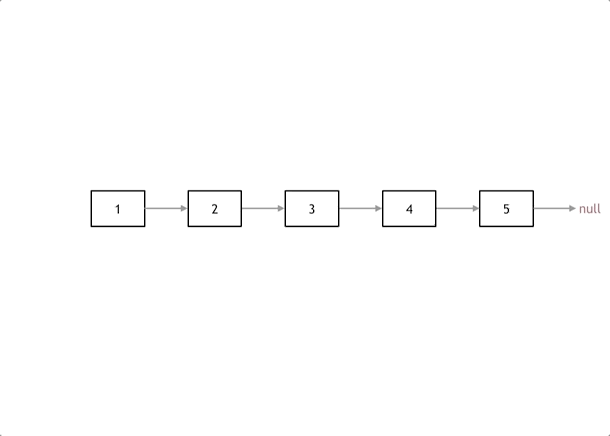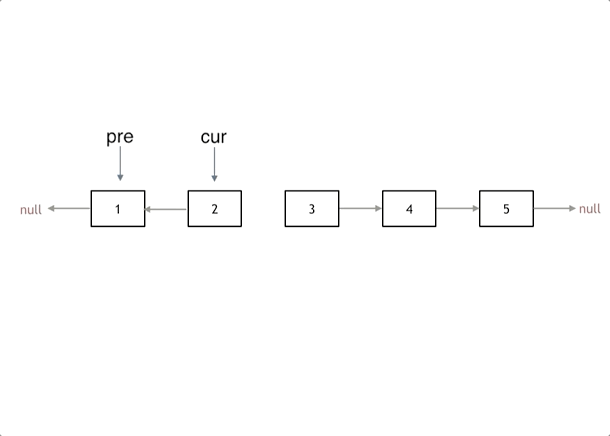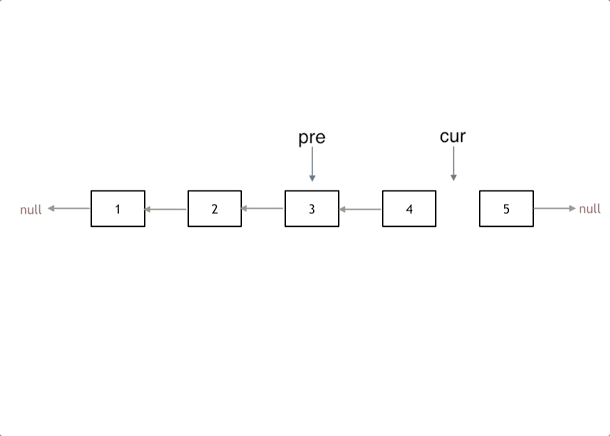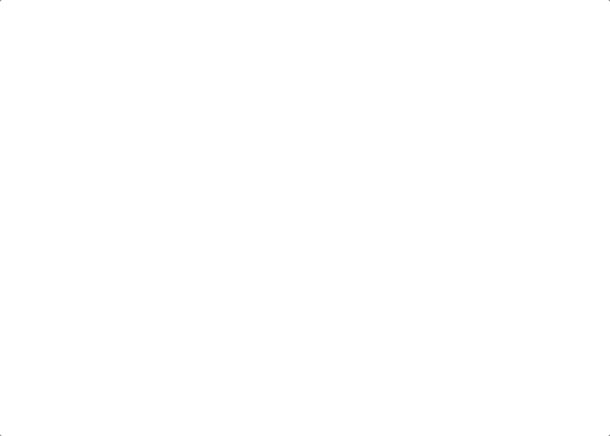
一、磁盘
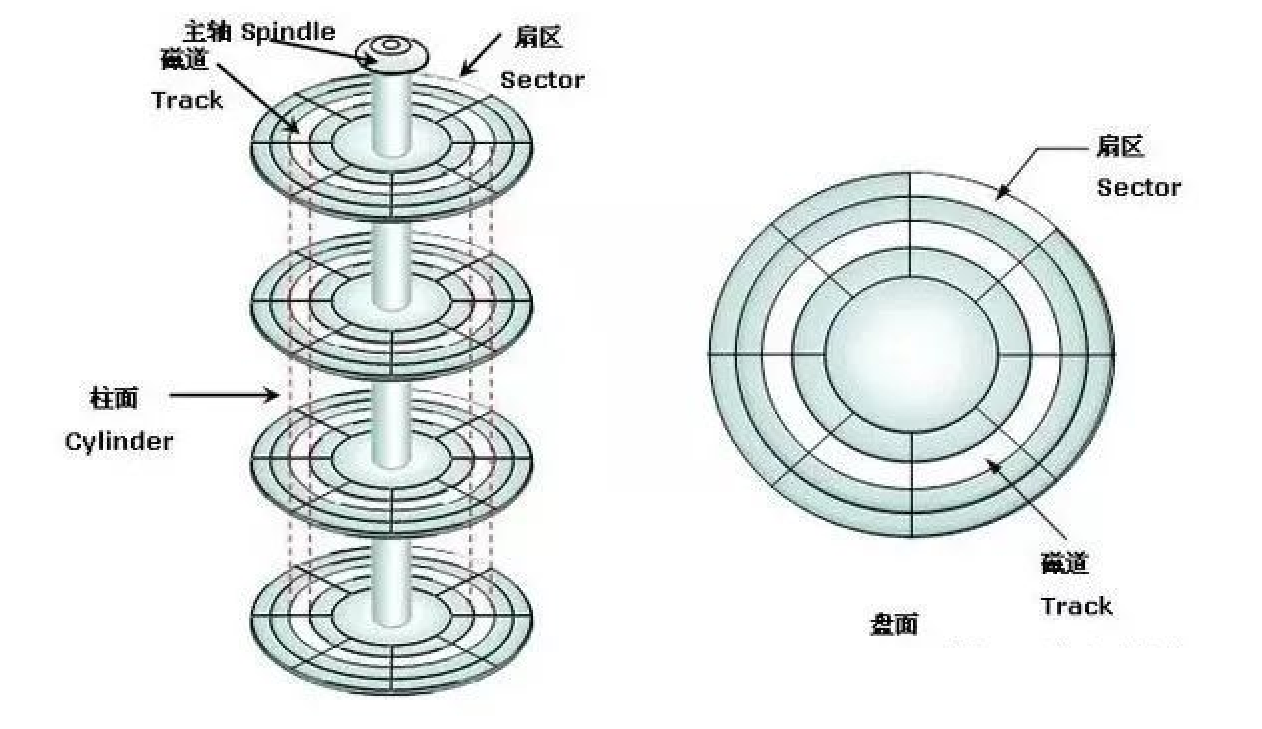
磁盘的物理结构
磁盘的本质是一个机械设备,可以存储大量的二进制信息,是实现数据存储的基础硬件设施,磁盘的盘片类似于光盘,不过盘片的两面都是可读可写可擦除的,每个盘面都有一个磁头,马达可以使盘片旋转起,磁头悬浮在非常接近盘片表面的位置,通过感应磁性变化来读取或改变磁性以读写数据。

磁盘的存储结构
一个磁盘可能拥有多个盘片,一个盘片存在两个盘面,而每个盘面以距离圆心的远近可以分为许多磁道,每个磁道又会被分为许多的扇区,同一径向位置的所有磁道组成一个柱面。
盘片的旋转是为了定位对应扇区,磁头左右摇摆是为了确定对应的磁道
-
盘片(Platters):
- 硬盘内部包含一组或多组圆形的薄金属盘片,它们堆叠在一起,并且每个盘片表面都涂覆一层磁性材料,用于记录二进制数据。
- 磁盘片可以双面存储数据,即每个盘片通常会有两个磁化表面。
-
磁道(Tracks):
- 每个盘片表面被划分为一系列同心圆,这些圆轨迹被称为磁道。磁道是记录数据的基本轨道,磁道越靠近中心,其直径越小,容纳的比特密度相对较高。
-
扇区(Sectors):
- 每个磁道进一步被划分为多个扇区,扇区是磁盘上能够独立寻址并存储固定大小数据块的最小单元,常见的扇区大小是512字节或4KB。
-
柱面(Cylinders):
- 同一径向位置的所有磁道组成一个柱面。也就是说,硬盘中所有盘片上相同半径的磁道构成一个柱面。在访问数据时,磁头同时移动到对应柱面上的同一磁道位置。
-
磁头(Heads):
- 每个盘面都有一个读写磁头,它们安装在磁臂(Actuator Arm)上。当磁盘旋转时,磁头悬浮在非常接近盘片表面的位置,通过感应磁性变化来读取或改变磁性以读写数据。
磁盘的逻辑结构
对于磁带我们知道它是一个线性的存储介质,在录音机中通过磁带在两个圈的旋转便可以访问其中的数据,对于磁盘,我们也可以把他抽象的想象为一个线性的结构,将每个盘面展开,将磁道连接到一起,此时该线性结构就为一个以扇区为基本单位的一个数组,通过数组下标就可以访问对应扇区的内容,只要有扇区对应的下标就可以通过一些简单的计算找到其在磁盘的物理位置。故文件就是在磁盘中占几个扇区的问题。
例如:若扇区的下标为index,一个盘面有10个磁道,一个磁道分为了100个扇区,那么一个盘面就拥有1000个扇区,index/1000为该扇区位于哪个盘面,tmp=(index%1000),tmp为该扇位于哥这个盘面的第几个扇区,tmp/100为位于该盘面的哪个磁道,tmp%100为位于该磁道到的第几个扇区。
所以找到一个指定扇区分为三步:
- 找到对应的磁头(Header)
- 找到对应的磁道(Cylinder)
- 找到对应扇区(Sector)
该方法成为CHS定址法
一个扇区为512个字节,在操作系统与磁盘进行交互的时候,OS认为一次读取512个字节的内容太少了,所以规定与磁盘交互的基本单位为4kb,也就是8个连续的扇区,所以我们可以进一步对磁盘进行抽象,将每8个扇区抽象为一个块,这样磁盘就被抽象为了一个以块为基本单位的数组,称为LBA 逻辑区块地址(块中的8个扇区最后是连续的,不然磁头和盘片要进行大量的旋转寻址,会影响效率),通过块数组下标,我们就可以找到对应扇区的数组下标,n*8就为该块对应第一个扇区的下标,而该块的8个扇区都是连续的,这样就可以锁定该块所有的扇区了。
所以只要有一个起始,知道磁盘的总大小,该磁盘有多少块,每个块的块号,如何转换到对应的多个CHS地址我们就全部知道了。
综上所述,一个磁盘被分为了许多的块,操作系统维护这么多的块其实是有一定难度的,一般会对磁盘在进行分区,其实我们的电脑一般就只有一个磁盘,其中的C盘、D盘就是所谓的分区,只要能管理好一个分区就能管理好整个磁盘
二、inode与文件系统
为了管理好一个分区,OS还会将一个分区进行分组,此时问题就到了如何管理好一个分组?
这样一层一层剥开分析的思想叫做分治。接下来就讲解一下如何管理好一个分组:
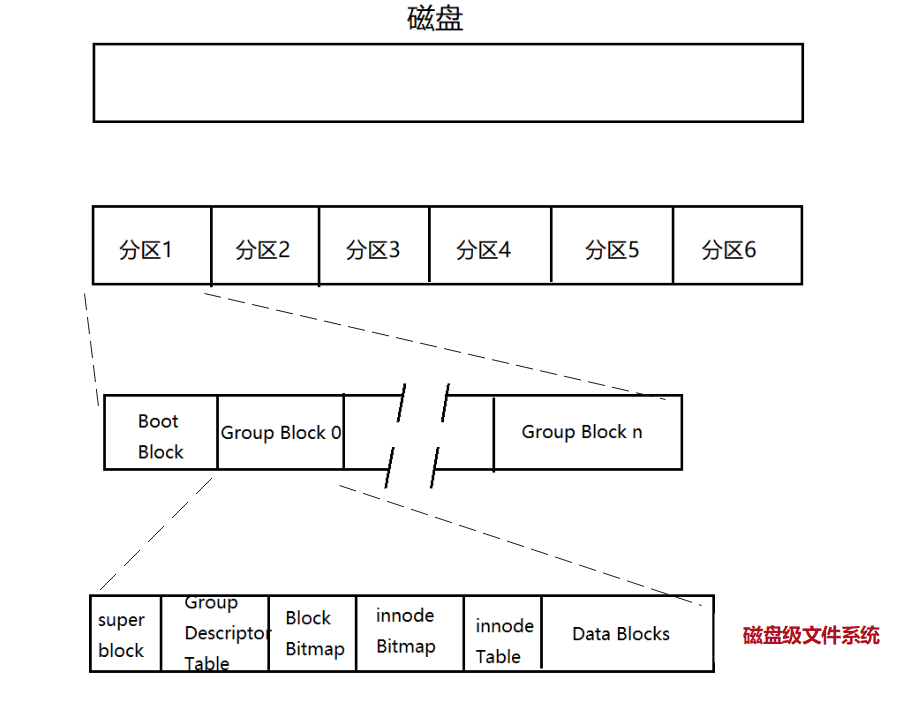
文件=内容+属性,文件储存在磁盘的本质就是文件的内容与文件的属性数据保存在磁盘,在Linux下,文件的内容与属性数据是分开保存的
- Data Blocks:数据区,及保存文件内容的地方,在数据区内抽象存在着许多的块,每个块都有自己的块号,数据就保存在这些快中
- Block Bitmap:块位图,Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没 有被占用
- inode:文件的类型与内容是不同的,但是描述文件的属性却是相同的,例如文件的大小,文件的创建时间等等,这些数据被保存在一个一个结构体中,这个结构体就称为inode。一般这个结构体的大小是固定的128个字节,每一个文件被一个inode描述,但是inode中并不会保存文件的名字,在内核层面上每一个inode都会有一个inode_number,只要有inode号就可以在inode表中定位一个inode,其中inode中还会存在一个数组:datablock[N],这个数组会保存文件内容保存在Data Blocks中块的下标,通过这个数组就可以找到文件的内容了,总之只要有了inode号就可以找到文件的内容+属性
- inode Table:inode表就是管理inode的结构,保存着分组内部所有的可用(已经使用 + 没有使用)inode。
- inode Bitmap: inode位图,每一个比特位表示一个inode是否空闲可用
- GDT,Group Descriptor Table:块组描述符,描述块组属性信息,记录了当前块inode与块的使用情况等等
- super block:超级块,super block中保存的是整个分区的使用情况,记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了
- 补充:inode的编号是分区级别的,一个分区中的inode不能相同,分区之间的inode可以有重复,每个组都有自己起始的inode编号与结束inode编号,保存在GDT中,而超级块保存着整个分区所有分组的start_inode_num与end_inode_num,这样只要有inode编号,就可以快速定位inode的位置(Data Block也是这样做的)
- 为什么超级块保存在组中呢,不应该是分区级别的吗?要知道磁盘信息的写入与读取离不了盘片的旋转与磁头的摆动,如果发生了一些意外情况,将分区超级块的信息刮花了,那么这个分区就损坏掉了,其实并不是所有的分组都会保存超级块,一般是隔几个组保存一个,这么做的原因是当一个组中的超级块数据发生错误,可以将其他组超级块正确的内容加载过来,这样提高了磁盘的复用性。
- 将分区进行分组,并将GDT等文件管理信息写入,这个操作叫做格式化,这样整个分区的文件系统框架就搭建好了
想要得到一个文件的信息,首先需要这个文件的inode编号,我们平常使用的是文件名是怎么获取inode呢?
首先我们谈一谈目录,目录也是文件,既然是文件就有文件的属性和文件的内容,而目录的内容其实保存的是文件名与inode编号的映射关系,这样我们通过文件名就可以找到该文件的inode编号了,而目录中不允许出现同名文件就是为了避免找到错误的映射关系,并且我们知道在一个目录中想要创建新文件就需要写权限,这是因为新建一个文件需要在所处目中内容中写入文件名与inode的映射关系
通过上面的讲述我们理解了,想要管理一个文件,只要找到其所在目录下文件名与inode的映射关系就好了,及访问一个文件需要先访问其目录,而目录也是文件,这样就会一层一层的进行逆向路径解析,在Linux下当遇到根目录时就会停止,因为在机器开机时就会导入数据,OS是知道根目录保存在哪里的,这就是为什么我们进行文件操作时必须带文件的路径
inode编号是分区级别的,那怎么判断文件的inode是哪个分区的呢?
一个分区想要使用,必须与一个目录进行挂载,也就是进入这个分区就相当于进入了这个目录,这样当我们访问一个文件时,只需要对比该文件的路径前缀是与哪个目录相同,然后确定该目录是与哪个分区挂载的,这样就可以找到这个文件的分区了