对其余(OvR,也称为一对所有):这种方法涉及为每个类别训练一个二分类器。例如,在数字识别中,可以训练一个0检测器,一个1检测器,等等,共10个分类器(对应数字0到9)。在分类一个图像时,你会从每个分类器获取一个决策得分,并选择得分最高的类别作为输出结果。这个策略就像是你举起一种颜色的球,比如红球,然后让其他所有的球与红球比较,看看哪些是红球,哪些不是。这种方式很直接,就像你把所有的红球放在一边,其他所有的球放在另一边。然后你再拿起蓝球,做同样的事,再来是黄球,以此类推。
一对一(OvO):此方法要求训练每一对类别之间的二分类器。如果有N个类别,那么需要训练N × (N – 1) / 2个分类器。对于每个类别对(如0和1,0和2等),训练一个分类器。对于识别手写数字的MNIST问题,这意味着需要训练45个二分类器!在对图像进行分类时,必须通过所有这些分类器运行图像,看哪个类别在对决中胜出次数最多。OvO的一个主要优点是每个分类器只需在必须区分的两个类别的训练集部分上进行训练。
这就像是你和你的朋友们玩一个游戏,比较每两种颜色的球谁的更多。首先,你拿起所有的红球和蓝球,数一数哪种颜色的球更多,然后记录下来。接下来,比较红球和黄球,再记录下来。你会这样做很多次,直到每两种颜色的球都比较过。这个方法很好因为当球的总数很多时,每次只需要比较两种颜色的球,这样会比较快。
OvO策略通常适用于那些随训练集大小扩大而表现不佳的算法,如SVM,因为在较小的训练集上训练多个分类器比在大型训练集上训练少数几个分类器要快。然而,对于大多数二分类算法,一般更倾向于使用OvR策略。
Scikit-Learn能够自动检测当你尝试用一个二分类算法解决多类分类任务时,并会根据算法的不同自动运行OvR或OvO策略。例如,在使用Scikit-Learn的sklearn.svm.SVC类训练支持向量机分类器时,就是这种情况。
svm_clf = SVC()
svm_clf.fit(X_train, y_train)
svm_clf.predict([X.iloc[36000]])
some_digit_scores = svm_clf.decision_function([X.iloc[36000]])
print(some_digit_scores)
输出是
[[ 1.70506533 4.89597617 -0.30950622 4.16191052 8.30179489 3.10419772
0.69948654 7.25322361 6.26259103 9.30853054]]
显然9的分数最高,所以分类就分到9了.
如果想强制Scikit-Learn使用一对一(One-vs-One)或一对其余(One-vs-Rest)的策略,你可以使用OneVsOneClassifier或OneVsRestClassifier类。只需创建一个实例并将一个分类器传递给它的构造函数(这个分类器甚至不必是二分类器)
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC())
ovr_clf.fit(X_train, y_train)
result = ovr_clf.predict([X.iloc[36000]])
print(result)
decision_result = ovr_clf.decision_function([X.iloc[36000]])
print(decision_result)
print(len(ovr_clf.estimators_))
结果
[9]
[[-2.53415701 -1.86912293 -3.99505471 -1.69708316 -1.22221512 -1.53091305
-2.92555266 -1.75230027 -2.18596344 0.44970378]]
10
错误分析
如果这是一个真实的项目,现在会按照机器学习项目清单的步骤进行。将会探索数据准备选项,尝试多个模型(筛选最佳模型并使用GridSearchCV调整它们的超参数),并尽可能实现自动化。在这里,我们假设已经找到了一个有前景的模型,而想要找到改进它的方法。其中一种方法是分析它所犯的错误类型。首先,查看混淆矩阵。需要使用cross_val_predict()函数进行预测,然后像之前一样调用confusion_matrix()函数。
y_train_pred = cross_val_predict(ovr_clf, X_train, y_train,cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
print(conf_mx)
混淆矩阵看起来很不错,因为大多数图片都在主对角线上,这说明它们被正确分类。数字9看起来比其他数字稍稍暗一些,这可能意
味着数据集中数字9的图片较少,也可能是分类器在数字9上的执行效果不如在其他数字上好。可能会验证这两者都属实。让我们把焦点放在错误上。
利用混淆矩阵来判断分类器好坏的几个关键点:
真实值与预测值:混淆矩阵的每一行代表实际的类别,每一列代表预测的类别。矩阵对角线上的值表示正确分类的数量,非对角线上的值表示错误分类的数量。
错误分析:通过观察混淆矩阵中的非对角线值,可以识别出分类器常犯的错误类型,比如经常将哪两个类别相互误分。这可以帮助进一步调整分类器或进行特征工程。
多标签分类
到目前为止,每个实例都只会被分在一个类别里。而在某些情况下,你希望分类器为每个实例产出多个类别。例如,人脸识别的分类器:如果在一张照片里识别出多个人怎么办?当然,应该为识别出来的每个人都附上一个标签。假设分类器经过训练,已经可以识别出三张脸—爱丽丝、鲍勃和查理,那么当看到一张爱丽丝和查理的照片时,它应该输出[1,0,1](意思是“是爱丽丝,不是鲍勃,是查理”)这种输出多个二元标签的分类系统称为多标签分类系统。
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
这段代码会创建一个y_multilabel数组,其中包含两个数字图片的目标标签:第一个表示数字是否是大数(7、8、9),第二个表示是否为奇数。下一行创建一个KNeighborsClassifier实例(它支持多标签分类,不是所有的分类器都支持),然后使用多个目标数组对它进行训练。现在用它做一个预测,注意它输出的两个标签:
print(knn_clf.predict([X.iloc[36000]]))
返回
[[ True True]]
结果是正确的!数字9确实是大数(True),为奇数(True)。评估多标签分类器的方法很多,如何选择正确的度量指标取决于你的项目。比如方法之一是测量每个标签的F1分数,然后简单地平均。下面这段代码计算所有标签的平均F1分数:
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3)
f1_score(y_train, y_train_knn_pred, average="macro")
多输出分类
简单来说,它是多标签分类的泛化,其标签也可以是多种类别的(比如它可以有两个以上可能的值)。为了说明这一点,构建一个系统去除图片中的噪声。给它输入一张有噪声的图片,它将(希望)输出一张干净的数字图片,跟其他MNIST图片一样,以像素强度的一个数组作为呈现方式。请注意,这个分类器的输出是多个标签(一个像素点一个标签),每个标签可以有多个值(像素强度范围为0到225)。所以这是个多输出分类器系统的例子。
还先从创建训练集和测试集开始,使用NumPy的randint()函数为MNIST图片的像素强度增加噪声。目标是将图片还原为原始图片:
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_mod, y_train_mod)
设置目标数据集:
y_train_mod = X_train 和 y_test_mod = X_test:这里将原始的无噪声图像设置为目标数据集(即模型训练的目标是从带噪声的图像恢复出原始的清晰图像)。
模型的初始化和训练:
knn_clf = KNeighborsClassifier():初始化一个K近邻分类器。K近邻算法是一种基于实例的学习,用于分类和回归。
knn_clf.fit(X_train_mod, y_train_mod):使用带噪声的训练数据集X_train_mod作为输入特征,原始清晰的图像X_train作为目标,训练K近邻分类器。在这个过程中,分类器学习如何根据输入的带噪声图像预测出对应的清晰图像。
用处:
这种训练方式通常用于图像去噪、修复损坏的图像等任务。在实际应用中,例如扫描破损的文档或修复老照片时非常有用。
训练好的模型能够理解如何从损坏或噪声干扰的图像中恢复出原始的、清晰的图像内容。
多标签特性:
在这个图像修复的例子中,每个输入实例(即带噪声的图像)的输出是784维的向量,每个维度代表图像一个像素的灰度值。因此,这不仅是一个分类问题,而且每个“标签”(这里指的是每个像素)都可以看作是一个输出变量,需要被同时预测。
多输出:
与传统的分类问题(如猫狗分类,输出是单一标签)不同,这里的每个像素都需要一个独立的预测结果,这些结果表现为像素的灰度值。这就意味着模型需要能够同时处理和预测多个输出标签。
结束
在本次探索中,我们深入了解并实践了各种机器学习技术,从基本的二元分类器到复杂的多输出分类系统。我们利用MNIST数据集,一个广泛使用的手写数字识别数据集,作为我们学习和测试的平台。通过逐步构建和优化各种模型,我们得以揭示机器学习项目实施的多个关键阶段:
数据处理与可视化:我们从获取和预处理数据开始,理解数据的基本结构,然后通过可视化一个具体实例,直观感受数据的实际形态。
分类问题的实现:我们首先针对二元分类(如识别数字9)进行了讨论,并逐步扩展到多类别分类,解释了如何使用一对一(OvO)和一对所有(OvR)策略处理更复杂的分类问题。
性能评估:深入分析了使用混淆矩阵、精确率、召回率和F1分数等工具来评估分类器性能的方法。通过这些度量,我们可以详细了解模型在各个方面的表现,以及如何通过调整阈值来平衡精确率与召回率。
多标签和多输出分类:探索了更高级的分类任务,如多标签分类,它允许一个实例同时被标记为多个类别。我们也探讨了多输出分类,通过图像去噪的实例,说明了如何处理输出标签是多种类别的情况。
错误分析:通过分析模型所犯的错误,我们学习了如何进一步改进模型的性能,这通常涉及到对数据进行更精细的处理或调整模型参数。