关注公众号【AI论文解读】回复或者发送:论文解读 获取本文论文PDF

引言:大型语言模型的长篇事实性挑战
在当今信息爆炸的时代,大型语言模型(LLMs)在处理开放式话题的事实性问题时,常常会产生包含事实错误的内容。这些错误可能涉及日期、统计数据,甚至名人的职业等已确立的真实知识。例如,模型可能会提供关于某个名人的错误信息,这些事实错误削弱了语言模型的事实性,使得模型在现实世界中的应用变得不可靠。因此,如何准确评估和提升LLMs在长篇回答中的事实性,成为了一个重要的研究课题。
在本文中,我们提出了一种新的长篇事实性评估方法,以及一个新的度量标准(F1@K),用于量化模型回答的长篇事实性。我们还对流行的大型语言模型进行了广泛的基准测试,使用这些新的数据集和评估方法。我们的贡献包括:
利用GPT-4生成了一个新的长篇事实性基准测试集LongFact,涵盖38个手动选择的话题。
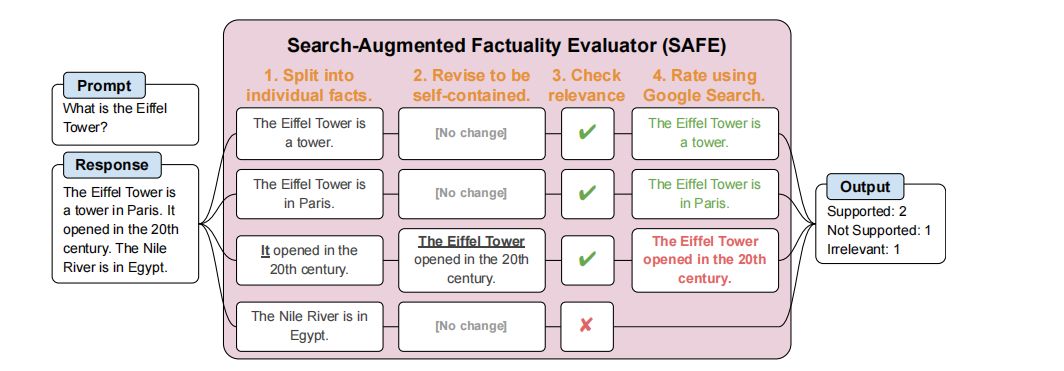
提出了一种利用LLM代理自动评估长篇事实性的方法,我们称之为SAFE(Search-Augmented Factuality Evaluator)。
提出了一种扩展的F1得分作为长篇事实性的聚合度量标准,平衡了回答中支持事实的百分比(精确度)与相对于用户首选回答长度的提供事实的百分比(召回率)。
对13种大型语言模型进行了广泛的基准测试,发现更大的语言模型通常能够实现更好的长篇事实性。
论文标题、机构、论文链接和项目地址
1. 论文标题:《大型语言模型中的长篇事实性》
2. 机构:Google DeepMind
3. 论文链接:https://arxiv.org/pdf/2403.18802.pdf
4. 项目地址:https://github.com/google-deepmind/long-form-factuality
LongFact数据集的创新与意义
1. LongFact数据集介绍
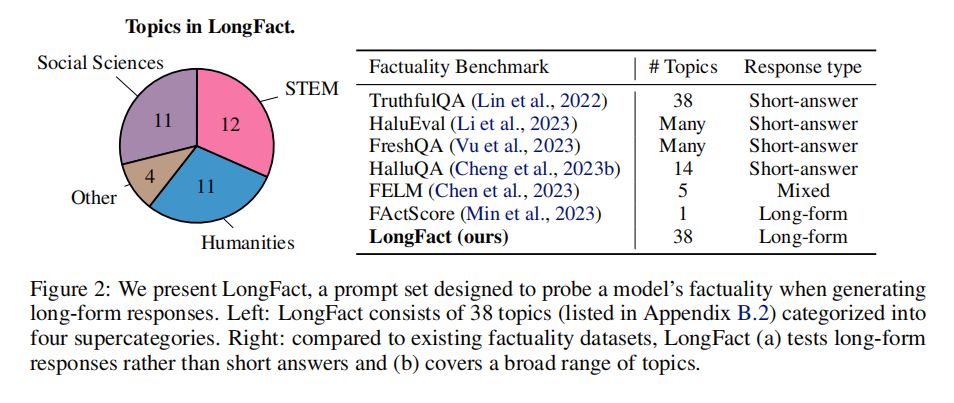
LongFact数据集由GPT-4生成,包含2,280个寻求事实性长篇回答的提示,涵盖38个手动选定的主题。这些主题分为概念和对象两个任务,每个主题生成30个独特的提示,总计每个任务1,140个提示。LongFact旨在评估大型语言模型(LLMs)在开放领域中长篇事实性回答的能力,是首个针对多种领域长篇事实性评估的提示集。LongFact的公开发布,为研究社区提供了一个重要的资源,用于探索和改进LLMs在处理长篇事实性内容方面的性能。
2. 长篇事实性评估的重要性
长篇事实性评估对于提高LLMs的可靠性至关重要。尽管LLMs在近年来取得了显著进展,但它们在回应寻求事实的提示时仍然会产生事实错误,这些错误可能与已建立的真实知识相矛盾。例如,模型可能提供关于日期、统计数据或名人职业的错误信息。这些事实错误削弱了语言模型的事实性,使模型在需要事实准确回答的真实世界场景中变得不可靠。
3. LongFact与现有数据集的对比
与现有的事实性数据集相比,LongFact的独特之处在于它专门设计用于评估长篇回答的事实性。许多已有的基准测试,如TruthfulQA、HaluEval和FreshQA等,主要集中在测试单个事实点的知识,通常只需要短篇回答。而LongFact则要求模型生成可能包含多个详细事实点的长篇回答,覆盖了更广泛的主题范围,为长篇事实性评估提供了更全面的测试场景。
SAFE:自动化长篇事实性评估方法
1. SAFE方法概述
SAFE(Search-Augmented Factuality Evaluator)是一种利用LLM代理自动评估长篇回答事实性的方法。它通过将长篇回答分解为独立的事实点,并使用多步骤推理过程(包括向Google搜索发送查询)来评估每个事实的准确性。此外,SAFE引入了扩展的F1分数作为聚合度量标准,平衡了回答中支持事实的百分比(精确度)与相对于用户偏好回答长度的提供事实的百分比(召回率)。
2. 利用Google搜索进行事实检查
SAFE通过生成多步骤的Google搜索查询,并仔细推理搜索结果是否支持特定事实,来执行事实检查。这一过程的关键创新在于使用语言模型作为代理,生成搜索查询并对结果进行推理,从而准确评估长篇回答中每个事实的支持程度。
3. SAFE与人类评注者的比较
在约16,000个独立事实的测试集上,SAFE与人类评注者的一致性达到72%,并且在100个随机选取的分歧案例中,SAFE的判断在76%的情况下被认为是正确的,显示出超越人类的评估性能。此外,SAFE的成本是人类评注者的20倍以下,显示了其在成本效率和性能上的显著优势。这表明,利用语言模型作为自动化评估器,可以实现超人类水平的自动评估性能,为长篇事实性评估提供了一种可扩展且经济高效的解决方案。
F1@K:衡量长篇事实性的新指标
1. F1@K指标的定义与计算
F1@K是一个新提出的指标,用于衡量模型在长篇回答中的事实性。它通过平衡回答中支持的事实百分比(准确性)与相对于用户期望回答长度的提供事实的百分比(召回率)来计算。具体来说,F1@K将准确性定义为支持事实的比例,召回率则定义为提供的支持事实与用户期望的支持事实数量K之间的比例。最终,F1@K结合了准确性和召回率,给出一个介于0到1之间的分数,以量化模型回答的长篇事实性。
2. 准确性与召回率的平衡
在长篇事实性评估中,理想的模型回答应该既准确又详尽。准确性(precision)通过回答中所有事实中支持事实的比例来衡量,而召回率(recall)则通过提供的事实与应该出现在回答中的所有相关事实的比例来衡量。由于确定应该包含在长篇回答中的事实集是不可能的,F1@K通过引入超参数K来估计用户期望的“理想”事实数量,从而间接衡量召回率。
3. F1@K在不同模型中的应用
F1@K被用于评估不同大型语言模型在长篇事实性方面的表现。研究发现,更大的语言模型通常在长篇事实性上表现得更好。F1@K作为一个标准化的度量,允许研究人员在不同的语言模型和获取回答的方法之间进行量化比较。
大型语言模型的长篇事实性表现
1. 不同模型家族的评估结果
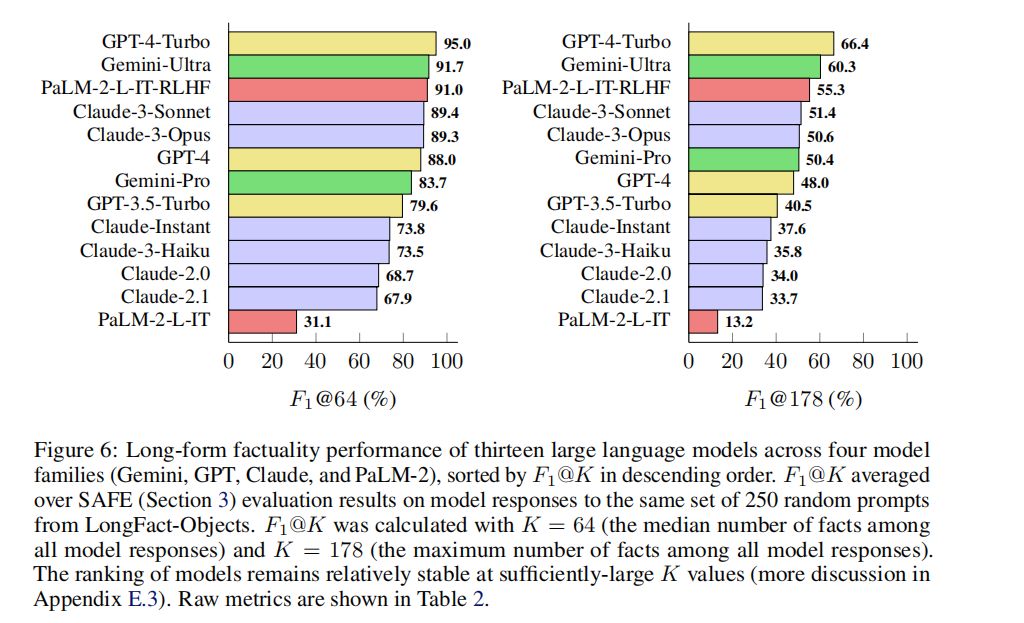
研究对四个模型家族(Gemini, GPT, Claude, 和 PaLM-2)中的十三个大型语言模型进行了长篇事实性的评估。使用SAFE方法和F1@K指标进行评估,结果显示,更大的模型在长篇事实性上通常表现得更好。例如,GPT-4-Turbo的表现优于GPT-4,而GPT-4又优于GPT-3.5-Turbo。
2. 模型规模与事实性的关系
研究发现,模型规模与其长篇事实性之间存在正相关关系。即,模型规模越大,其长篇事实性越好。这一发现与之前的研究结果一致,即更大的模型在多种任务上通常能够提供更准确的信息。
3. 长篇事实性的改进方向
尽管大型语言模型在长篇事实性上取得了进步,但它们在回答深度事实性问题时仍然缺乏可靠性。例如,它们可能会产生与已建立的真实知识相矛盾的事实错误。因此,未来的研究可以探索如何通过更好的预训练/微调或通过使用外部工具来改进语言模型的长篇事实性。此外,SAFE方法在减少对搜索启用的语言模型代理的依赖方面也存在改进空间。

讨论与未来展望
LongFact与SAFE的局限性
在本文中,我们提出了一种新的长篇事实性评估方法SAFE,以及一个用于评估大型语言模型长篇事实性的新数据集LongFact。然而,这些工具和方法也存在一些局限性。首先,SAFE的性能依赖于所使用的大型语言模型的能力,尤其是模型的指令遵循和推理能力。如果模型无法准确地分解长篇回答中的个别事实,或者在确定事实与搜索结果的相关性时推理不当,SAFE的准确性可能会受到影响。此外,SAFE依赖于Google搜索作为知识来源,这可能在某些情况下不足以找到特定事实的信息,尤其是在法律和医学等专业领域。尽管如此,Google搜索仍然是目前可用的最全面的知识来源之一。
长篇事实性评估的未来研究方向
未来的研究可以探索如何通过更好的预训练/微调或通过使用外部工具来提高语言模型的长篇事实性。此外,还可以探索改进SAFE的方法,例如提高搜索结果的质量或增加搜索查询的数量。此外,我们的工作集中在事实性(即与世界知识相符的事实的正确性)上,而长篇设置中的幻觉(即与模型内部知识相符的事实的正确性)的可靠测量方法仍然不清楚。
对大型语言模型事实性的深入理解
通过本文的研究,我们希望能够更深入地理解大型语言模型在长篇内容生成方面的能力。我们展示了如何通过可靠的数据集获取方法、模型评估和度量聚合来显著提高我们对模型能力的理解。我们期待未来的研究能够在测量和提高语言模型在长篇领域的性能方面取得进一步的进展。
结论
论文贡献总结
本文提出了一种新的长篇事实性评估方法SAFE,以及一个用于评估大型语言模型长篇事实性的新数据集LongFact。我们证明了SAFE在与人类标注者的一致性上达到了超人类的表现,并且在成本上比人类标注者便宜20倍以上。此外,我们还对13个来自四个模型家族(Gemini、GPT、Claude、PaLM-2)的模型进行了长篇事实性评估,并发现更大的语言模型通常具有更好的长篇事实性。
对长篇事实性评估的贡献
我们的研究提供了一种新的方法来评估和量化大型语言模型生成的长篇内容的事实性。通过使用SAFE和LongFact,我们能够对大型语言模型进行更全面、更可扩展的长篇事实性评估。
对未来研究的期待
我们期待未来的研究能够在提高语言模型的长篇事实性方面取得进展,包括通过更好的预训练/微调或通过使用外部工具来提高性能。我们还希望未来的研究能够探索如何在长篇设置中可靠地测量幻觉,并进一步提高语言模型在长篇领域的性能。
点击关注公众号 AI论文解读
设置星标 获取最新AI论文解读
往期文章
精彩推荐
计算机视觉新巅峰,微软&牛津联合提出MVSplat登顶3D重建!用更少的参数,速度快2倍,还能跨数据集泛化