【背景说明】
我需要用flume将kafka上的数据采集到hdfs上,发现数据怎么到不了hdfs。
【问题排查】
1.kafka上已有相应的数据
2.我的flume配置文档(没问题),
3.时间拦截器(没问题),
4.JSONObject.class(flume/lib中也已经导入),
5.f3也能正常启动
这是我的flume配置文档:
vim kafka_to_hdfs_db.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimestampAndTableNameInterceptor$Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
【原因】
最后发现是我的taildir_position.json之前在/opt/module/flume/jobs/collectionProject路径下(不对),导致flume读不到这个文件的位置,所以无法从kafka将数据读到hdfs
【解决】
将这个文件移动到/opt/module/flume的路径下:
[atguigu@hadoop102 collectionProject]$ mv taildir_position.json /opt/module/flume
再次启动flume
[atguigu@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f jobs/collectionProject/kafka_to_hdfs_db.conf
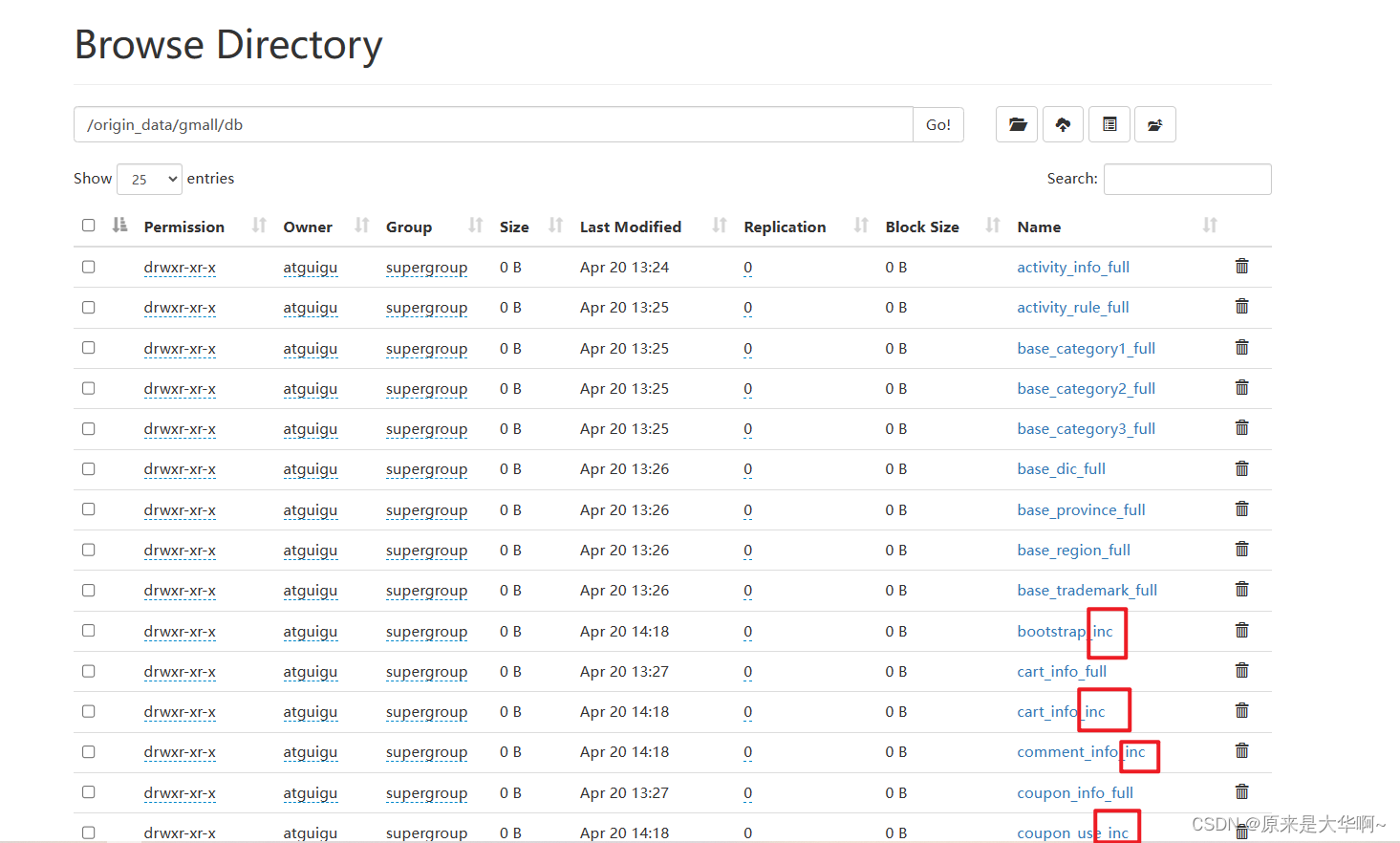
MySQL数据库的增量数据已从kafka成功同步到hdfs~