并查集理论基础
1.背景
首先要知道并查集可以解决什么问题呢?
并查集常用来解决连通性问题。大白话就是当我们需要判断两个元素是否在同一个集合里的时候,我们就要想到用并查集。
并查集主要有两个功能:
- 将两个元素添加到一个集合中。
- 判断两个元素在不在同一个集合
接下来围绕并查集的这两个功能来展开讲解。
2.原理讲解
从代码层面,我们如何将两个元素添加到同一个集合中呢。
可能会想到:可以把他放到同一个数组里或者set 或者 map 中,这样就表述两个元素在同一个集合。
那么问题来了,对这些元素分门别类,可不止一个集合,可能是很多集合,成百上千,那么要定义这么多个数组吗?
那可以定义一个二维数组吗?但定义一个二维数组的话,如果我们要判断两个元素是否在同一个集合里的时候 我们又能怎么办? 只能把而二维数组都遍历一遍。而且每当想添加一个元素到某集合的时候,依然需要把把二维数组组都遍历一遍,才知道要放在哪个集合里。
这仅仅是一个粗略的思路,如果沿着这个思路去实现代码,非常复杂,因为管理集合还需要很多逻辑。
那么我们来换一个思路来看看。
我们将三个元素A,B,C (分别是数字)放在同一个集合,其实就是将三个元素连通在一起,如何连通呢。
只需要用一个一维数组来表示,即:father[A] = B,father[B] = C 这样就表述 A 与 B 与 C连通了(有向连通图)。
代码如下:
// 将v,u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
可能会想,这样我可以知道 A 连通 B,因为 A 是索引下标,根据 father[A]的数值就知道 A 连通 B。那怎么知道 B 连通 A呢?
我们的目的是判断这三个元素是否在同一个集合里,知道 A 连通 B 就已经足够了。
这里要讲到寻根思路,只要 A ,B,C 在同一个根下就是同一个集合。
给出A元素,就可以通过 father[A] = B,father[B] = C,找到根为 C。
给出B元素,就可以通过 father[B] = C,找到根也为为 C,说明 A 和 B 是在同一个集合里。 那么第一段代码里find函数是如何实现的呢?其实就是通过数组下标找到数组元素,一层一层寻根过程,代码如下:
// 并查集里寻根的过程
int find(int u) {
if (u == father[u]) return u; // 如果根就是自己,直接返回
else return find(father[u]); // 如果根不是自己,就根据数组下标一层一层向下找
}
如何表示 C 也在同一个元素里呢? 我们需要father[C] = C,即C的根也为C,这样就方便表示 A,B,C 都在同一个集合里了。
所以father数组初始化的时候要 father[i] = i,默认自己指向自己。
代码如下:
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
最后我们如何判断两个元素是否在同一个集合里,如果通过 find函数 找到 两个元素属于同一个根的话,那么这两个元素就是同一个集合,代码如下:
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
3.路径压缩
在实现 find 函数的过程中,我们知道,通过递归的方式,不断获取father数组下标对应的数值,最终找到这个集合的根。
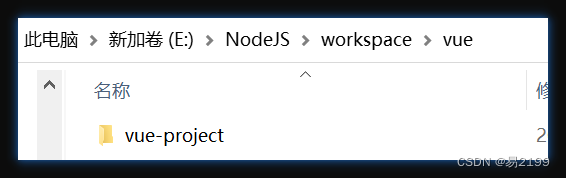
搜索过程像是一个多叉树中从叶子到根节点的过程,如图:

如果这棵多叉树高度很深的话,每次find函数 去寻找根的过程就要递归很多次。
我们的目的只需要知道这些节点在同一个根下就可以,所以对这棵多叉树的构造只需要这样就可以了,如图:
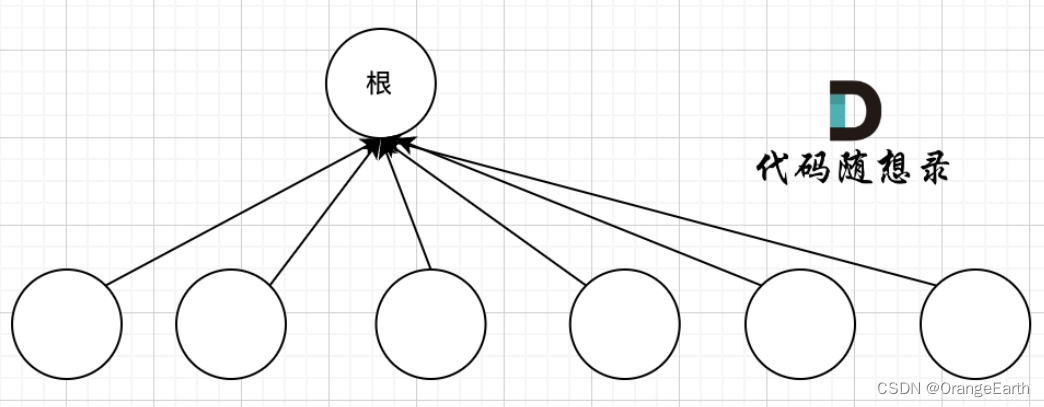
除了根节点其他所有节点都挂载根节点下,这样我们在寻根的时候就很快,只需要一步,
如果我们想达到这样的效果,就需要 路径压缩,将非根节点的所有节点直接指向根节点。 那么在代码层面如何实现呢?
我们只需要在递归的过程中,让 father[u] 接住 递归函数 find(father[u]) 的返回结果。
因为 find 函数向上寻找根节点,father[u] 表述 u 的父节点,那么让 father[u] 直接获取 find函数 返回的根节点,这样就让节点 u 的父节点 变成根节点。
代码如下,注意看注释,路径压缩就一行代码:
// 并查集里寻根的过程
int find(int u) {
if (u == father[u]) return u;
else return father[u] = find(father[u]); // 路径压缩
}
以上代码在C++中,可以用三元表达式来精简一下,代码如下:
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]);
}
4.代码模板
那么此时并查集的模板就出来了, 整体模板C++代码如下:
int n = 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]); // 路径压缩
}
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
通过模板,我们可以知道,并查集主要有三个功能。
- 寻找根节点,函数:
find(int u),也就是判断这个节点的祖先节点是哪个 - 将两个节点接入到同一个集合,函数:
join(int u, int v),将两个节点连在同一个根节点上 - 判断两个节点是否在同一个集合,函数:
isSame(int u, int v),就是判断两个节点是不是同一个根节点
5.常见误区
模板中的 join 函数里的这段代码:
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
与 isSame 函数的实现是不是重复了? 如果抽象一下呢,代码如下:
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
if (isSame) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
这样写可以吗? 好像看出去没问题,而且代码更精简了。
其实这么写是有问题的,在join函数中 我们需要寻找 u 和 v 的根,然后再进行连线在一起,而不是直接 用 u 和 v 连线在一起。
举一个例子:
join(1, 2);
join(3, 2);
此时构成的图是这样的:
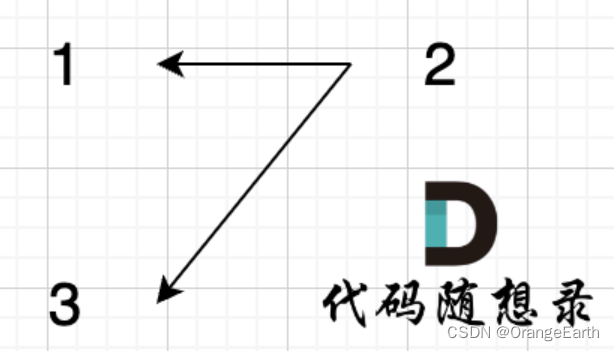
此时问 1,3是否在同一个集合,我们调用 join(1, 2); join(3, 2); 很明显本意要表示 1,3是在同一个集合。
但我们来看一下代码逻辑,当我们调用 isSame(1, 3)的时候,find(1) 返回的是1,find(3)返回的是3。 return 1 == 3 返回的是false,代码告诉我们 1 和 3 不在同一个集合,这明显不符合我们的预期,所以问题出在哪里?
问题出在我们精简的代码上,即 join 函数 一定要先 通过find函数寻根再进行关联。
如果find函数是这么实现,再来看一下逻辑过程。
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
分别将 这两对元素加入集合。
join(1, 2);
join(3, 2);
当执行join(3, 2)的时候,会先通过find函数寻找 3的根为3,2的根为1 (第一个join(1, 2),将2的根设置为1),所以最后是将1 指向 3。
构成的图是这样的:

因为在join函数里,我们有find函数进行寻根的过程,这样就保证元素 1,2,3在这个有向图里是强连通的。
此时我们在调用 isSame(1, 3)的时候,find(1) 返回的是3,find(3) 返回的也是3,return 3 == 3 返回的是true,即告诉我们 元素 1 和 元素3 是 在同一个集合里的。
6.复杂度分析
空间复杂度: O(n) ,申请一个father数组。
关于时间复杂度,如果想精确表达出来需要繁琐的数学证明,就不在本篇讲解范围内了,大家感兴趣可以自己去深入研究。
这里做一个简单的分析思路。
路径压缩后的并查集时间复杂度在O(logn)与O(1)之间,且随着查询或者合并操作的增加,时间复杂度会越来越趋于O(1)。
在第一次查询的时候,相当于是n叉树上从叶子节点到根节点的查询过程,时间复杂度是logn,但路径压缩后,后面的查询操作都是O(1),而 join 函数 和 isSame函数 里涉及的查询操作也是一样的过程。
并查集例题
并查集例题1:1971 寻找图中是否存在路径(easy)
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。
请你确定是否存在从顶点 source 开始,到顶点 destination 结束的 有效路径 。
给你数组 edges 和整数 n、source 和 destination,如果从 source 到 destination 存在 有效路径 ,则返回 true,否则返回 false 。
思路:标准并查集问题,利用edges和join函数创建并查集再判断source和destination根节点是否相同即可,注意最开始不要忘了进行init()初始化
代码实现:
class Solution {
private:
int n = 200005; // 节点数量 20000
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) { father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]);
}
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
public:
bool validPath(int n, vector<vector<int>>& edges, int source, int destination) {
init();
for (int i = 0; i < edges.size(); i++) {
join(edges[i][0], edges[i][1]);
}
return isSame(source, destination);
}
};
并查集例题2:684 冗余连接(medium)
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
思路:简单思考一下发现还是套并查集模板就行,注意不要忘了初始化。
题目说是无向图,返回一条可以删去的边,使得结果图是一个有着N个节点的树(即:只有一个根节点)。如果有多个答案,则返回二维数组中最后出现的边。
那么我们就可以从前向后遍历每一条边(因为优先让前面的边连上,如果题目中说:如果有多个答案,则返回二维数组中最前出现的边。 那我们就要 从后向前遍历每一条边了)
-
边的两个节点如果不在同一个集合,就加入集合(即:同一个根节点)。
-
如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,再加入这条边一定就出现环了,那么返回这条边。
代码实现1:
class Solution {
private:
int n = 1005; // 节点数量3 到 1000
vector<int> father = vector<int> (n, 0); // C++里的一种数组结构
// 并查集初始化
void init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]);
}
// 判断 u 和 v是否找到同一个根
bool isSame(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u); // 寻找u的根
v = find(v); // 寻找v的根
if (u == v) return ; // 如果发现根相同,则说明在一个集合,不用两个节点相连直接返回
father[v] = u;
}
public:
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
init();
for (int i = 0; i < edges.size(); i++) {
if (isSame(edges[i][0], edges[i][1])) return edges[i];
else join(edges[i][0], edges[i][1]);
}
return {};
}
};
代码实现2:
class Solution {
public:
int sum;
vector<int> father;
void init(){
father.resize(sum + 1);
for(int i = 0; i < sum; i++){
father[i] = i;
}
}
int find(int u){
return father[u] == u? u: father[u] = find(father[u]);
}
bool isSame(int u, int v){
u = find(u);
v = find(v);
return u == v;
}
void join(int u, int v){
u = find(u);
v = find(v);
if(u == v) return;
father[v] = u;
}
vector<int> findRedundantConnection(vector<vector<int>>& edges) {
sum = edges.size();
init();
for(int i = 0; i < sum; i++){
if(isSame(edges[i][0], edges[i][1]))
return edges[i];
join(edges[i][0], edges[i][1]);
}
return {};
}
};
并查集例题3:685 冗余连接 II(hard)
在本问题中,有根树指满足以下条件的 有向 图。该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。
输入一个有向图,该图由一个有着 n 个节点(节点值不重复,从 1 到 n)的树及一条附加的有向边构成。附加的边包含在 1 到 n 中的两个不同顶点间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组 edges 。 每个元素是一对 [ui, vi],用以表示 有向 图中连接顶点 ui 和顶点 vi 的边,其中 ui 是 vi 的一个父节点。
返回一条能删除的边,使得剩下的图是有 n 个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
思路:这道题目是hard题,相较于单纯的套并查集模板其实要考虑的还蛮多的,需要进行分情况讨论,但总体思路还是建立在并查集的基础上的
首先重点读懂题目中的这句
该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。
附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
这说明题目中的图原本是是一棵树,只不过在不增加节点的情况下多加了一条边!
还有
若有多个答案,返回最后出现在给定二维数组的答案。
这说明在两条边都可以删除的情况下,要删顺序靠后的!
因为是有向图,所以本题不一定成环,还有可能是某一个节点出现了两个父节点(也即该节点的入度为2),所以要分情况:
- 情形1:入度为2
- 情形2:出现有向环
情形1(入度为2):
首先先计算节点的入度,edges[i][1] 表示的节点都是 箭头指向的节点,即这个节点有一个入度!。
所以,统计入度的代码如下:
int inDegree[N] = {0}; // 记录节点入度
n = edges.size(); // 边的数量
for (int i = 0; i < n; i++) {
inDegree[edges[i][1]]++; // 统计入度
}
入度为2的情况,一定是删除指向入度为2的节点的两条边其中的一条,如果删了一条,判断这个图是一个树,那么这条边就是答案,同时注意要从后向前遍历,因为如果两条边删哪一条都可以成为树,就删最后那一条。
代码如下:
vector<int> vec; // 记录入度为2的边(如果有的话就两条边)
// 找入度为2的节点所对应的边,注意要倒序,因为优先返回最后出现在二维数组中的答案
for (int i = n - 1; i >= 0; i--) {
if (inDegree[edges[i][1]] == 2) {
vec.push_back(i);
}
}
// 处理情况1
// 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
if (vec.size() > 0) {
if (isTreeAfterRemoveEdge(edges, vec[0])) {
return edges[vec[0]];
} else {
return edges[vec[1]];
}
}
情况2(形成有向环):
明确没有入度为2的情况,那么一定有向环,找到构成环的边就是要删除的边。
可以定义一个函数,代码如下:
// 在有向图里找到删除的那条边,使其变成树,返回值就是要删除的边
vector<int> getRemoveEdge(const vector<vector<int>>& edges)
综合上面的叙述我们要实现两个最为关键的函数:
isTreeAfterRemoveEdge() 判断删一个边之后是不是树了
getRemoveEdge() 确定图中一定有了有向环,那么要找到需要删除的那条边
此时应该是用到并查集了,因为如果两个点所在的边在添加图之前如果就可以在并查集里找到了相同的根,那么这条边添加上之后 这个图一定不是树了
代码实现:
class Solution {
private:
static const int N = 1010; // 如题:二维数组大小的在3到1000范围内
int father[N];
int n; // 边的数量
// 并查集初始化
void init() {
for (int i = 1; i <= n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
int find(int u) {
return u == father[u] ? u : father[u] = find(father[u]);
}
// 将v->u 这条边加入并查集
void join(int u, int v) {
u = find(u);
v = find(v);
if (u == v) return ;
father[v] = u;
}
// 判断 u 和 v是否找到同一个根
bool same(int u, int v) {
u = find(u);
v = find(v);
return u == v;
}
// 在有向图里找到删除的那条边,使其变成树
vector<int> getRemoveEdge(const vector<vector<int>>& edges) {
init(); // 初始化并查集
for (int i = 0; i < n; i++) { // 遍历所有的边
if (same(edges[i][0], edges[i][1])) { // 构成有向环了,就是要删除的边
return edges[i];
}
join(edges[i][0], edges[i][1]);
}
return {};
}
// 删一条边之后判断是不是树
bool isTreeAfterRemoveEdge(const vector<vector<int>>& edges, int deleteEdge) {
init(); // 初始化并查集
for (int i = 0; i < n; i++) {
if (i == deleteEdge) continue;
if (same(edges[i][0], edges[i][1])) { // 构成有向环了,一定不是树
return false;
}
join(edges[i][0], edges[i][1]);
}
return true;
}
public:
vector<int> findRedundantDirectedConnection(vector<vector<int>>& edges) {
int inDegree[N] = {0}; // 记录节点入度
n = edges.size(); // 边的数量
for (int i = 0; i < n; i++) {
inDegree[edges[i][1]]++; // 统计入度
}
vector<int> vec; // 记录入度为2的边(如果有的话就两条边)
// 找入度为2的节点所对应的边,注意要倒序,因为优先返回最后出现在二维数组中的答案
for (int i = n - 1; i >= 0; i--) {
if (inDegree[edges[i][1]] == 2) {
vec.push_back(i);
}
}
// 处理情况1
// 如果有入度为2的节点,那么一定是两条边里删一个,看删哪个可以构成树
if (vec.size() > 0) {
if (isTreeAfterRemoveEdge(edges, vec[0])) {
return edges[vec[0]];
} else {
return edges[vec[1]];
}
}
// 处理情况2
// 明确没有入度为2的情况,那么一定有有向环,找到构成环的边返回就可以了
return getRemoveEdge(edges);
}
};













![【YOLOv8改进[损失函数]】使用结合InnerIoU和Focaler的各种损失函数助力YOLOv8更优秀](https://img-blog.csdnimg.cn/direct/d5a5a1ca387e4b18a78dcad4c57442d4.png)