在 2024年4月19 日,AI界迎来了一项重大突破:Meta 公司宣布推出了迄今为止最强大的新一代开源大语言模型 Llama3。这一消息无疑为我国AI产业的发展带来了新的希望和机遇。
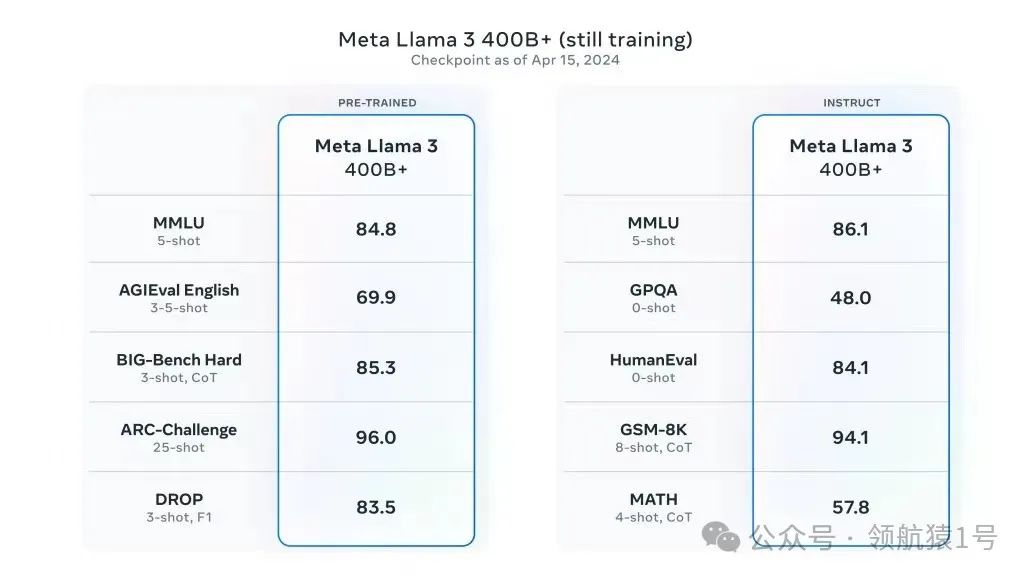
🎯 Llama3 系列语言模型(LLM)包括 Llama3 8B 和 Llama3 70B 两个版本,分别具备预训练和指令微调功能,支持 8K 上下文。这两个模型是在两个 24K GPU 定制集群上,使用 15万亿tokens 数据进行训练的。据 Meta 公司表示,这两个模型分别是 80亿 和 700亿 参数上的最佳表现。此外,一个参数超过 400B 的“最大Llama3”也正在紧锣密鼓地训练中,有望在性能上超越目前市场上的闭源王者 GPT-4 Turbo。
Llama3在各行业基准测试中表现出色,能够广泛支持各种应用场景。在接下来的几个月里,Meta公司将陆续推出更多新功能,包括多语言对话、多模态、更长的上下文和更强大的整体核心性能,并将与社区分享相关研究论文。

🔗 Meta 相关网址【收藏】
史上最全 Llama 3 网址资料:不要犹豫,先收藏再说,你肯定用得到!
- Meta Llama 3 官网:https://llama.meta.com/llama3
- Meta AI 网址:https://ai.meta.com/
- 官网下载地址:https://llama.meta.com/llama-downloads
- GitHub 地址:https://github.com/meta-llama/llama3
- Huggingface 地址:https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
- 可直接使用 Llama 3 的平台
-
- Meta AI 网址:https://ai.meta.com/
- Hugging Chat:https://huggingface.co/chat/
- App 下载地址:https://apps.apple.com/us/app/huggingchat/id6476778843?l=zh-Hans-CN
- 第三方 API
-
- 微软 Azure:Microsoft Azure Marketplace
- Replicate 8B 模型:meta/meta-llama-3-8b – Run with an API on Replicate
- Replicate 70B 模型:meta/meta-llama-3-70b – Run with an API on Replicate

📊 测评报告
- 在 TriviaQA-Wiki 测试中,Llama 3 70B 模型的准确率达到了89.7%,这一成绩远超其他同规模的模型。
- 在精心设计的内部评估集中,包含1,800个精选提示,涵盖12个关键用例,从咨询到编码,从创意写作到深度分析,Llama 3 在这些真实世界场景中展现了其卓越的实力。
- 据Meta公司表示,Llama 3 不仅仅是一次进步,它是一次革命性的飞跃!在Llama 2的基础上,新一代模型在预训练和后训练的过程中都实现了质的飞越,显著降低了错误拒绝率,提升了一致性,并且丰富了模型响应的多样性。无论是推理、代码生成还是指令遵循,Llama 3 都展现了更高的可控性和精准度。
📍 横向对比
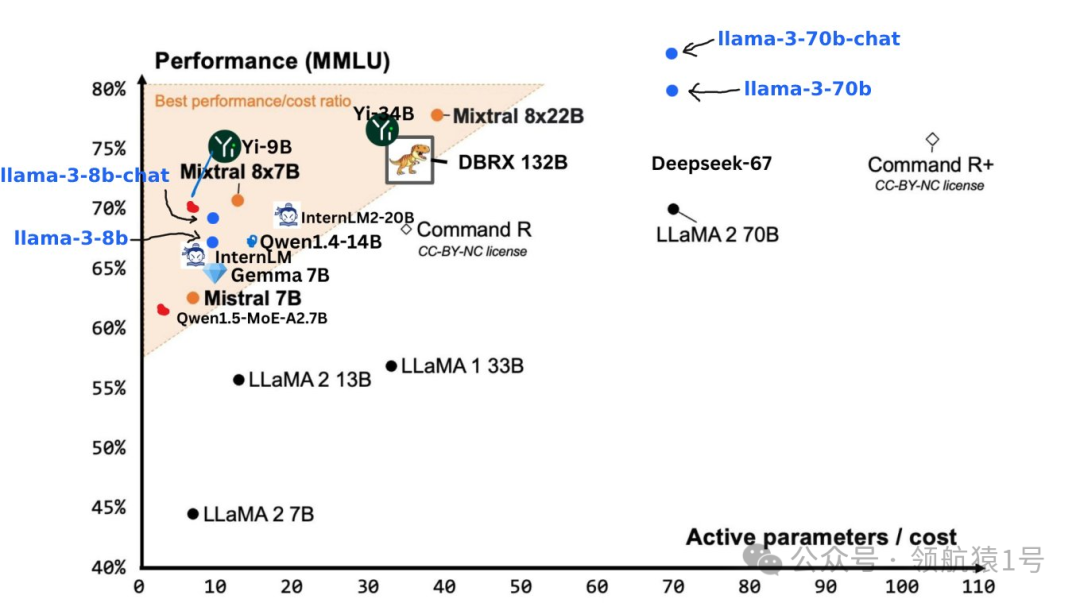
- 在与Gemma 7B 和 Mistral 7B 的直接对比中,Llama3 8B 在多任务语言理解、生成式预训练问题回答、编码和数学等核心基准测试上毫不费力地取得胜利。更不用说,Llama3 70B 也在对决中轻松战胜了备受瞩目的 Gemini Pro 1.5 和广受赞誉的 Claude 3 Sonnet。

- 🥊 面对Mitral 7B、Gemma 7B、Gemini Pro 1.0,以及新晋竞争者Mixtral 8x22B,Llama 3 8B和70B版本展现了它们的强大实力,将这些对手一一击败,宛如战场上的勇士,无一敌手。

- 除了聚焦于LLM的标准基准测试,Meta还致力于提升模型在现实应用中的表现。为此,他们精心打造了一套全新且质量上乘的人工评估集,其中包含1800个精心设计的提示,涵盖了从寻求建议到头脑风暴,再到分类、封闭式问题回答、编码、创意写作、信息提取、角色扮演、开放式问题回答、推理、重写以及总结等12个核心应用场景。为了确保评估的公正性和避免过拟合的风险,即便是Meta自家的建模团队也无法触及这一评估集。
- 在这套严格的评估体系下,Llama3 70B模型表现出色,与Claude Sonnet、Mistral Medium、GPT-3.5以及前代王者Llama2的较量中胜率显著。虽然此次对比并未包括GPT-4和Claude 3 Opus这样的业界翘楚,但我们有理由期待,后续的400B模型将肩负起更重的使命,续写辉煌篇章。

📍 Llama3 8B 能力远超 Llama 2 70-b


📍 中文有点弱
📍 Llama3 400B 还在训练中

🌈 架构与优化
- 模型架构:Llama 3 采用了标准的纯解码器 Transformer 架构,这种架构有利于模型进行高效的自回归文本生成任务。
- Tokenizer 改进:Llama 3 使用了具有 128K token 词汇表的 tokenizer,这比前代模型更大,能够更有效地编码语言,从而显著提升模型性能。
- 分组查询注意力(GQA):在 8B 和 70B 模型中,Llama 3 采用了分组查询注意力机制,这有助于提高模型的推理效率。
- 序列长度和掩码:Llama 3 在 8192 个 token 的序列上训练模型,并使用掩码来确保自注意力不会跨越文档边界,这有助于模型更好地处理长序列。
- 预训练数据集:Llama 3 使用了超过 15T 的 token 进行预训练,这是 Llama 2 使用数据集的七倍,其中包含的代码数据是 Llama 2 的四倍,显示了 Meta 在数据量上的大量投入。
- 多语言支持:Llama 3 的预训练数据集超过 5% 由 30 多种语言的非英语数据组成,以支持多语言的实际应用,尽管这些语言的性能可能略低于英语。
- 数据质量控制:Meta 研究团队使用启发式过滤器、NSFW 筛选器、语义重复数据删除方法和文本分类器来预测和确保数据质量,甚至利用前代 Llama 模型来生成用于训练的文本质量分类器数据,实现了“AI 训练 AI”的概念。
- 训练效率提升:Llama 3 在训练效率上取得了显著进步,通过结合数据并行化、模型并行化和管道并行化,以及开发新的训练堆栈和改进硬件可靠性,训练效率比前代提高了约 3 倍。
- 基准测试:Llama 3 在多个基准测试中取得了优异的成绩,如在 MMLU、GPQA、HumanEval 等测试中得分远超其他模型,显示了其强大的性能。
- 人类评估数据集:Meta 开发了一套新的高质量人类评估数据集,包含 1800 个提示,涵盖 12 个关键用例,以准确研究模型性能
🎯 微调注意:
LLAMA3的所有微调必须加名字
📈 梗图
此外,Meta 承诺将与全球技术社区共享 Llama3 的研究论文和开发成果,这一开放的姿态不仅体现了 Meta 对于开源文化的坚定支持,也为全球的研究人员和开发者提供了宝贵的学习和合作机会。
总而言之,Llama3 的发布不仅是Meta公司的一个重大成就,更是全球AI领域的一个重要转折点。它不仅展示了Meta在AI技术上的深厚实力,也为未来的技术创新和应用打开了无限可能。随着 Llama3 的不断完善和升级,我们有理由相信,它将成为推动AI技术发展的强大引擎,并在全球范围内激发更多的创新和合作。
学习更多关于 AI 大模型全栈知识👇
🚦【必读】50多万字「AI全栈」知识库 · 语雀

![[Python开发问题] Selenium ERROR: Unable to find a matching set of capabilities](https://img-blog.csdnimg.cn/direct/531165c3ae494a6ea813e245d31082c8.gif#pic_center)