目录
- 一、前言
- 二、概念理解
- 2.1 有序性
- 2.2 原子性
- 后果1:其它线程会读到中间态结果:
- 后果2:修改结果被覆盖
- 2.3 可见性
- 1)store buffer(FIFO)引起的类似store-load乱序现象
- 2)store buffer(非FIFO)引起的类似store-store乱序现象
- 三、CPU级别的解决方案 - 内存屏障
- 3.1 sfence(Store Barrier)
- 3.2 lfence(Load Barrier)
- 3.3 mfence(Full Barrier)
- 问题1:为什么mfence != sfence + lfence?
- 3.4 用LOCK前缀修饰指令
- 问题1:LOCK前缀指令跟mfence之间的区别是什么?
- 四、高级语言级别的解决方案 - 内存模型
- 4.1 内存模型
- 4.2 happens-before规则
- 4.3 同步事件
- 问题1:sync.Mutex和sync.atomic的区别?
- 问题2:sync.atomic的happens-before 语义是什么?
- 五、没有正确同步的代码示例及修复方法
- 六、参阅
一、前言
在并发编程中会出现的问题可以归结为三大类:有序性、原子性、可见性。
说到并发,可能会有部分小伙伴认为只有在多线程环境中,才会有并发问题,但其实不是的,在单线程多协程的环境中也会有。只要多个对象对同一个共享变量进行读写(至少有一个是写),且没有做任何的同步(Synchronization)措施,那么不管这多个对象是线程还是协程或是其它东西,不管CPU是单核的还是多核的,都会造成竞态(Race Condition)的产生,从而引发并发问题,这点一定要记住。
单线程多协程:这里
单核CPU多线程:这里
建议在阅读本文前,先了解一些基本知识点,例如现代CPU缓存架构、MESI一致性协议、store buffer、invalidate queue等,可以阅读此文了解。
如文章内容有错误,欢迎指出,共同学习进步,谢谢:)
二、概念理解
2.1 有序性
顾名思义,有序性就是确保代码按照正确顺序运行,但在计算机中却不容易做到,例如:
a = 1
b = 2
我们预期是先执行a = 1,再执行b = 1,但实际的执行过程有可能会发生乱序,即两个语句的执行顺序跟代码书写顺序不同。
乱序来自两个方面,一个是编译器优化,一个是CPU优化,两者都有可能为了提高执行效率,对指令的执行顺序进行调整,这种行为称为指令重排(Instruction Reordering)。
- 编译器优化导致的乱序称为编译器指令重排(Compiler Reordering),也叫编译期指令重排;
- CPU优化导致的乱序称为CPU指令重排(CPU Reordering),也叫运行时指令重排。
但编译器和CPU也不是随便进行指令重排的,它们只会对没有依赖关系的指令进行重排,例如这种指令就不会重排:
a = 1
b = a + 1
b的值依赖于a,所以不能改变执行顺序,否则就会出问题了。
在无并发(单线程/单协程)的环境中,指令重排不会影响程序最终的执行结果,这是编译器和CPU给的保证。但一旦到了并发环境(多线程/多协程),假设线程B的执行依赖于线程A的执行顺序,这时候如果对线程A进行指令重排就有可能导致线程B的执行结果出现问题,但编译器、CPU是无法识别出这种多线程之间的依赖关系的,所以需要另外的手段来解决。
下面看一个例子:
var a string
var done bool
func setup() {
a = "hello, world"
done = true
}
func main() {
go setup()
for !done {
}
print(a)
}
main协程期望done变为true的时候,就结束循环输出a变量(期望输出值是hello, world)。
这种期望能实现的前提是:a要在done完成赋值前完成赋值,也就是说,main协程输出正确的结果,依赖于setup协程的代码执行顺序。但可惜因为有指令重排序的存在,这个前提不一定能满足,有可能会发生:
- [setup协程] :执行
done = true; - [main协程] :结束 for 循环,执行
print(a); // a还没赋值,输出空字符串 - [setup协程] :执行
a = "hello, world";
setup协程的代码执行顺序被打乱,导致main协程输出的a变量是一个空字符串,与预期不符。
问:如果指令没有重排,完全按照书写顺序执行,那还会输出空字符串吗?
答:还是会有可能,具体见下文2.3可见性章节
这段代码除了有重排序的问题,还有可见性的问题,
for !done {}有可能会陷入死循环,具体见下文2.3可见性章节(1)。
CPU的操作指令可以分为store、load两类,例如 a = 1这种就属于store指令,所以归纳起来,乱序类型有四种:
- store-load乱序:load操作先比store操作完成
- store-store乱序(store1-store2):store2操作先比store1操作完成
- load-load乱序(load1-load2):load2操作先比load1操作完成
- load-store乱序:store操作先比load操作完成
按照可能会出现的乱序类型数量来划分,CPU的内存一致性模型大概有以下几种:
- 顺序存储模型(sequential consistency model,简写SC),没有任何乱序
- 完全存储定序(total store order,简写TSO),会出现store-load乱序
- 部分存储定序(part store order,简写PSO),会出现store-load、store-store乱序
- 宽松存储模型(relax memory order,简写RMO),四种乱序类型都会出现
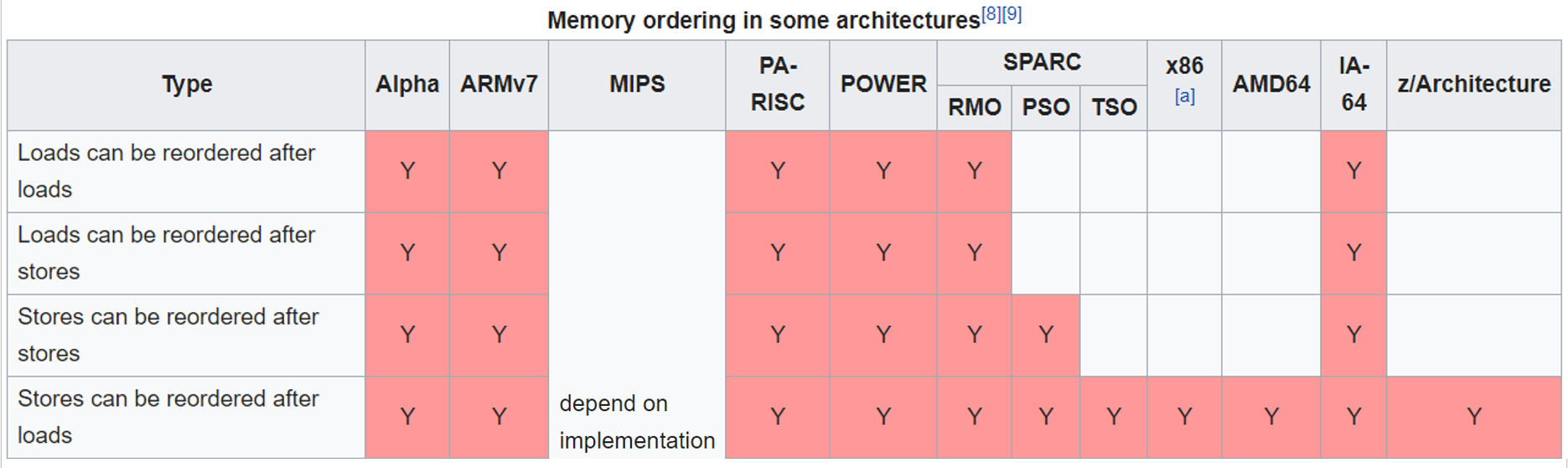
我们常用的x86架构CPU,属于TSO一致性模型,仅存在store-load乱序。
除了CPU有内存模型,高级语言也会有自己的内存模型。
但要注意的是,即使CPU没有对指令进行重排序,最终也仍有可能会出现乱序现象。例如CPU严格按照 store -> load 的顺序执行指令,但因为有 store buffer 的存在,store操作有可能会延迟一段时间才刷出到cache,而MESI一致性协议的作用范围是各级cache,不包括store buffer,只有刷出到cache其它CPU才能读到新的值,因此从cache的视角看,事件顺序有可能会变成 load -> store,具体见下文2.3可见性章节。
通过本节,我们知道:
- 编译器、CPU有可能会为了提高性能,对指令的执行顺序进行调整
- 在单线程环境下,指令乱序执行不会影响程序最终结果,但在多线程环境下就不保证了
- CPU只会对没有依赖关系的指令进行重排序
- 影响指令执行顺序的因素有很多,编译器优化策略、CPU优化策略、CPU架构等等
- 即使不对指令进行重排序,仍有可能会出现类似重排序的现象
2.2 原子性
原子性指的是一个或多个操作要么全部执行成功,要么全部执行失败,而且其它线程不能读取到中间态结果。
先看看如果一个操作不是原子性的,会发生什么后果。
后果1:其它线程会读到中间态结果:
type UserInfo struct {
Name string
}
var instance *UserInfo
func main() {
instance = &UserInfo{Name: "tim"}
}
instance = &UserInfo{Name: "tim"}这句代码看起来只有一句,但实际执行起来并不是原子性的,它分为多个步骤:
- 先 new 一个
UserInfo - 然后设置
Name="tim" - 最后把 new 的对象赋值给
instance
既然不是原子性的,那么就给“指令重排”提供了机会,上面的执行步骤可能会重排成:
- 先 new 一个
UserInfo - 然后把 new 的对象赋值给
instance - 最后设置
Name="tim"
假设这段代码是线程A在执行,在执行完第2个步骤后,突然线程B来访问这个instance,这时候线程B读取到的instance.Name将会是个空字符串(因为线程A的第3步还没执行),线程B读取到了一个中间态的结果。
后果2:修改结果被覆盖
假设有变量count,现在我们要对其执行count++操作,它也不是原子性的,分为三个步骤:
- 读取变量
count所在的cache line到CPU寄存器 - 执行
+1操作 - 将
+1后的结果回写到L1缓存的cache line(不考虑store buffer)
这个过程称为 RMW (Read-Modify-Write),假设现在有两个线程同时执行count++操作:

可见,最后count的值并不是预期的2,而是1。
上面是两个线程并行(两个线程在不同的CPU核心上运行)的结果,如果让他们变成并发(两个线程在同一个CPU核心运行),由于CPU是抢占式调度线程的,在线程A执行到一半的时候,可能会被切换去执行线程B,所以最终仍会导致同样的结果。
思考下,如果我们要解决上述原子性问题,至少要做哪些工作?
以i++举例,让它原子化至少要确保:
- 计算开始前,要读取到最新的
i值 i所在的cache区域要独占,如果其它CPU核心有相同的cache副本,要让它们变为无效- 从开始到结束期间,其它线程不能读写
i所在的cache区域(类似加互斥锁),即各个原子操作要串行化 - 计算结束后,要把新的值刷出到cache,然后借助MESI一致性协议,让其它CPU核心能看到新的值
下面第三章讲述的LOCK前缀指令能实现这些要求,所以LOCK前缀指令可以帮我们实现原子操作。
2.3 可见性
可见性问题是由 store buffer 和 invalidate queue引出的。
store buffer的引入,使得Store操作的结果不能及时被其它CPU核心发现,这种称为可见性问题。
而 invalidate queue 的引入则更加加剧了这种现象,导致即使CPU已经将store buffer全部刷出到cache,其它CPU核心依然有可能发现不了新的值。
- store buffer 和 invalidate queue 只有本地核心可以访问,其它CPU核心访问不到
- 从缓存中读取cache line时,会优先检索本地store buffer中有没有相同的cache line,有的话直接从store buffer获取(这种优化策略称为Store-Buffer Forwarding),但不会优先检索invalidate queue
- 如果cache line在缓存里的状态是独占(M或者E),则CPU会直接将结果写入到cache,而不是先写入到store buffer
- 如果将结果写入store buffer,则会广播invalidate消息(cache line的状态暂时不变),收到各个核心的invalidate ack响应后,才会将store buffer里的暂存结果刷出到cache(状态改为M)
- 将结果写入cache时,如果cache line已经失效,会重新读取cache line(发起read invalidate请求),读取后将结果写入,状态改为M
问:既然store buffer不与其它CPU核心共享,那线程A写入store buffer后,被系统调度到其它核心运行了,此时怎么同步store buffer到其它核心?
答:这种情况不需要程序员担心,操作系统会帮我们处理好数据的同步。参阅这里
1)store buffer(FIFO)引起的类似store-load乱序现象
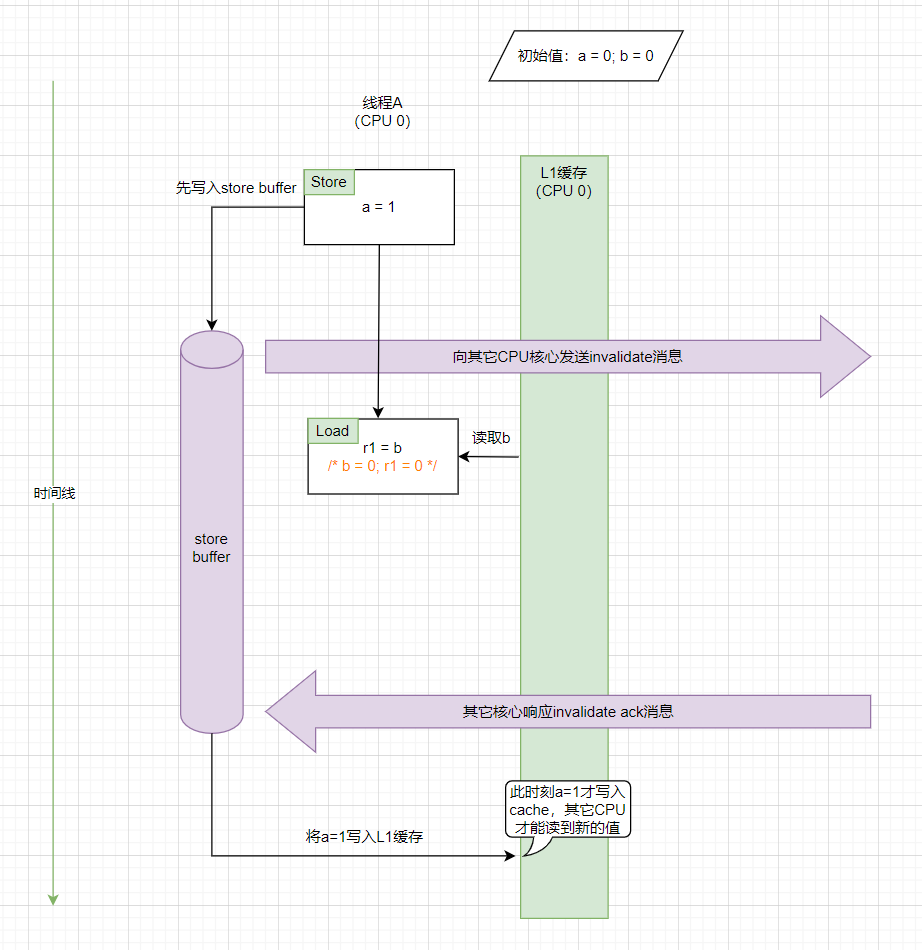
从时间线上来看,我们看到是先发生了store操作(将a修改为1),然后才发生的load操作(读取b)。但是因为有store buffer的存在,a = 1是在load操作后面才写入到L1缓存的(写入到缓存后其它CPU核心才能读取到新的值),假设我们设定“写入到缓存”才算真正的完成store操作,那么从cache的视角看,此时就发生了store-load乱序:load操作先比store操作完成了。
注意,这里CPU和编译器并没有对指令进行重排序,但还是出现了重排序的现象,这种称为内存重排序(Memory Reordering),要注意跟其它两种重排序区分(CPU重排序、编译器重排序)
因 store buffer 和 invalidate queue 产生的可见性问题,一般不会持续太久,因为store buffer终究会刷出到cache,invalidate queue终究会被消费清空。
比较可怕的是编译器的激进优化,例如上文2.1章节第一个代码示例中的for !done {}这个循环,编译器可能会优化成:读取done变量到CPU寄存器后,就一直使用寄存器里的值,即使你在其它线程将done由false修改为true,CPU也不会从cache里重新读取新的值,导致循环不会终止。
2)store buffer(非FIFO)引起的类似store-store乱序现象
上一个例子里的store buffer是FIFO(first in first out)的,如果改成非FIFO,会多出一种store-store乱序现象。
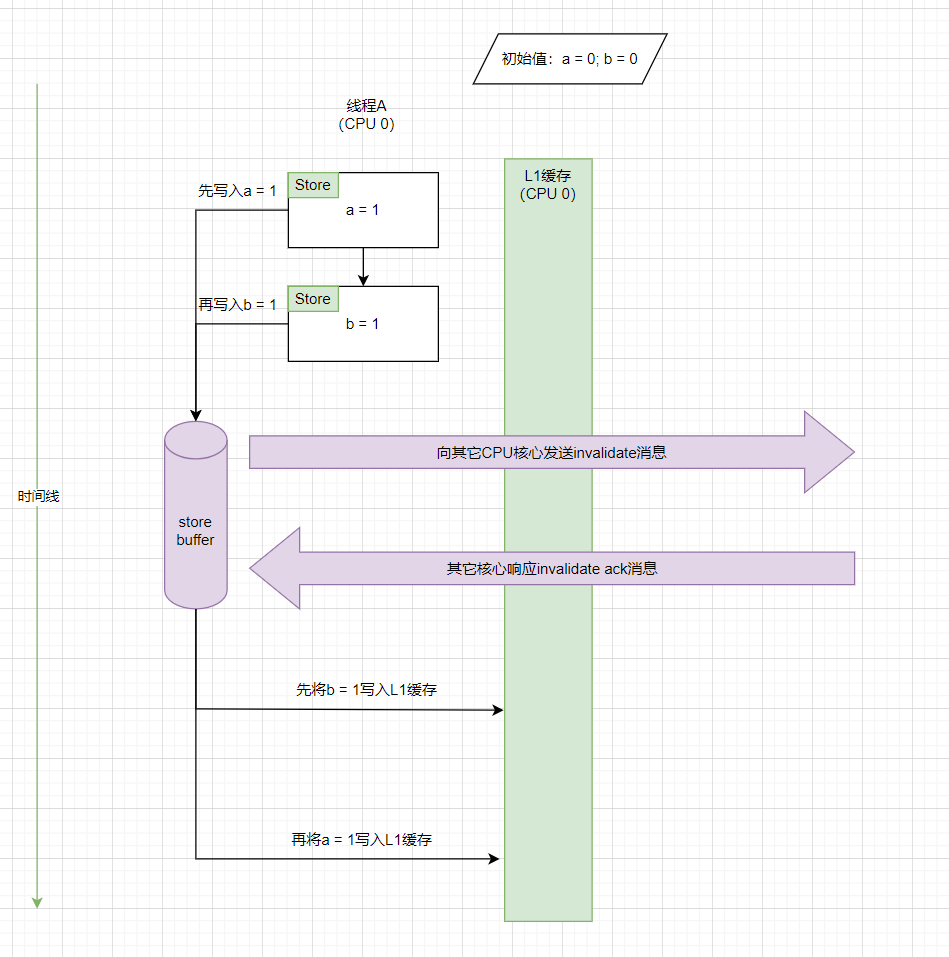
从时间线上来看,是先发生store1操作(a = 1),然后再发生store2操作(b = 1)。但是因为store buffer非FIFO的特性,导致store2操作先写入到了缓存,然后才写入store1。从cache的视角看,发生了类似store-store乱序的现象。
三、CPU级别的解决方案 - 内存屏障
要解决CPU的各种乱序、可见性问题,需要用到硬件级别的内存屏障(Memory Barrier)。
内存屏障的作用:
- 防止屏障前后的指令越过屏障,导致重排序
- 保证数据的可见性
不同架构的CPU会提供不同的内存屏障指令,比如 Intel x86架构的CPU就提供了以下四种内存屏障指令。
3.1 sfence(Store Barrier)
- sfence 前面的 store 操作不会被调度到 sfence 后面
- sfence 后面的 store 操作不会被调度到 sfence 前面
- 清空store buffer,全部刷出到主内存(注意是主内存,不是cache),使 sfence 前面的所有store操作变成全局可见
3.2 lfence(Load Barrier)
- lfence 前面的 load 操作不会被调度到 lfence 后面
- lfence 后面的 load 操作不会被调度到 lfence 前面
- 清空 invalidate queue,使得 lfence 后面的 load 操作可以读到最新的cache值
3.3 mfence(Full Barrier)
- mfence 前面的 store 操作不会被调度到 mfence 后面,后面的 store 操作不会被调度到 mfence 前面
- mfence 前面的 load 操作不会被调度到 mfence 后面,后面的 load 操作不会被调度到 mfence 前面
- 清空store buffer,全部刷出到主内存(注意是主内存,不是cache),使 mfence 前面的所有store操作变成全局可见
- 清空 invalidate queue,使得 mfence 后面的 load 操作可以读到最新的cache值
问题1:为什么mfence != sfence + lfence?
因为 sfence 和 lfence 本身就有可能乱序,例如:
mov addr, eax // 将eax寄存器中的数据保存到内存地址addr,属于store操作
sfence
lfence
mov eax, addr // 将内存地址addr的数据加载到eax寄存器中,属于load操作
最终的执行顺序有可能会变成:
lfence
mov eax, addr // load
mov addr, eax // store
sfence
可见,lfence 和 sfence 在此处已经发挥了它的作用,store操作没有跑到 sfence 的后面去,load操作也没有跑到 lfence 的前面去,但是 store-load 的执行顺序却变成了load-store,产生了乱序,因此,阻止 store-load 乱序只能用 mfence。
3.4 用LOCK前缀修饰指令
在一条指令前面添加LOCK前缀,可以使这条指令的执行具有原子性,支持使用LOCK前缀的指令有ADD/OR/AND/SUB/INC/NOT等,另外XCHG/XADD自带LOCK效果。
具体做法是在执行指令前,向CPU发出LOCK#信号,CPU接收到LOCK#信号后,会锁定总线,锁定期间其它CPU均不能通过总线访问内存,性能开销比较大。
后来又增加了只锁定cache line的功能,开销相比锁定总线小了很多,但是锁定cache line要符合一定的条件,如果不符合条件,会降级为锁定总线。
锁定流程见下图:
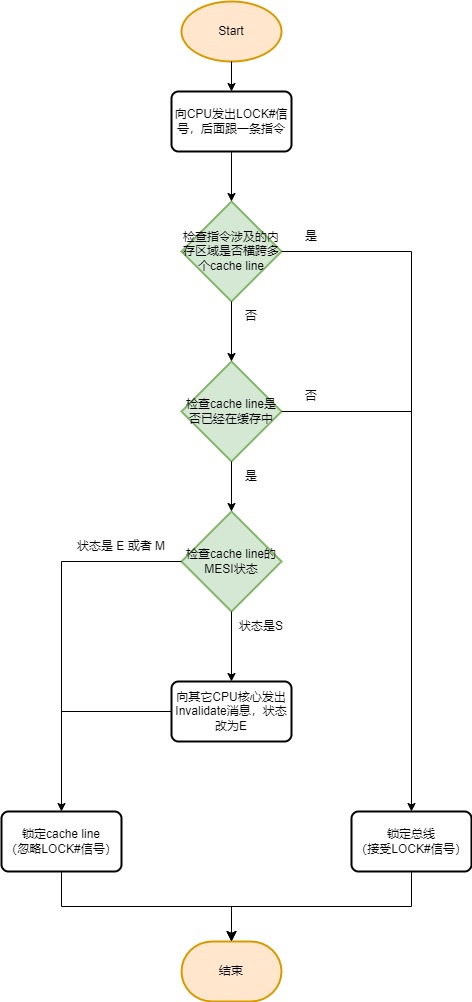
锁定总线或cache line后:
- 其它线程不可再读写已锁定的内存区域,直至锁定结束,可以确保指令执行的原子性;
- 禁止该指令前后的指令重排序,类似mfence内存屏障的作用,可以确保指令执行的有序性;
- 锁定结束后,还会将store buffer刷出到cache,确保变量修改后的可见性;
问题1:LOCK前缀指令跟mfence之间的区别是什么?
mfence要求修改过的值必须要写回到主内存,仅写回到cache是不行的,这样才能做到全局可见(不仅仅是CPU各个核心可见,还要求其它设备可见,比如显卡);
而LOCK前缀指令结束后,修改后的新值写回到cache就可以,没有强制要求写回到主内存。
Golang的 sync.atomic 包里的方法就用到了LOCK前缀指令,不要看到atomic这个单词,就以为这些方法只能确保原子性,其实它还能确保有序性、可见性。
除了CPU级别的内存屏障,还有编译器级别的内存屏障
四、高级语言级别的解决方案 - 内存模型
4.1 内存模型
我们从上一章节得知,单单x86架构的CPU就有4种内存屏障指令,如果加上其它架构的,各种指令就五花八门了,如果让程序员直接使用CPU级别的内存屏障的话,学习成本会很高,很难写出跨平台的程序。因此 Golang 给我们设计了一套内存模型,内存模型屏蔽了底层CPU的细节,优点:
- 免去程序员使用内存屏障的心智负担,更加容易开发出跨平台的程序;
- Golang在底层会帮我们合理正确的使用内存屏障,在保障有序性、原子性、可见性的同时,对程序性能也不会有太大的影响;
内存模型定义了在什么情况下,可以确保协程B可以读取到协程A对共享变量v写入的值,这里的“什么情况”指的是 happens-before 规则,我们只需要写出满足 happens-before 规则的代码,剩下的其它什么有序性、可见性问题内存模型会帮我们处理好。
4.2 happens-before规则
单纯看字面意思,happens-before是用于描述两件事的发生顺序的,但其实它还暗含着可见性的规定,这一点一定要注意。
举例,事件e1 happens-before e2,它的含义是:
e1事件发生在e2事件之前(有序性)e1事件的操作结果,对于e2可见(可见性)
happens-before还有传递性的特点,如果用>符号表示happens-before,那么有以下关系:
如果 A < B,C < D,且 B < C,那么 A < D
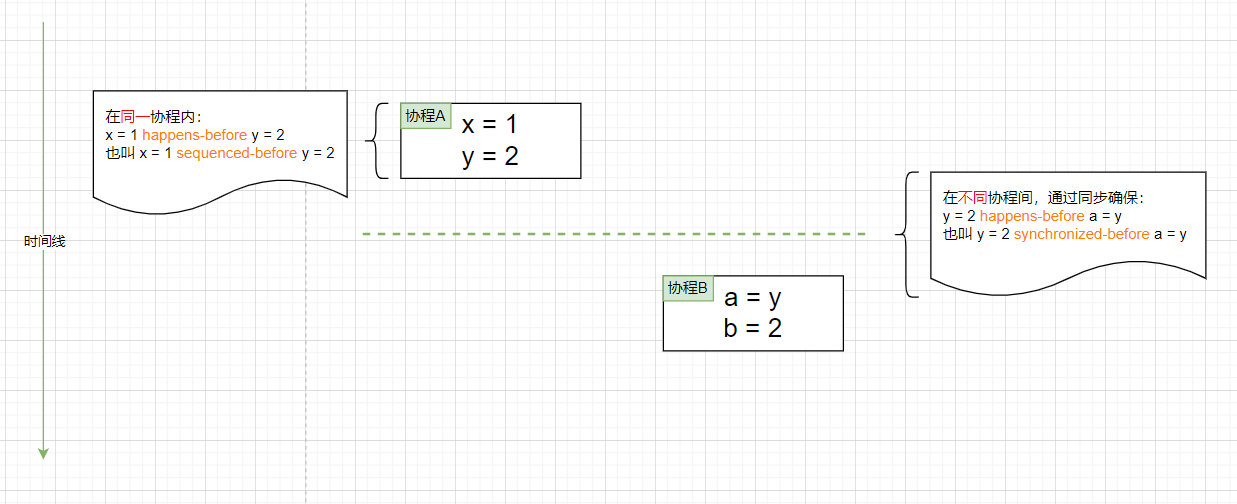
happens-before下面又细分为 sequenced-before 和 synchronized-before 两种类型,同一协程内的 happens-before 称为 sequenced-before,不同协程间的 happens-before 称为 synchronized-before,见上图。
在只有一个 Go协程的内部,sequenced-before的顺序就是代码的书写顺序。当协程不止一个时,例如协程1和协程2共同读写一变量v,协程1负责读(事件r),协程2负责写(事件w),要想确保协程1能读到协程2写入的值,需要满足:
wsynchronized-beforer- 在
w和r之间不允许有其它对同一变量v写入的事件发生
4.3 同步事件
Golang的内存模型已经为我们定义好了一些同步事件,例如channel、Locks、Atomic Values等等,同时Golang承诺这些同步事件遵守 hanppens-before 规则,我们只需应用好这些事件即可。
这些事件不再详细赘述,网上资料较多,可参阅这些文章:
- Golang 并发编程核心—内存可见性
- The Go Memory Model
- Memory Order Guarantees in Go
问题1:sync.Mutex和sync.atomic的区别?
相同点:
- 两者均能保证原子性、有序性、可见性
差异点:
- atomic只能保护单个变量修改的原子性,而Mutex可用于保护一段代码(临界区)的原子性
- atomic使用的是LOCK前缀指令(CPU级别的锁)来确保原子性,而Mutex是语言级别的高级锁,实现中也使用到了atomic
- 一般来说,atomic的性能要比Mutex高
参阅Understanding Golang’s Atomic Package and Mutexes
问题2:sync.atomic的happens-before 语义是什么?
Since Go 1.19, the Go 1 memory model documentation formally specifies that all atomic operations executed in Go programs behave as though executed in some sequentially consistent order. If the effect of an atomic operation A is observed by atomic operation B, then A is synchronized before B.
五、没有正确同步的代码示例及修复方法
后面补充…
六、参阅
- X86 平台 volatile 与 StoreLoad 乱序描述与验证
- Why is (or isn’t?) SFENCE + LFENCE equivalent to MFENCE?
- 聊聊原子变量、锁、内存屏障那点事
- Locks实现:背后不为人知的故事
- Lock前缀指令带来的缓存行锁定有什么作用?