map的结构
map实现的两个关键数据结构
- hmap 定义了map的结构
- bmap 定义了hmap.buckets中每个bucket的结构
// A header for a Go map.
type hmap struct {
count int // 元素的个数
flags uint8 // 状态标记,标记map当前状态,是否正在写入
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子
noverflow uint16 // 溢出的个数
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 桶的地址
oldbuckets unsafe.Pointer // 旧桶的地址,用于扩容
nevacuate uintptr // 迁移进度,小于nevacuate的已经迁移完成
extra *mapextra // optional fields
}
// A bucket for a Go map.
type bmap struct {
//每个元素hash值的高8位,如果tophash[0] < minTopHash,表示这个桶的搬迁状态
tophash [bucketCnt]uint8
// 接下来是8个key、8个value,但是我们不能直接看到;为了优化对齐,go采用了key放在一起,value放在一起的存储方式,
// 再接下来是hash冲突发生时,下一个溢出桶的地址
}
//上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype由编译器编译时候确定
values [8]elemtype
// elemtype由编译器编译时候确定
overflow uintptr
//overflow的下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
名词解释
负载因子
负载因子是衡量hash表中当前空间占用率的指标。在go中,就是平均每个bucket存储的元素个数。
- 计算公式如下:
LoadFactor(负载因子)= hash表中已存储的键值对的总数量/hash桶的个数(即hmap结构中buckets数组的个数)在各语言的实现中,都会确定一个负载因子的阈值,当负载因子超过这个阈值时,就要进行扩容,以平衡存储空间和查找元素时的性能。根据golang团队的测试数据,将负载因子定为了6.5,即平均每个bucket保存的元素≥6.5个时会触发扩容。
B
bucket个数为:2^B; 可以保存的元素数量是 负载因子 * 2^B。
data := make(map[int]int,17)
根据计算公式
初始元素个数 ≤ 2^B * 6.5
17 ≤ 2^2 * 6.5
可以计算出B为2,初始的桶的个数为4
其中:
B<4时,根据B创建桶的个数的规则为:2^B(标准桶)
B>=4时,根据B创建桶的个数的规则为:2^B + 2^(B-4) (标准桶+溢出桶)
tophash
tophash是一个长度为8的数组,它不仅仅用来存放key的哈希高8位,在不同场景下它还可以标记迁移状态,bucket是否为空等。弄懂tophash对我们深入了解map实现非常重要。
当tophash对应的K/V被使用时,存的是key的哈希值的高8位;当tophash对应的K/V未被使用时,存的是K/V对应位置的状态。
emptyRest = 0
emptyOne = 1
evacuatedX = 2
evacuatedY = 3
evacuatedEmpty = 4
minTopHash = 5
当tophash[i] < 5时,表示存的是状态;
当tophash[i] >= 5时,表示存的是哈希值;
当计算的哈希值小于minTopHash时,会直接在原有哈希值基础上加上minTopHash,确保哈希值一定大于minTopHash。
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
return top
}
emptyRest
这个值有两层意思:一是表示该tophash对应的K/V位置是可用的;二是表示该位置后面的K/V位置都是可用的。
赋值:
初始化的时,tophash会被置为emptyRest。
删除map元素时,会判断是否需要把删除key对应的tophash置为emptyRest。
作用:
判断bucket是否为空
当tophash[0]==emptyRest表示整个bucket都是空的,这就是源码里面判断bucket是否为空的方法。
查找时快速判断后面位置是否还需遍历
如在查找时,在一个bucket中,找到tophash[2]位置,发现值为emptyRest,就可以判断该bucket没有该元素,继续查找下一个bucket。
emptyOne
仅表示该tophash对应的K/V位置是可用的,其后面的是否可用不知道。
赋值:
删除map元素时,会把key对应的tophash先置为emptyOne,再继续判断是否需要置为emptyRest。
evacuatedX && evacuatedY
这两个状态与扩容有关,记录元素被迁移到了新桶的部位–X或Y。如果是等位迁移,旧桶的元素必然被迁移到X部;如果是扩容迁移,旧桶元素可能迁移到X部,也可能迁移到Y部。当迁移到X部时,旧桶tophash置为evacuatedX;当迁移到Y部时,旧桶tophash置为evacuatedY。
举个例子说明:扩容迁移,要把旧桶1的元素迁到新桶,因为新桶长度增长了一倍,因此旧桶1元素可能被迁移到新桶的1或5。当元素迁移到了1时,把旧桶tophash置为evacuatedX;反之,迁移到了5时,tophash置为evacuatedY。要注意置的是旧桶的tophash。
旧桶迁移完就被回收了,为啥还要记录每个元素迁移的位置?
想了解原因,我们必须要考虑一个很复杂的场景:遍历map时,开始扩容。map遍历并不是原子操作,在遍历过程中会有数据插入、删除等,会导致map扩容。因为遍历发生在扩容前,因此一直是遍历老桶。这时有两种情况:老桶数据没有迁移,这时直接从老桶返回K/V就可以了;老桶数据已经迁移,这时就需要重新查找map。那怎么判断老桶数据是否迁移?这时就用到evacuatedX和evacuatedY,这两个就是用来标记老桶数据迁移状态的。
evacuatedEmpty
用于表示此单元已迁移
创建map
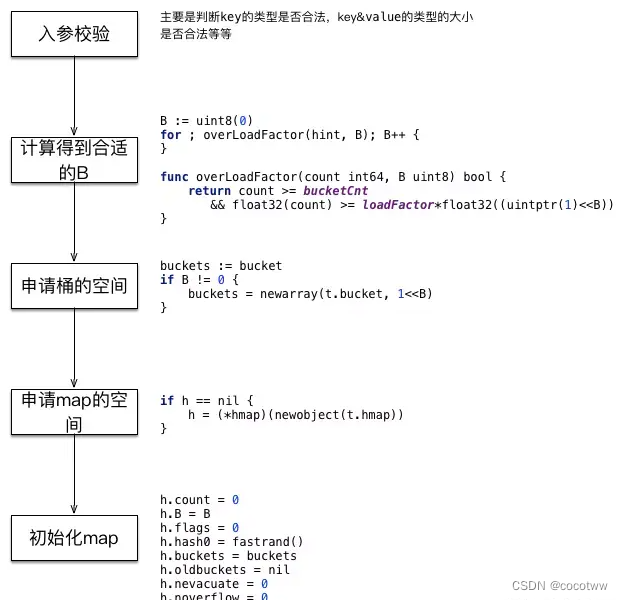
func makemap_small() *hmap
func makemap(t *maptype, hint int, h *hmap) *hmap
func makemap64(t *maptype, hint int64, h *hmap) *hmap // hint类型为int64, 实质还是调用的 makemap
当创建map时不指定hint大小,那么调用makemap_small来进行创建 当指定了hint(代表初始化时可以保存的元素的个数)的大小的时候,若hint<=8, 使用makemap_small进行创建map,否则使用makemap创建map
map查找
Go map会在编译阶段转换成runtime包中的hmap。其中,bmap指向存储key-value的结构(数组)。数组元素为“桶”,每个桶中包含高8位的hash和相应的8个key-value,高8位hash用来快速找到目标key,其次是8个key,8个value(key和value分开存储,是为了防止key存储空间大于value时,value会自动占用key大小的空间,这样做可以减少空间的浪费),最后是指向溢出桶的指针(解决哈希冲突)。hash 表通过 hash 值的低几位(原理是对数组长度取余,但通常采用与运算来加速)去查找 hash 桶,然后在去查找到的 hash 桶中查找高8位的hash,快速锁定key,知道key,就可以获取其value了。如果遇到哈希冲突,即不同key产生的hash值一样,如此就需要额外进行key值的比较,这就要求存储的key值是可以比较相等的,
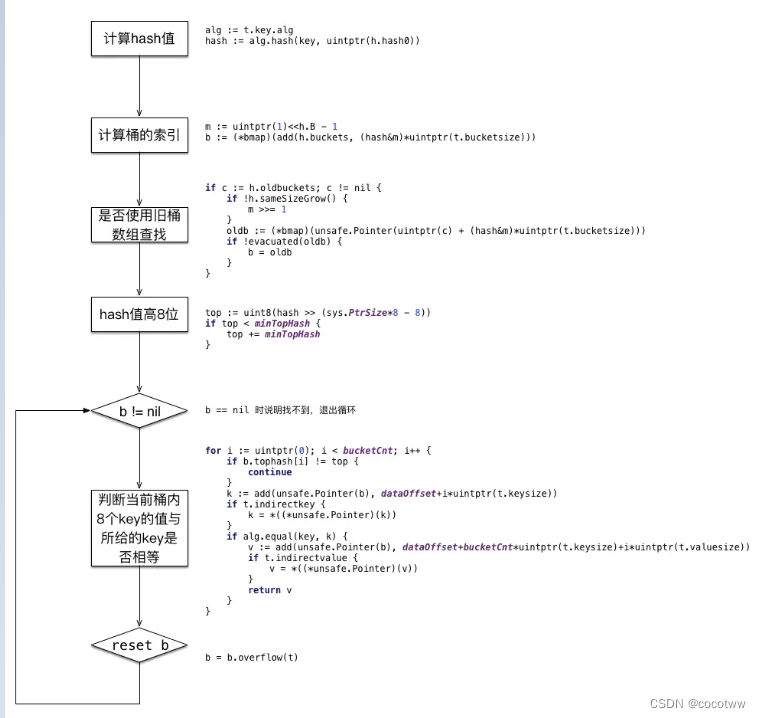
Go map扩容,数据迁移不是一次性迁移,而是等到访问到具体某个bucket时才将数据从旧bucket中迁移到新bucket中
- 一次性迁移会涉及到cpu资源和内存资源的占用,在数据量较大时,会有较大的延时,影响正常业务逻辑。因此Go采用渐进式的数据迁移,每次最多迁移两个bucket的数据到新的buckets中(一个是当前访问key所在的bucket,然后再多迁移一个bucket)
- cpu资源:扩容时需要迁移map中oldbuckets的元素,其中的rehash操作会消耗cpu的计算资源,有可能会影响到用户协程的调度
map插入/删除
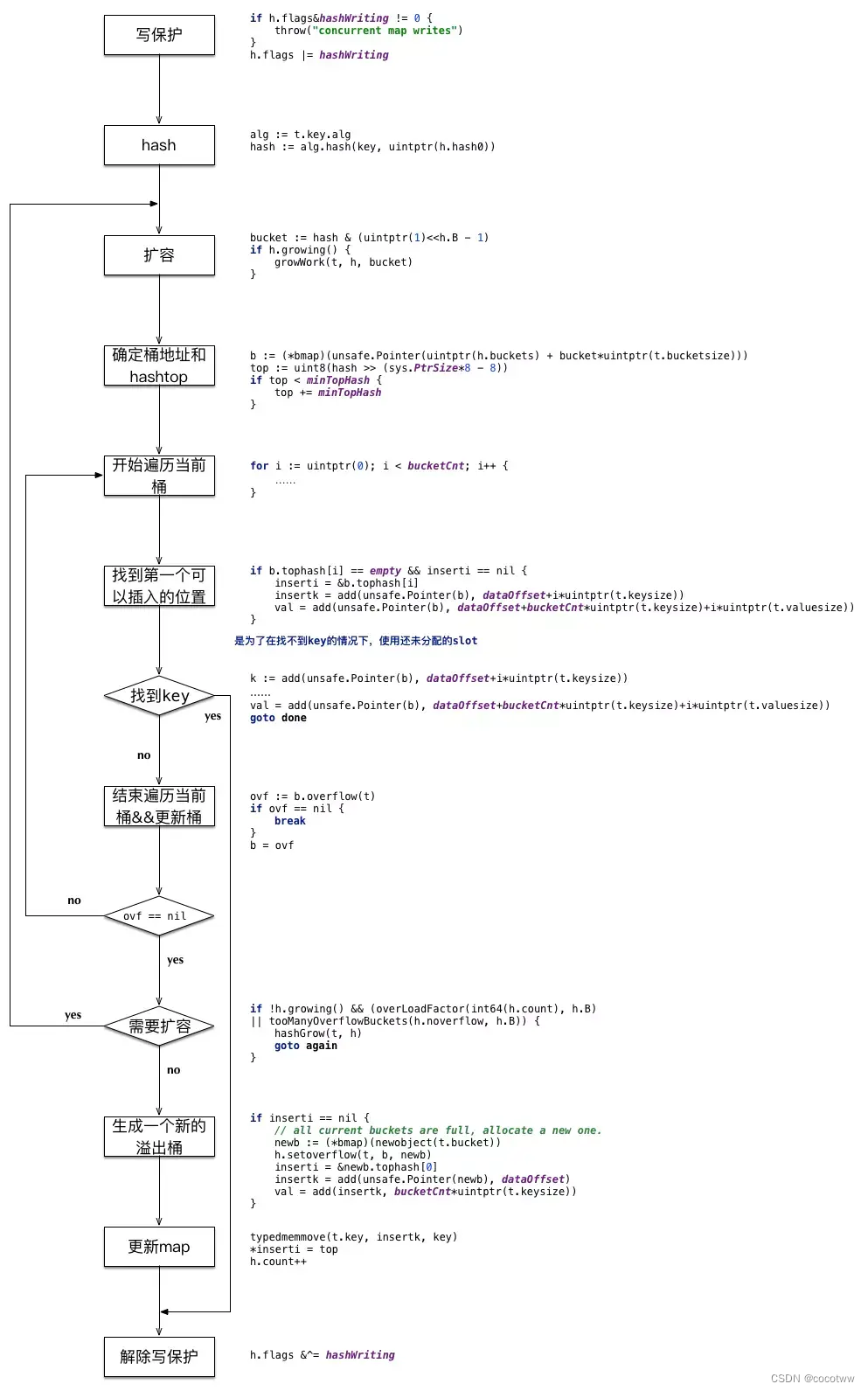
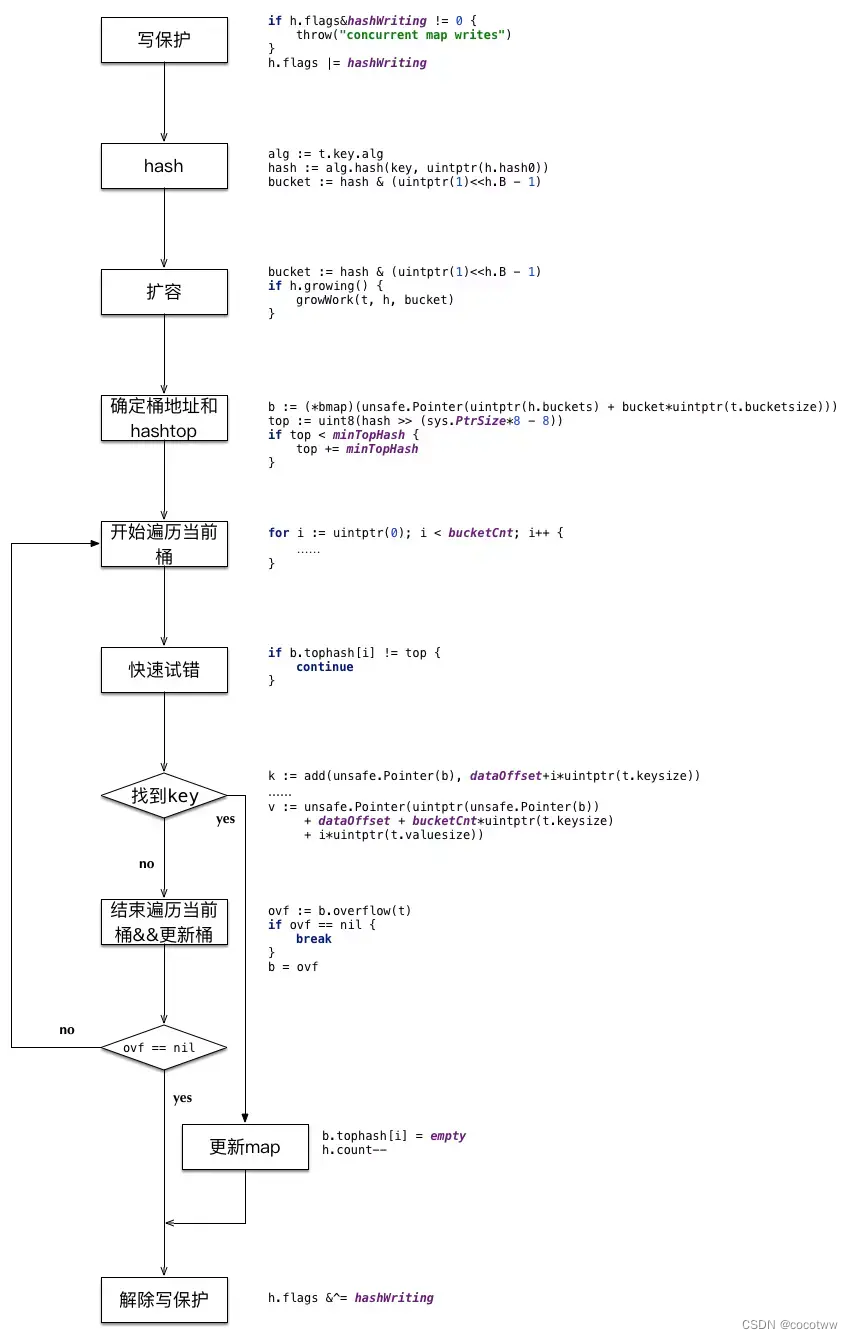
扩容的条件:
1. 超过负载 map元素个数>6.5*桶个数
func overLoadFactor(count int, B uint8) bool{
return count > bucketCnt && uintptr(count)>loadFactor*bucketShift(B)
}
其中
bucketCnt=8,一个桶可以装的最大元素个数
loadFactor=6.5,负载因子,平均每个桶的元素个数
bucketShift(8), 桶的个数
2. 溢出桶太多
当桶总数<2^15时,如果溢出桶总数>=桶总数,则认为溢出桶过多
当桶总数>=2^15时,直接与2^15比较,当溢出桶总数>=2^15时,即认为溢出桶太多了
扩容机制:
1.双倍扩容:针对条件1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧的buckets数据
搬迁到新的buckets
2.等量扩容:针对条件2,并不扩大容量,buckets数量维持不变,重新做一遍类似双倍扩容的搬迁操作,
把松散的键值对重新排列一次,使得同一个bucket中的key排列地更紧密,节省空间,提高buckets利用
率,进而保证更快的存取。该方法我们称之为等量扩容。
扩容过程:
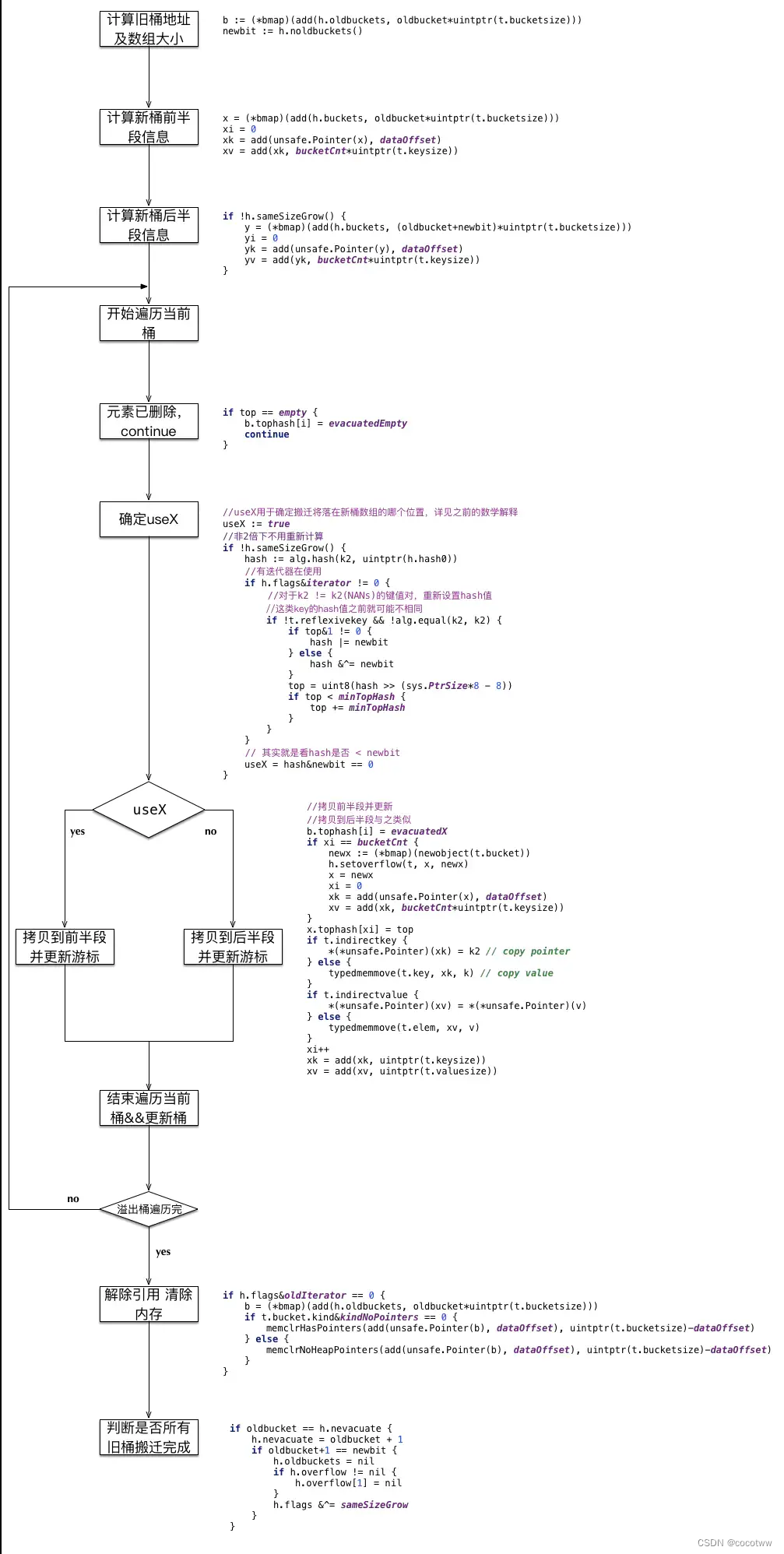
假设旧桶数组大小为2^B, 新桶数组大小为2*2^B,对于某个hash值X
若 X & (2^B) == 0,说明 X < 2^B,那么它将落入与旧桶集合相同的索引xi中;
否则,它将落入xi + 2^B中