这里写目录标题
- 1.摘要
- 2.Vgg的网络架构
- 3.代码
- backbone
- train
- predict
- 4.训练记录
- 5.推理
- onnxruntime推理
- export_onnx
- openvino推理
- tensorrt推理
1.摘要
vgg是由牛津大学视觉几何组(Visual Geometry Group)的这篇论文中提出的模型,并且在2014年的ILSVRC物体分类和目标检测任务中分别斩获第二和第一名的好成绩,被cv界以VGG的名称所熟知。VGG中提出以小卷积核多层卷积的核心思想,显著的提升了模型的性能(后面细讲),并且vgg的网络架构十分的清晰,卷积核与池化层的参数稳定,容易迁移到不同的数据集中来适应不同的任务。
2.Vgg的网络架构
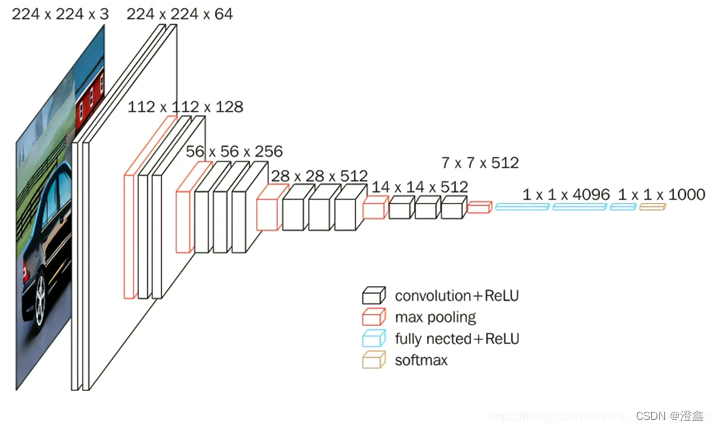
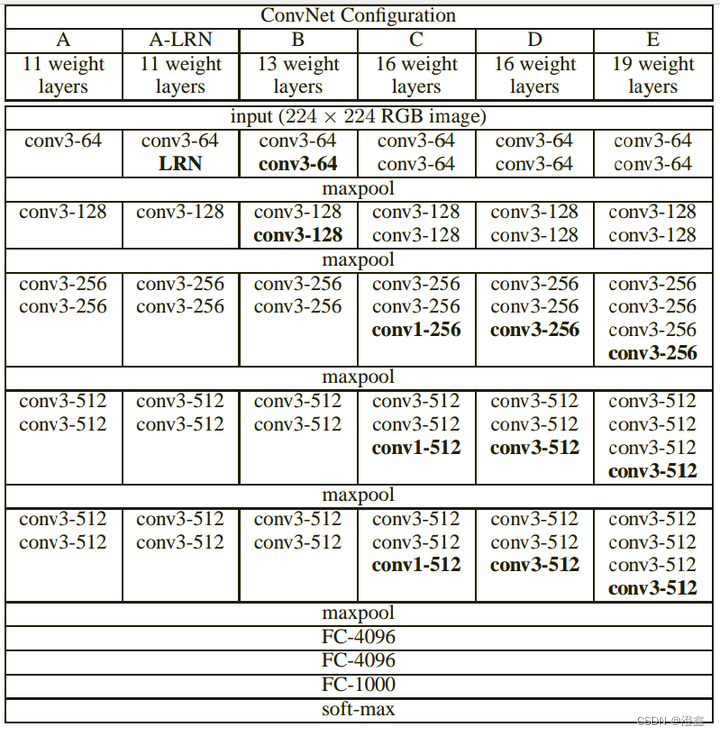
以下的vgg的网络架构图是以vgg-16为例来展示的(共16层权重层,包含卷积层和全连接层)。
- 输入尺寸为224×224×3。
- 使用了3×3的小卷积核来代替7×7的大卷积核,通过计算我们可以发现,设置stride=1,pooling_size=0的前提下,我们可以根据感受野的公式(rfsize=(out_size-1)×stride+ksize),假定我们现在得到一个特征图,我们以某一个像素为开始向下映射感受野,可以得到3个3 × 3的卷积核得到的感受野和1个7 × 7的卷积核的感受野是一样的,但是我们可以通过使用多个卷积核来将网络在维度上设计的更深,能够增强网络的非线性能力,并且能够构建除更具判别能力的决策函数(不同维度的信息不同,例如纹理,形状,抽象具象特征等)。
- 根据参数量的计算方式,假设特征图的数量为c,那么3个3×3的卷积核得到的特征图的参数量为3 × (3 × 3 + 1)× c2 = 30c2,而1个7×7的卷积核得到的特征图的参数量为1 × (7 × 7 + 1) ×c2 = 50c2,从参数量看,多层的小卷积核比单层的大卷积核的参数要少了不少,因此缩短了训练时间。
- 使用了5层最大池化,都使用的是same卷积的方式(卷积的三种模式:full、same、valid),每经过一次池化之后特征图尺寸缩小一半,最后一层的特征层尺寸即为224/2^5 = 7,因此进入线性层之前的最后一个特征层为7 × 7的尺寸,这是一个比价合理的尺寸大小。
- 然后跟着的是两个隐藏层节点数为4096的全连接层,最后是一个class_nums维度的softmax分类层。(可以根据我们的分类需求来自定义最后的分类个数)
3.代码
backbone
import torch.nn as nn
import torch
cfgs = {
'vgg11' : [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13' : [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16' : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19' : [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, feature, num_class=1000, pre_trained=False):
super(VGG, self).__init__()
self.feature = feature
self.L1 = nn.Sequential(
nn.Linear(7*7*512, 4096),
nn.BatchNorm1d(4096),
nn.ReLU()
)
self.L2 = nn.Sequential(
nn.Linear(4096, 4096),
nn.BatchNorm1d(4096),
nn.ReLU()
)
self.FC = nn.Linear(4096, num_class)
def forward(self, x):
features = self.feature(x)
out = features.view(x.size(0), -1)
# x = torch.flatten(x, start_dim=1)
out_1 = self.L1(out)
out_2 = self.L2(out_1)
out_3 = self.FC(out_2)
return out_3
def Feature(cfg:list):
layers = []
in_channels = 3
for c in cfg:
if c == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
out_channels = c
conv_block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
layers += conv_block
in_channels = c
return nn.Sequential(*layers)
def vgg(model_name:str, pre_trained=False, **kwargs, ):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
features = Feature(cfg)
model = VGG(features, **kwargs)
if pre_trained:
model.load_state_dict(torch.load("best.pth"))
return model
train
import argparse
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
from tqdm import tqdm
from vgg import vgg
def parse_args():
parser = argparse.ArgumentParser(description="vgg train by pytorch")
parser.add_argument('--train_root', default='', type=str, help="the path of train-data folder")
parser.add_argument('--val_root', default='', type=str, help="the path of val-data folder")
parser.add_argument('--model_name', default="vgg16", type=str, help="the name of backbone")
parser.add_argument('--class_num', default=2, type=int, help="the number of classes")
parser.add_argument('--batch_size', default=10, type=int, help="the size of one batch")
parser.add_argument('--epochs', default=100, type=int, help="the times of iteration")
parser.add_argument('--workers', default=10, type=int, help="the nums of process")
parser.add_argument('--learn_rate', default=0.00005, type=int, help="the speed of learning rate")
parser.add_argument('--momentum', default=0.9, type=int, help="momentum")
parser.add_argument('--weight_decay', default=None, type=int, help="weight decay")
parser.add_argument('--gpu_id', default=0, type=int, help="the index of your gpu")
parser.add_argument('--save_dir', default='best.pth', type=str, help="the best accuracy pth saved path")
args = parser.parse_args()
return args
def train():
args = parse_args()
train_dir = os.path.join(args.train_root, "dataset")
val_dir = os.path.join(args.val_root, "dataset")
assert os.path.exists(train_dir), "{} path does not exist!".format(train_dir)
assert os.path.exists(val_dir), "{} path does not exist!".format(val_dir)
device = torch.device("cuda:{}".format(args.gpu_id) if torch.cuda.is_available() else "cpu")
# device = 'cpu'
print('using {} to train.'.format(device))
# nw = 1
# if args.class_num == None:
# nw = min([os.cpu_count(), args.batchsize if args.batchsize > 1 else 0, 8])
# args.workers = nw
print('using {} workers to train'.format(args.workers))
vgg_transform = {
"train" : transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.485, 0.456, 0.406 ],
std = [ 0.229, 0.224, 0.225 ]),
]),
"val" : transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.485, 0.456, 0.406 ],
std = [ 0.229, 0.224, 0.225 ]),
])
}
train_dataset = datasets.ImageFolder(root=train_dir, transform=vgg_transform["train"])
train_loader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=args.workers)
val_dataset = datasets.ImageFolder(root=val_dir, transform=vgg_transform["val"])
val_loader = DataLoader(dataset=val_dataset, batch_size=args.batch_size, shuffle=False, num_workers=args.workers)
train_len = len(train_dataset)
val_len = len(val_dataset)
print('using {} images to train and {} images to val'.format(train_len, val_len))
model = vgg(model_name=args.model_name, num_class=args.class_num)
model.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=args.learn_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
train_acc = 0.0
train_steps = len(train_loader)
for epoch in range(args.epochs):
model.train()
running_loss = 0.0
cnt = 0
train_bar = tqdm(train_loader, file=sys.stdout)
for time, data in enumerate(train_bar):
images, labels = data
outputs = model(images.to(device))
loss = loss_function(outputs, labels.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
cnt += 1
train_bar.desc = "train_epoch[{}]/total_epoch[{}] —— avg_loss:{}".format(epoch+1, args.epochs, running_loss/cnt)
scheduler.step(running_loss)
model.eval()
val_acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader, file=sys.stdout)
for step, data in enumerate(val_bar):
images, labels = data
outputs = model(images.to(device))
pred_label = torch.max(outputs, dim=1)[1]
val_acc += torch.eq(pred_label, labels.to(device)).sum().item()
average_acc = val_acc / val_len
print("[{}-epoch] train_loss: {} val_accuracy: {}".format(epoch + 1, running_loss/train_steps, average_acc))
if average_acc > train_acc:
torch.save(model.state_dict(), args.save_dir)
print('finish training')
if __name__ == "__main__":
train()
predict
import torch
import vgg
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from train import parse_args
import cv2
from PIL import Image
from torchvision.transforms import ToPILImage
from torch.autograd import Variable
# 前处理
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
classes = [
"cat",
"dog",
]
args = parse_args()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = vgg.vgg(model_name=args.model_name, pre_trained=False, num_class=args.class_num).to(device)
model.load_state_dict(torch.load(r'best.pth'))
model.eval()
image = cv2.imread('dataset/dog/dog.12386.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = Image.fromarray(image)
input = val_transform(image)
# image.show()
input = Variable(torch.unsqueeze(input, dim=0).float(), requires_grad=False).to(device)
with torch.no_grad():
pred = model(input)
class_idx = torch.argmax(pred[0])
class_idx = class_idx.detach().cpu()
print("This is a {}".format(classes[class_idx]))
4.训练记录
- 需要设置较小的初始learning_rate来进行反向传播,否则会导致step太大,无法收敛,我一开始设置的是0.01,结果无法收敛,后来设置成0.0001,效果会好很多。
- 随着我们训练的不断迭代,每个参数逐渐的接近收敛到梯度最小值处,这个位置往往是梯度变化较大的位置,小小的步长就能带来巨大的参数变化,导致模型精度的影响,因此在后期,我们需要进行学习率的调整,使模型能够在一个较小的学习率下去更新各项参数,因此我引入了
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)来实现一个学习率的自动衰减,效果很好,可以尝试一下不同的方式,比如余弦退火法。
5.推理
onnxruntime推理
首先,需要加载pth模型权重到实例化的模型中,然后调用自己写的导出onnx模型的代码:
export_onnx
import os.path
import vgg
import onnx
from train import parse_args
import torch
def export_onnx(pt_path:str, onnx_path:str):
args = parse_args()
model = vgg.vgg(model_name=args.model_name, pre_trained=False, num_class=args.class_num)
model.load_state_dict(torch.load(pt_path))
dummy_inputs = {
"input" : torch.randn(1, 3, 224, 224, dtype=torch.float),
}
output_names = {
"classes"
}
# if not os.path.exists(os.path.dirname(onnx_path)):
# os.makedirs(os.path.dirname(onnx_path))
with open(onnx_path, "wb") as f:
print(f"Exporting onnx model to {onnx_path}...")
torch.onnx.export(
model,
tuple(dummy_inputs.values()),
f,
export_params=True,
verbose=False,
opset_version=11,
do_constant_folding=True,
input_names=list(dummy_inputs.keys()),
output_names=output_names,
# dynamic_axes=dynamic_axes,
)
if __name__ == "__main__":
pt_path = "best.pth"
onnx_path = "best.onnx"
export_onnx(pt_path, onnx_path)