目录
1.概述
2.数据模型
3.API
4.架构
5.一个完整的读写过程
6.如何查找到要的tablet
7.LSM树
1.概述
本文是作者阅读完bigtable论文后对bigtable进行的一个梳理,只涉及核心概念不涉及具体实操,具体实操会在后续的文章中推出。
GFS的出现虽然解决了海量数据的存储问题,但是还是存在一个问题就是如果我存放的数据是结构化的,对结构化数据的使用往往是希望如关系型数据库一样,进行复杂的数据操作的。但是GFS并没有支持基于特定属性(如行键、列名、时间戳)的高效查询、更新、聚合等操作。自然就需要大数据版本的关系型数据库,这就是分布式数据库。
BigTable 是由 Google 开发的一款分布式数据存储系统,专为管理大规模结构化数据而设计,同GFS一样,bigtable是基于Google的具体业务需求而诞生的。
Google最核心的搜索业务,其会用爬虫的方式在整个互联网上爬取网页的信息然后存储起来供搜索引擎使用,也就是要存储海量的web索引。除此之外,Google还有Google Maps(地图)、Gmail(邮件)等应用也需要对海量结构化数据进行高效的查询、更新、聚合等操作。
bigtable基于GFS而来的,底层是用的GFS来进行数据存储。
BigTable 最初的概念和技术细节在 2006 年由 Google 研究人员发表的一篇同名论文《Bigtable: A Distributed Storage System for Structured Data》中公开。这篇论文详细阐述了 BigTable 的设计理念、数据模型、架构和实现细节,对后续的大数据存储技术产生了深远影响。
前面已经说过了bigtable在业务场景中要满足的需求,所以其设计目标总结起来无非就是:
-
能扛住海量数据
-
能灵活进行数据操作(增删改查)
能抗住海量数据:
能抗住海量数据无非就要办成两件事:
-
是能存海量数据
-
能高效的对海量数据进行读写
要存海量数据自然要有良好的伸缩性,能轻松的进行节点扩展,能支持TB甚至PB级别的数据存储,要有高可靠性,要进行高性能的海量数据的读写其实就要能进行并发的读写。这些要求谁能满足?GFS就能满足,所以bigtable底层就是用GFS来存储数据的。
能灵活进行数据操作:
能对海量数据进行灵活的操作(增删改查)是bigtable的核心诉求。由于海量数据其实是交给GFS来扛的,所以前面的一点bigtable其实是不需要关心的,它要关心的是怎样用一个中间层来在GFS上面实现对数据进行灵活操作。在这个中间层里bigtable用了一套巧妙的数据组织逻辑来进行数据管理,从而实现了核心诉求。
bigtable采用一种基于行键(row key)、列族(column family)和时间戳(timestamp)的多维数据模型,允许用户以高效、灵活的方式组织和访问数据。
2.数据模型
bigtable中一条数据的数据模型(格式)如下:
(row:string,column:string,time:int64)->string

这样设计数据模型,将整行打散为单列,是为了实现数据的灵活操作,bigtable的核心诉求本来就是为了尽量实现数据的灵活操作,这样打散可以在更新的时候避免操作整个行(行数据还是蛮大的,毕竟在大数据的业务场景下逻辑表基本都是大表),而是精确的操作单个列,性能更好。
举个谷歌的业务场景的例子:
爬虫会爬回来的web索引以供搜索引擎使用,这些web索引对应的内容里,可能会经常变的也就是网站的首页,其它很少会变,精确的更新就显得很有价值了。
那么为什么会有时间戳喃?因为Google面对的业务数据大量都是有时序概念的,如爬虫爬回来的web索引,网页的内容是会随着时间改变的,除此之外地图邮件等数据也是有时序属性的。
以CSDN首页为例:
row:作者名
column:头像、简介、文章列表、个人成就等

如果我的主页简介改变了,就只需要新加新的简介的那一个KV对,那对新的KV对生成新的时间序列即可。
3.API
由于数据是分布式存储的,所以其实bigtable还是没办法办到像SQL一样灵活的对数据进行操作,其只能尽力的在GFS之上封装出一套完整的增删改查操作。bigtable支持以下类型的API:
-
建表、删表
-
单行数据的增删查,以及用删除和增加组合出来的修改效果,只对单行数据的增删具有ACID特性。
-
范围查询
4.架构
bigtable架构中最核心的概念是tablet。存放tablet的节点在bigtable体系中叫做tablet server,一个tablet server中存放多个tablet。
bigtable在最底层把数据按照key进行排列后,进行分区,一个分区就是一个tablet,而一个tablet就是GFS中的一个文件。

tablet只是一个逻辑概念,并不直接存储数据,只是指代特定范围内的数据行。真正干活儿的是memtable和sstable以及下面的GFS。memtable是缓存,一个tablet对应着一个memtable,其中记录着当前节点的tablet中的所有数据(key值+数据指针)。为了容错和可靠,memtable每隔一段时间或者到了一定的阈值后会落磁盘进行持久化,持久化为SSTable,一个tablet存在多个SSTable,这样设计的目的是省去了新老sstable合并带来的额外磁盘IO拉低吞吐量,也可以起到数据版本记录的目的。
所以tablet server我们可以理解为长这个样子:

memtable和sstable中存放的什么内容:数据的key+数据存在 GFS 的哪个 DataNode 上
各个tablet server各自管理着一部分tablet信息,所以还需要一个全局的协调者(master节点)来负责记录下全局的:
哪些key在哪个tablet中,以及哪些tablet在哪些节点上。
所以综上所述整个bigtable的架构图如下:

最后这里问出一个核心的问题:
为什么要设计出tablet的概念喃?
这是因为在关系型数据库中数据量是没那么大的,在管理粒度上细到单个数据上是没什么问题的。因为当我们想用树形结构来进行查找上的性能优化的时候(索引)倒是没什么问题(B+树完全扛得住),但是在大数据系统中动辄上TB和PB的数据量级,仍然细到单个数据上这棵树形结构该有多深?多大?所以是扛不住的,最佳的方式当然是先用tablet来“分块”一下,树形结构直接管理到tablet层面即可,tablet内部再来进行自我的数据组织(内部再维护一种树形结构),这样就扛得住了,树也不会太深。
5.一个完整的读写过程
读取过程:
-
客户端发起读请求: 客户端应用程序指定要读取的表名、行键(Row Key)以及(可选的)列族(Column Family)、列限定符(Qualifier)、时间戳范围等参数,构造一个读请求。
-
查找 Tablet 位置: 客户端将读请求发送给 Bigtable 的 Master 节点。 Master 节点根据行键在 Tablet 分布图中查找对应的 Tablet 信息(包括 Tablet ID 和负责的 Tablet Server 地址)。
-
转发读请求: Master 节点将查找到的 Tablet 位置信息返回给客户端。 客户端直接将读请求发送给对应的 Tablet Server。
-
Tablet Server 处理读请求: Tablet Server 接收到读请求后,根据请求参数在本地存储的 SSTable 文件和 Memtable 中查找数据。 若数据存在于 SSTable 文件: Tablet Server 通过 GFS API 查询 SSTable 文件的元数据,获取其内部数据块(chunk)在 GFS 集群中的分布信息。 根据数据块位置信息,通过 GFS API 从相应的 DataNode 读取所需数据块内容。 将读取到的数据块内容拼接成完整的数据项,返回给客户端。 如果数据存在于多个版本(不同时间戳),按需选择合适的版本返回。 如果数据跨越多个 SSTable 或 Memtable,可能需要进行多版本合并或筛选。
-
响应客户端: Tablet Server 将查询结果打包成响应消息,发送回客户端。 客户端接收到响应后,解析并使用读取到的数据。
写入过程:
-
客户端发起写请求: 客户端应用程序指定要写入的表名、行键、列族、列限定符以及值(Cell Value)和时间戳(默认为当前时间),构造一个写请求
-
查找 Tablet 位置: 类似于读取过程,客户端首先将写请求发送给 Master 节点。 Master 节点查找对应的 Tablet 信息并返回给客户端。
-
转发写请求: 客户端直接将写请求发送给对应的 Tablet Server。
-
Tablet Server 处理写请求: Tablet Server 接收到写请求后,将其写入内存中的 Memtable。 Memtable 刷写到 SSTable: 当 Memtable 达到一定大小或达到其他触发条件,Tablet Server 会触发 Memtable 刷写到本地磁盘,生成新的 SSTable 文件。 生成 SSTable 文件: Tablet Server 通过 GFS API 创建一个新的 SSTable 文件,并写入文件头、索引等元数据。 将 Memtable 中的数据按需排序,并组织成 SSTable 文件格式的数据块。 分散存储数据块: 将 SSTable 文件内部数据块(chunk)分散存储在 GFS 集群中: Tablet Server 通过 GFS API 将 SSTable 文件的数据块上传到 GFS 集群中的多个 DataNode。 GFS 根据其数据分布策略(如复制因子)自动将数据块复制到其他 DataNode,确保数据冗余和高可用。
-
响应客户端: Tablet Server 完成写入操作后,向客户端发送确认消息,表示写入成功。
6.如何查找到要的tablet
在上一章节(第5章节)中我们大致聊了聊bigtable一次完整的读写过程,整个过程聊的粒度比较粗,这里面值得我们展开聊一聊的是在读写的时候如何准确的找到要的tablet。我们在读写的时候都是持有key值然后进来找其对应的tablet。这个找的过程是顺序遍历吗?肯定不是,大数据系统里面数据量这么多,顺序遍历性能肯定扛不住,所以在master上是维护着一个类树型的层级结构的:
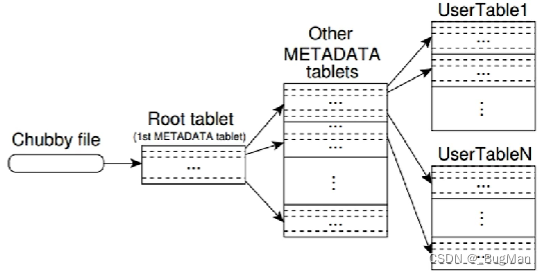
树形结构与排列顺序:
-
根节点:Root Tablet: 作为树的根节点,root tablet 是整个元数据层次结构的起始点。 它固定存储在一个已知的位置,如高度可靠的分布式锁服务(如 Chubby)中。
-
中间节点:Metadata Tablets: 除 root tablet 外的 metadata tablets 可以看作是树的中间节点。 这些节点按照某种规则(如基于 tablet 行键范围的划分)组织成多层结构,形成一个分层的索引系统。 每个中间节点(metadata tablet)负责存储其子节点(通常是更低层级的 metadata tablets 或 user table tablets)的位置信息。
-
叶子节点:User Table Tablets: User table tablets 作为树的叶子节点,代表实际存储用户数据的tablet。 它们没有进一步的子节点,每个叶子节点直接关联到一个具体的 user table tablet,包含其行键范围和 TabletServer 地址。
Metadata Tablet可以理解为专门用来在这个类树形结构里维护这个类树形结构的,用来维护好真正负责数据存储的user tablet在整个类树形结构中所处位置,便于进行高效的读写。
层级遍历:
-
从根出发: 客户端首先访问 root tablet,获取到第一级 metadata tablets 的位置信息。
-
逐层深入: 对于每一级 metadata tablets,客户端按照某种顺序(如行键范围的字典序)遍历它们,查询其中存储的子节点(下一级 metadata tablets 或 user table tablets)的位置信息。 如果子节点是 user table tablets,则定位完成;如果子节点是下一级 metadata tablets,则继续深入下一层进行遍历。
-
定位目标: 在遍历过程中,客户端根据待查询或写入的行键,判断其所属的行键范围是否与当前遍历到的 tablet 匹配。 当找到包含目标行键范围的 user table tablet 时,遍历结束,此时客户端已经确定了目标tablet的位置。
7.LSM树
这里留个尾巴,前面一个章节我们说了在找具体的tablet的时候为了查找效率会维护着一个类树形的结构,那么作为直接负责数据存储的user tablet,其内部在进行数据查找的时候肯定也不是通过顺序遍历来实现的,也是有一定的数据结构来保证查找效率的,这就是LSM树,下一篇文章我们将聊一聊LSM树。