Kafka、RabbitMQ、Pulsar、RocketMQ基本原理和选型
- 1. 消息队列
- 1.1 消息队列使用场景
- 1.2. 消息队列模式
- 1.2.1 点对点模式,不可重复消费
- 1.2.2 发布/订阅模式
- 2. 选型参考
- 2.1. Kafka
- 2.1.1 基本术语
- 2.1.2. 系统框架
- 2.1.3. Consumer Group
- 2.1.4. 存储结构
- 2.1.5. Rebalance
- 2.1.6.优点
- 2.1.7. 缺点
- 2.1.8. 使用场景
- 2.2. RabbitMQ
- 2.2.1. 基本术语
- 2.2.2. 系统框架
- 2.2.3. ExchangeType
- 2.2.4. 优点
- 2.2.5. 缺点
- 2.2.6. 总结
- 2.3. Pulsar
- 2.3.1. 基本术语
- 2.3.2. 系统框架
- 2.3.3. 存储计算分离/分片存储
- 2.3.4. 读写分离
- 2.3.5. 消息确认
- 2.3.6. 延时消息
- 2.3.7. 跨地域复制
- 2.3.8. 优点
- 2.4. RocketMQ
- 2.4.1. 基本术语
- 2.4.2. 系统框架
- 2.4.3. 优点
- 2.4.4 缺点
- 2.4.5 使用场景
- 3. 疑问和思考
- 4. 参考文档
1. 消息队列
1.1 消息队列使用场景
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,削峰填谷等问题。实现高性能、高可用、可伸缩和最终一致性架构。
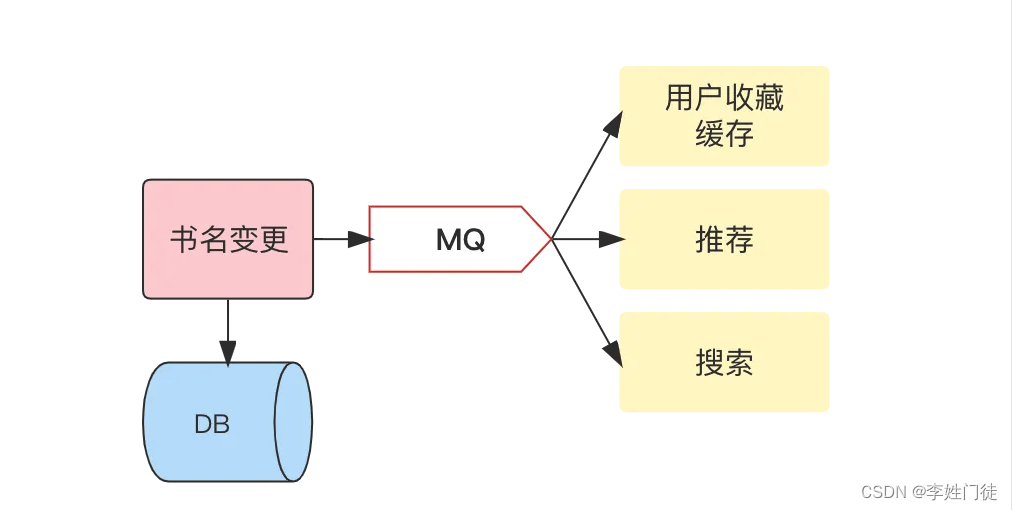
使用消息队列能够获得如下好处,能够在应用与应用之间降低依赖和实时性要求。
- 解耦:多个服务监听、处理同一条消息,避免多次rpc调用
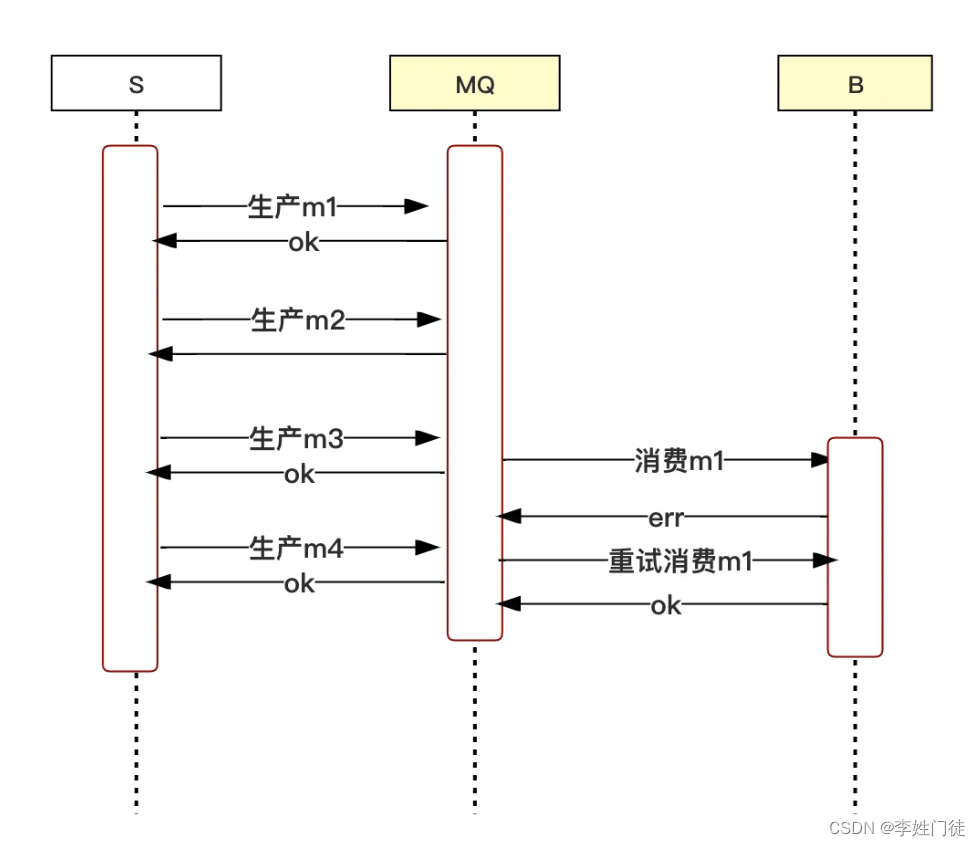
- 异步消息:消息发布者不用等待消息处理的的结果
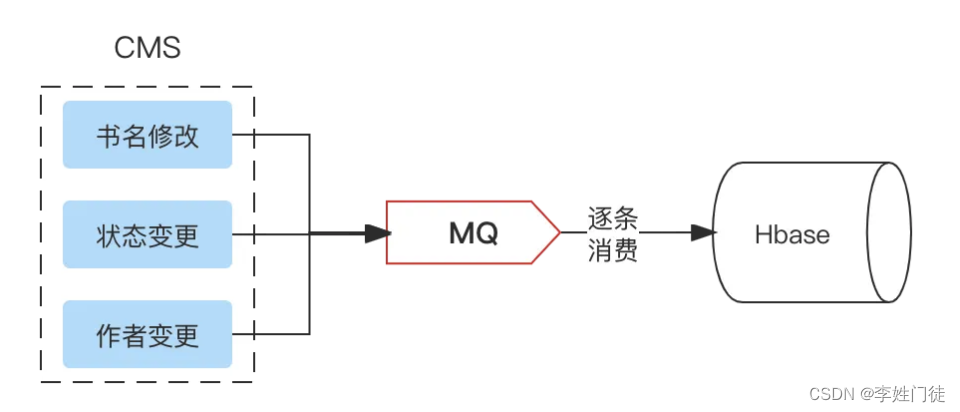
- 削峰填谷:较大流量、写入场景,为下游I/O服务抗流量。当然大流量下就需要使用其他方案了
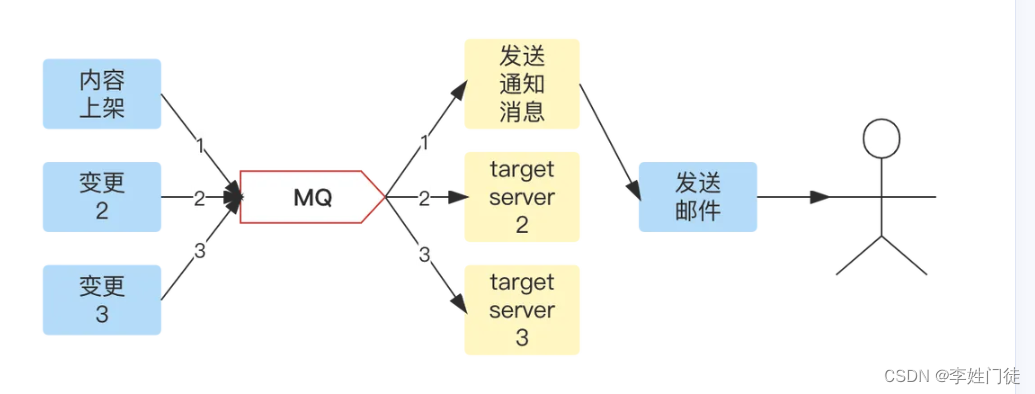
- 消息驱动框架:在事件总线中,服务通过监听事件消息驱动服务完成相应动作。
1.2. 消息队列模式
1.2.1 点对点模式,不可重复消费
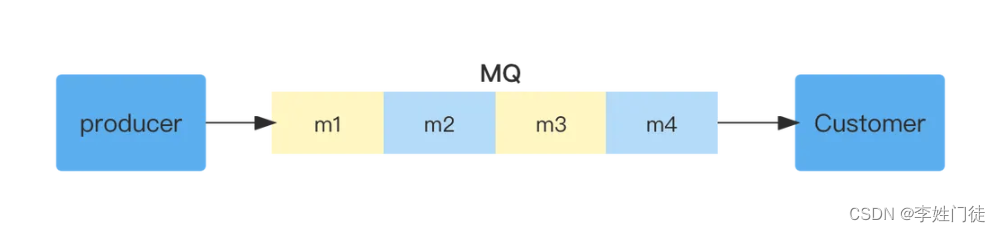
多个生产者可以向同一个消息队列发送消息,一个消息在被一个消息者消费成功后,这条消息会被移除,其他消费者无法处理该消息。如果消费者处理一个消息失败了,那么这条消息会重新被消费。
1.2.2 发布/订阅模式
发布订阅模式需要进行注册、订阅,根据注册消费对应的消息。多个生产者可以将消息写到同一个Topic中,多种消息可以被同一个消费者消费。一个生产者生产的消息,同样也可以被多个消费者消费,只要他们进行过消息订阅。
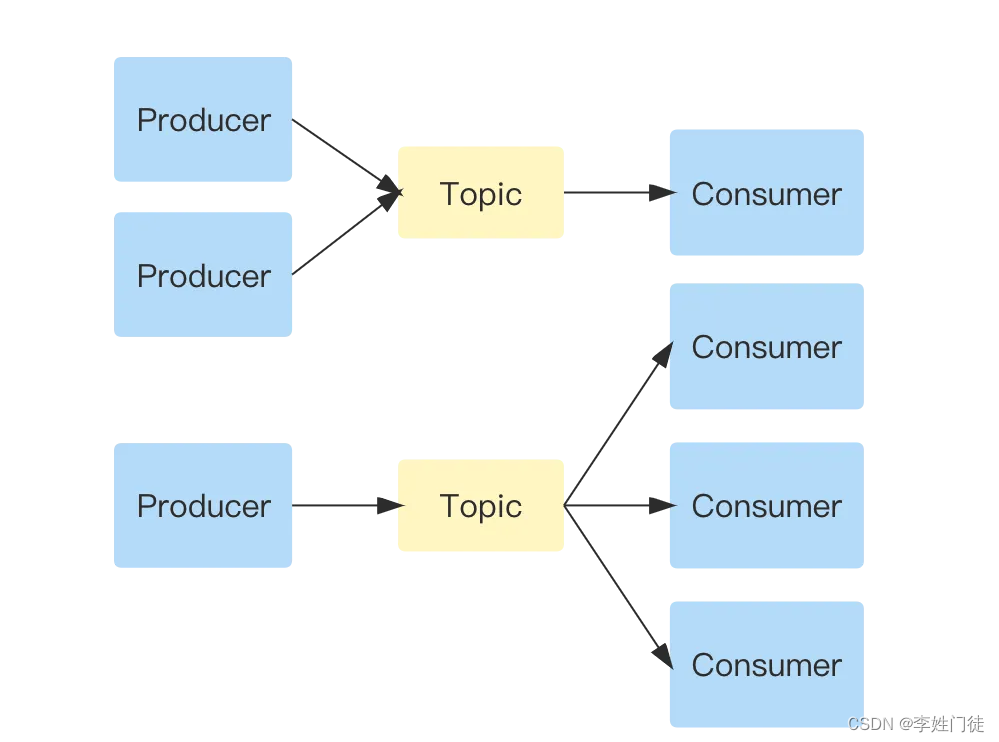
2. 选型参考
- 消息顺序:发送到队列的消息,消费时是否可以保证消费的顺序;
- 伸缩:当消息队列性能有问题,比如消费太慢,是否可以快速支持扩容;当消费队列过多,浪费系统资源,是否可以支持缩容。
- 消息留存:消息消费成功后,是否还会继续保留在消息队列。
- 容错性:当一条消息消费失败后,是否有一些机制,保证这条消息是一定能成功,比如异步第三方退款消息,需要保证这条消息消费掉,才能确定给用户退款成功,所以必须保证这条消息消费成功的准确性。
- 消息可靠性:是否会存在丢消息的情况,比如有A/B两个消息,最后只有B消息能消费,A消息丢失;
- 消息时序:主要包括“消息存活时间”和“延迟消息”;
- 吞吐量:支持的最高并发数;
- 消息路由:根据路由规则,只订阅匹配路由规则的消息,比如有A/B两者规则的消息,消费者可以只订阅A消息,B消息不会消费。
2.1. Kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。 该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。 其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。(维基百科)
2.1.1 基本术语
-
Producer:消息生产者。一般情况下,一条消息会被发送到特定的主题上。通常情况下,写入的消息会通过轮询将消息写入各分区。生产者也可以通过设定消息key值将消息写入指定分区。写入分区的数据越均匀Kafka的性能才能更好发挥。
-
Topic:Topic是个抽象的虚拟概念,一个集群可以有多个Topic,作为一类消息的标识。一个生产者将消息发送到topic,消费者通过订阅Topic获取分区消息。
-
Partition:Partition是个物理概念,一个Topic对应一个或多个Partition。新消息会以追加的方式写入分区里,在同一个Partition里消息是有序的。Kafka通过分区,实现消息的冗余和伸缩性,以及支持物理上的并发读、写,大大提高了吞吐量。
-
Replicas:一个Partition有多个Replicas副本。这些副本保存在broker,每个broker存储着成百上千个不同主题和分区的副本,存储的内容分为两种:master副本,每个Partition都有一个master副本,所有内容的写入和消费都会经过master副本;follower副本不处理任何客户端的请求,只同步master的内容进行复制。如果master发生了异常,很快会有一个follower成为新的master。
-
Consumer:消息读取者。消费者订阅主题,并按照一定顺序读取消息。Kafka保证每个分区只能被一个消费者使用。
-
Offset:偏移量是一种元数据,是不断递增的整数。在消息写入时Kafka会把它添加到消息里。在分区内偏移量是唯一的。消费过程中,会将最后读取的偏移量存储在Kafka中,消费者关闭偏移量不会丢失,重启会继续从上次位置开始消费。
-
Broker:独立的Kafka服务器。一个Topic有N个Partition,一个集群有N个Broker,那么每个Broker都会存储一个这个Topic的Partition。如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
2.1.2. 系统框架
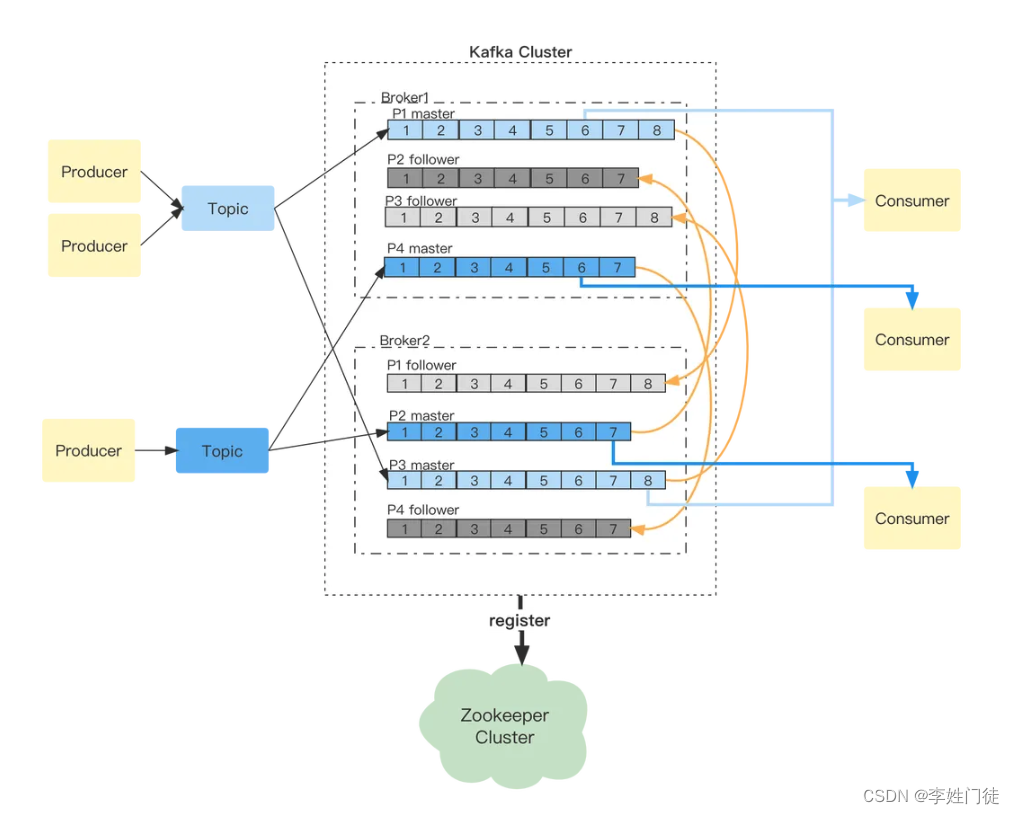
第一个topic有两个生产,新消息被写入到partition 1或者partition 2,两个分区在broker1、broker2都有备份。有新消息写入后,两个follower分区会从两个master分区同步变更。对应的consumer会从两个master分区根据现在offset获取消息,并更新offset。 第二个topic只有一个生产者,同样对应两个partition,分散在Kafka集群的两个broker上。有新消息写入,两个follower分区会同步master变更。两个Consumer分别从不同的master分区获取消息。
2.1.3. Consumer Group
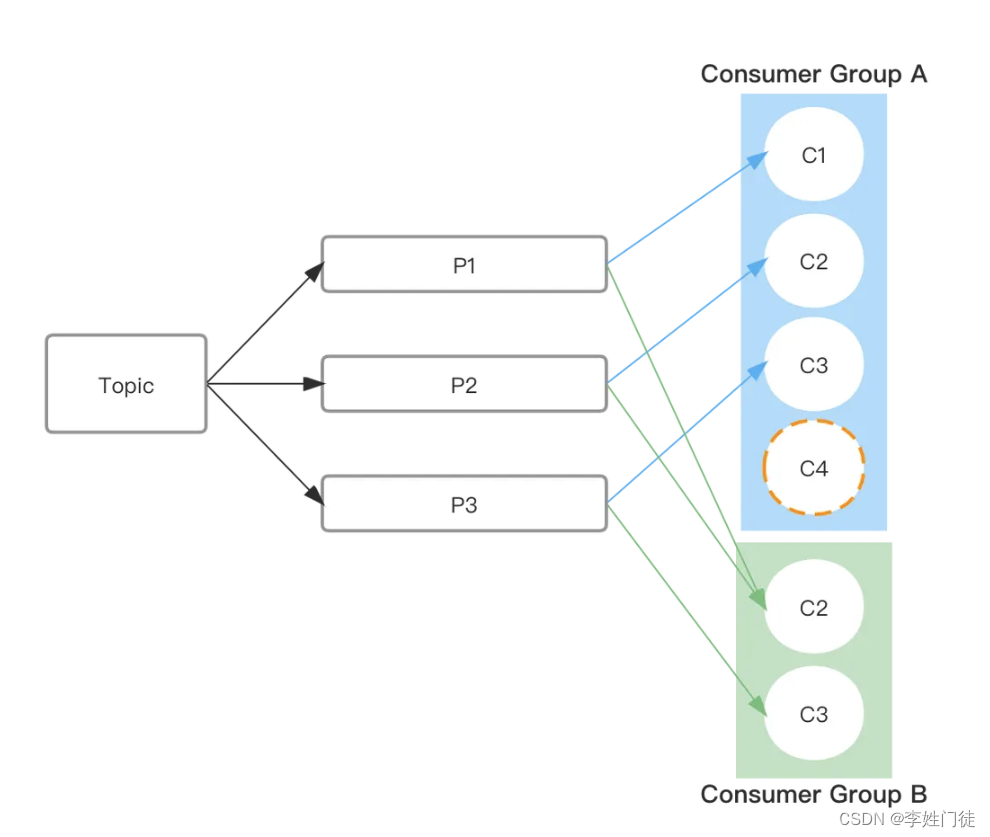
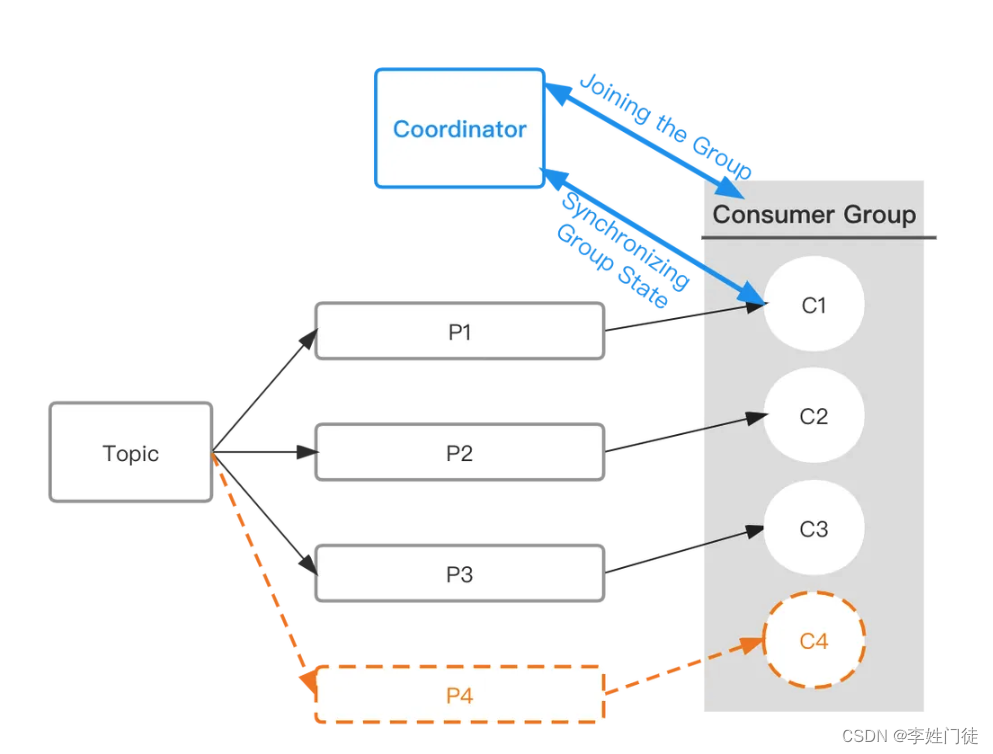
一个Group可以包含一个或多个consumer实例。Consumer实例可以是一个进程也可以是一个线程;每个Group都有一个全局唯一的GroupID。图中Topic有3个分区p1、p2、p3,三个分区的消息总和就是Topic的全量消息。 GroupA有3个消费实例,GroupB有两个消费实例,这种情况下恰好每个消费实例都能拿到数据。如果这时给GroupA增加一个消费实例C4,C1-C4有一个收不到消息。
一个partition最多只能给1个consumer进行消费 。
仔细思考如上的问题,能够发现如下逻辑。
因为kafka的数据只能在partition级别有序,所有的partition的数据之合组成topic的所有数据,每个partition的数据不同(partition副本不纳入考虑)。因此如果一个partition可以被多个consumer消费数据,就会面临2个选择
-
多个consumer消费的数据有重复
这种设计模式,显然不能满足业务的要求,并且由于不同的consumer能够消费到重复的数据,consumer之间需要进行数据去重处理,但是哪些数据重复是不确定的,因此consumer之间的数据去重逻辑可能很复杂,实现代价很高,因此这不是一个好的设计 -
多个consumer消费的数据不重复,所有consumer消费的数据组成一个partition的所有数据
仔细阅读发现,这种实现方式的语义和consumer groups是一样的,重复设计了。
因此在设计上,不允许单个partition被多个consumer消费。
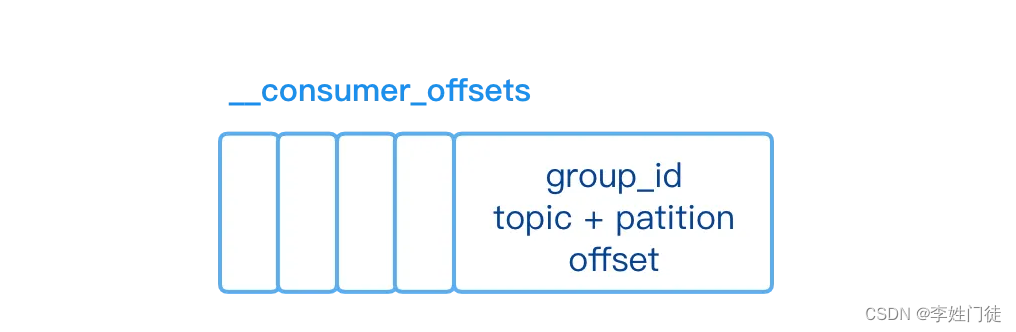
Consumer消费的进度由Kafka的服务器记录,对应结构_consumer_offsets,分别由group_id、topic、partition、offset组成。它分别记录着每个Consumer Group中的每个Consumer实例。可以看出一个Topic下的同一分区在相同的Group下只能对应一个Consumer实例。
消费阻塞? 。
- 消费力不足导致的消息积压,需要同事对分区和consumer实例进行扩容;
- 消息key导致的分区数据不均衡,需要根据业务对消息的key值进行优化。
2.1.4. 存储结构
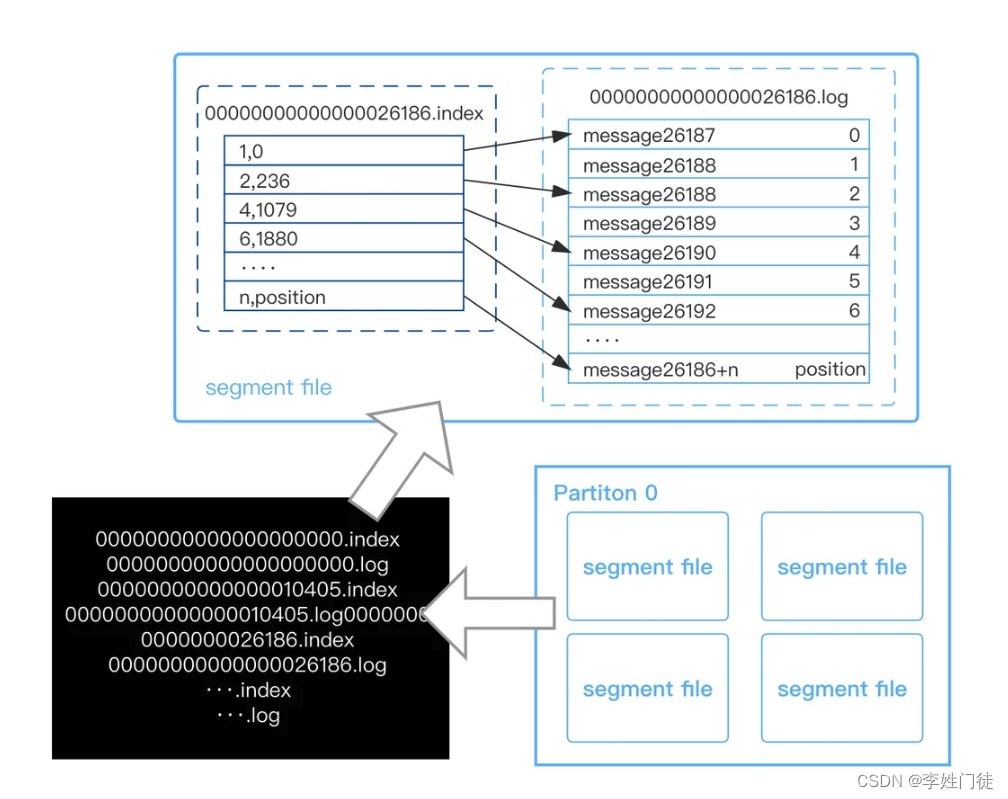
kafka的消息一分区为单位存储在Broker上,分区由多个段组成(segment)。每个分区相当于一个巨型文件,被平均分配到多个大小相等的段中。每个段文件消息数量不一定相等。这样的好处就是能快速删除无用文件,提高磁盘利用率。
段文件由两部分组成,,index文件和.log文件,这两类文件一一对应。段文件命名规则:Partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。 以索引文件中2,139为例,依次在数据文件中表示第2个消息,全分区第26188个消息、物理偏移地址为139。
查找offset为26187的消息,先根据段文件命名规则,查找到命名为26186段文件,再在26186的.log文件中顺序查找offset=26187的数据。
2.1.5. Rebalance
kafka会为每个Consumer实例分配1个分区。这个分配的过程就是Rebalance。
Rebalance触发条件有三个:
- 组成员个数发生变化;
- 订阅的 Topic个数发生变化;
- 订阅Topic的分区数发生变化。
Rebalance过程分两步:
-
第一步JoinGroup:
所有消费成员都向协调者发送请求加入消费组。一旦所有成员都发送了JoinGroup请求,coordinator会从申请加入的成员里选一个担任leader的角色,并把组成员信息以及订阅信息发给leader角色 -
第二步SyncGroupleader:
分配消费方案,也就是consumer负责消费哪些topic的哪些partition。完成分配leader会将方案封装进SyncGroup请求中发给协调者。非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案后,会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。
Rebalance 发生时,kafka为了能够保证尽量达到最公平的分配,过程中Consumer Group下的所有消费者实例都会停止工作,直到Rebalance过程完成。对实际业务有很大影响。
每个Consumer 实例都会定期地向coordinator 发送心跳请求,如果不能及时地发送心跳请求,coord协调者就会认为这个Consumer 已经宕机 了,把它 Group中移除然后开启新一轮Rebalance。可以通过合理的设置心跳检测的过期时间,consumer发送心跳请求的频率,以及合理预估业务消费耗时。
为什么要进行rebalance?
- 本质上是因为消费者的相关元数据发生了变化,为了平衡数据消费(增加新状态或者剔除异常状态),从而进行热加载
- 在进行热加载(rebalance)过程中,难以做到只调整受到影响的部分状态,因此整体consumer group暂停消费,等调整完成了再进行消费
2.1.6.优点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性:kafka集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点故障,一个数据多个副本,少数机器宕机,不会丢失数据;
- 高并发:支持数千个客户端同时读写。
2.1.7. 缺点
- 分区有序:仅在同一分区内保证有序,无法实现全局有序;
- 无延时消息:消费顺序是按照写入时的顺序,不支持延时消息
- 重复消费:消费系统宕机、重启导致offset未提交;
- Rebalance:Rebalance的过程中consumer group下的所有消费者实例都会停止工作,等待Rebalance过程完成。
2.1.8. 使用场景
- 日志收集:大量的日志消息先写入kafka,数据服务通过消费kafka消息将数据落地;
- 消息系统:解耦生产者和消费者、缓存消息等;
- 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
- 运营指标:记录运营、监控数据,包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理:比如spark streaming
2.2. RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件(英语:Message-oriented middleware))。RabbitMQ服务器是用Erlang语言编写的,而群集和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端函式库。(维基百科)
2.2.1. 基本术语
- Broker:接收客户端链接实体,实现AMQP消息队列和路由功能;
- Virtual Host:是一个虚拟概念,权限控制的最小单位。一个Virtual Host里包含多个Exchange和Queue;
- Exchange:接收消息生产者的消息并将消息转发到队列。发送消息时根据不同ExchangeType的决定路由规则,ExchangeType常用的有:direct、fanout和topic三种;
- Message Queue:消息队列,存储为被消费的消息;
- Message:由Header和Body组成,Header是生产者添加的各种属性,包含Message是否持久化、哪个MessageQueue接收、优先级。Body是具体的消息内容;
- Binding:Binding连接起了Exchange和Message Queue。在服务器运行时,会生成一张路由表,这张路由表上记录着MessageQueue的条件和BindingKey值。当Exchange收到消息后,会解析消息中的Header得到BindingKey,并根据路由表和ExchangeType将消息发送到对应的MessageQueue。最终的匹配模式是由ExchangeType决定;
- Connection:在Broker和客户端之间的TCP连接;
- Channel:信道。Broker和客户端只有tcp连接是不能发送消息的,必须创建信道。AMQP协议规定只有通过Channel才能执行AMQP命令。一个Connection可以包含多个Channel。之所以需要建立Channel,是因为每个TCP连接都是很宝贵的。如果每个客户端、每个线程都需要和Broker交互,都需要维护一个TCP连接的话是机器耗费资源的,一般建议共享Connection。RabbitMQ不建议客户端线程之前共享Channel,至少保证同一Channel发小消息是穿行的。
- Command:AMQP命令,客户端通过Command来完成和AMQP服务器的交互。
2.2.2. 系统框架
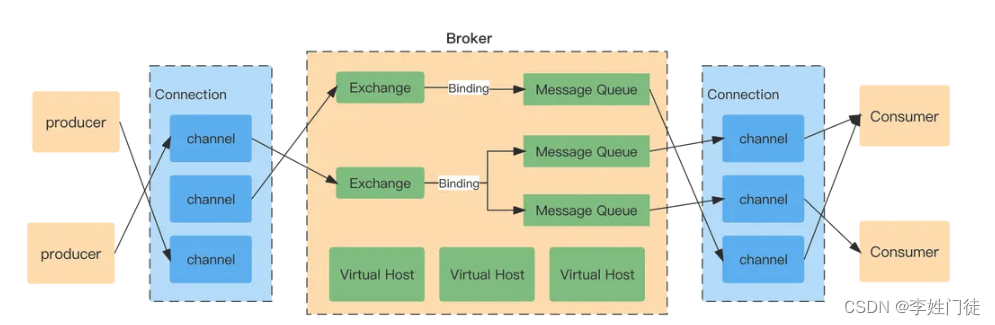
一条Message经过信道到达对应的Exchange,Exchange收到消息后解析出消息Header内容,获取消息BindingKey并根据Bindingh和ExchangeType将消息转发到对应的MessageQueue,最后通过Connection将消息传送的客户端。
2.2.3. ExchangeType
-
Direct:精确匹配
-
只有RoutingKey和BindingKey完全匹配的时候,消息队列才可以获取消息。
-
Broker默认提供一个Exchange,类型是Direct名字是空字符串,绑定到所有的Queue(这里通过Queue名字来区分)

-
-
Fanout:订阅、广播
- 这个模式会将消息转发到所有的路由的Queue中
-
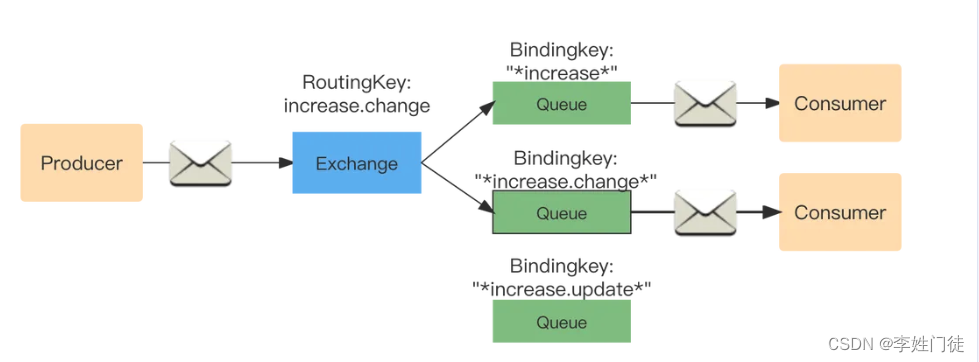
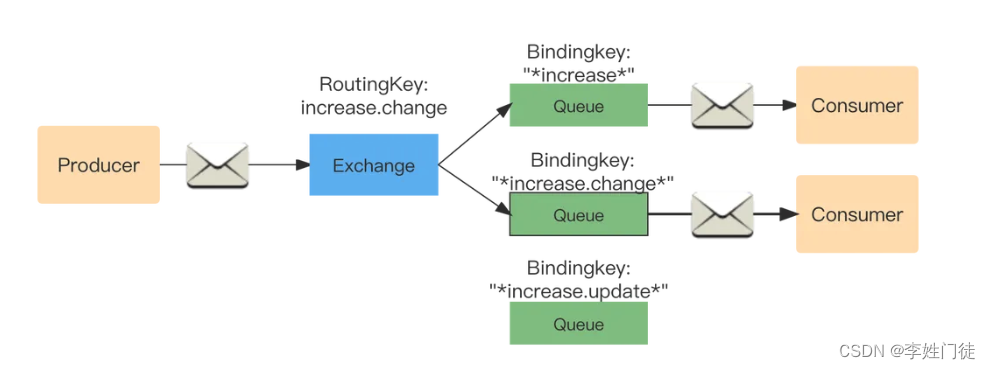
Topic:通配符模式
- RoutingKey为一个句点号“. ”分隔的字符串(将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“quick.orange.rabbit”。BindingKey与RoutingKey一样
- Bindingkey中的两个特殊字符"#"和“”用于模糊匹配,“#”用于匹配多个单次,“”用来匹配单个单词(包含零个)
2.2.4. 优点
基于AMQP协议:除了Qpid,RabbitMQ是唯一一个实现了AMQP标准的消息服务器;
- 健壮、稳定、易用;
- 社区活跃,文档完善;
- 支持定时消息;
- 可插入的身份验证,授权,支持TLS和LDAP;
- 支持根据消息标识查询消息,也支持根据消息内容查询消息。
2.2.5. 缺点
- erlang开发源码难懂,不利于做二次开发和维护;
- 接口和协议复杂,学习和维护成本较高。
2.2.6. 总结
- erlang有并发优势,性能较好。虽然源码复杂,但是社区活跃度高,可以解决开发中遇到的问题;
- 业务流量不大的话可以选择功能比较完备的RabbitMQ。
2.3. Pulsar
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算最佳解决方案。Pulsar 是一个 pub-sub (发布-订阅)模型的消息队列系统。(百科)
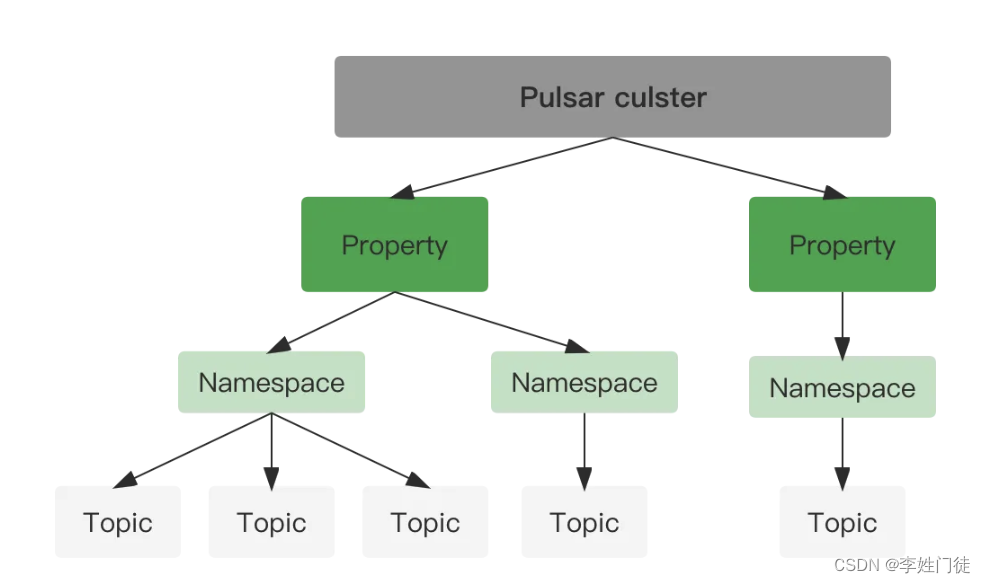
2.3.1. 基本术语
-
Property:代表租户,每个property都可以代表一个团队、一个功能、一个产品线。一个property可包含多个namesapce,多租户是一种资源隔离手段,可以提高资源利用率;
-
Namespace:Pulsar的基本管理单元,在namaspace级别可设置权限、消息TTL、Retention 策略等。一个namaspace里的所有topic都继承相同的设置。命名空间分为两种:本地命名空间,只在集群内可见、全局命名空间对多个集群可见集群命名空间;
-
Producer:数据生产方,负责创建消息并将消息投递到 Pulsar 中;
-
Consumer:数据消费方,连接到 Pulsar接收消息并进行相应的处理;
-
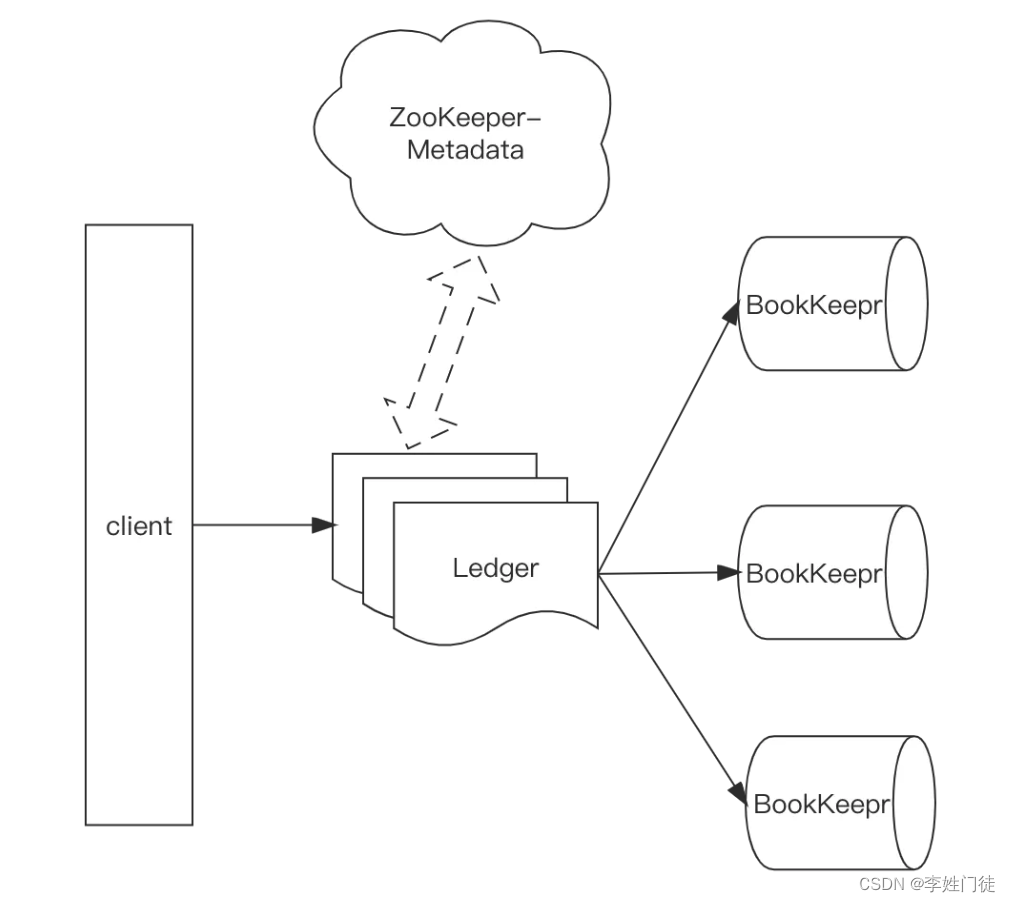
Broker:无状态Proxy服务,负责接收消息、传递消息、集群负载均衡等操作,它对 client 屏蔽了服务端读写流程的复杂性,是保证数据一致性与数据负载均衡的重要角色。Broker 不会持久化保存元数据。可以扩容但不能缩容;
-
BookKeeper:有状态,负责持久化存储消息。当集群扩容时,Pulsar会在新增BookKeeper和Segment(即 Bookeeper 的 Ledger),不需要像kafka一样在扩容时进行Rebalance。扩容结果是 Fragments跨多个Bookies以带状分布,同一个Ledger的Fragments 分布在多个Bookie上,导致读取和写入会在多个 Bookies 之间跳跃;
-
ZooKeeper:存储 Pulsar 、 BookKeeper 的元数据,集群配置等信息,负责集群间的协调、服务发现等;
-
Topic:用作从producer到consumer传输消息。Pulsar在Topic级别拥有一个leader Broker,称之为拥有 Topic 的所有权,针对该 Topic 所有的 R/W 都经过该 Broker 完成。Topic的 Ledger 和 Fragment 之间映射关系等元数据存储在 Zookeeper 中,Pulsar Broker 需要实时跟踪这些关系进行读写流程;
-
Ledger:即Segment,Pulsar底层数据以Ledger的形式存储在BookKeeper上。是Pulsar删除的最小单位;
-
Fragment : 每个 Ledger 由若干 Fragment 组成。
2.3.2. 系统框架
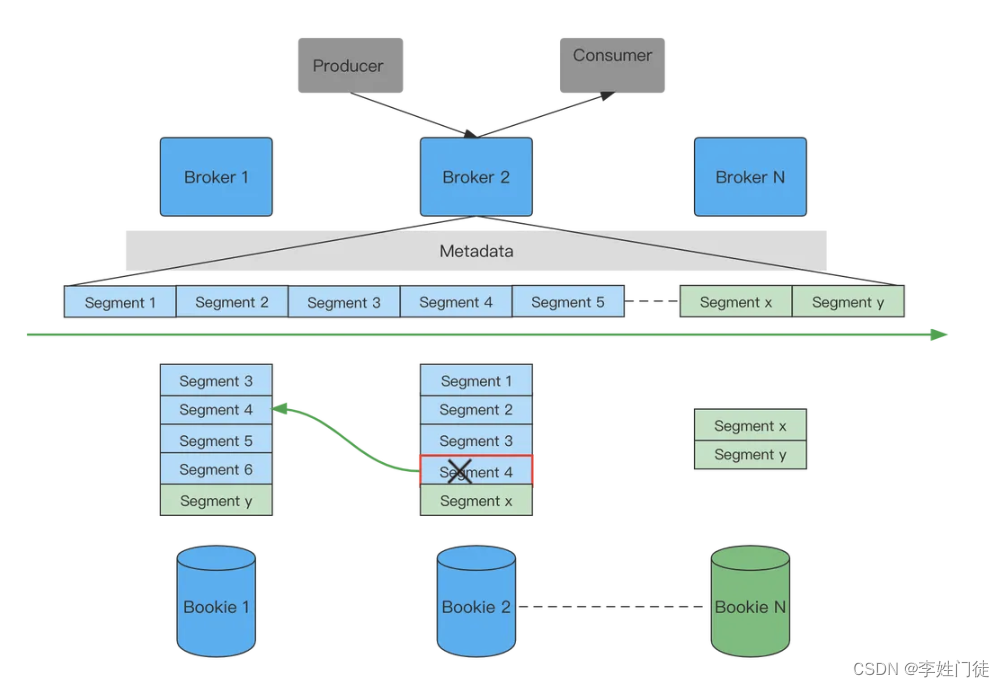
上面框架图分别演示了扩容、故障转移两种情况。
- 扩容:因业务量增大扩容新增Bookie N,后续写入的数据segment x、segment y写入新增Bookie中,为保持均衡扩容结果如上图绿色模块所示。
- 故障转移:Bookie 2的segment 4发生故障,Pulasr的Topic会立马从新选择Bookie 1作为处理读写的服务。
Broker是无状态的服务,只服务数据计算不存储,所以Pulsar 可以认为是一种基于 Proxy 的分布式系统。
2.3.3. 存储计算分离/分片存储
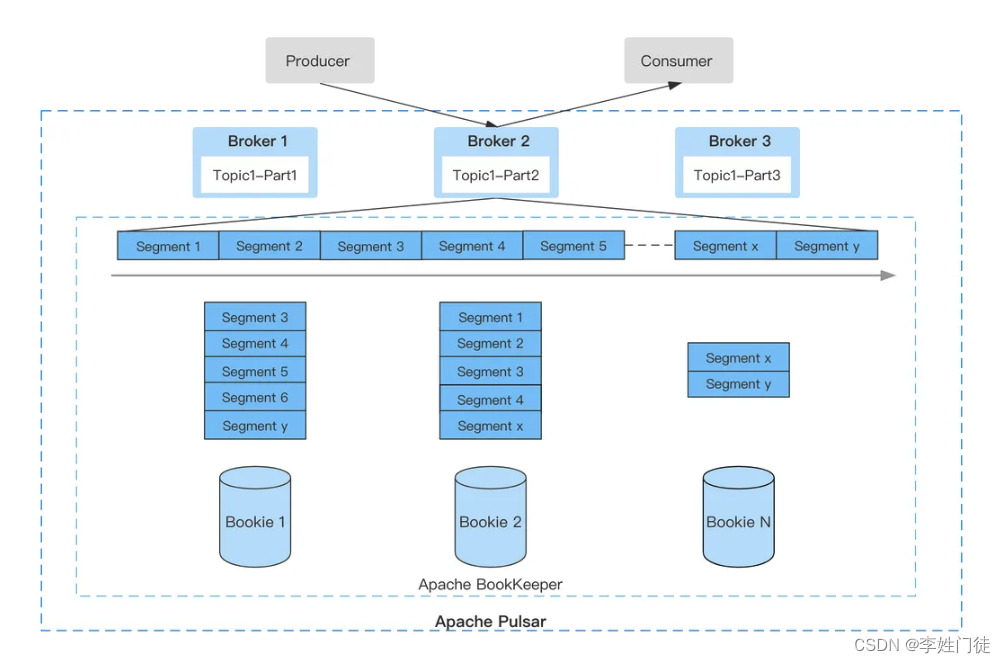
- 存储计算分离,其中Broker1,Broker2,Broker3是无状态服务层;BookKeeper是有状态持久层,由一组Bookie存储节点组成。
- 分片存储存储粒度比分区(参考Kafka分区)更细化,负载更均衡。Topic可以有多个分区,这里的分区是逻辑上的概念,实际存储的单位是分片。
- Topic1的Part2分区数据由多个分片组成,均匀存储在BookKeeper群集中的多个Bookie节点中,每个分片有 3个副本。
2.3.4. 读写分离
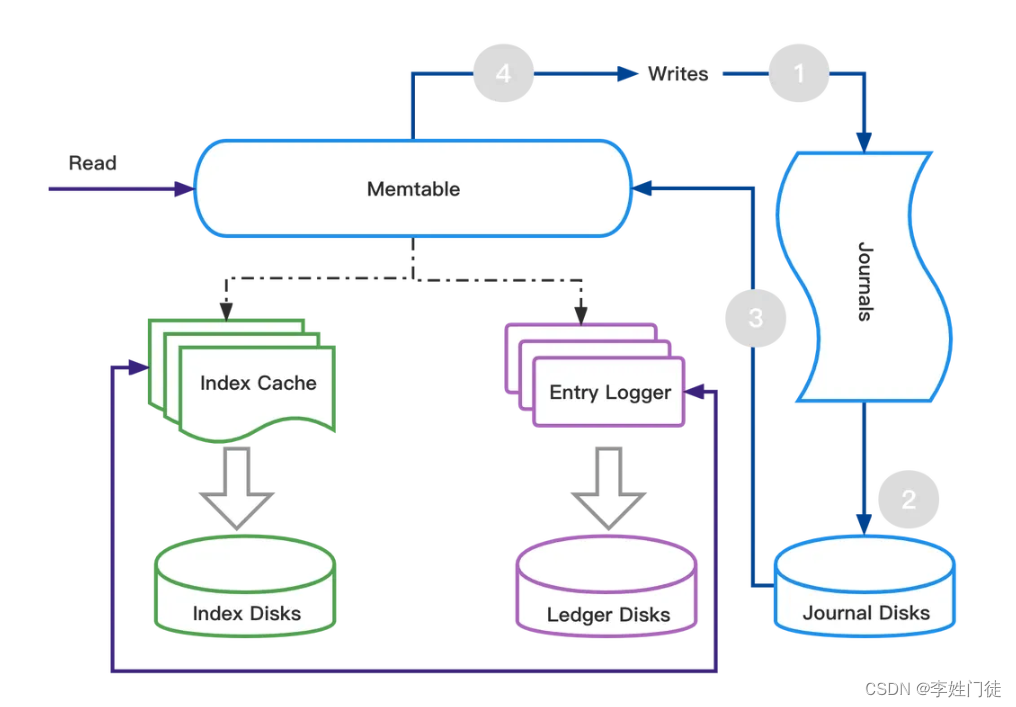
写入过程:
- 数据首先会写入 Journal;
- 写入Journal的数据会实时落到磁盘;
- 数据写入到读写缓存Memtable;
- 之后对写入请求进行响应。
- Memtable 写满之后,会 Flush到Entry Logger和Index cache,Entry Logger中保存了数据,Index cache保存了数据的索引信息,然后由后台线程将Entry Logger和Index cache数据落到磁盘。
读取过程:
- 如果是读取新消息请求,直接从Memtable读写缓存中读取;
- 如果是滞后消费请求,先读取Index索引信息,然后索引从Entry Logger文件读取消息。
读写分离优势:
- 写入时,Journal中的数据需要实时写到Journal磁盘,只影响数据写入。
- 读取消息时,首先从读写缓存Memtable中读取,如果不命中再从Ledger磁盘中读取,读取数据会影响 Ledger 磁盘的IO。
- 读、写分别对应两块磁盘,所以读写逻辑互不影响。
2.3.5. 消息确认
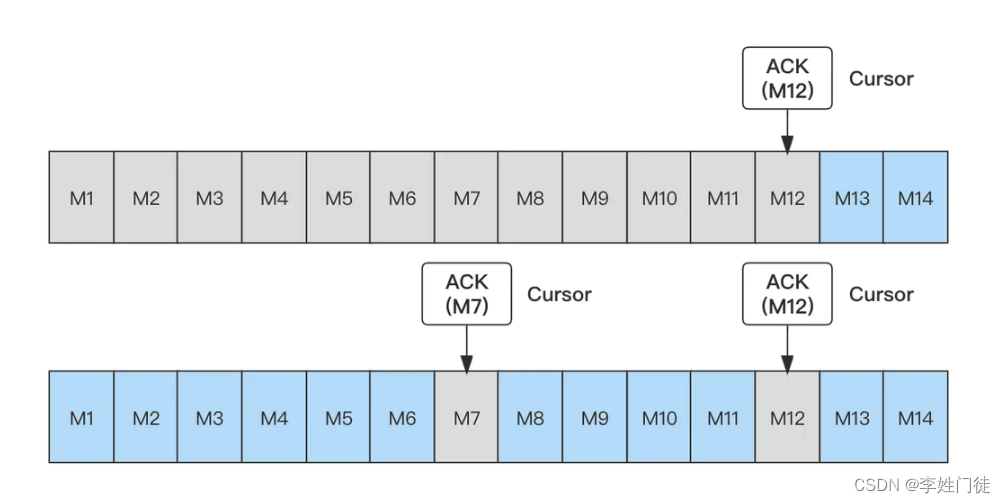
- 单条确认:依次确认每一个消息,保证确认的顺序性。
- 累积确认,只需要确认一条消息,表示这条消息以及之前的消息都已确认。
2.3.6. 延时消息
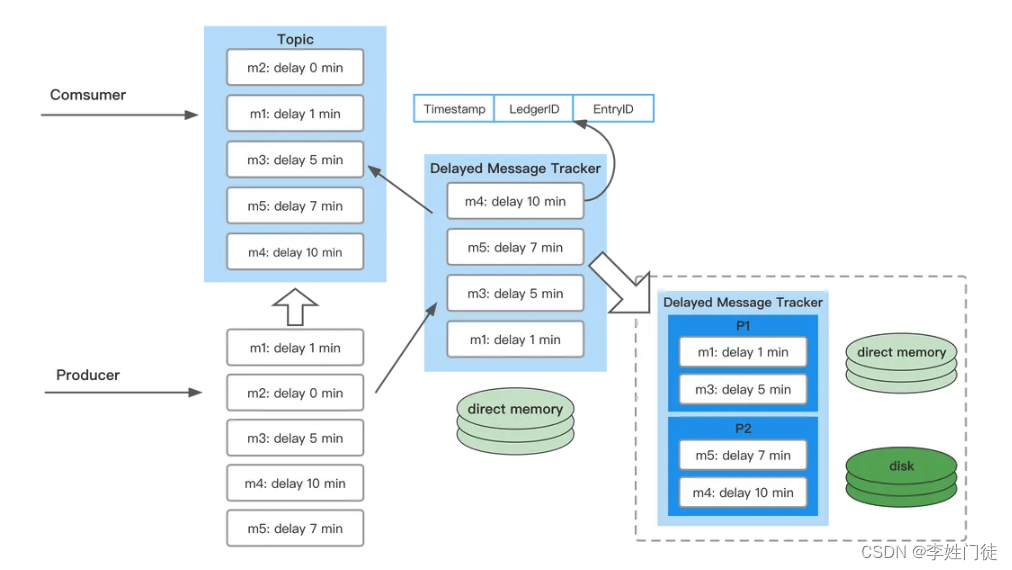
所有延迟投递的消息会被Delayed Message Tracker记录对应的index。index是由 timestamp | LedgerID | EntryID 三部分组成,后两个用于定位该消息,timestamp除了记录需要投递的时间,还用于delayed index优先级队列排序。延时队列维护着一个delayed index优先级队列,延迟时间最短的会放在下面,时间越长越靠后。consumer会先去延时队列检查,如果有到期的消息,就找到对应的消息进行消费。
如果集群出现Broker宕机或者topic的ownership转移,Pulsar会重建延时队列,来保证延迟投递的消息能够正常工作。初始版的方案存在两个问题:延时队列受到内存限制;队列重建的时间开销。
改进版: 以5分钟为间隔对index 队列进行分区。
- m1和m3 放在了time partition 1,延迟时间最近放内存;
- m4 和 m5 在 time partition 2,延迟时间比较靠后存储在磁盘。
这样可以降低内存使用及队列重建时间开销。
2.3.7. 跨地域复制
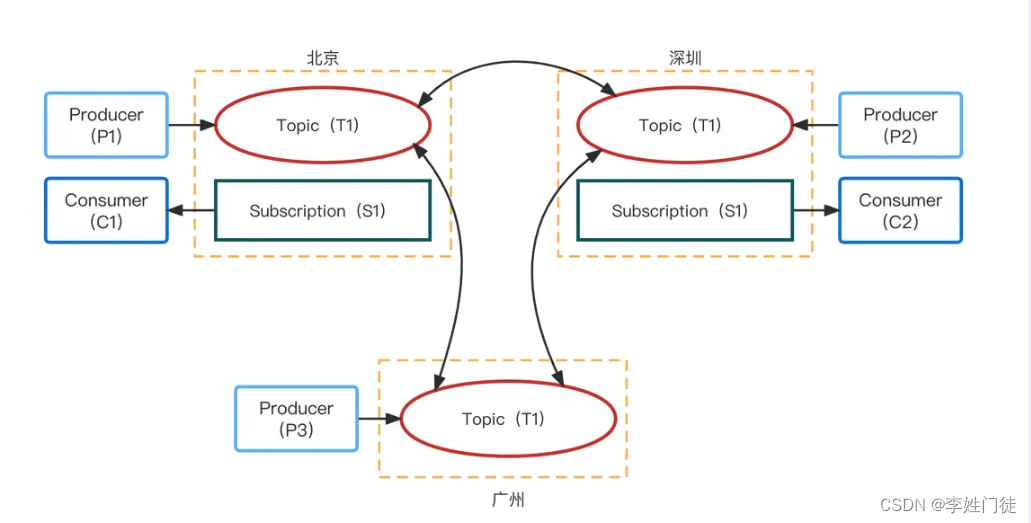
有三个Pulsar 集群,分布于北京、深圳和广州,用户创建的一个Topic T1 设置了跨越三个数据中心做互备。在三个数据中心中,分别有三个生产者,它们往T1 中发布消息;有两个消费者:C1、C2,订阅了T1主题。
当消息写入成功后,会立即复制到其他两个数据中心。消费者不仅可以收到本数据中心产生的消息,也可以收到从其他数据中心复制过来的消息。
2.3.8. 优点
- 灵活扩容
- 无缝故障恢复
- 支持延时消息
- 内置的复制功能,用于跨地域复制如灾备
- 支持两种消费模型:流(独享模式)、队列(共享模式)
2.4. RocketMQ
RocketMQ是一个分布式消息和流数据平台,具有低延迟、高性能、高可靠性、万亿级容量和灵活的可扩展性。RocketMQ是2012年阿里巴巴开源的第三代分布式消息中间件。(维基百科)
2.4.1. 基本术语
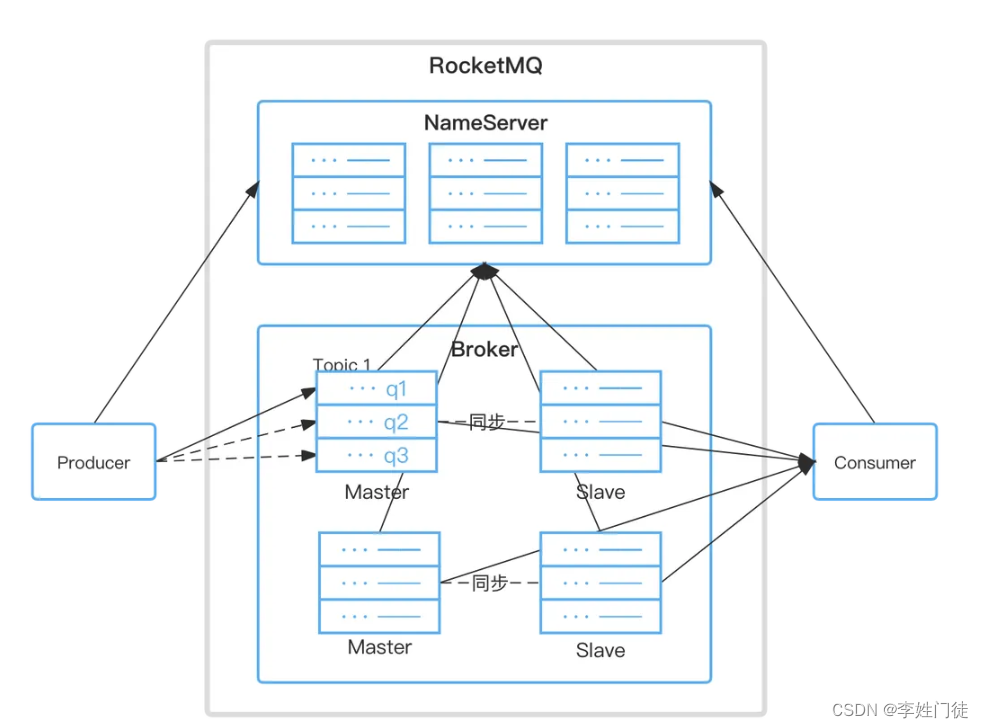
- Topic:一个Topic可以有0个、1个、多个生产者向其发送消息,一个生产者也可以同时向不同的Topic发送消息。一个Topic也可以被0个、1个、多个消费者订阅;
- Tag:消息二级类型,可以为用户提供额外的灵活度,一条消息可以没有tag;
- Producer:消息生产者;
- Broker:存储消息,以Topic为纬度轻量级的队列;转发消息,单个Broker节点与所有的NameServer节点保持长连接及心跳,会定时将Topic信息注册到NameServer;
- Consumer:消息消费者,负责接收并消费消息;
- MessageQueue:消息的物理管理单位,一个Topic可以有多个Queue,Queue的引入实现了水平扩展的能力;
- NameServer:负责对原数据的管理,包括Topic和路由信息,每个NameServer之间是没有通信的;
- Group:一个组可以订阅多个Topic,ProducerGroup、ConsumerGroup分别是一类生产者和一类消费者;
- Offset:通过Offset访问存储单元,RocketMQ中所有消息都是持久化的,且存储单元定长。Offset为Java Long类型,理论上100年内不会溢出,所以认为Message Queue是无限长的数据,Offset是下标;
- Consumer:支持PUSH和PULL两种消费模式,支持集群消费和广播消费。
2.4.2. 系统框架
2.4.3. 优点
- 支持发布/订阅(Pub/Sub)和点对点(P2P)消息模型;
- 顺序队列:在一个队列中可靠的先进先出(FIFO)和严格的顺序传递;
- 支持拉(pull)和推(push)两种消息模式;
- 单一队列百万消息的堆积能力;
- 支持多种消息协议,如 JMS、MQTT 等;
- 分布式横向扩展架构
- 满足至少一次消息传递语义;
- 提供丰富的Dashboard,包含配置、指标和监控等;
- 支持的客户端,目前是java、c++及golang
2.4.4 缺点
- 社区活跃度一般
- 延时消息:开源版不支持任意时间精度,仅支持特定的level
2.4.5 使用场景
为金融互联网领域而生,对于可靠性要求很高的场景
注: 参考rocketmq的架构和设计理念,几乎跟kafka很类似,架构几乎相同,只是调整了相关的名词而已。当然在设计时,也确实针对kafka的问题做了改进,比如kafka在权限设计上比较偷懒,能够支持的场景有限,rocketmq针对这部分就做了很多的设计,以满足丰富的权限需求。
3. 疑问和思考
暂无
4. 参考文档
暂无






![[node 库推荐] rosie 测试用生成数据](https://img-blog.csdnimg.cn/direct/048131fdfda045699a6e47135ab557ef.png)