前言
又是一个面试问题, 呵呵 之前碰到的
一个 java 进程 cpu 占用率过高, 应该如何排查?
对于这种问题, 第一反应就是 jstack, pstack, 然后仔细观察多次堆栈信息结果的 重复率较高的代码
因此 我给出的思路是, 写脚本 多次 jstack 目标进程, 然后 再统计分析一下 出现频率最高的 topN 的方法调用附近的东西
呵呵 这里来整理一下 这个流程
测试用例
这里主要是一个 不断计算的一个测试用例
主要是确保 程序一直在不断的执行, 计算的相关操作, 这里不要加入 io 的相关操作
-Xint 是防止, jvm 的编译优化, 将 funcA, funcB, funcC, funcD 的相关处理削除掉了
/**
* Test17CpuTooHigh
*
* @author Jerry.X.He
* @version 1.0
* @date 2023/9/20 17:38
*/
public class Test17CpuTooHigh {
// Test17CpuTooHigh
// -Xint
public static void main(String[] args) {
while (true) {
funcA();
}
}
public static void funcA() {
for (int i = 0; i < 10000; i++) {
funcB();
}
}
public static void funcB() {
for (int i = 0; i < 10000; i++) {
funcC();
}
}
public static void funcC() {
for (int i = 0; i < 10000; i++) {
funcD();
}
}
public static void funcD() {
for (int i = 0; i < 10000; i++) {
int x = 2, y = 3;
int z = x + y;
}
}
}多次统计 jstack 的脚本
呵呵 简单的输出, 不多解释
public class Test18OutputJstackScripts {
// Test18OutputJstackScripts
public static void main(String[] args) {
String pid = "14232";
for (int i = 0; i < 100; i++) {
System.out.println(String.format("jstack %s >> %s.txt", pid, i));
}
}
}统计方法调用频率最高的 topN
呵呵 这里仅仅考虑 相对比较 common 的场景, 简单处理
特殊的场景, 需要特殊考虑
/**
* Test19CollectMostCommonCode
*
* @author Jerry.X.He
* @version 1.0
* @date 2023/9/20 17:46
*/
public class Test19CollectMostCommonCode {
// Test19CollectMostCommonCode
public static void main(String[] args) throws Exception {
String path = "D:\\Tmp\\30_multi_jstack";
Map<String, Integer> func2Count = new LinkedHashMap<>();
FileUtils.traverse(path, file -> {
return !file.getName().contains("run");
}, file -> {
try {
List<String> lines = Tools.getContentWithList(file);
for (String line : lines) {
if (!line.contains("at ")) {
continue;
}
String func = Tools.getStrInRangeWithStart(line, "at ");
Integer oldCount = func2Count.computeIfAbsent(func, k -> 0);
func2Count.put(func, oldCount + 1);
}
} catch (Exception e) {
e.printStackTrace();
}
});
List<String> keywords = Arrays.asList("spring", "hx", "test");
List<Pair<String, Integer>> list = new ArrayList<>();
for (Map.Entry<String, Integer> entry : func2Count.entrySet()) {
String func = entry.getKey();
List<String> targetKeywords = keywords.stream().filter(k -> func.contains(k)).collect(Collectors.toList());
if (CollectionUtils.isEmpty(targetKeywords)) {
continue;
}
list.add(new Pair<>(entry.getKey(), entry.getValue()));
}
Collections.sort(list, (o1, o2) -> {
return -(o1.getSecond() - o2.getSecond());
});
int x = 0;
}
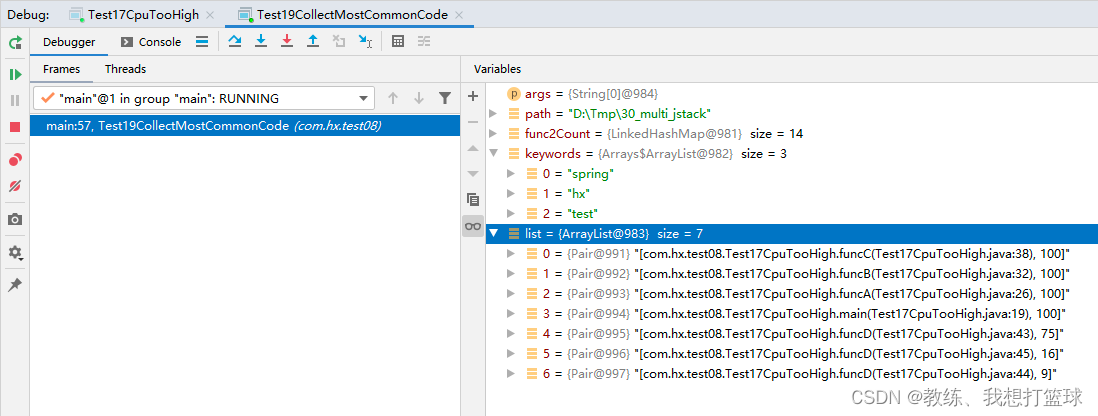
}最终执行结果如下
就可以根据这些方法调用的相关信息, 来定位导致 cpu 过高的原因
一般来说是 无限循环 或者 非常大的循环 或者 无限递归
完



![[笔试强训day01]](https://img-blog.csdnimg.cn/direct/ea4db5be66a84fcdb6e4ec6ea34ca39a.png)