简介
论文学习 https://arxiv.org/abs/2308.13418
项目地址 GitHub - facebookresearch/nougat: Implementation of Nougat Neural Optical Understanding for Academic Documents
项目主页 Nougat
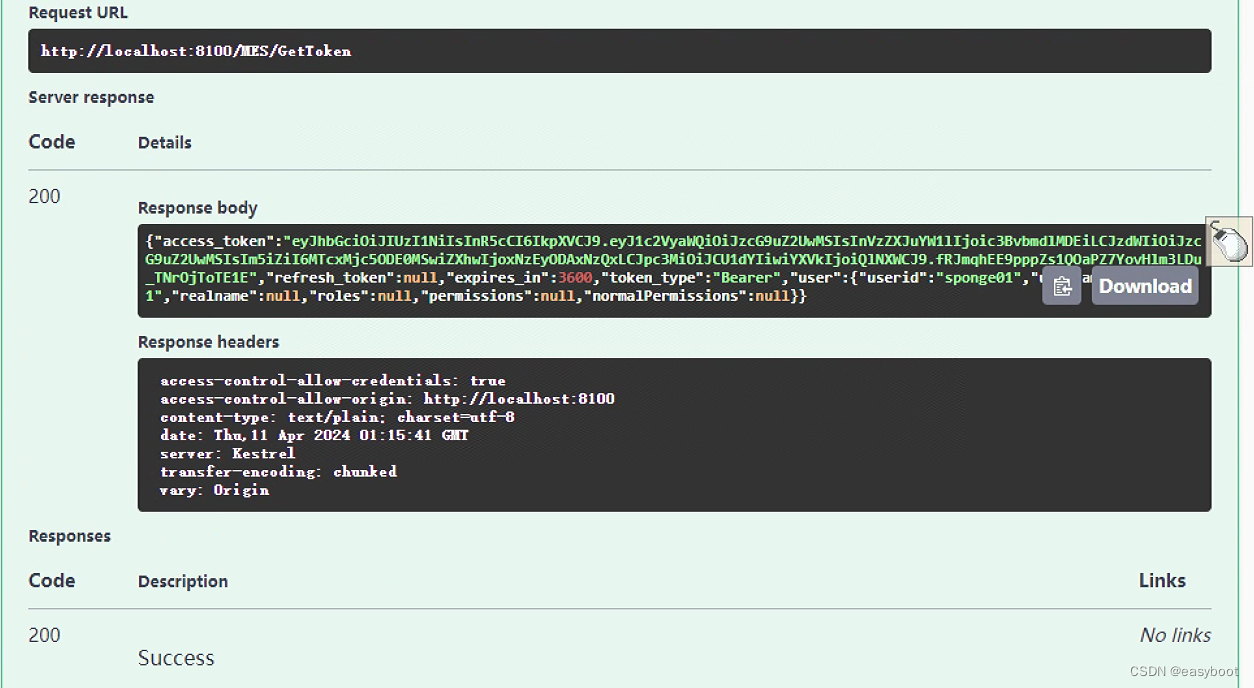
这个项目主要是实现将pdf文档图片转换为markdown格式;针对纯英文文本和英文公式效果较好,针对中文的支持不佳。
大部分科学知识储存在书籍中,或者发表在科学期刊上,通常采用便携式文档格式(PDF)。在互联网上,PDF格式是除HTML之外第二常见的数据格式,占据了常见爬取数据的2.4% 。然而,这些文件中存储的信息很难提取到其他格式中。这对于高度专业的文档,如科学研究论文,其中数学表达式的语义信息丢失了。
现有的光学字符识别(OCR)引擎,如Tesseract OCR ,在检测和分类图像中的单个字符和单词方面表现出色,但由于其逐行方法,无法理解它们之间的关系。这意味着它们将上标和下标与周围的文本一样对待,这对于数学表达式来说是一个重大的缺点。在数学符号中,如分数、指数和矩阵,字符的相对位置至关重要。
将学术研究论文转换为机器可读的文本也使得科学整体的可访问性和可搜索性成为可能。因为这些论文被不可读的格式所锁住,所以无法完全访问数百万篇学术论文的信息。现有的语料库,如S2ORC数据集 ,使用GROBID 捕获了12M篇论文的文本,但缺少了数学方程的有意义表示。
视觉文档理解(VDU)是深度学习研究的另一个相关主题,它专注于提取各种文档类型的相关信息。以前的工作依赖于预训练模型,这些模型通过同时建模文本和布局信息来学习提取信息,使用Transformer架构。LayoutLM模型家族(layoutLMv1-layoutLMv3)使用遮蔽布局预测任务来捕捉不同文档元素之间的空间关系。
与我们目标相关的开源解决方案包括GROBID,它将数字生成的科学文档解析为XML,重点是参考文献数据和pdf2htmlEX,它将数字生成的PDF转换为HTML,同时保留文档的布局信息 和外观。然而,这两个解决方案都不能恢复数学表达式的语义信息。
为此,我们介绍了Nougat,一个基于Transformer的模型,可以将文档页面的图像转换为格式化的标记文本。
模型
模型结构
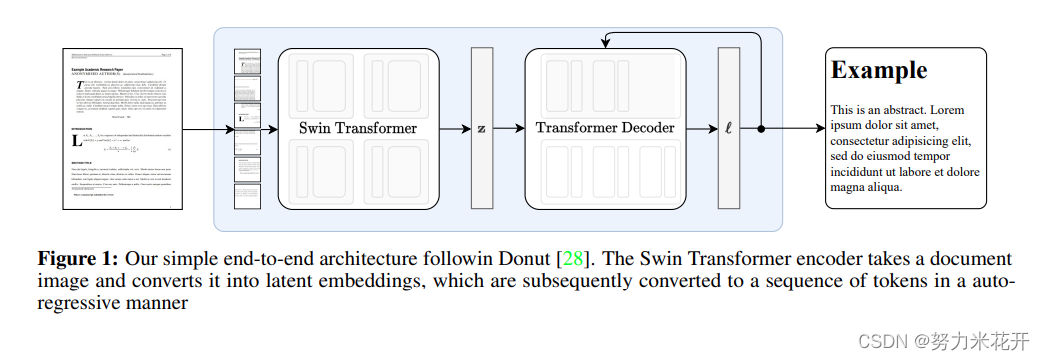
Nougat的端到端结构和Donut一致(Donut模型-图像文本阅读以及下游任务的多模态大模型-CSDN博客)。采用Swin Transformer作为视觉编码器,并生成潜空间嵌入表示;然后采用一个大语言模型mBART模型作为decoder作为自生成解码器,采用Galactica: A Large Language Model for Science中的tokenizer作为这里使用的tokenizer。
模型配置信息
我们以96 DPI的分辨率渲染文档图像。由于Swin Transformer可能的输入尺寸受限,我们选择输入大小(H,W)=(896,672)。这种比例介于US信纸和Din A4格式之间22 17 < 4 3 < √ 2。我们将文档图像缩放并填充以达到所需的输入尺寸。这个输入尺寸允许我们使用Swin基础模型架构。我们用预训练权重初始化模型。Transformer解码器有最大的序列长度S = 4096。这个相对较大的尺寸是因为学术研究论文的文本可能很密集,特别是表格的语法很繁琐。BART解码器是一个只有解码器的Transformer,具有10层。整个架构总共有3.5亿个参数。我们还尝试了一个较小的模型(2.5亿个参数),其序列长度为S = 3584,只有4层解码器,我们从预训练的基础模型开始。 在推理过程中,文本使用贪婪解码生成。
训练我们使用AdamW优化器进行训练,共3个epoch,有效batchsize为192。由于训练不稳定性,我们选择初始学习率lr= 5 × 10-5,它在每次更新15次后减少到lr = 7.5 × 10-6
数据增强

在图像识别任务中,使用数据增强来提高泛化能力通常是有益的。由于我们只使用数字生成的学术研究论文,因此我们需要实施多种转换来模拟扫描文档的不完美和变异性。这些转换包括侵蚀、膨胀、高斯噪声、高斯模糊、位图转换、图像压缩、网格扭曲和弹性变换。每个转换对给定图像应用的概率是固定的。这些转换是在Albumentations库中实现的。有关每个转换效果的概述,请参见图2。
数据集
数据集概述
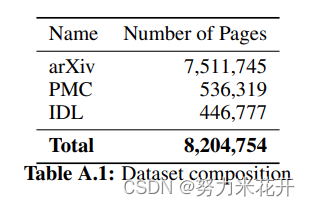
据我们所知,目前还没有PDF页面和相应源代码的配对数据集,因此我们自己在arXiv上的开放获取文章中创建了自己的数据集。为了布局多样性,我们还包括了PubMed Central (PMC)的开放获取非商业数据集的一个子集。在预训练期间,还包含了一部分行业文档图书馆(IDL)。有关数据集组成的详细信息,如下图所示。
arXiv
我们从arXiv上发布的1,748,201篇文章中收集了源代码和编译后的PDF。为了确保一致的格式,我们首先使用LaTeXML处理源文件,并将其转换为HTML5文件。这一步骤很重要,因为它标准化并消除了LaTeX源代码中的模糊性,尤其是在数学表达式方面。转换过程包括替换用户定义的宏,标准化空白,添加可选的括号,规范化表格,并将引用和引用替换为它们的正确编号。 然后我们解析HTML文件,并将它们转换为支持标题、加粗和斜体文本、算法、LaTeX内联和显示数学以及LaTeX表格的轻量级标记语言。这样,我们就确保了源代码格式正确,并准备好进行进一步处理。 该过程在图3中可视化。

PMC:
我们还处理了来自PMC的文章,其中除了PDF文件外,还有包含PDF对应的语义信息的XML文件(这些文件是GT)。我们将这些文件解析为与arXiv文章相同的标记语言格式(markdown)。我们选择使用较少的PMC文章,因为XML文件并不总是包含丰富的语义信息。通常,方程和表格以图像形式存储,这导致表格和公式的信息不容易被标记和详细记录。最终我们将PMC文章的使用限制在预训练阶段。
IDL
IDL是由对公共健康有影响的行业生产的文档集合,由加州大学旧金山图书馆维护。Biten等人[37]为IDL数据集中的PDF提供了高质量的OCR文本。但是这导致这批数据的GT中不包括文本格式信息,因此这部分的数据也仅用于预训练,用来训练模型正确的扫描文档的基本OCR文本信息。
分割页面
为什么要分割页面?
因为通过latexxml转换得到的html是针对整个文档生成的一份html文件,而我们训练需要的样本是针对每页pdf的图片,需要生成对应的轻量级的标记语言,这里采用的markdown。因此需要首先将html转换为markdown,然后根据pdf每页的解析结果将markdown的内容进行拆分,将一份完成的markdown拆分成N份文档GT,其中N为pdf的实际页码数量。
具体操作怎么实现?
我们根据PDF文件中的页面分隔符将Markdown文件分割,并将每页栅格化为图像,以创建最终的配对数据集。在编译过程中,LaTeX编译器会自动确定PDF文件的分页。由于我们不会为每篇论文重新编译LaTeX源文件,因此必须启发式地将源文件分割成与不同页面对应的部分。为了实现这一点,我们使用PDF页面内的文本与源数据中文本匹配。到这里解决了页面文本的匹配问题。
然而,PDF中的图表和插图可能不与其在源代码中的位置相对应。为了解决这个问题,我们在预处理步骤中使用pdffigures2 移除这些元素。随后识别出的caption与XML文件中的标题进行比较,并基于它们之间的Levenshtein距离进行匹配。一旦源文档被分割成单独的页面,移除的图表和插图就被重新插入到每页的末尾。为了更好地匹配,我们还将PDF文本中的Unicode字符替换为相应的LaTeX命令,使用的是pylatexenc-library。
词袋匹配
首先,我们使用MuPDF9从PDF中提取文本行,并预处理它们以去除页码和可能的页眉/页脚。然后,我们使用包含TF-IDF向量化器和线性支持向量机分类器的Bag of Words模型 [40]。该模型以页码作为标签对PDF行进行拟合。接下来,我们将LaTeX源代码分割成段落,并为每个段落预测页码。
理想情况下,预测将形成一个楼梯状函数,但实际中信号会存在噪声。为了找到最佳的分界点,我们使用了与决策树相似的逻辑,并最小化基于Gini不纯度的衡量标准。
数据集的GT中可能存在的问题
由于数据集已经通过LaTeXML进行了预处理,源代码的标记版本可能包含不受支持的包中的 artifact 和命令。HTML文件可能包含有编号的子节标题,即使它们在PDF中没有编号。还可能存在一些情况,由于处理错误, ground truth 中缺失了图表或表格。
此外,源代码的分割算法在某些情况下会包含上一页的文字,或者从末尾切割掉单词。这对于用于格式化的“不可见”字符,如斜体、粗体文本或章节标题尤其如此。
对于PMC论文,内联数学通常写作Unicode或斜体文本,而显示数学公式或表格经常以图像格式包含,因此将被忽略。
这些问题都会降低整体数据质量。然而,大量的训练样本可以弥补这些小错误。
评估指标
评估指标参数
Edit distanc:
编辑距离,或Levenshtein距离[39],衡量了将一个字符串转换为另一个字符串所需的字符操作(插入、删除、替换)的数量。在这项工作中,我们考虑的是归一化的编辑距离,其中我们将其除以总字符数。
BLEU:
BLEU指标最初是为了衡量从一种语言机器翻译到另一种语言的文本质量而引入的。这个指标基于候选句和参考句之间匹配的n-gram的数量来计算得分。
METEOR:
另一种专注于召回率而不是精确度的机器翻译指标,在[43]中引入。
F-measure:
我们还计算了F1分数,并报告了精确度和召回率。
文本的多种表达方式
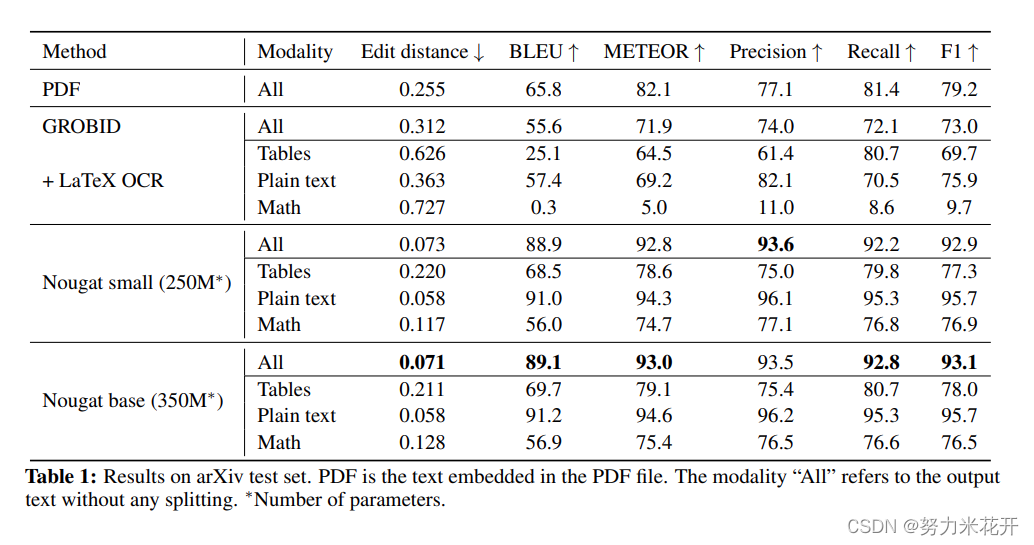
文本模态 在科学研究文章中,有三种不同的文本类型:1)纯文本,它构成了文档的大部分,2)数学表达式,以及3)表格。在评估过程中分别检查这些组成部分是很重要的。这是必要的,因为在LaTeX中,有多种方式可以表达同一个数学表达式。尽管在LaTeXML预处理步骤中消除了一些变化性,但仍然存在大量的模糊性,如下标和上标的顺序、等效命令的不同表示法(stackrel、atop、substack或frac、over)、情境可互换的命令(bm、mathbf、boldsymbol、bf或\left(、\big(等)、空白命令、额外的括号层等等。因此,即使渲染后的公式看起来相同,预测和地面真实之间也可能存在差异。
此外,当书写数字和标点符号时,有时无法确定内联数学环境何时结束,文本何时开始
![]()
这种模糊性降低了数学和纯文本的得分。
数学表达式的预期得分低于纯文本。