目录
- 1.TensorRT的高性能部署简介
- 2.TensorRT驾驭方案
- 3.如何正确导出onnx
- 4.动态batch和动态宽高的实现
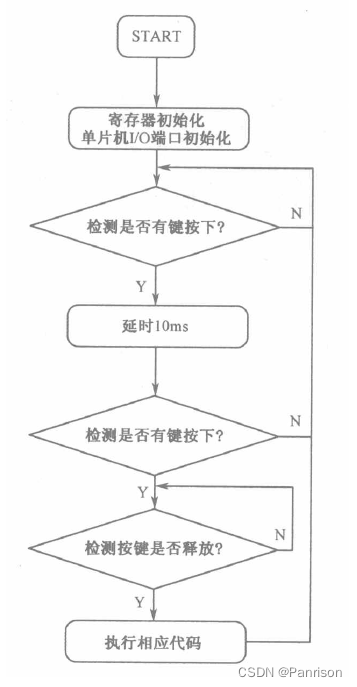
- 5.实现一个自定义插件
- 6.关于封装
- 7.YoloV5案例
- 8.Retinaface案例
- 9.高性能低耦合
- 10.YOLOX集成
- 参考
1.TensorRT的高性能部署简介
tensorRT,nvidia发布的dnn推理引擎,是针对nvidia系列硬件进行优化加速,实现最大程度的利用GPU资源,提升推理性能
tensorRT是业内nvidia系列产品部署落地时的最佳选择
这里主要是围绕https://github.com/shouxieai/learning-cuda-trt
https://github.com/shouxieai/tensorRT_cpp提供的方案开展讨论,使得能够使用、部署起来。
2.TensorRT驾驭方案
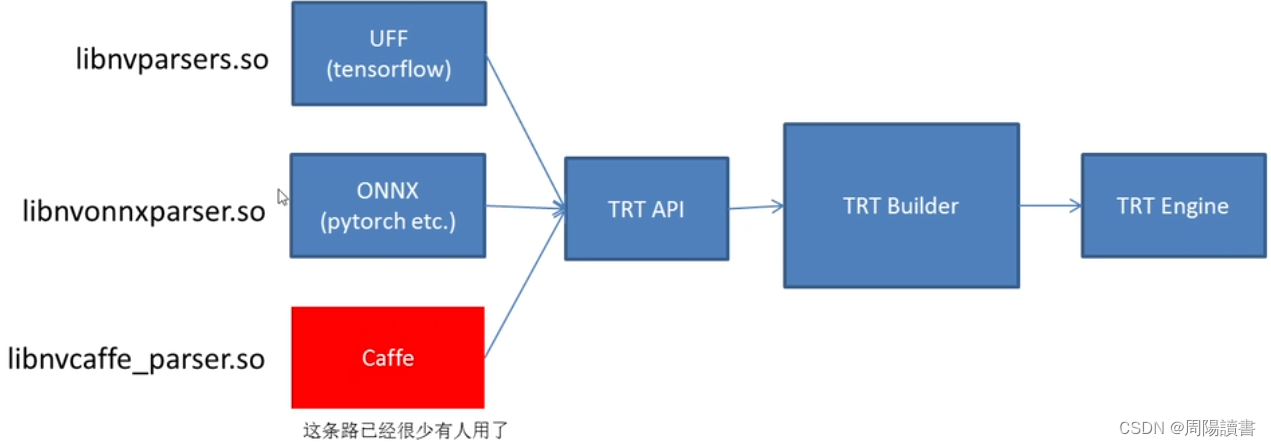




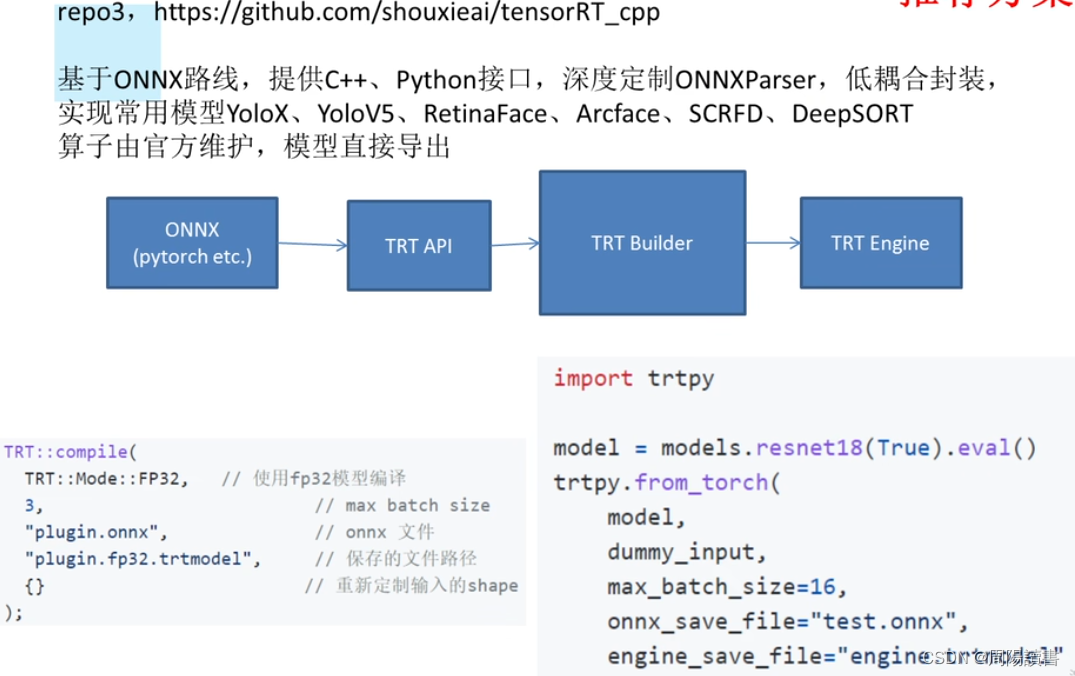

3.如何正确导出onnx


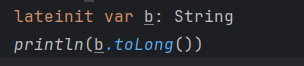
例如,原始
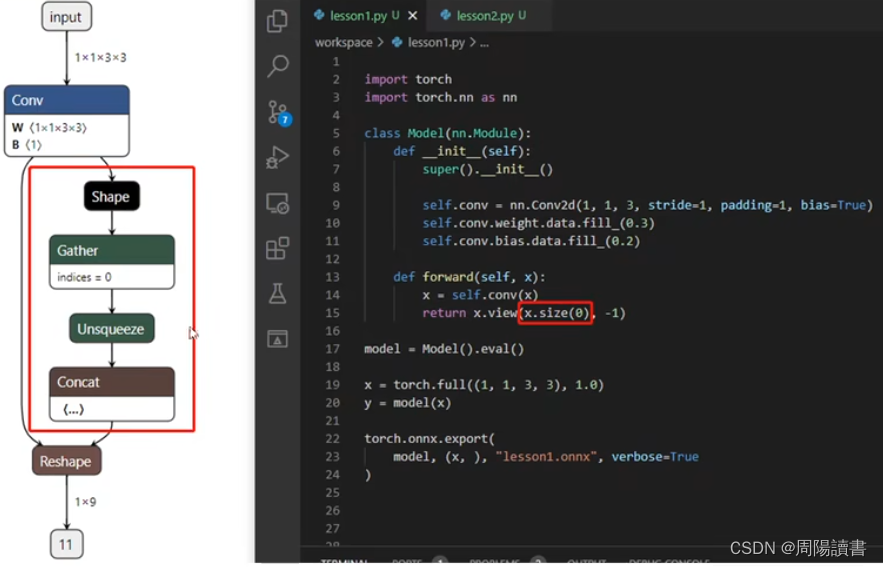
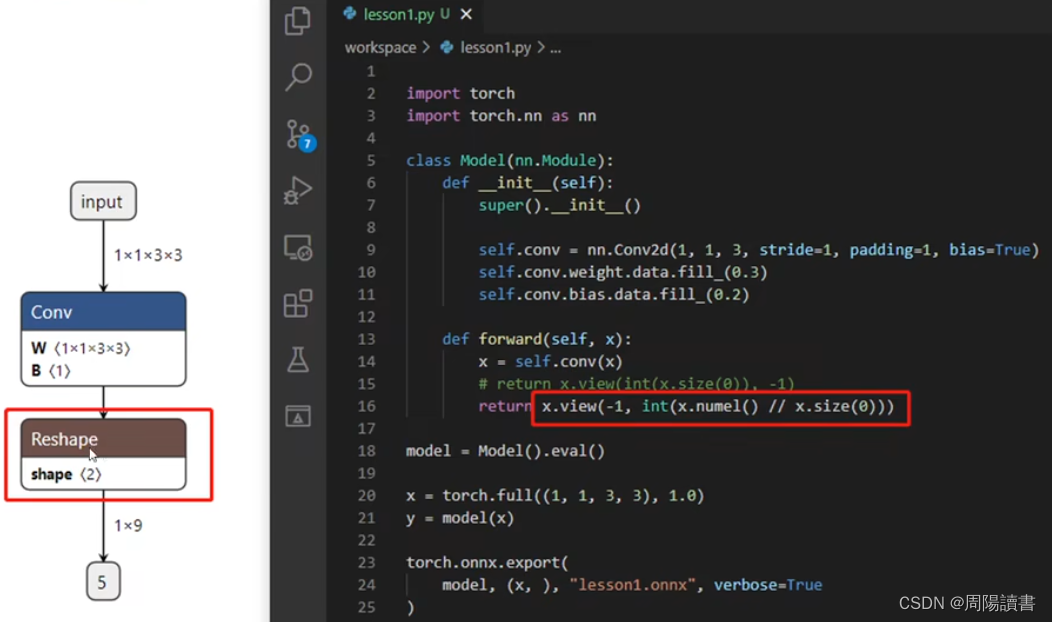
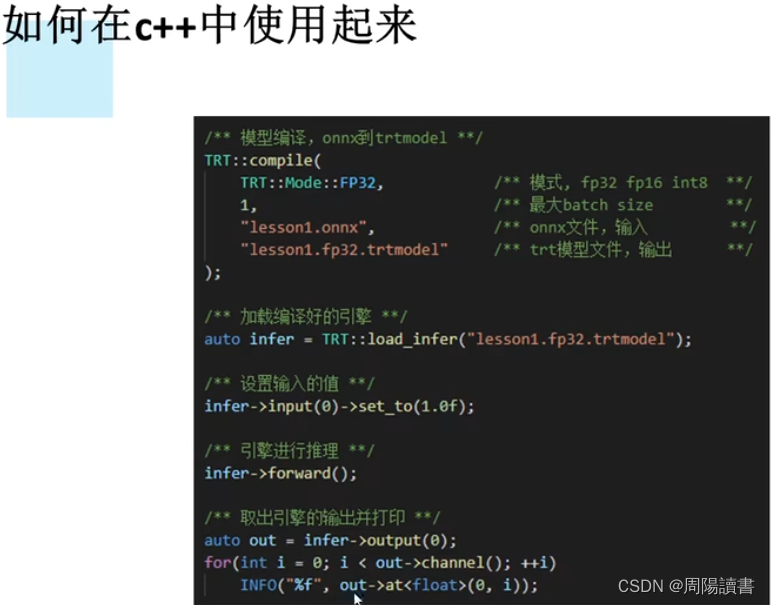
4.动态batch和动态宽高的实现


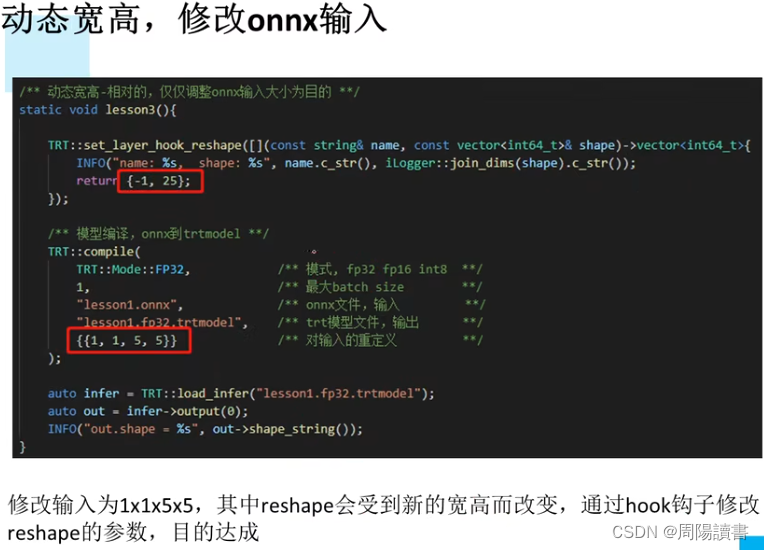
5.实现一个自定义插件
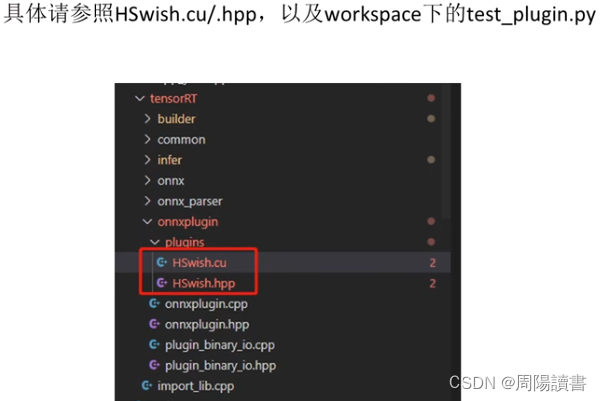

6.关于封装
 封装,关注业务逻辑,避免细节
封装,关注业务逻辑,避免细节

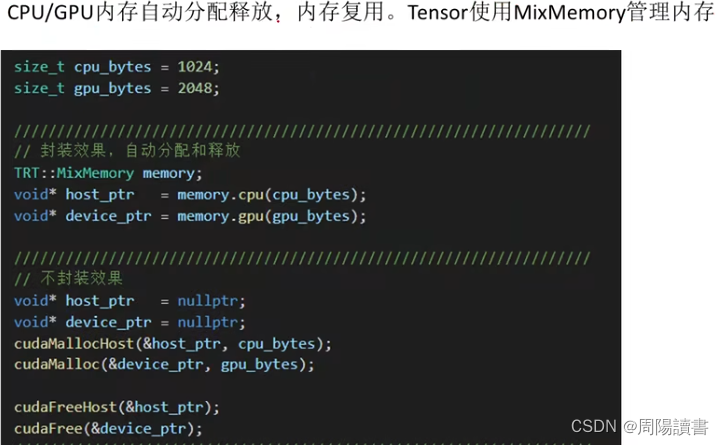
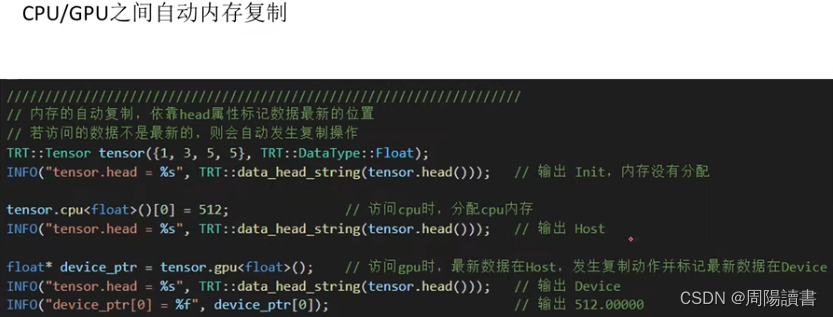
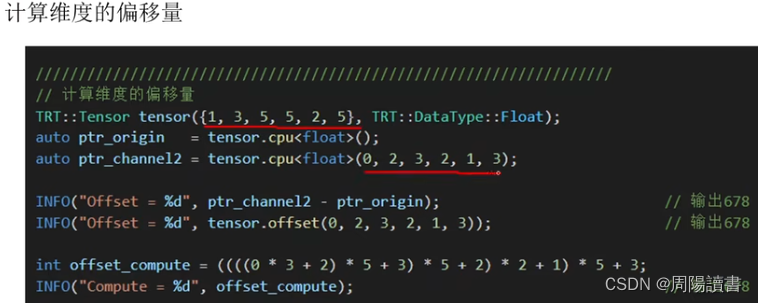

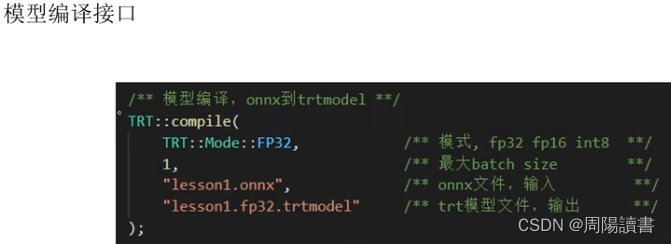
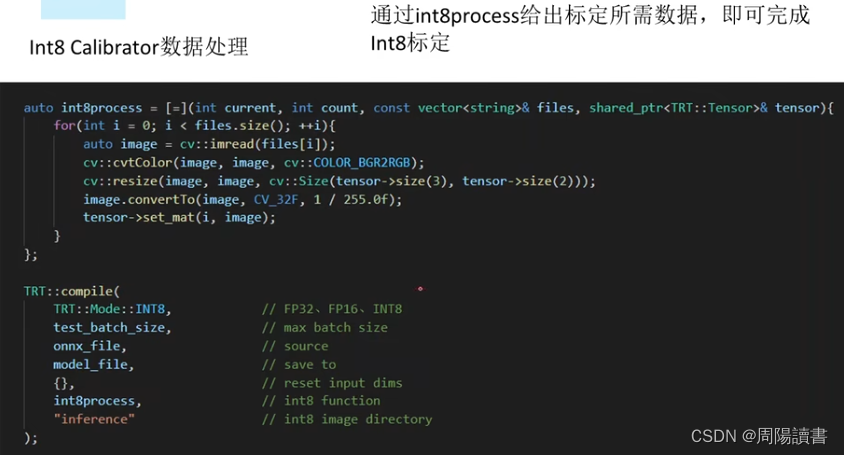
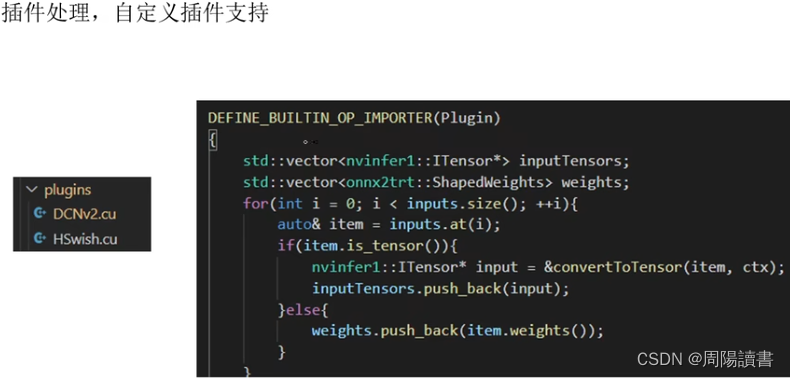
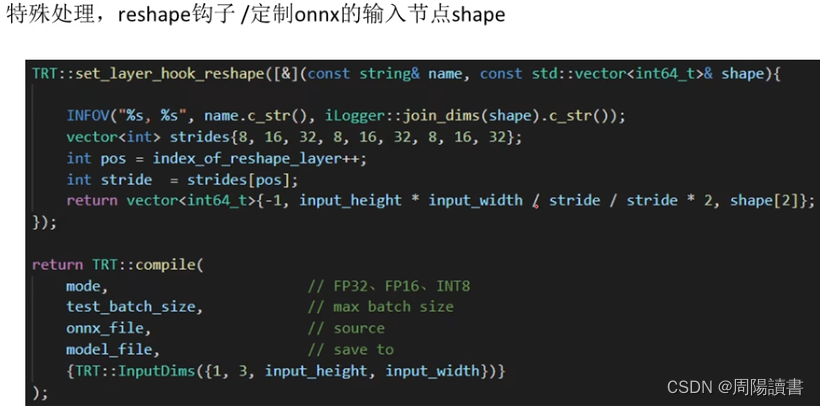
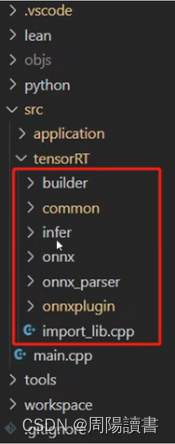
 主要是介绍该封装库代码工程,在github上,可下载下来研究
主要是介绍该封装库代码工程,在github上,可下载下来研究
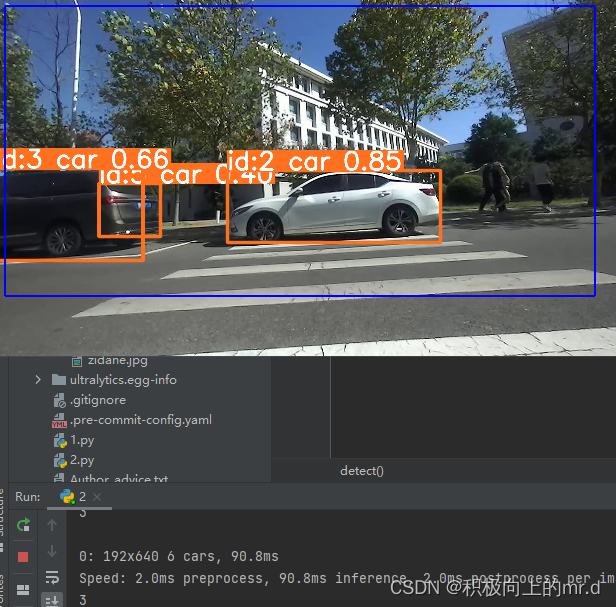
7.YoloV5案例
https://github.com/ultralytics/YOLOv5
YoloV5案例
8.Retinaface案例
https://github.com/biubug6/pytorch_Retinaface
Retinaface案例
9.高性能低耦合


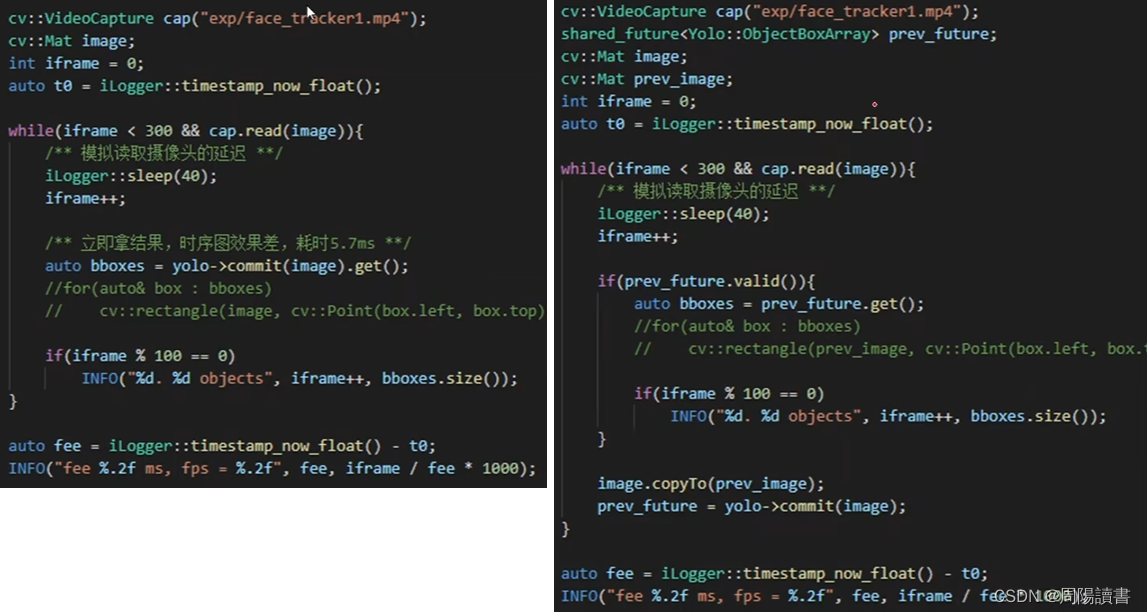

便捷性

10.YOLOX集成
参考
1.详解TensorRT的C++/Python高性能部署,实战应用到项目
2.作者博客,手写AI
zifuture.com