Word2Vector
1.什么是词嵌入模型?
把词映射为实数域向量的技术也叫词嵌⼊
2.介绍一下Word2Vec
谷歌2013年提出的Word2Vec是目前最常用的词嵌入模型之一。Word2Vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是连续词袋(CBOW)和跳字(Skip-Gram)模型。
3.介绍CBOW
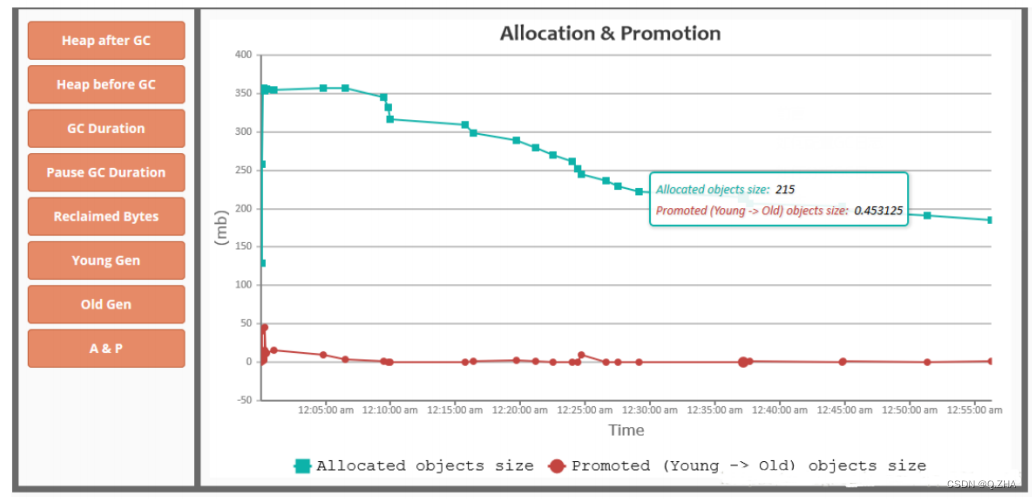
CBOW,全称Continuous Bag-of-Word,中文叫做连续词袋模型:以上下文来预测当前词 w t w_t wt 。CBOW模型的目的是预测 $P(w_t| w_{t-k}, \cdots, w_{t-1}, w_{t+1}, \cdots, w_{t+k}) $

前向传播过程
-
输入层: 输入C个单词 x x x: $x_{1k}, \cdots, x_{Ck} $,并且每个 x x x 都是用 One-hot 编码表示,每一个 x x x 的维度为 V(词表长度)。
-
输入层到隐层
- 首先,共享矩阵为 W V × N W_{V \times N} WV×N ,V表示词表长度,W的每一行表示的就是一个N维的向量(训练结束后,W的每一行就表示一个词的词向量)。
- 然后,我们把所有输入的词转 x x x化为对应词向量,然后取平均值,这样我们就得到了隐层输出值 ( 注意,隐层中无激活函数,也就是说这里是线性组合)。 其中,隐层输出 h h h 是一个N维的向量 。
h = 1 C W T ( x 1 + x 2 + ⋯ + x c ) h = \frac{1}{C} W^T(x_1 + x_2 + \cdots + x_c) h=C1WT(x1+x2+⋯+xc)
-
隐层到输出层:隐层的输出为N维向量 h h h , 隐层到输出层的权重矩阵为 W N × V ′ W'_{N \times V} WN×V′ 。然后,通过矩阵运算我们得到一个 $V \times 1 $ 维向量
u = W ′ T ∗ h u = W'^{T} * h u=W′T∗h
其中,向量
u
u
u 的第
i
i
i 行表示词汇表中第
i
i
i 个词的可能性,然后我们的目的就是取可能性最高的那个词。因此,在最后的输出层是一个softmax 层获取分数最高的词,那么就有我们的最终输出:
P
(
w
j
∣
c
o
n
t
e
x
t
)
=
y
i
=
e
x
p
(
u
j
)
∑
k
∈
V
e
x
p
(
u
k
)
P(w_j| context) =y_i = \frac{exp({u_j})}{\sum_{k \in V} exp({u_k})}
P(wj∣context)=yi=∑k∈Vexp(uk)exp(uj)
损失函数
我们假定
j
∗
j^*
j∗ 是真实单词在词汇表中的下标,那么根据极大似然法,则目标函数定义如下:
E
=
−
l
o
g
p
(
W
O
∣
W
I
)
=
−
l
o
g
e
x
p
(
u
j
)
∑
k
∈
V
e
x
p
(
u
k
)
=
l
o
g
∑
k
∈
V
e
x
p
(
u
k
)
−
u
j
E = -log \, p(W_O |W_I) = -log \, \frac{exp({u_j})}{\sum_{k \in V} exp({u_k})} = log \sum_{k \in V} exp(u_{k}) -u_j
E=−logp(WO∣WI)=−log∑k∈Vexp(uk)exp(uj)=logk∈V∑exp(uk)−uj
4.Skip-gram模型
Skip-Gram的基本思想是:通过当前词 w t w_t wt 预测其上下文 w t − i , ⋯ , w t + i w_{t-i}, \cdots , w_{t+i} wt−i,⋯,wt+i ,模型如下图所示:
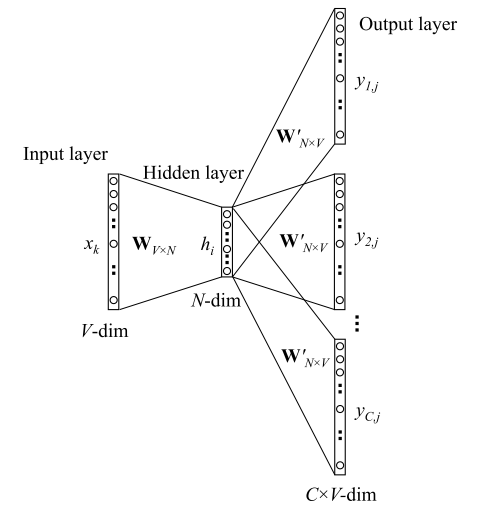
前向传播过程
-
输入层: 输入的是一个单词,其表示形式为 One-hot ,我们将其表示为V维向量 x k x_k xk ,其中 V V V 为词表大小。然后,通过词向量矩阵 W V × N W_{V \times N} WV×N 我们得到一个N维向量
h = W T ∗ x k = v w I T h = W^T * x_k = v^{T}_{w_I} h=WT∗xk=vwIT -
隐层: 而隐层中没有激活函数,也就是说输入=输出,因此隐藏的输出也是 h h h 。
-
隐层到输出层:
-
首先,因为要输出C个单词,因此我们此时的输出有C个分布: $y_1, \cdots y_C $,且每个分布都是独立的,我们需要单独计算, 其中 y i y_i yi 表示窗口的第 i i i 个单词的分布。
-
其次, 因为矩阵 W N × V ′ W'_{N \times V} WN×V′ 是共享的,因此我们得到的 V × 1 V \times 1 V×1 维向量 u u u 其实是相同的,也就是有 u c , j = u j u_{c,j} = u_j uc,j=uj ,这里 u u u 的每一行同 CBOW 中一样,表示的也是评分。
-
最后,每个分布都经过一个 softmax 层,不同于 CBOW,我们此处产生的是第 i i i 个单词的分布(共有C个单词),如下:
P ( w i , j ∣ c o n t e x t ) = y i = e x p ( u j ) ∑ k ∈ V e x p ( u k ) P(w_{i,j}| context) =y_i = \frac{exp({u_j})}{\sum_{k \in V} exp({u_k})} P(wi,j∣context)=yi=∑k∈Vexp(uk)exp(uj)
-
损失函数
假设
j
∗
j^*
j∗ 是真实单词在词汇表中的下标,那么根据极大似然法,则目标函数定义如下:
E
=
−
l
o
g
p
(
w
1
,
w
2
,
⋯
,
w
C
∣
w
I
)
=
−
l
o
g
∏
c
=
1
C
P
(
w
c
∣
w
i
)
=
−
l
o
g
∏
c
=
1
C
e
x
p
(
u
c
,
j
)
∑
k
=
1
V
e
x
p
(
u
c
,
k
)
=
−
∑
c
=
1
C
u
j
c
∗
+
C
⋅
l
o
g
∑
k
=
1
V
e
x
p
(
u
k
)
\begin{split} E &= - log \, p(w_1, w_2, \cdots, w_C | w_I) \\ &= - log \prod_{c=1}^C P(w_c|w_i) \\ &= - log \prod_{c=1}^{C} \frac{exp(u_{c, j})}{\sum_{k=1}^{V} exp(u_{c,k}) } \\ &= - \sum_{c=1}^C u_{j^*_c} + C \cdot log \sum_{k=1}^{V} exp(u_k) \end{split}
E=−logp(w1,w2,⋯,wC∣wI)=−logc=1∏CP(wc∣wi)=−logc=1∏C∑k=1Vexp(uc,k)exp(uc,j)=−c=1∑Cujc∗+C⋅logk=1∑Vexp(uk)
5.Word2Vec与LDA的区别
-
LDA
LDA是利用文档中单词的共现关系来对单词按主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。
-
Word2Vec
Word2Vec是利用上下文-单词“矩阵进行学习,其中上下文由周围的几个单词组成,由此得到的词向量表示更多地融入了上下文共现的特征。也就是说,如果两个单词所对应的word2vec向量相似度较高,那么它们很可能经常在同样的上下文中出现。
-
LDA模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题);
-
而Word2Vec模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
6.Word2Vec存在的问题是什么?
- 对每个local context window单独训练,没有利用包 含在global co-currence矩阵中的统计信息。
- 对多义词无法很好的表示和处理,因为使用了唯一的词向量
Tf-idf
1.介绍一下Tf-idf
一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
-
TF: Term Frequency, 表示词频。 一个给定的词在该文章中出现的次数。
T F = 某个词在文章中的出现次数 文章的总词数 TF = \frac{\text{某个词在文章中的出现次数}}{\text{文章的总词数}} \\ TF=文章的总词数某个词在文章中的出现次数 -
IDF: Inverse Document Frequency, 表示逆文档频率。如果包含词条 t 的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
I D F = l o g ( 语料库的文档总数 包含该词的文档数 + 1 ) IDF = log(\frac{语料库的文档总数}{包含该词的文档数+1}) \\ IDF=log(包含该词的文档数+1语料库的文档总数)
- **TF-IDF:**某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语
TF-IDF = T F × I D F \text{TF-IDF} = TF \times IDF TF-IDF=TF×IDF
举例说明
假设现在有一篇文章, 文章中包含 10000 个词组, 其中,“贵州” 出现100次,“的” 出现500次,那么我们可以计算得到这几个词的 TF(词频) 值:
T
F
(
贵州
)
=
100
/
10000
=
0.01
T
F
(
的
)
=
500
/
10000
=
0.05
TF(贵州) = 100 / 10000 = 0.01 \\ TF(的) = 500 / 10000 = 0.05
TF(贵州)=100/10000=0.01TF(的)=500/10000=0.05
现在语料库中有 1000 篇文章, 其中,包含 “贵州” 的有 99 篇, 包含 “的” 的有 899 篇, 则它们的 IDF 值计算为:
I
D
F
(
贵州
)
=
l
o
g
(
1000
/
(
99
+
1
)
)
=
1.000
I
D
F
(
的
)
=
l
o
g
(
1000
/
(
899
+
1
)
)
=
0.046
IDF(贵州) = log(1000 / (99+1)) = 1.000 \\ IDF(的) = log(1000 / (899+1)) = 0.046
IDF(贵州)=log(1000/(99+1))=1.000IDF(的)=log(1000/(899+1))=0.046
2. Tf-idf的优缺点
- 优点:简单快速,而且容易理解。
- 缺点:有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。