👀樊梓慕:个人主页
🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C++》《Linux》《算法》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
前言
1.什么是左值&&什么是右值
左值
右值
2.什么是左值引用&&什么是右值引用
左值引用
右值引用
3.左值引用与右值引用的比较
左值引用总结
右值引用总结
4.右值引用的使用场景和意义
传值返回场景分析
移动构造
移动赋值
总结
容器的插入场景分析
move的简单解释
list测试源码
string测试源码
右值被右值引用后,该右值引用是左值
那为什么这样设计呢?
5.完美转发
万能引用
完美转发保持值的属性不变
前言
今天我们正式进入C++11的学习,C++11引入的一个非常重要的语法就是右值引用,在C++11之前的C++版本我们所提的引用都是左值引用,那么右值引用与左值引用又有什么区别呢?什么是左值?什么是右值?右值引用的价值体现在哪里?以及完美转发和万能引用的相互配合?那么接下来我们就来学习有关右值引用的相关知识。
欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。
=========================================================================
GITEE相关代码:🌟樊飞 (fanfei_c) - Gitee.com🌟
=========================================================================
1.什么是左值&&什么是右值
左值
左值是一个表示数据的表达式,如变量名或解引用的指针。
- 我们可以获取左值的地址,一般情况下也可以被修改(const修饰的左值除外)。
- 左值既可以出现在赋值符号的左边,也可以出现在赋值符号的右边。
int main()
{
//以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
return 0;
}右值
右值也是一个表示数据的表达式,如字母常量、表达式的返回值、函数的返回值(不能是左值引用返回)等等。
- 不可以获取右值的地址。
- 右值可以出现在赋值符号的右边,但是『 不能』出现在赋值符号的左边。
int main()
{
double x = 1.1, y = 2.2;
//以下几个都是常见的右值
10;
x + y;
fmin(x, y);
//错误示例(右值不能出现在赋值符号的左边)
//10 = 1;
//x + y = 1;
//fmin(x, y) = 1;
return 0;
}其实右值一般都是一个临时变量或常量值,比如代码中的10就是常量值,表达式x+y和函数fmin的返回值就是临时变量,这些都叫做右值,而我们知道这些临时变量和常量值实际上并没有被存储起来,当然也就不存在地址。
//这里x是左值
int func1()
{
static int x = 0;
return x;
}
//这里x是左值
int& func2()
{
static int x = 0;
return x;
}- 当返回值没有引用标记时,返回的是临时拷贝x的一份临时变量;
- 当返回值有引用标记时,返回的是x本身(注意销毁的问题)。
2.什么是左值引用&&什么是右值引用
传统的C++语法中就有引用的语法,而C++11中新增了右值引用的语法特性,为了进行区分,于是将C++11之前的引用就叫做左值引用。但是无论左值引用还是右值引用,本质都是给对象取别名。
左值引用
左值引用就是对左值的引用,给左值取别名,通过“&”来声明。比如:
int main()
{
//以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
//以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}右值引用
右值引用就是对右值的引用,给右值取别名,通过“&&”来声明。比如:
int main()
{
double x = 1.1, y = 2.2;
//以下几个都是常见的右值
10;
x + y;
fmin(x, y);
//以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double rr3 = fmin(x, y);
return 0;
}很多人到这里就有疑惑了,引用的本质就是起别名,但是右值我们知道是没有地址的,如果一个引用可以标记在右值上,那又有什么意义呢?
是的,既然有右值引用存在,那么右值引用一定是将这个临时变量存放到了某个确定的地址上,让这个右值可以被取到地址,并且可以被修改,当然如果不想让被引用的右值被修改,可以用const修饰右值引用。比如:
int main()
{
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; //报错
return 0;
}3.左值引用与右值引用的比较
左值引用总结
- 左值引用只能引用左值,不能引用右值。
- 但是const左值引用既可引用左值,也可引用右值。
int main()
{
// 左值引用只能引用左值,不能引用右值。
int a = 10;
int& ra1 = a; // ra为a的别名
//int& ra2 = 10; // 编译失败,因为10是右值
// const左值引用既可引用左值,也可引用右值。
const int& ra3 = 10;
const int& ra4 = a;
return 0;
}右值引用总结
- 右值引用只能右值,不能引用左值。
- 但是右值引用可以move以后的左值。
int main()
{
// 右值引用只能右值,不能引用左值。
int&& r1 = 10;
// error C2440: “初始化”: 无法从“int”转换为“int &&”
// message : 无法将左值绑定到右值引用
int a = 10;
int&& r2 = a;
// 右值引用可以引用move以后的左值
int&& r3 = std::move(a);
return 0;
}4.右值引用的使用场景和意义
在探究右值引用的使用场景和意义之前,我们来回忆以下左值引用给我们带来的优点:
左值引用可以避免一些没有必要的拷贝操作,比如传参或函数返回值。
但是左值引用在修饰函数返回值时却容易出现问题,因为函数返回值是一个的局部变量,出了函数作用域就被销毁了,如果给加上了左值引用,就会导致左值引用出现问题,所以这种情况下不能使用左值引用作为返回值,只能以传值方式返回,这就是『 左值引用的短板』。
既然是右值,我们就可以使用右值引用,但是右值引用解决这里的问题是『 间接解决的』。
什么叫间接解决??
右值引用不能直接加到返回类型上直接解决么,答案当然是不能的,因为不管你给返回值加左值引用还是右值引用,都改变不了它即将被销毁的事实。
所以我们只能间接解决,怎么间接解决呢?
传值返回场景分析
移动构造
我们想要避免拷贝构造的发生,那就要设法让编译器在遇到右值引用时调用其他构造方式,这里采用的就是『 移动构造』。
而移动构造说白了就是利用swap函数将『 将亡值』与当前对象进行交换,获得『 将亡值』的数据,通过一个swap即可得到数据,不需要调用拷贝构造既节省了时间也节省了空间。
这种swap其实是一种非常危险的行为,只能适用于『 将亡值』,可以理解为是一种资源的掠夺。
将亡值:即将销毁的变量,比如返回值x这种。
增加移动构造之后,由于移动构造采用的是右值引用接收参数,因此如果拷贝构造对象时传入的是右值,那么就会调用移动构造函数(编译器最匹配原则)。
比如:
// 拷贝构造 -- 左值
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
// 移动拷贝 -- 右值(将亡值)
string(string&& s)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}给string类增加移动构造后,对于返回局部string对象的这类函数,在返回string对象时就会调用移动构造进行资源的移动,而不会再调用拷贝构造函数进行深拷贝了。比如:
F::string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
F::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return move(str);//move函数可以理解为是将左值转换成右值的
}
int main()
{
F::string s = F::to_string(1234);//调用移动构造
return 0;
}之前我们在学习类和对象部分的时候,曾经提到过编译器会对连续的构造、拷贝构造等进行优化,这部分内容需要回顾的可以戳链接->【C++】类和对象(下) ——樊梓慕

那对于移动拷贝来说,编译器也会对其进行优化:
首先在引入移动拷贝后,如果编译器不优化的过程是这样的:

但是我们之前讲过『 将亡值』,很明显str就是『 将亡值』,所以我们不需要那么小心翼翼地拷贝构造他,反正str马上就要被销毁了,我们就直接移动构造swap掠夺资源了就行了,但是str此时是左值,左值可不敢随意掠夺容易出问题,所以我们要通过move函数将str转化为右值,当然为了兼容存量代码(语言都是向下兼容的),这里编译器自动做了处理,不需要我们手动move:

参考双拷贝构造合二为一的例子,这里双移动构造编译器也进行了优化。

移动赋值
之前的场景是:
int main()
{
F::string ret = F::to_string(1234);
return 0;
}那如果是下面这种情况呢?
int main()
{
F::string ret ;
ret = F::to_string(1234);
return 0;
}很明显这里就不是构造的问题了,这里是先要拷贝构造一个临时对象,然后再用临时对象赋值给ret,所以我们需要重载赋值操作符来达到移动赋值的效果,在这个过程中需要避免深拷贝的发生。
//移动赋值
string& operator=(string&& s)
{
swap(s);
return *this;
}这样的话如果赋值时传入的是右值,那么就会调用移动赋值函数(最匹配原则)。
而且string原有的operator=函数做的是深拷贝,而移动赋值函数中只需要调用swap函数进行资源的转移,因此调用移动赋值的代价比调用原有operator=的代价小。
总结
到这里,之前我们讲左值引用无法解决的传值返回的问题被右值引用解决了,深拷贝对象传值返回只需要移动资源,代价很低。
在C++11标准出来后,所有的STL容器都增加了移动构造和移动赋值。
比如:
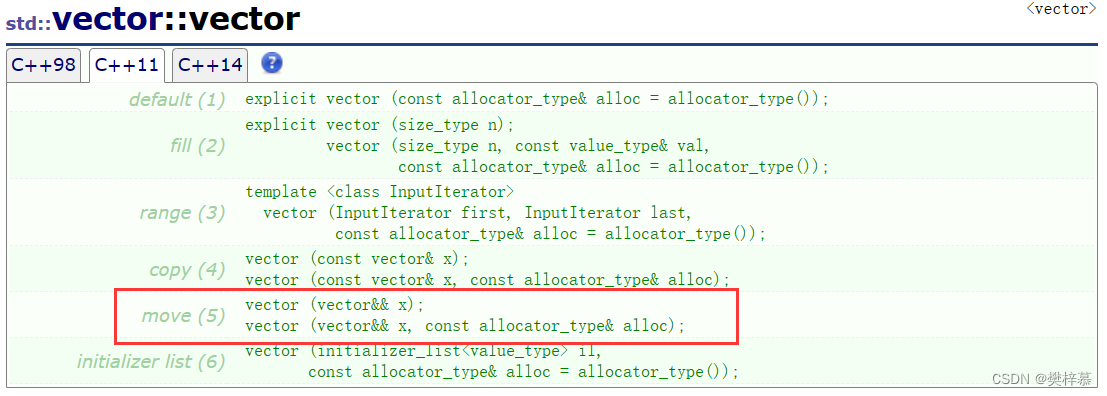

容器的插入场景分析
在C++11后,容器的插入函数提供了右值的插入方法:

也就是说当push_back的参数为右值时,会调用对应的右值插入函数。
move的简单解释
我们之前说move可以让一个对象从左值变成右值,这是不准确的。
实际上move一个对象后,该对象本身属性还是左值不会改变,只不过move这个表达式的返回值为右值。
比如:
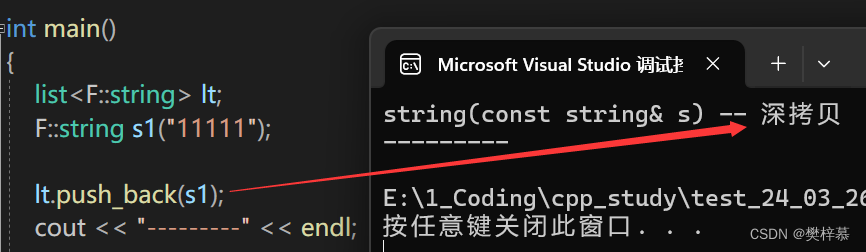
我们知道s1是左值,那传参时调用的是普通的构造深拷贝一个临时对象尾插。
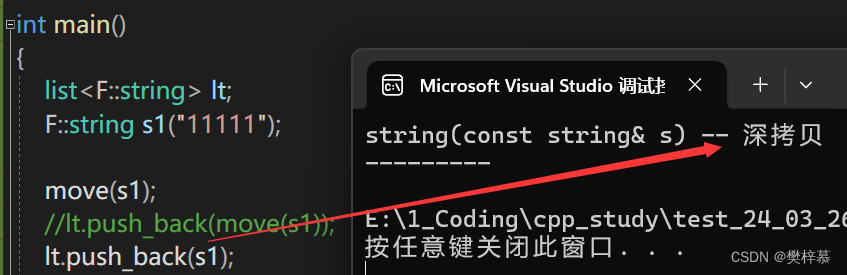
move(s1)执行完成后,调用push_back函数,构造参数仍然是深拷贝,也就是说s1仍然为左值,move不会改变s1的属性。
注意:不要轻易move左值,除非你确定要转移这个左值资源。

move(s1)这个表达式的属性为右值,所以构造参数时调用的是移动构造。
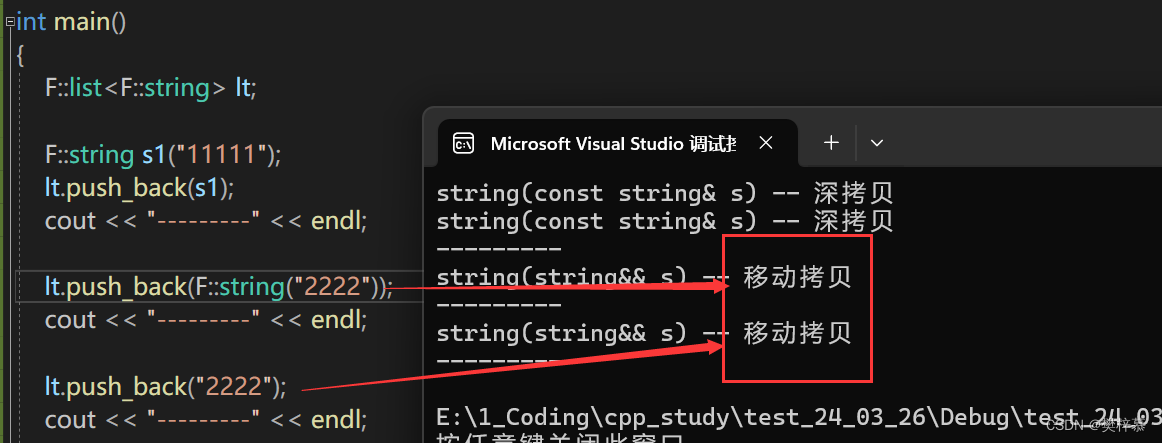
观察发现,STL库中的List在push_back时,左值传参调用拷贝构造,右值传参调用移动构造:
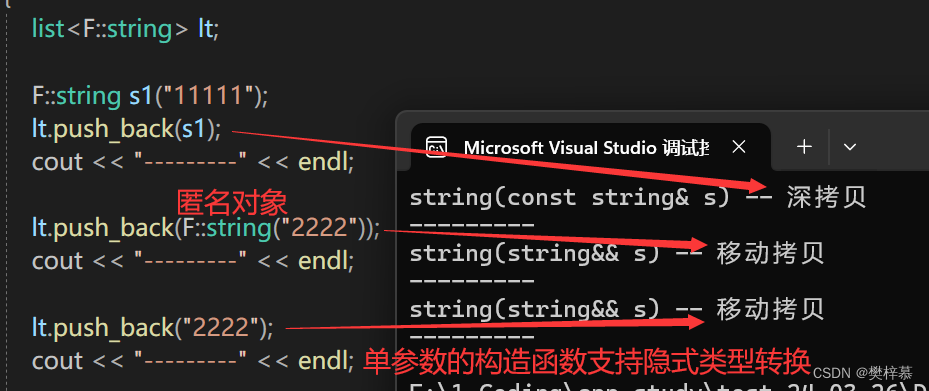
那么为了深入了解容器的插入函数是如何利用移动语义的思想来优化的,我们要自己实现一个容器list用来研究。
list测试源码
#pragma once
namespace F
{
// List的节点类
template<class T>
struct ListNode
{
ListNode<T>* _next;
ListNode<T>* _prev;
T _data;
ListNode(const T& val = T())
:_next(nullptr)
, _prev(nullptr)
, _data(val)
{}
};
//List的迭代器类
template<class T, class Ref, class Ptr>
class __list_iterator
{
public:
typedef ListNode<T> Node;
typedef __list_iterator<T, Ref, Ptr> Self;
Node* _node;
__list_iterator(Node* x)
:_node(x)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self& operator++()
{
_node = _node->_next;
return *this;
}
Self operator++(int)
{
Self tmp(*this);
_node = _node->_next;
return tmp;
}
Self& operator--()
{
_node = _node->_prev;
return *this;
}
Self& operator--(int)
{
Self tmp(*this);
_node = _node->_prev;
return tmp;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
bool operator==(const Self& s)
{
return _node == s._node;
}
};
//list类
template<class T>
class list
{
typedef ListNode<T> Node;
public:
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
///
// List Iterator
iterator begin()
{
return _head->_next;
}
iterator end()
{
return _head;
}
const_iterator begin() const
{
return _head->_next;
}
const_iterator end() const
{
return _head;
}
///
// List的构造
void empty_init()
{
_head = new Node;
_head->_next = _head;
_head->_prev = _head;
}
list()
{
empty_init();
}
list(int n, const T& value = T())
{
empty_init();
while (n--)
{
push_back(value);
}
}
list(const list<T>& l)
{
empty_init();
for (const auto& e : l)
{
push_back(e);
}
}
list<T>& operator=(list<T> l)
{
swap(l);
return *this;
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
///
// List Capacity
size_t size()const
{
size_t count = 0;
const_iterator it = begin();
while (it != end())
{
++count;
++it;
}
return count;
}
bool empty()const
{
return _head->_next == _head;
}
// List Access
T& front()
{
return *begin();
}
const T& front()const
{
return *begin();
}
T& back()
{
return *(--end());
}
const T& back()const
{
return *(--end());
}
// List Modify
void push_back(const T& val) { insert(end(), val); }
void pop_back() { erase(--end()); }
void push_front(const T& val) { insert(begin(), val); }
void pop_front() { erase(begin()); }
// 在pos位置前插入值为val的节点
iterator insert(iterator pos, const T& val)
{
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* newnode = new Node(val);
prev->_next = newnode;
newnode->_next = cur;
newnode->_prev = prev;
cur->_prev = newnode;
//return iterator(newnode);
return newnode;//单参数的构造函数支持隐式类型转换
}
// 删除pos位置的节点,返回该节点的下一个位置
iterator erase(iterator pos)
{
assert(pos != end());//list是带头双向循环链表,当pos是end()位置时,证明没有可删除的节点了
Node* cur = pos._node;
Node* prev = cur->_prev;
Node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
return next;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
void swap(list<T>& l)
{
std::swap(_head, l._head);
}
private:
Node* _head;
};
};
string测试源码
#pragma once
namespace F
{
class string
{
public:
/* string()
:_str(new char[1])
,_size(0)
,_capacity(0)
{
_str[0] = '\0';
}*/
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s2(s1)
// 传统写法
/*string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}*/
现代写法
//string(const string& s)
//{
// string tmp(s._str);
// swap(tmp);
//}
// 拷贝构造 -- 左值
string(const string& s)
:_str(nullptr)
{
cout << "string(const string& s) -- 深拷贝" << endl;
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
// 移动构造 -- 右值(将亡值)
string(string&& s)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}
// 拷贝赋值
// s2 = tmp
string& operator=(const string& s)
{
cout << "string& operator=(const string& s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
// 移动赋值
string& operator=(string&& s)
{
cout << "string& operator=(string&& s) -- 移动拷贝" << endl;
swap(s);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = 0;
_capacity = 0;
}
const char* c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
const char& operator[](size_t pos) const
{
assert(pos <= _size);
return _str[pos];
}
char& operator[](size_t pos)
{
assert(pos <= _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
void append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
void insert(size_t pos, char ch)
{
assert(pos <= _size);
if (_size == _capacity)
{
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newCapacity);
}
/*int end = _size;
while (end >= (int)pos)
{
_str[end + 1] = _str[end];
--end;
}*/
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
_size++;
}
void insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
int end = _size;
while (end >= (int)pos)
{
_str[end + len] = _str[end];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
}
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
size_t find(char ch, size_t pos = 0)
{
for (size_t i = pos; i < _size; i++)
{
if (_str[i] == ch)
{
return i;
}
}
return npos;
}
//21:10继续
size_t find(const char* str, size_t pos = 0)
{
const char* ptr = strstr(_str + pos, str);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t end = pos + len;
if (len == npos || pos + len >= _size)
{
end = _size;
}
string str;
str.reserve(end - pos);
for (size_t i = pos; i < end; i++)
{
str += _str[i];
}
return str;
}
void clear()
{
_size = 0;
_str[0] = '\0';
}
private:
size_t _capacity = 0;
size_t _size = 0;
char* _str = nullptr;
const static size_t npos = -1;
//const static double x = 1.1;
/*const static int N = 10;
int a[N];*/
};
ostream& operator<<(ostream& out, const string& s)
{
for (auto ch : s)
{
out << ch;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char buff[128];
char ch = in.get();
int i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == 127)
{
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
if (i > 0)
{
buff[i] = '\0';
s += buff;
}
return in;
};
}
右值被右值引用后,该右值引用是左值
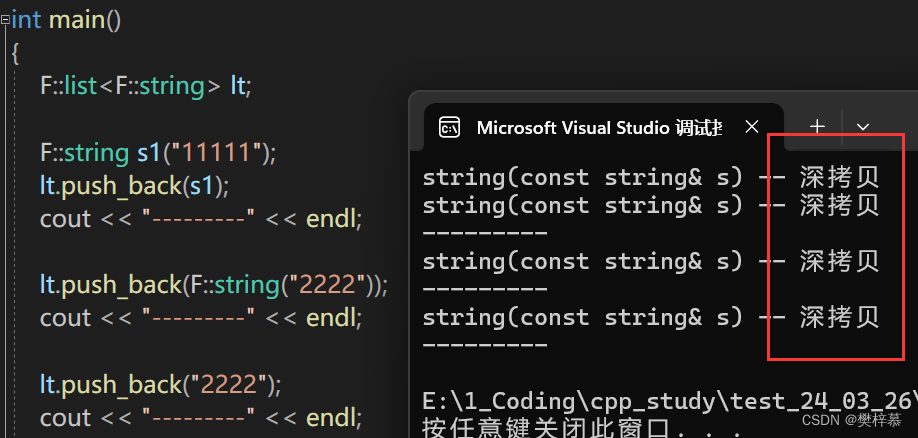
未实现右值传参时的现象:

均为拷贝构造,证明此时不管左值还是右值传参调用的构造都是普通的拷贝构造。
我们进行逐步探究,首先为了实现push_back识别右值传参,我们就要提供一个右值引用的重载版本:
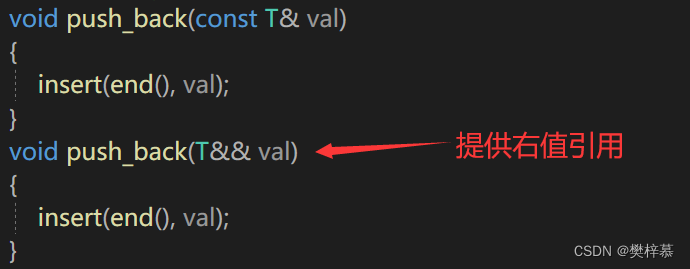
执行代码发现没有起效果:
发现原来push_back复用insert实现的,那么我们就给insert也提供一个右值引用版本:
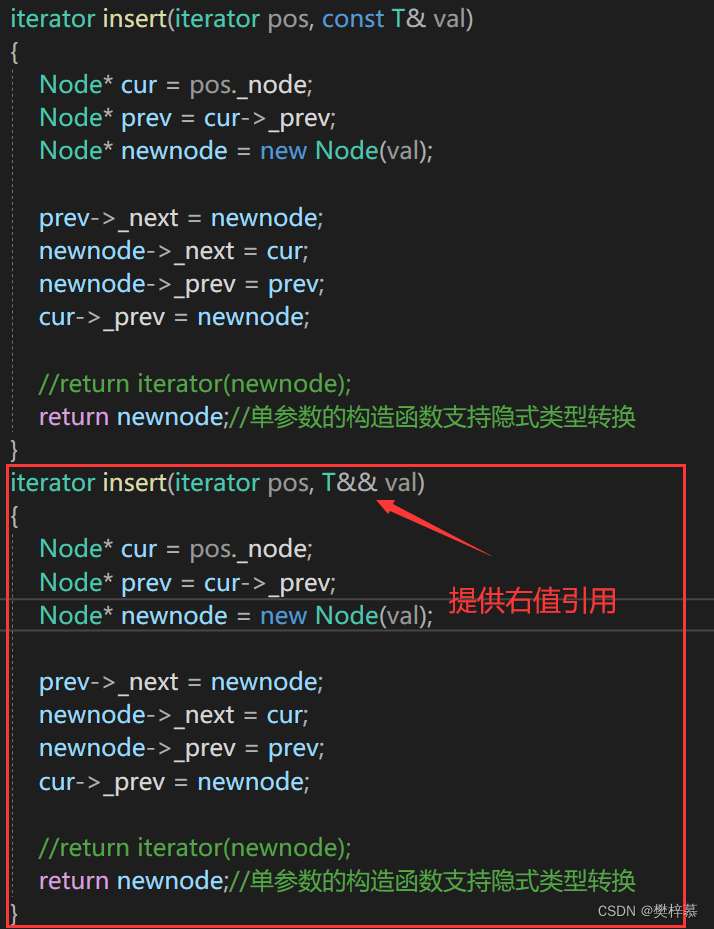
补充:STL库中也提供了insert的右值引用版本:

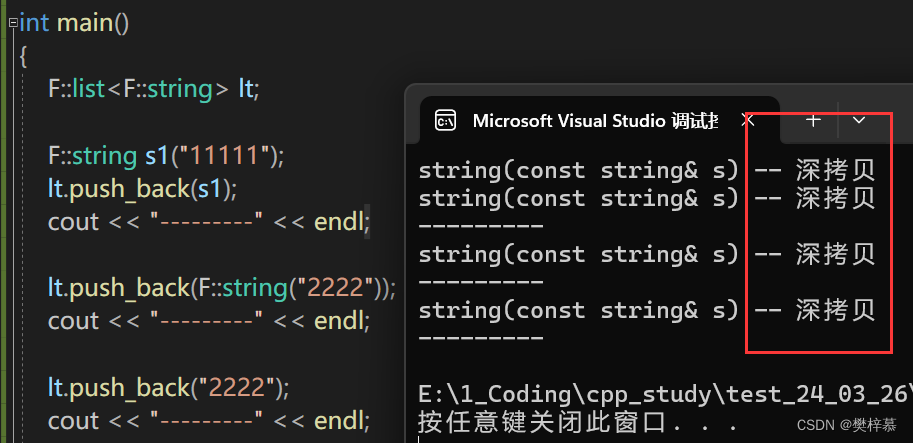
执行代码,发现仍然没有起效果:
再又发现insert内部new了一个Node,那这里会存在构造,list的构造我们并没有提供右值引用版本,那就加上:
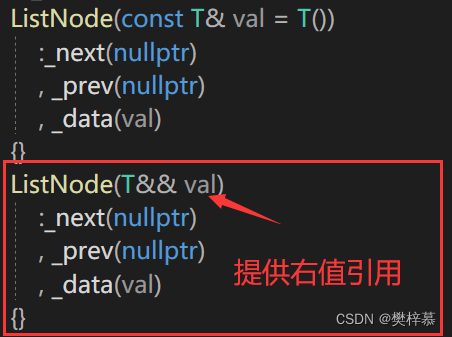
执行后发现还是没效果:
那么我们只能进行调试,看看到底有没有按照我们的想法进入右值引用的版本呢?
我们不看第一个左值,直接看第二个匿名对象的右值,发现:

为什么呢,我们不是实现了insert的右值引用么?
这里我直接说结论:
右值被右值引用,该右值引用的属性是左值。
所以当进入push_back后,此时:

那为什么这样设计呢?
我们看下之前讲移动构造的例子:
之前说,编译器进行了优化,讲str隐式地move变成右值(注意这里比较特殊,我们之前说move不能改变对象的属性,这里其实不是真的move,这样写是为了更好的让大家理解),然后直接移动资源swap,可是你有没有想过,如果这里的str变成了右值,交换资源是需要修改的,右值可以被修改么??
或者说,右值传参也传不给swap呀:

当然是不可以,这是我们最开始『 什么是左值&&什么是右值』就提到过的基本概念。
那既然不可修改那还移动啥啊。
所以这里才有了右值被右值引用后,该右值引用是左值的概念。
左值是可以被修改的,之后才能被移动,资源才可以进行转移,到这才完成了逻辑闭环。
那么我们来验证一下吧,利用move(),move(x)这个表达式的返回值是右值,通过这样的方式进入insert的右值引用版本:

并且注意,insert内部new了一个Node,这里构造的参数x是右值的右值引用是左值需要move:
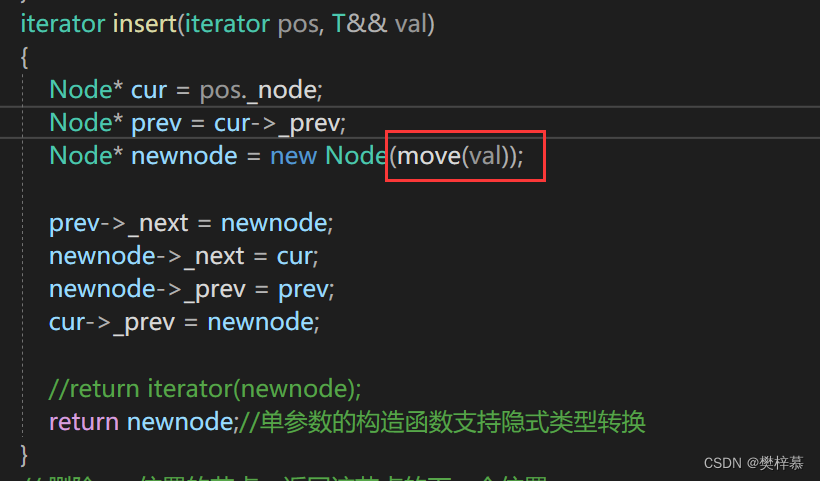
构造这里的data需要传参val,val是右值的右值引用也是左值,也需要move:

成功实现移动拷贝!
5.完美转发
万能引用
模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。比如:
template<class T>
void PerfectForward(T&& t)
{
//...
}万能引用顾名思义,就是既可以接收左值也可以接受右值,并且根据传入的参数进行推导得出具体的类型,所以这里必须是在模板类中使用 。
如果传入的实参是一个左值,那么这里的形参t就是左值引用,如果传入的实参是一个右值,那么这里的形参t就是右值引用。
但是这里就会有一个问题,在上面我们提到过右值被右值引用后,该右值引用的属性是左值,这样设计的目的主要是为了可以进行移动拷贝,允许修改,但我们后来不得不进行特殊处理move,将这个属性为左值的右值引用又转化回了右值,这样才能调用对应的右值引用的函数。
上面这段文字都是我们上面『 容器插入场景分析』部分逐步进行实现得到的结论。
那么如果我们要实现所谓的『 万能引用』,就必须要处理这块的问题,就不能进行所谓的特殊处理了,那怎么办呢?
C++11引入了『 完美转发』的概念。
完美转发保持值的属性不变
要想在参数传递过程中保持其原有的属性,需要在传参时调用forward函数。比如:
template<class T>
void PerfectForward(T&& t)
{
Func(std::forward<T>(t));
}经过完美转发后:
- 如果t本身是左值,就保持该左值属性;
- 如果t本身是右值,右值引用后,属性退化为左值,这里经完美转发会重新转化成右值,相当于move了一下,保持了t的原生属性。
万能引用与完美转发互相配合,体现了泛型编程的思想,有了他们,我们就避免了冗余代码,针对各种类型的引用也能轻松应对,无他,编译器承担了一切。
=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================