keras 2.1.4
tensorflow 1.12.0
python 3.6.4
numpy 1.14.5
一、准备工作
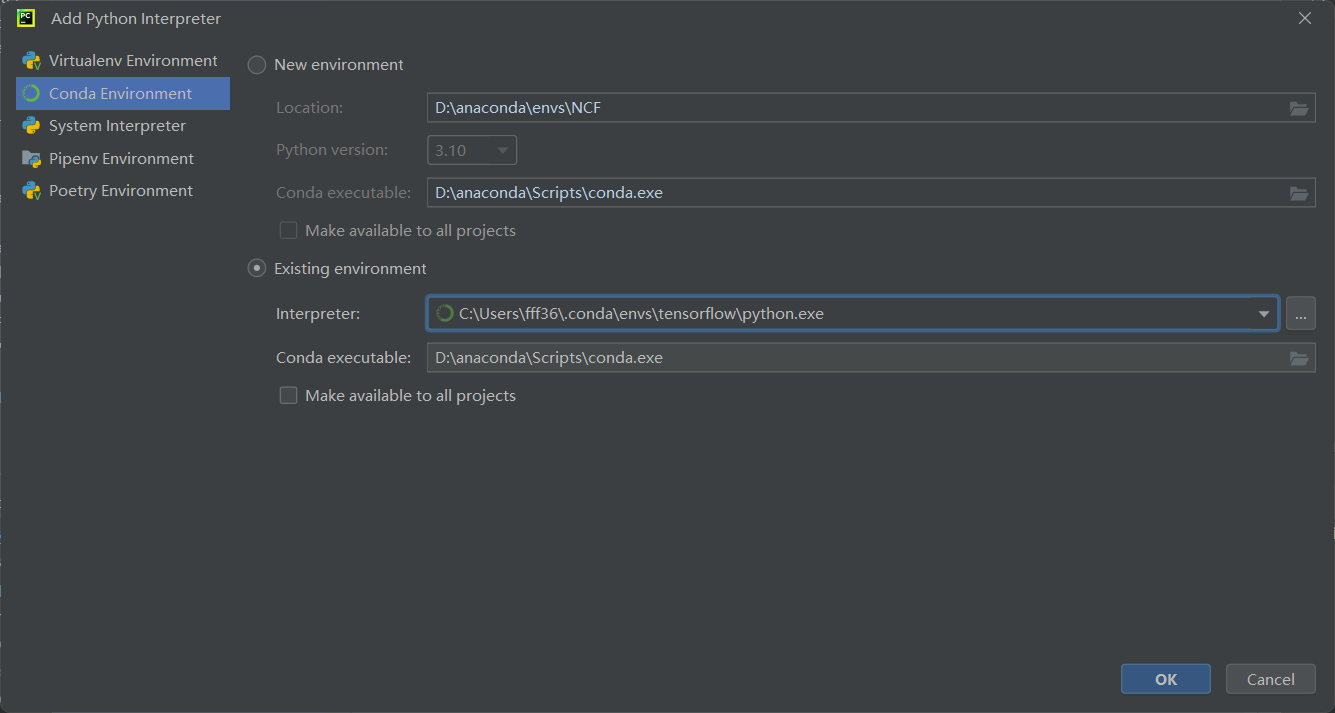
1、安装虚拟环境
conda create -n tensorflow python=3.6.4
conda activate tensorflow
conda install tensorflow=1.12.0
conda install keras=2.1.4

conda info

2、安装相应依赖
cd Py3_Recommender-Systems-Samples-master/RecSysAndDeepLearning/DNN/ncf
运行指令
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
报错:
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
WARNING (theano.configdefaults): g++ not available, if using conda:conda install m2w64-toolchain
C:\Users\fff36\AppData\Roaming\Python\Python310\site-packages\theano\configdefaults.py:560: UserWarning: DeprecationWarning: there is no c++ compiler.This is deprecated and with Theano 0.11 a c++ compiler will be mandatory
warnings.warn(“DeprecationWarning: there is no c++ compiler.”
WARNING (theano.configdefaults): g++ not detected ! Theano will be unable to execute optimized C-implementations (for both CPU and GPU) and will default to Python implementations. Performance will be severely degraded. To remove this warning, set Theano flags cxx to an empty string.
WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
Traceback (most recent call last):
File “D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf\GMF.py”, line 10, in
from keras.layers.core import Dense, Lambda, Activation
ModuleNotFoundError: No module named ‘keras.layers.core’
根据您提供的错误信息,有几个问题需要解决:
-
Theano编译器警告:
Theano在尝试使用C++编译器时遇到了问题。这通常是因为系统中没有安装必要的编译工具链。如果您使用的是Windows系统,可以通过安装m2w64-toolchain来解决这个问题,如警告信息中所建议的。 -
Theano性能警告:
由于缺少g++,Theano无法执行优化的C实现,将默认使用Python实现,这会严重影响性能。解决第一个问题后,这个警告应该也会消失。 -
Keras模块错误:
您遇到了ModuleNotFoundError,表明Python无法找到名为keras.layers.core的模块。这可能是因为Keras库没有正确安装,或者您的环境中存在多个Python版本,导致依赖项安装在了错误的Python版本上。
conda install m2w64-toolchain
验证
g++ --version

conda install theano
搞半天原来是忘记进去tensorflow虚拟环境了
输入指令
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
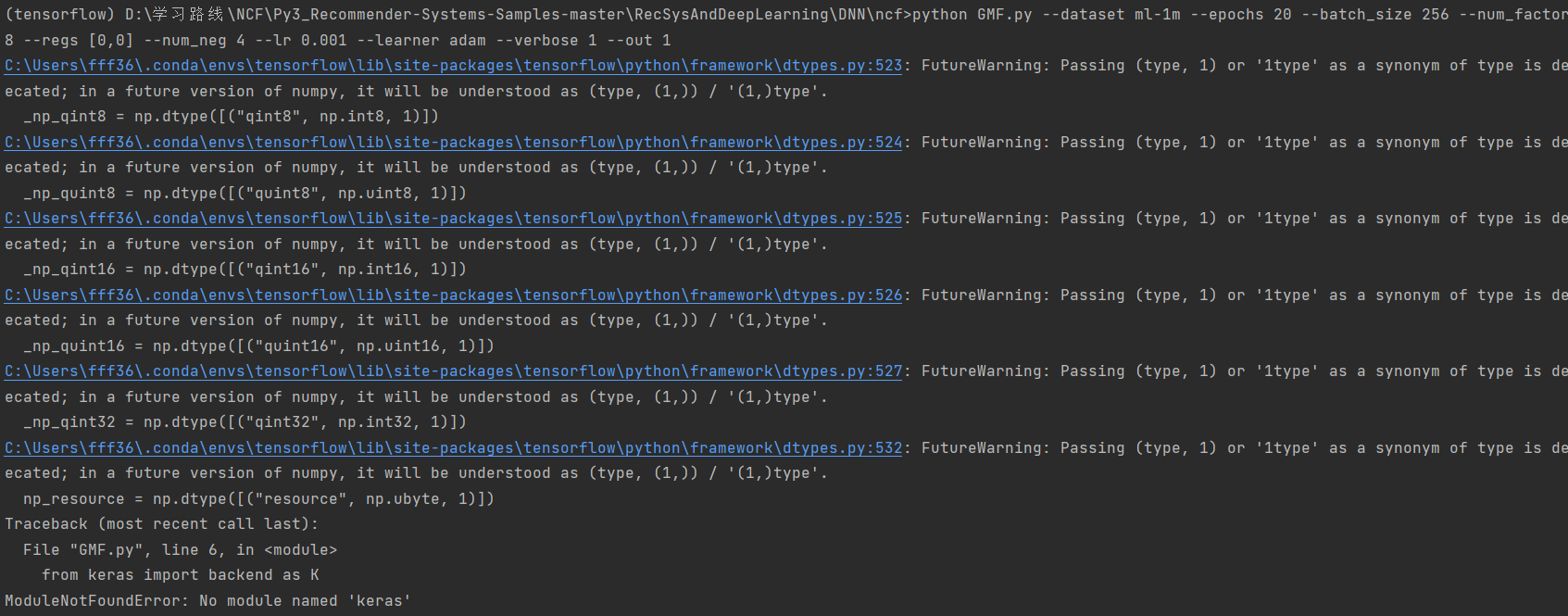
报错:
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:523: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
_np_qint8 = np.dtype([(“qint8”, np.int8, 1)])
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:524: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
_np_quint8 = np.dtype([(“quint8”, np.uint8, 1)])
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:525: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
_np_qint16 = np.dtype([(“qint16”, np.int16, 1)])
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
_np_quint16 = np.dtype([(“quint16”, np.uint16, 1)])
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:527: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
_np_qint32 = np.dtype([(“qint32”, np.int32, 1)])
C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:532: FutureWarning: Passing (type, 1) or ‘1type’ as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / ‘(1,)type’.
np_resource = np.dtype([(“resource”, np.ubyte, 1)])
Traceback (most recent call last):
File “GMF.py”, line 6, in
from keras import backend as K
ModuleNotFoundError: No module named ‘keras’
错误信息显示您遇到了两个主要问题:
-
FutureWarning:
这些警告来自TensorFlow,指出在创建NumPy数据类型时使用了已弃用的方法。这些警告通常不会影响当前代码的运行,但它们提示未来的NumPy版本中将不再支持这种用法。对于TensorFlow来说,这可能意味着在未来的版本中需要更新代码以适应NumPy的新API。 -
ModuleNotFoundError:
这个错误表明Python无法在您的环境中找到名为keras的模块。这可能是因为Keras没有安装,或者安装在了错误的Python环境中。
要解决这些问题,请尝试以下步骤:
-
更新NumPy:
如果您使用的是较旧版本的NumPy,尝试更新到最新版本。您可以使用以下命令来更新NumPy:pip install --upgrade numpy或者,如果您使用conda:
conda update numpy -
安装或更新Keras:
确保Keras已经安装在您当前激活的Python环境中。您可以使用以下命令来安装或更新Keras:pip install --upgrade keras或者,如果您使用conda:
conda install keras请确保您在
tensorflow环境中运行这些命令,以便在正确的环境中安装Keras。
在pycharm终端安装keras
pip install keras==2.1.4
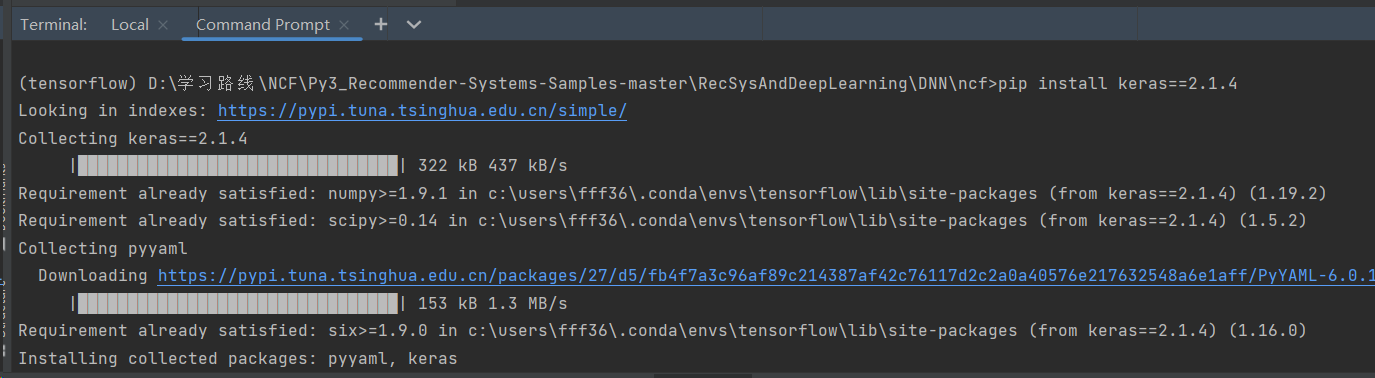
验证安装
python -c "import keras; print(keras.__version__)"
# 2.1.4
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
3、运行GMF.py文件
# 运行成功
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:523: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:524: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\dtypes.py:532: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
Using TensorFlow backend.
regs [0, 0]
GMF arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=20, learner='adam', lr=0.001, num_factors=8, num_neg=4, out=1, path='Data/', regs='[0,0]', verbose=1)
Load data done [9.5 s]. #user=6040, #item=3706, #train=994169, #test=6040
2024-04-10 15:05:18.117373: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Init: HR = 0.1031, NDCG = 0.0473 [3.4 s]
Iteration 0 [28.0 s]: HR = 0.5439, NDCG = 0.3064, loss = 0.3491 [2.8 s]
Iteration 1 [26.8 s]: HR = 0.5772, NDCG = 0.3261, loss = 0.2996 [2.8 s]
从您提供的输出信息来看,您正在运行一个基于神经协同过滤(Neural Collaborative Filtering, NCF)的推荐系统模型,具体是GMF(Generalized Matrix Factorization)模型。这个模型是一种深度学习方法,用于预测用户对物品的评分或偏好,从而进行个性化推荐。
首先,您在运行脚本时遇到了一些FutureWarning,这些警告是由于在numpy的数据类型定义中使用了已弃用的方式。这通常不会影响当前的运行,但是建议更新您的numpy库到最新版本,以避免将来可能的兼容性问题。
接下来,您的模型使用了以下参数:
dataset: ‘ml-1m’,表示使用的是MovieLens 1M数据集,这是一个公开的电影评分数据集。epochs: 20,表示模型将在整个训练集上训练20次。batch_size: 256,表示每次迭代中,模型将处理256个样本。num_factors: 8,表示嵌入向量的维度,这是模型中用于捕捉用户和物品特征的参数数量。regs: ‘[0,0]’, 表示没有使用正则化项,这可能有助于防止过拟合。num_neg: 4,表示对于每个正样本,模型将生成4个负样本进行训练。lr: 0.001,表示学习率,这是优化算法中的一个重要参数,用于控制权重更新的步长。learner: ‘adam’,表示使用的优化器是Adam,这是一种常用的自适应学习率优化算法。verbose: 1,表示训练过程中将输出详细信息。
模型的输出显示了训练过程中的一些关键指标:
HR(Hit Rate):准确率,衡量推荐系统准确性的一个指标。NDCG(Normalized Discounted Cumulative Gain):归一化折扣累积增益,衡量推荐系统质量的另一个指标。loss:损失函数的值,表示模型预测值与实际值之间的差异。
在第一次迭代后,模型的性能有所提升,HR从0.1031提升到0.5439,NDCG从0.0473提升到0.3064,损失从0.3491降低到0.2996。这表明模型正在学习并逐渐改进其预测能力。
然而,您的CPU并不支持TensorFlow二进制文件使用的某些指令集(AVX和AVX2),这可能会影响模型的训练速度。如果可能的话,考虑升级到支持这些指令集的CPU,或者在支持这些指令集的环境中运行您的代码。
最后,请注意,虽然模型性能有所提升,但是这些指标只是初步的评估。为了全面评估模型的性能,您可能需要进行更多的实验,包括交叉验证和长期的性能跟踪。此外,您可能还需要考虑其他评价指标,如精确率、召回率、F1分数等,以及用户的多样性和新颖性等其他因素。
Iteration 4 [30.8 s]: HR = 0.6205, NDCG = 0.3553, loss = 0.2748 [3.1 s]
Iteration 5 [28.9 s]: HR = 0.6255, NDCG = 0.3627, loss = 0.2731 [2.9 s]
Iteration 6 [29.5 s]: HR = 0.6253, NDCG = 0.3609, loss = 0.2722 [3.2 s]
Iteration 7 [29.4 s]: HR = 0.6290, NDCG = 0.3606, loss = 0.2711 [3.0 s]
Iteration 8 [34.3 s]: HR = 0.6298, NDCG = 0.3609, loss = 0.2707 [3.0 s]
Iteration 9 [32.2 s]: HR = 0.6310, NDCG = 0.3605, loss = 0.2704 [3.0 s]
Iteration 10 [33.3 s]: HR = 0.6262, NDCG = 0.3615, loss = 0.2698 [3.1 s]
Iteration 11 [32.3 s]: HR = 0.6301, NDCG = 0.3638, loss = 0.2695 [3.0 s]
Iteration 12 [30.9 s]: HR = 0.6285, NDCG = 0.3635, loss = 0.2693 [3.0 s]
Iteration 13 [32.9 s]: HR = 0.6293, NDCG = 0.3628, loss = 0.2689 [3.2 s]
Iteration 14 [30.7 s]: HR = 0.6318, NDCG = 0.3641, loss = 0.2689 [3.1 s]
Iteration 15 [32.2 s]: HR = 0.6326, NDCG = 0.3637, loss = 0.2684 [3.0 s]
Iteration 16 [32.6 s]: HR = 0.6336, NDCG = 0.3645, loss = 0.2680 [3.2 s]
Iteration 17 [31.1 s]: HR = 0.6318, NDCG = 0.3640, loss = 0.2682 [4.0 s]
Iteration 18 [40.0 s]: HR = 0.6288, NDCG = 0.3628, loss = 0.2679 [3.2 s]
Iteration 19 [37.0 s]: HR = 0.6315, NDCG = 0.3650, loss = 0.2679 [3.1 s]
End. Best Iteration 16: HR = 0.6336, NDCG = 0.3645.
The best GMF model is saved to Pretrain/ml-1m_GMF_8_1712732708.h5
numpy版本有问题
从您提供的输出信息来看,您正在运行一个基于神经协同过滤(Neural Collaborative Filtering, NCF)的推荐系统模型,具体是GMF(Generalized Matrix Factorization)模型。这个模型是一种深度学习方法,用于预测用户对物品的评分或偏好,从而进行个性化推荐。
首先,您在运行脚本时遇到了一些FutureWarning,这些警告是由于在numpy的数据类型定义中使用了已弃用的方式。这通常不会影响当前的运行,但是建议更新您的numpy库到最新版本,以避免将来可能的兼容性问题。
python -c "import numpy; print(numpy.__version__)"
1.19.2
pip install --upgrade numpy

还是不行
pip uninstall numpy
pip install numpy==1.14.0
运行文件
python GMF.py --dataset ml-1m --epochs 5 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python GMF.py --dataset ml-1m --epochs 5 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\scipy\__init__.py:143: UserWarning: NumPy 1.14.5 or above is required for this version of SciPy (detected version 1.14.0)
UserWarning)
Using TensorFlow backend.
regs [0, 0]
GMF arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=5, learner='adam', lr=0.001, num_factors=8, num_neg=4, out=1, path='Data/', regs='[0,0]', verbose=1)
Load data done [9.6 s]. #user=6040, #item=3706, #train=994169, #test=6040
2024-04-10 15:24:04.050450: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Init: HR = 0.0969, NDCG = 0.0438 [2.8 s]
Iteration 1 [27.0 s]: HR = 0.5806, NDCG = 0.3264, loss = 0.3016 [2.8 s]
Iteration 2 [26.0 s]: HR = 0.6101, NDCG = 0.3464, loss = 0.2855 [2.9 s]
Iteration 3 [25.5 s]: HR = 0.6215, NDCG = 0.3595, loss = 0.2778 [2.7 s]
Iteration 4 [25.7 s]: HR = 0.6207, NDCG = 0.3613, loss = 0.2748 [2.9 s]
End. Best Iteration 3: HR = 0.6215, NDCG = 0.3595.
The best GMF model is saved to Pretrain/ml-1m_GMF_8_1712733834.h5
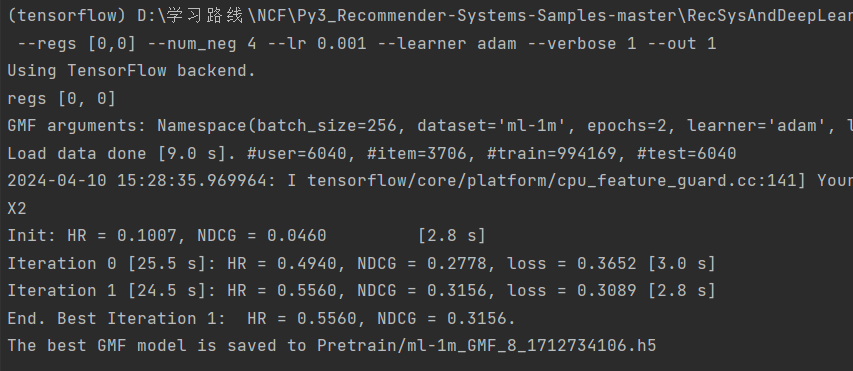
最终numpy改成1.14.5版本
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python GMF.py --dataset ml-1m --epochs 2 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
Using TensorFlow backend.
regs [0, 0]
GMF arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=2, learner='adam', lr=0.001, num_factors=8, num_neg=4, out=1, path='Data/', regs='[0,0]', verbose=1)
Load data done [9.0 s]. #user=6040, #item=3706, #train=994169, #test=6040
2024-04-10 15:28:35.969964: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Init: HR = 0.1007, NDCG = 0.0460 [2.8 s]
Iteration 0 [25.5 s]: HR = 0.4940, NDCG = 0.2778, loss = 0.3652 [3.0 s]
Iteration 1 [24.5 s]: HR = 0.5560, NDCG = 0.3156, loss = 0.3089 [2.8 s]
End. Best Iteration 1: HR = 0.5560, NDCG = 0.3156.
The best GMF model is saved to Pretrain/ml-1m_GMF_8_1712734106.h5
4、运行MLP.py文件
将epochs 改成3
python MLP.py --dataset ml-1m --epochs 3 --batch_size 256 --layers [64,32,16,8] --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python MLP.py --dataset ml-1m --epochs 3 --batch_size 256 --layers [64,32,16,8] --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
Using TensorFlow backend.
[64, 32, 16, 8] <class 'int'>
[0, 0, 0, 0] <class 'int'>
MLP arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=3, layers='[64,32,16,8]', learner='adam', lr=0.001, num_neg=4, out=1, path='Data/', reg_layers='[0,0,0,0]', verbose=1)
Load data done [9.0 s]. #user=6040, #item=3706, #train=994169, #test=6040
MLP.py:77: UserWarning: Update your `Dense` call to the Keras 2 API: `Dense(32, activation="relu", name="layer1", kernel_regularizer=<keras.reg...)`
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
MLP.py:77: UserWarning: Update your `Dense` call to the Keras 2 API: `Dense(16, activation="relu", name="layer2", kernel_regularizer=<keras.reg...)`
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
MLP.py:77: UserWarning: Update your `Dense` call to the Keras 2 API: `Dense(8, activation="relu", name="layer3", kernel_regularizer=<keras.reg...)`
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
MLP.py:81: UserWarning: Update your `Dense` call to the Keras 2 API: `Dense(1, activation="sigmoid", name="prediction", kernel_initializer="lecun_uniform")`
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = 'prediction')(vector)
MLP.py:84: UserWarning: Update your `Model` call to the Keras 2 API: `Model(inputs=[<tf.Tenso..., outputs=Tensor("pr...)`
output=prediction)
2024-04-10 15:33:21.743994: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Init: HR = 0.0990, NDCG = 0.0444 [3.2]
MLP.py:161: UserWarning: The `nb_epoch` argument in `fit` has been renamed `epochs`.
batch_size=batch_size, nb_epoch=1, verbose=0, shuffle=True)
Iteration 0 [56.2 s]: HR = 0.5219, NDCG = 0.2913, loss = 0.3453 [4.9 s]
Iteration 1 [59.5 s]: HR = 0.5844, NDCG = 0.3261, loss = 0.3052 [3.2 s]
Iteration 2 [58.8 s]: HR = 0.6149, NDCG = 0.3482, loss = 0.2850 [3.2 s]
End. Best Iteration 2: HR = 0.6149, NDCG = 0.3482.
The best MLP model is saved to Pretrain/ml-1m_MLP_[64,32,16,8]_1712734392.h5
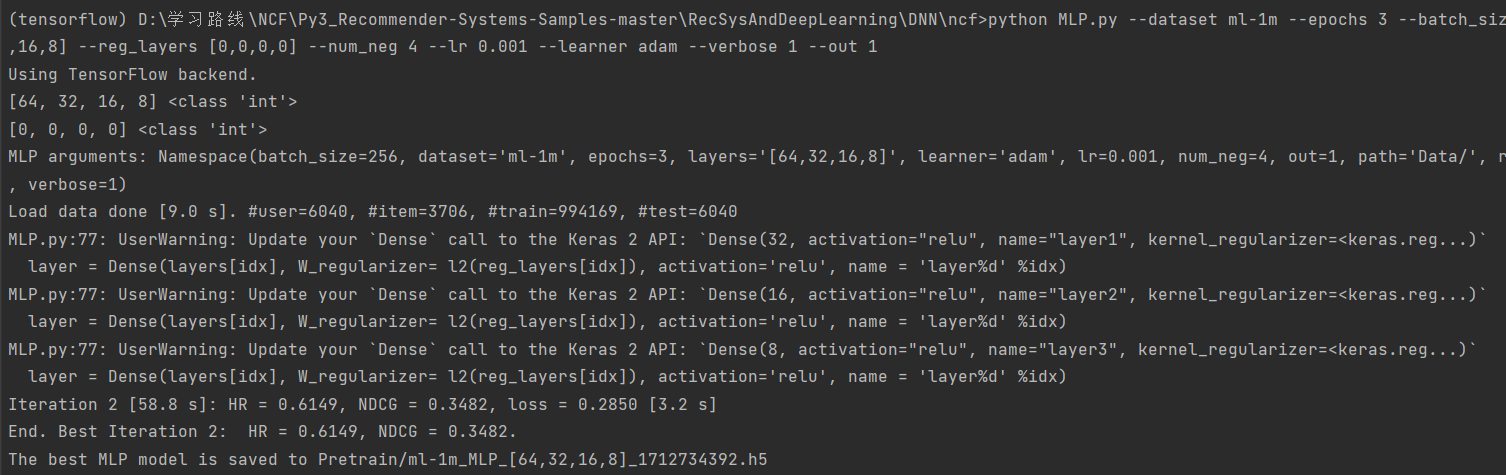
5、运行NeuMF.py文件
(1)无需预训练版
Run NeuMF (without pre-training):
运行 NeuMF(无需预训练):
python NeuMF.py --dataset ml-1m --epochs 3 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --reg_mf 0 --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python NeuMF.py --dataset ml-1m --epochs 3 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --reg_mf 0 --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1
Using TensorFlow backend.
NeuMF arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=3, layers='[64,32,16,8]', learner='adam', lr=0.001, mf_pretrain='', mlp_pretrain='', num_factors=8, num_neg=4, out=1, path='Data/', reg_layers='[0,0,0,0]', reg_mf=0.0, verbose=1)
Load data done [8.9 s]. #user=6040, #item=3706, #train=994169, #test=6040
2024-04-10 15:37:11.316083: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
Init: HR = 0.1005, NDCG = 0.0450
Iteration 0 [62.3 s]: HR = 0.6022, NDCG = 0.3411, loss = 0.3182 [4.3 s]
Iteration 1 [62.6 s]: HR = 0.6343, NDCG = 0.3651, loss = 0.2726 [3.7 s]
Iteration 2 [66.1 s]: HR = 0.6522, NDCG = 0.3830, loss = 0.2627 [4.1 s]
End. Best Iteration 2: HR = 0.6522, NDCG = 0.3830.
The best NeuMF model is saved to Pretrain/ml-1m_NeuMF_8_[64,32,16,8]_1712734622.h5
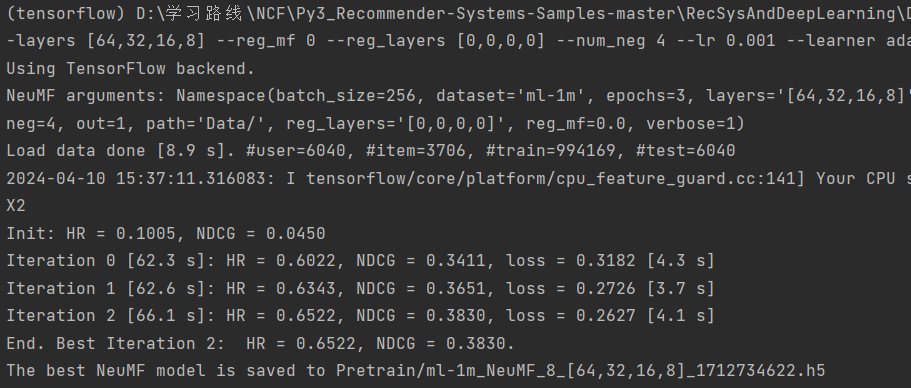
(2)预训练版
Run NeuMF (with pre-training):
运行 NeuMF(带预训练):
python NeuMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1 --mf_pretrain Pretrain/ml-1m_GMF_8_1501651698.h5 --mlp_pretrain Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5
(tensorflow) D:\学习路线\NCF\Py3_Recommender-Systems-Samples-master\RecSysAndDeepLearning\DNN\ncf>python NeuMF.py --dataset ml-1m --epochs 3 --batch_size 256 --num_factors-layers [64,32,16,8] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1 --mf_pretrain Pretrain/ml-1m_GMF_8_1501651698.h5 --mlp_pretrain Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5
Using TensorFlow backend.
NeuMF arguments: Namespace(batch_size=256, dataset='ml-1m', epochs=3, layers='[64,32,16,8]', learner='adam', lr=0.001, mf_pretrain='Pretrain/ml-1m_GMF_8_1501651698.h5', mlp_pretrain='Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5', num_factors=8, num_neg=4, out=1, path='Data/', reg_layers='[0,0,0,0]', reg_mf=0, verbose=1)
Load data done [11.7 s]. #user=6040, #item=3706, #train=994169, #test=6040
Traceback (most recent call last):
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 1628, in _create_c_op
c_op = c_api.TF_FinishOperation(op_desc)
tensorflow.python.framework.errors_impl.InvalidArgumentError: Dimension 0 in both shapes must be equal, but are 6040 and 3706. Shapes are [6040,8] and [3706,8]. for 'Assign' (op: 'Assign') with input shapes: [6040,8], [3706,8].
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "NeuMF.py", line 194, in <module>
gmf_model.load_weights(mf_pretrain)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\keras\engine\topology.py", line 2652, in load_weights
f, self.layers, reshape=reshape)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\keras\engine\topology.py", line 3189, in load_weights_from_hdf5_group
K.batch_set_value(weight_value_tuples)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\keras\backend\tensorflow_backend.py", line 2365, in batch_set_value
assign_op = x.assign(assign_placeholder)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\ops\variables.py", line 1718, in assign
name=name)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\ops\state_ops.py", line 221, in assign
validate_shape=validate_shape)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\ops\gen_state_ops.py", line 60, in assign
use_locking=use_locking, name=name)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\util\deprecation.py", line 488, in new_func
return func(*args, **kwargs)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 3274, in create_op
op_def=op_def)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 1792, in __init__
control_input_ops)
File "C:\Users\fff36\.conda\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 1631, in _create_c_op
raise ValueError(str(e))
ValueError: Dimension 0 in both shapes must be equal, but are 6040 and 3706. Shapes are [6040,8] and [3706,8]. for 'Assign' (op: 'Assign') with input shapes: [6040,8], [3706,8].
为什么预训练会报错
输入python NeuMF.py --dataset ml-1m --epochs 3 --batch_size 256 --num_factors 8 --layers [64,32,16,8] --num_neg 4 --lr 0.001 --learner adam --verbose 1 --out 1 --mf_pretrain Pretrain/ml-1m_GMF_8_1501651698.h5 --mlp_pretrain Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5
然后报错:
使用预训练的GMF和MLP模型权重来初始化NeuMF模型时遇到了错误。错误信息表明,在尝试加载预训练权重时,模型的形状不匹配。具体来说,预训练的GMF模型的权重形状是[6040, 8],这意味着它预期用户数量为6040,而预训练的MLP模型的权重形状是[3706, 8],意味着它预期物品数量为3706。
5、与原代码的不同之处
(1)权重初始化
在新版本的Keras中,权重初始化通常直接在模型层的定义中进行,而不是通过一个单独的函数来完成。例如,您可以在定义层时直接使用 kernel_initializer 参数来指定初始化方法,如 RandomNormal 或 XavierNormal6。这种改变使得模型的构建和权重初始化更加直观和模块化。
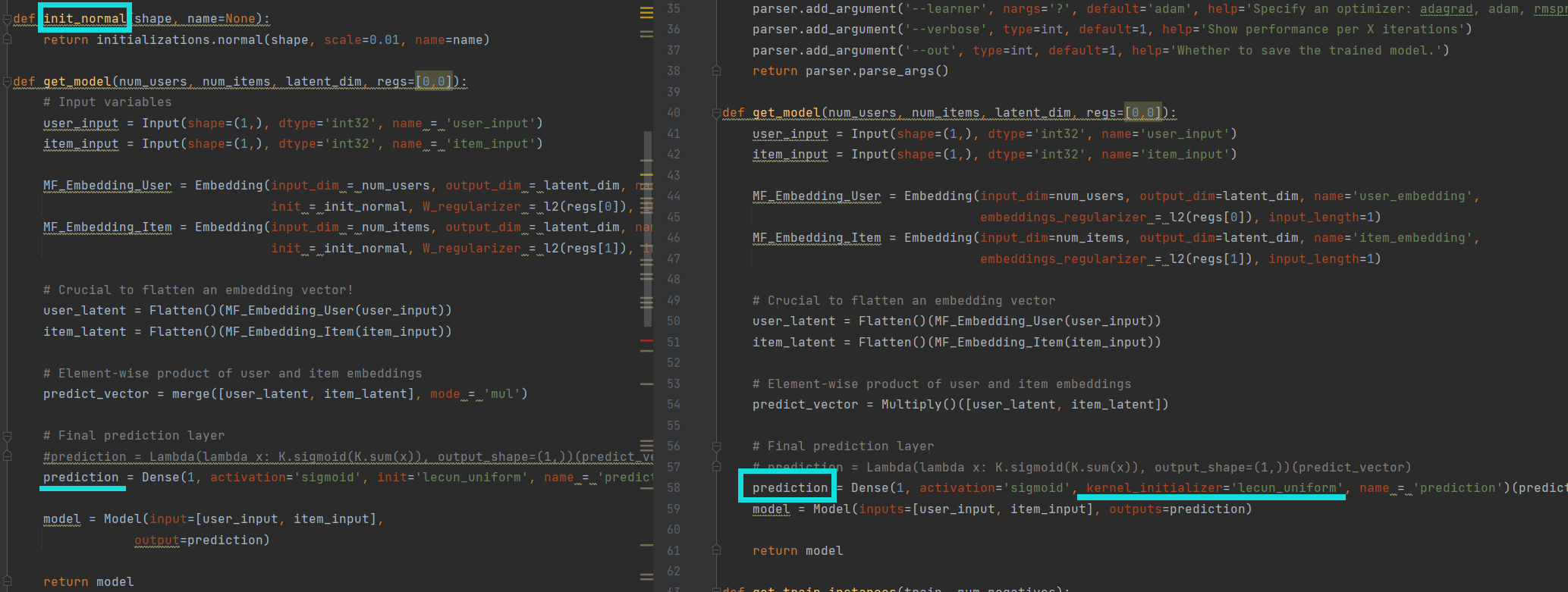
(2)后端的使用
不再使用theano
6、代码细微更新处_f
运行MLP.py的警告:
D:/推荐/NCF/ncf(理解版)/MLP.py:66: UserWarning: Update yourDensecall to the Keras 2 API:Dense(32, activation="relu", name="layer1", kernel_regularizer=<keras.reg...)
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation=‘relu’, name = ‘layer%d’ %idx)显示报错
警告信息提示您需要更新代码中的 Dense 层调用方式,以适应 Keras 2 的 API。在 Keras 2 中,正则化器的使用方式有所改变,您需要使用 kernel_regularizer 而不是 W_regularizer。要解决这个问题,您应该将所有的
W_regularizer=l2(reg_layers[idx]) 替换为 kernel_regularizer=l2(reg_layers[idx])。同时,确保您已经从 keras.regularizers 导入了 l2 正则化器。
运行MLP.py的警告:
Traceback (most recent call last):
File “D:/推荐/NCF/ncf(理解版)/MLP.py”, line 150, in
batch_size=batch_size, nb_epoch=1, perform_display_interval=0, shuffle=True)
File “C:\Users\fff36.conda\envs\tensorflow\lib\site-packages\keras\engine\training.py”, line 1627, in fit
raise TypeError('Unrecognized keyword arguments: ’ + str(kwargs))
TypeError: Unrecognized keyword arguments: {‘perform_display_interval’: 0}
这个错误信息表明在调用 model.fit 方法时,传递了一个不再被识别的关键字参数 perform_display_interval。在较新版本的 Keras 中,nb_epoch 参数已经被重命名为 epochs,同时 perform_display_interval 不是 fit 方法的有效参数。在您提供的代码片段中,perform_display_interval 应该是用于自定义训练过程中性能信息显示间隔的参数,但是它不是 model.fit 方法的标准参数。如果您想要在训练过程中显示性能信息,应该使用 verbose 参数或者使用回调函数(如 LambdaCallback)来自定义输出
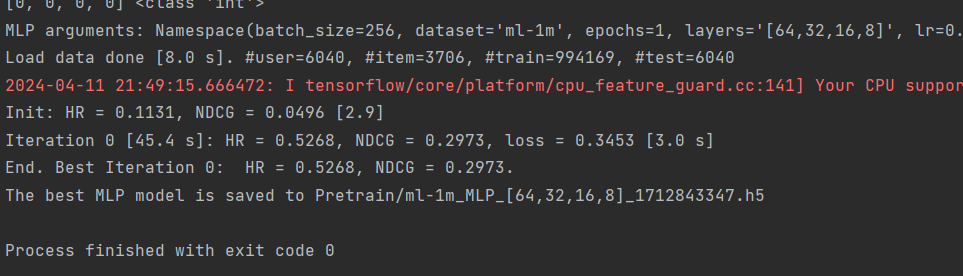
更改后无任何警告。
二、成功运行且无警告的代码
1、GMF
python GMF.py --dataset ml-1m --epochs 20 --batch_size 256 --num_factors 8 --regs [0,0] --num_neg 4 --lr 0.001 --optimizer_selected adam --verbose 1 --whether_save_model 1
# -*- coding: utf-8 -*-
import numpy as np
from keras.models import Model
# Embedding: 嵌入层,用于处理分类数据,将其转换为密集向量(embeddings)。
# Input: 输入层,用于定义模型的输入层,指定输入数据的形状。
# Flatten: 展平层,用于将多维输入数据展平为一维。
# Multiply: 乘法层,用于执行输入张量的逐元素乘法
from keras.layers import Embedding, Input, Flatten, Multiply
from keras.layers.core import Dense
# Adagrad 适用于稀疏数据集,因为它会为频繁更新的参数分配较小的学习率,而为更新较少的参数分配较大的学习率。
# Adam 计算每个参数的自适应学习率
# 在每次迭代中随机选择一个小批量样本来计算梯度,并更新模型的权重
# 通过除以过去梯度的移动平均的平方根来调整学习率。这种方法有助于解决学习率选择不当导致的收敛问题
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
# L2正则化器,用于添加权重衰减,防止过拟合
from keras.regularizers import l2
# 自定义模块
from Dataset import Dataset
from evaluate import evaluate_model
# Python标准库中的模块
from time import time
import argparse
import warnings
warnings.filterwarnings("ignore")
# 使用argparse库来解析命令行参数
def parse_args():
# 创建ArgumentParser解析器对象
parser = argparse.ArgumentParser(description='Run GMF')
# 向解析器对象添加一个新的参数
# nargs = '?'表示可选
parser.add_argument('--path', nargs='?', default='Data/', help='Input data path')
parser.add_argument('--dataset', nargs='?', default='ml-1m', help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=1, help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256, help='Batch size.')
parser.add_argument('--embedding_dimension', type=int, default=8, help='Embedding dimension.即隐含特征的数量')
parser.add_argument('--regs', nargs='?', default='[0,0]', help="Regularization for user and item embeddings.")
parser.add_argument('--num_neg', type=int, default=4, help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001, help='Learning rate.')
parser.add_argument('--optimizer_selected', nargs='?', default='adam', help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1, help='控制每多少次迭代显示一次性能信息')
parser.add_argument('--whether_save_model', type=int, default=1, help='Whether to save the trained model.')
# parse_args方法会解析命令行输入的参数,并返回一个包含这些参数的命名空间(Namespace 对象)
return parser.parse_args()
# 定义了一个名为get_model的函数,用于创建GMF模型
def get_model(users_dimension, items_dimension, latent_dim, regs=[0,0]):
# name表示这一网络层的名字
# 定义了输入数据的结构和预期的输入格式
user_input = Input(shape=(1,), dtype='int32', name='user_input')
item_input = Input(shape=(1,), dtype='int32', name='item_input')
# 定义嵌入层,将用户、物品ID映射到潜在向量
MF_Embedding_User = Embedding(input_dim=users_dimension, output_dim=latent_dim, name='user_embedding',
embeddings_regularizer = l2(regs[0]), input_length=1)
MF_Embedding_Item = Embedding(input_dim=items_dimension, output_dim=latent_dim, name='item_embedding',
embeddings_regularizer = l2(regs[1]), input_length=1)
# 将输入张量展平:因为点积需要在一维数组上执行
user_latent = Flatten()(MF_Embedding_User(user_input))
item_latent = Flatten()(MF_Embedding_Item(item_input))
# Element-wise product of user and item embeddings
# 计算用户和物品潜在向量的逐元素乘积
predict_vector = Multiply()([user_latent, item_latent])
# 定义输出层,使用sigmoid激活函数输出单个预测值
# Dense: Keras中用于创建全连接层的类。
# 1: 层中的神经元数量,这里是1,因为我们只需要一个输出。
# activation = 'sigmoid': 激活函数,用于将输出值限制在0到1之间。
# kernel_initializer = 'lecun_uniform': 权重初始化方法,使用LeCun均匀分布。
# predict_vector: 传递给Dense层的输入张量。
prediction = Dense(1, activation='sigmoid', kernel_initializer='lecun_uniform', name = 'prediction')(predict_vector)
# 创建模型实例,将输入层和输出层连接起来
model = Model(inputs=[user_input, item_input], outputs=prediction)
return model
# 生成训练实例
# 从训练数据中提取正例和负例,并将它们分别存储在不同的列表中
# train:包含用户-物品评分对的字典或类似数据结构。
def get_train_instances(train, num_negatives):
# 初始化三个空列表,用于存储用户ID、物品ID和对应的标签(1表示正例,0表示负例)
user_input, item_input, labels = [], [], []
# 获取训练数据中物品的总数
items_num = train.shape[1]
# 遍历 train 字典的键,其中 u 是用户ID,i 是物品ID
for u, i in train.keys():
# positive instance
# 将当前的正例(用户-物品对和评分)添加到相应的列表中。
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
# 此循环用于 为每个正例生成 指定数量的负例
for t in range(num_negatives):
# 生成一个介于 0 到 items_num - 1 之间的随机整数,代表数据集中的一个随机物品ID
j = np.random.randint(items_num)
# while循环目的:确保生成的负例物品ID不存在于 train 中的任何正例中
# 如果生成的ID是一个正例ID
while (u,j) in train:
# 则重新循环生成新的随机ID,直到找到一个未在正例中出现的ID
j = np.random.randint(items_num)
# 将生成的负例添加到列表中
user_input.append(u)
item_input.append(j)
labels.append(0)
# 将三个列表作为元组返回,包含所有的用户ID、物品ID和标签。
# 这些数据将用于模型的训练,以学习区分正例和负例
return user_input, item_input, labels
# 只有当脚本作为主程序运行时,以下代码块才会执行(而不是作为模块导入时)
if(__name__ == '__main__'):
# 解析命令行参数
args = parse_args()
embedding_dimension = args.embedding_dimension
regs = eval(args.regs);print('regs', regs)
num_negatives = args.num_neg
optimizer_selected = args.optimizer_selected
learning_rate = args.lr
epochs = args.epochs
batch_size = args.batch_size
verbose = args.verbose
# 评估模型时考虑的 top-K 推荐列表的长度
topK = 10
# 用于评估模型的线程数
evaluation_threads = 1
# 打印出所有的命令行参数
# % 操作符的格式化用法
# 将 args 变量的值转换为字符串,并替换前面的 %s 占位符
# args 变量是一个命名空间对象,包含了通过 argparse 库解析的命令行参数
print('GMF arguments: %s' % (args))
# 定义了模型输出文件的名称,包含数据集名称、嵌入维度和当前时间戳。
model_out_file = 'Pretrain/%s_GMF_%d_%d.h5' %(args.dataset, embedding_dimension, time())
# load datasets
# 记录开始加载数据的时间
t1 = time()
# 创建 Dataset 类的实例
dataset = Dataset(args.path + args.dataset)
# 从数据集中提取训练、测试评分和测试负样本数据
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
# 获取训练数据的形状,以确定用户和物品的维度
users_dimension, items_dimension = train.shape
# 打印加载数据所花费的时间,以及训练集中的用户数、物品数、非零元素的数量(train.nnz)和测试集中的样本数
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, users_dimension, items_dimension, train.nnz, len(testRatings)))
# build model:调用 get_model() 函数构建模型
model = get_model(users_dimension, items_dimension, embedding_dimension, regs)
# 根据 optimizer_selected 的值,使用不同的优化器(Adagrad、RMSprop、Adam 或 SGD)
# 并设置损失函数为二元交叉熵(binary_crossentropy)
if optimizer_selected.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
# 初始性能
# 记录开始训练的时间
t1 = time()
# 使用 evaluate_model() 函数评估模型的初始性能
# 计算 (HR) 和 (NDCG) 的平均值,并打印
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f\t [%.1f s]' % (hr, ndcg, time()-t1))
# train model
# 初始化最佳性能变量
best_hr, best_ndcg, best_iter = hr, ndcg, -1
for epoch in range(epochs):
# 记录训练开始的时间
t1 = time()
# 调用 get_train_instances 函数生成训练实例
user_input, item_input, labels = get_train_instances(train, num_negatives)
# 训练模型
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, nb_epoch=1, verbose=0, shuffle=True)
# 记录训练结束后的时间
t2 = time()
# Evaluation:评估和打印信息
# 每隔 verbose 指定的次数打印一次性能信息
if epoch %verbose == 0:
# 调用 evaluate_model 函数评估模型性能
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
# 计算平均的HR、NDCG和损失值
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
# 打印当前迭代的性能信息,包括迭代次数、所需时间、HR、NDCG和损失值
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
# 如果当前的HR值高于之前记录的最佳HR值,则更新最佳性能变量,并记录当前的迭代次数
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
# 如果命令行参数 whether_save_model 大于0,则保存当前最佳模型到指定的文件路径
if args.whether_save_model > 0:
model.save_weights(model_out_file, overwrite=True)
# 打印训练结束信息和最佳迭代的性能
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
# 如果命令行参数 whether_save_model 大于0,则打印模型保存的位置信息
if args.whether_save_model > 0:
print("The best GMF model is saved to %s" %(model_out_file))
2、MLP
python MLP.py --dataset ml-1m --epochs 3 --batch_size 256 --layers [64,32,16,8] --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --optimizer_selected adam --verbose 1 --whether_save_model 1
'''
Created on Aug 9, 2016
Keras Implementation of Multi-Layer Perceptron (GMF) recommender model in:
He Xiangnan et al. Neural Collaborative Filtering. In WWW 2017.
@author: Xiangnan He (xiangnanhe@gmail.com)
'''
import numpy as np
from keras.regularizers import l2
from keras.models import Model
from keras.layers import Embedding, Input, Dense,Flatten,Concatenate
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from evaluate import evaluate_model
from Dataset import Dataset
from time import time
import argparse
def parse_args():
parser = argparse.ArgumentParser(description="Run MLP.")
parser.add_argument('--path', nargs='?', default='Data/',
help='Input data path.')
parser.add_argument('--dataset', nargs='?', default='ml-1m',
help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=4,
help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256,
help='Batch size.')
parser.add_argument('--layers', nargs='?', default='[64,32,16,8]',
help="Size of each layer. Note that the first layer is the concatenation of user and item embeddings. So layers[0]/2 is the embedding size.")
parser.add_argument('--reg_layers', nargs='?', default='[0,0,0,0]',
help="Regularization for each layer")
parser.add_argument('--num_neg', type=int, default=4,
help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001,
help='Learning rate.')
parser.add_argument('--optimizer_selected', nargs='?', default='adam',
help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1,
help='控制每多少次迭代显示一次性能信息')
parser.add_argument('--whether_save_model', type=int, default=1,
help='Whether to save the trained model.')
return parser.parse_args()
# layers列表,包含每个隐藏层的神经元数量
def get_model(users_dimension, items_dimension, layers, reg_layers):
# 用于断言一个条件是否为真,以确保 layers 和 reg_layers 列表的长度相同
assert len(layers) == len(reg_layers)
# 将MLP层数传入变量中
num_layer = len(layers)
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# layers[0]/2因为上面默认设置layers=[64,32,16,8]即第一个隐藏层有64个神经元
# 而要保证第一层的输入是64,也就是用户和物品连接后的嵌入向量为64
# 就要让嵌入层的输出向量(即 用户嵌入向量,物品嵌入向量都为32)也就是让输出维度=layers[0]/2
MLP_Embedding_User = Embedding(input_dim = users_dimension, output_dim = int(layers[0]/2), name = 'user_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = items_dimension, output_dim = int(layers[0]/2), name = 'item_embedding',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# 使用 Flatten 层将用户和物品的嵌入向量展平
user_latent = Flatten()(MLP_Embedding_User(user_input))
item_latent = Flatten()(MLP_Embedding_Item(item_input))
# 将用户和物品的展平嵌入向量在最后一个轴上(即特征轴)拼接起来
vector = Concatenate(axis=-1)([user_latent, item_latent])
# 循环创建 MLP 的后续隐藏层
for idx in range(1, num_layer):
# 每个隐藏层都是一个 Dense 层,具有指定数量的神经元layers[idx](由 layers 列表中的元素指定)
# 使用 L2 正则化,激活函数为 'relu'
layer = Dense(layers[idx], kernel_regularizer=l2(reg_layers[idx]), activation='relu', name = 'layer%d' %idx)
vector = layer(vector)
# Final prediction layer
# 在训练开始之前为网络中的权重赋予初始值,选择合适的权重初始化方法有利于模型的训练和收敛
# lecun_uniform权重初始化方法,它根据 LeCun 等人在一篇论文中提出的均匀分布初始化方命名
# 从均匀分布 U(-a, a) 中随机选择权重的初始值
prediction = Dense(1, activation='sigmoid',
kernel_initializer='lecun_uniform',
name = 'prediction')(vector)
model = Model(inputs=[user_input, item_input],
outputs=prediction)
return model
# 生成负例的目的是为了模拟用户对未交互物品的不感兴趣或不喜欢的情况
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [],[],[]
items_dimension = train.shape[1]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(items_dimension)
while (u, j) in train:
j = np.random.randint(items_dimension)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
if __name__ == '__main__':
# 解析命令行参数,并将解析后的参数赋值给变量 args
args = parse_args()
path = args.path
dataset = args.dataset
# eval() 函数将字符串形式的参数转换为 Python 对象
layers = eval(args.layers)
# print(layers, type(layers[0]))
reg_layers = eval(args.reg_layers)
# print(reg_layers, type(reg_layers[0]))
num_negatives = args.num_neg
optimizer_selected = args.optimizer_selected
learning_rate = args.lr
batch_size = args.batch_size
epochs = args.epochs
verbose = args.verbose
topK = 10
evaluation_threads = 1 #mp.cpu_count()
print("MLP arguments: %s " %(args))
model_out_file = 'Pretrain/%s_MLP_%s_%d.h5' %(args.dataset, args.layers, time())
# Loading data
t1 = time()
dataset = Dataset(args.path + args.dataset)
# 从数据集中提取训练、测试评分和测试负样本数
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
users_dimension, items_dimension = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, users_dimension, items_dimension, train.nnz, len(testRatings)))
# Build model
model = get_model(users_dimension, items_dimension, layers, reg_layers)
if optimizer_selected.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
# Check Init performance
t1 = time()
# 模型、测试评分数据、测试负样本数据
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f [%.1f]' %(hr, ndcg, time()-t1))
# Train model
best_hr, best_ndcg, best_iter = hr, ndcg, -1
for epoch in range(epochs):
t1 = time()
# Generate training instances
user_input, item_input, labels = get_train_instances(train, num_negatives)
# Training
hist = model.fit( [np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, epochs=1, verbose=0, shuffle=True)
t2 = time()
# Evaluation
# 控制每隔多少个epoch进行一次模型性能的评估和打印
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
# 计算当前的hr、ndcg平均值
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
# 当前的平均hr高于之前记录的最佳
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
# 如果命令行参数whether_save_model大于0,则执行以下操作
if args.whether_save_model > 0:
# 保存当前最佳模型的权重到model_out_file指定的文件路径
# overwrite = True参数表示如果文件已存在,则覆盖它
model.save_weights(model_out_file, overwrite=True)
# 训练结束后,打印最佳迭代的信息
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
# 如果whether_save_model大于0,再次确认最佳模型是否已经保存到model_out_file指定的文件路径,并打印相关信息
if args.whether_save_model > 0:
print("The best MLP model is saved to %s" %(model_out_file))
3、NeuMF
无预训练
python NeuMF.py --dataset ml-1m --epochs 3 --batch_size 256 --embedding_dimension 8 --layers [64,32,16,8] --reg_mf 0 --reg_layers [0,0,0,0] --num_neg 4 --lr 0.001 --optimizer_selected adam --verbose 1 --whether_save_model 1
预训练版
python NeuMF.py --dataset ml-1m --epochs 20 --batch_size 256 --embedding_dimension 8 --layers [64,32,16,8] --num_neg 4 --lr 0.001 --optimizer_selected adam --verbose 1 --whether_save_model 1 --mf_pretrain Pretrain/ml-1m_GMF_8_1501651698.h5 --mlp_pretrain Pretrain/ml-1m_MLP_[64,32,16,8]_1501652038.h5
'''
Created on Aug 9, 2016
Keras Implementation of Neural Matrix Factorization (NeuMF) recommender model in:
He Xiangnan et al. Neural Collaborative Filtering. In WWW 2017.
@author: Xiangnan He (xiangnanhe@gmail.com)
'''
import numpy as np
from keras.regularizers import l2
from keras.models import Model
from keras.layers import Embedding, Input, Dense,Multiply, Flatten, Concatenate
from keras.optimizers import Adagrad, Adam, SGD, RMSprop
from time import time
import argparse
from Dataset import Dataset
from evaluate import evaluate_model
import GMF,MLP
def parse_args():
parser = argparse.ArgumentParser(description="Run NeuMF.")
parser.add_argument('--path', nargs='?', default='Data/',
help='Input data path.')
parser.add_argument('--dataset', nargs='?', default='ml-1m',
help='Choose a dataset.')
parser.add_argument('--epochs', type=int, default=1,
help='Number of epochs.')
parser.add_argument('--batch_size', type=int, default=256,
help='Batch size.')
parser.add_argument('--embedding_dimension', type=int, default=8,
help='Embedding size of MF model.')
parser.add_argument('--layers', nargs='?', default='[64,32,16,8]',
help="MLP layers. Note that the first layer is the concatenation of user and item embeddings. So layers[0]/2 is the embedding size.")
parser.add_argument('--reg_mf', type=float, default=0,
help='Regularization for MF embeddings.')
parser.add_argument('--reg_layers', nargs='?', default='[0,0,0,0]',
help="Regularization for each MLP layer. reg_layers[0] is the regularization for embeddings.")
parser.add_argument('--num_neg', type=int, default=4,
help='Number of negative instances to pair with a positive instance.')
parser.add_argument('--lr', type=float, default=0.001,
help='Learning rate.')
parser.add_argument('--optimizer_selected', nargs='?', default='adam',
help='Specify an optimizer: adagrad, adam, rmsprop, sgd')
parser.add_argument('--verbose', type=int, default=1,
help='控制每多少次迭代显示一次性能信息')
parser.add_argument('--whether_save_model', type=int, default=1,
help='Whether to save the trained model.')
# 用于指定预训练的模型文件
# NeuMF 模型结构中包含了两部分:MF 和 MLP
# 并且可以选择是否使用预先训练好的模型权重来初始化这两部分
parser.add_argument('--mf_pretrain', nargs='?', default='',
help='Specify the pretrain model file for MF part. If empty, no pretrain will be used')
parser.add_argument('--mlp_pretrain', nargs='?', default='',
help='Specify the pretrain model file for MLP part. If empty, no pretrain will be used')
return parser.parse_args()
# mf_dim=10 是一个整数,表示矩阵分解(MF)部分的嵌入向量的维度
# MLP 通常包含多个层,需要一个列表来表示每层的大小(每层的神经元个数)
# reg_layers=[0,0] 是一个列表,表示每个 MLP 层的 L2 正则化强度
def get_model(users_dimension, items_dimension, mf_dim=10, layers=[32,16], reg_layers=[0,0], reg_mf=0):
assert len(layers) == len(reg_layers)
num_layer = len(layers) #Number of layers in the MLP
# Input variables
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
# Embedding layer
MF_Embedding_User = Embedding(input_dim = users_dimension, output_dim = mf_dim, name = 'mf_embedding_user',
embeddings_regularizer = l2(reg_mf), input_length=1)
MF_Embedding_Item = Embedding(input_dim = items_dimension, output_dim = mf_dim, name = 'mf_embedding_item',
embeddings_regularizer = l2(reg_mf), input_length=1)
MLP_Embedding_User = Embedding(input_dim = users_dimension, output_dim = int(layers[0]/2), name = "mlp_embedding_user",
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = items_dimension, output_dim = int(layers[0]/2), name = 'mlp_embedding_item',
embeddings_regularizer = l2(reg_layers[0]), input_length=1)
# MF part
mf_user_latent = Flatten()(MF_Embedding_User(user_input))
mf_item_latent = Flatten()(MF_Embedding_Item(item_input))
mf_vector = Multiply()([mf_user_latent, mf_item_latent]) # element-wise multiply
# MLP part
mlp_user_latent = Flatten()(MLP_Embedding_User(user_input))
mlp_item_latent = Flatten()(MLP_Embedding_Item(item_input))
mlp_vector = Concatenate(axis = 1)([mlp_user_latent, mlp_item_latent])
for idx in range(1, num_layer):
layer = Dense(layers[idx], W_regularizer= l2(reg_layers[idx]), activation='relu', name="layer%d" %idx)
mlp_vector = layer(mlp_vector)
# Concatenate MF and MLP parts
# Lambda 是 Keras 中的一个层,允许应用任意的函数到输入数据上
# 这里使用了一个匿名函数 lambda x: x * alpha,将 mf_vector 中的每个元素乘以 alpha,
# alpha 用于控制 MF 和 MLP 部分在最终预测中的相对重要性
#mf_vector = Lambda(lambda x: x * alpha)(mf_vector)
#mlp_vector = Lambda(lambda x : x * (1-alpha))(mlp_vector)
predict_vector = Concatenate(axis = -1)([mf_vector, mlp_vector])
# Final prediction layer
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = "prediction")(predict_vector)
model = Model(input=[user_input, item_input],
output=prediction)
return model
# 将预训练的模型的权重加载到一个新的 NeuMF 模型中
# model: 新的 NeuMF 模型实例,将用于加载预训练权重。
# gmf_model: 预训练的 GMF 模型实例。
# mlp_model: 预训练的 MLP 模型实例。
# num_layers: MLP 部分的层数。
def load_pretrain_model(model, gmf_model, mlp_model, num_layers):
# MF embeddings
# 获取MF模型中 用户和物品嵌入层 的权重
gmf_user_embeddings = gmf_model.get_layer('user_embedding').get_weights()
gmf_item_embeddings = gmf_model.get_layer('item_embedding').get_weights()
# 将获取到的权重 设置到新的 NeuMF 模型的相应层中
model.get_layer('mf_embedding_user').set_weights(gmf_user_embeddings)
model.get_layer('mf_embedding_item').set_weights(gmf_item_embeddings)
# MLP embeddings
mlp_user_embeddings = mlp_model.get_layer('user_embedding').get_weights()
mlp_item_embeddings = mlp_model.get_layer('item_embedding').get_weights()
model.get_layer('mlp_embedding_user').set_weights(mlp_user_embeddings)
model.get_layer('mlp_embedding_item').set_weights(mlp_item_embeddings)
# MLP layers
# 遍历mlp模型中的所有隐藏层,并获取层索引
for i in range(1, num_layers):
# 获取根据每层的索引 获取这一层的权重
mlp_layer_weights = mlp_model.get_layer('layer%d' %i).get_weights()
# 并将获得的权重设置到此模型相应层中
model.get_layer('layer%d' %i).set_weights(mlp_layer_weights)
# Prediction weights
# 获取预测层的权重
gmf_prediction = gmf_model.get_layer('prediction').get_weights()
mlp_prediction = mlp_model.get_layer('prediction').get_weights()
# new_weights 是拼接后的权重矩阵
new_weights = np.concatenate((gmf_prediction[0], mlp_prediction[0]), axis=0)
# new_b 是拼接后的偏置项
new_b = gmf_prediction[1] + mlp_prediction[1]
print('new_b.shape', new_b.shape)
model.get_layer('prediction').set_weights([0.5*new_weights, 0.5*new_b])
return model
# 获取训练实例
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [],[],[]
items_dimension = train.shape[1]
for (u, i) in train.keys():
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instances
for t in range(num_negatives):
j = np.random.randint(items_dimension)
while (u, j) in train:
j = np.random.randint(items_dimension)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
if __name__ == '__main__':
args = parse_args()
num_epochs = args.epochs
batch_size = args.batch_size
mf_dim = args.embedding_dimension
layers = eval(args.layers)
reg_mf = args.reg_mf
reg_layers = eval(args.reg_layers)
num_negatives = args.num_neg
learning_rate = args.lr
optimizer_selected = args.optimizer_selected
verbose = args.verbose
mf_pretrain = args.mf_pretrain
mlp_pretrain = args.mlp_pretrain
topK = 10
evaluation_threads = 1#mp.cpu_count()
print("NeuMF arguments: %s " %(args))
model_out_file = 'Pretrain/%s_NeuMF_%d_%s_%d.h5' %(args.dataset, mf_dim, args.layers, time())
# Loading data
t1 = time()
dataset = Dataset(args.path + args.dataset)
train, testRatings, testNegatives = dataset.trainMatrix, dataset.testRatings, dataset.testNegatives
users_dimension, items_dimension = train.shape
print("Load data done [%.1f s]. #user=%d, #item=%d, #train=%d, #test=%d"
%(time()-t1, users_dimension, items_dimension, train.nnz, len(testRatings)))
# Build model
model = get_model(users_dimension, items_dimension, mf_dim, layers, reg_layers, reg_mf)
if optimizer_selected.lower() == "adagrad":
model.compile(optimizer=Adagrad(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "rmsprop":
model.compile(optimizer=RMSprop(lr=learning_rate), loss='binary_crossentropy')
elif optimizer_selected.lower() == "adam":
model.compile(optimizer=Adam(lr=learning_rate), loss='binary_crossentropy')
else:
model.compile(optimizer=SGD(lr=learning_rate), loss='binary_crossentropy')
# Load pretrain model
if mf_pretrain != '' and mlp_pretrain != '':
gmf_model = GMF.get_model(users_dimension,items_dimension,mf_dim)
gmf_model.load_weights(mf_pretrain)
mlp_model = MLP.get_model(users_dimension,items_dimension, layers, reg_layers)
mlp_model.load_weights(mlp_pretrain)
model = load_pretrain_model(model, gmf_model, mlp_model, len(layers))
print("Load pretrained GMF (%s) and MLP (%s) models done. " %(mf_pretrain, mlp_pretrain))
# Init performance
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR = %.4f, NDCG = %.4f' % (hr, ndcg))
best_hr, best_ndcg, best_iter = hr, ndcg, -1
if args.whether_save_model > 0:
model.save_weights(model_out_file, overwrite=True)
# Training model
for epoch in range(num_epochs):
t1 = time()
# Generate training instances
user_input, item_input, labels = get_train_instances(train, num_negatives)
# Training
hist = model.fit([np.array(user_input), np.array(item_input)], #input
np.array(labels), # labels
batch_size=batch_size, nb_epoch=1, verbose=0, shuffle=True)
t2 = time()
# Evaluation
if epoch %verbose == 0:
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg, loss = np.array(hits).mean(), np.array(ndcgs).mean(), hist.history['loss'][0]
print('Iteration %d [%.1f s]: HR = %.4f, NDCG = %.4f, loss = %.4f [%.1f s]'
% (epoch, t2-t1, hr, ndcg, loss, time()-t2))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
if args.whether_save_model > 0:
model.save_weights(model_out_file, overwrite=True)
print("End. Best Iteration %d: HR = %.4f, NDCG = %.4f. " %(best_iter, best_hr, best_ndcg))
if args.whether_save_model > 0:
print("The best NeuMF model is saved to %s" %(model_out_file))
4、evaluate.py
# -*- coding: utf-8 -*-
# 计算模型在测试数据集上的 HR 和 NDCG
import math
import heapq
import multiprocessing
import numpy as np
from time import time
# 全局变量——存储模型、测试评分数据、测试负样本数据和Top-K的长度
_model = None
_testRatings = None
_testNegatives = None
_K = None
def evaluate_model(model, testRatings, testNegatives, K, num_thread):
# 使用 global 关键字声明了四个全局变量,这样在函数内部对它们的修改将会影响整个程序
global _model
global _testRatings
global _testNegatives
global _K
# 将传入的参数赋值给全局变量,以便在函数的其他部分使用
_model = model
_testRatings = testRatings
_testNegatives = testNegatives
_K = K
# 初始化两个空列表,用于存储每个样本的HR和NDCG值
hits, ndcgs = [], []
# 检查是否需要使用多线程进行评估。
if(num_thread > 1):
# 创建一个多进程池,进程数由 num_thread 决定
pool = multiprocessing.Pool(processes=num_thread)
# 使用 pool.map 方法并行地调用 eval_one_rating 函数,对每个测试样本进行评估
res = pool.map(eval_one_rating, range(len(_testRatings)))
# 关闭进程池,并等待所有进程完成
pool.close()
pool.join()
# 从多线程的返回结果中提取HR和NDCG值
hits = [r[0] for r in res]
ndcgs = [r[1] for r in res]
return (hits, ndcgs)
# 如果不需要使用多线程(即 num_thread 为 1),则使用单线程进行评估
else:
for idx in range(len(_testRatings)):
# 调用 eval_one_rating 函数对当前样本进行评估,并获取HR和NDCG值
(hr, ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return (hits, ndcgs)
# 定义eval_one_rating 函数,它负责评估单个样本的性能
# 接受一个样本索引 idx 作为参数
def eval_one_rating(idx):
# 从全局变量中获取当前样本的评分数据和负样本数据
rating = _testRatings[idx]
items = _testNegatives[idx]
# 提取用户ID u 和目标物品ID gtItem
u = rating[0]
gtItem = rating[1]
# 将目标物品添加到物品列表中,并创建一个与物品列表长度相同的用户ID数组
items.append(gtItem)
users = np.full(len(items), u, dtype='int32')
# 初始化一个字典来存储物品的预测分数,并调用模型的 predict 方法获取预测分数
map_item_score = {}
predictions = _model.predict([users, np.array(items)], batch_size=100, verbose=0)
# 初始化一个字典来存储物品的预测分数,并调用模型的 predict 方法获取预测分数
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i]
# 从物品列表中移除目标物品,因为它不应该出现在推荐列表中
items.pop()
# 使用 heapq.nlargest 函数获取分数最高的 _K 个物品,形成推荐列表
ranklist = heapq.nlargest(_K, map_item_score, key=map_item_score.get)
# 调用 getHitRatio 和 getNDCG 函数计算当前样本的HR和NDCG值
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return (hr, ndcg)
# 接受推荐列表 ranklist 和目标物品ID gtItem 作为参数
def getHitRatio(ranklist, gtItem):
# 遍历推荐列表,如果目标物品出现在列表中,则返回1(表示命中)
for item in ranklist:
if(item == gtItem):
return 1
# 如果目标物品没有出现在推荐列表中,则返回0
return 0
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if(item == gtItem):
return math.log(2) / math.log(i+2)
return 0
5、dataset.py
# -*- coding: utf-8 -*-
import scipy.sparse as sp
import numpy as np
class Dataset(object):
def __init__(self, path):
# 下面三个变量分别用于存储 训练矩阵、测试评分列表和测试负样本列表
# ml-1m.train.rating 包含了用户对电影的评分数据,用于训练推荐模型。
# 数据格式通常为:UserID::MovieID::Rating::Time
self.trainMatrix = self.load_rating_file_as_matrix(path+'.train.rating')
self.testRatings = self.load_rating_file_as_list(path+'.test.rating')
# 包含了用户未评分的电影数据,这些数据用于模拟推荐系统中的负样本。
# 数据格式通常为:UserID::MovieID,每行包含一个用户ID和一个电影ID的组合,表示用户没有对该电影进行评分
self.testNegatives = self.load_negative_file(path+'.test.negative')
assert len(self.testRatings) == len(self.testNegatives)
self.users_dimension, self.items_dimension = self.trainMatrix.shape
# 用于将评分文件加载为稀疏矩阵
def load_rating_file_as_matrix(self, filename):
# get numbers of users and items
users_dimension, items_dimension = 0, 0
with open(filename, 'r') as f:
line = f.readline()
# 读取的这一行不为空,则执行循环
while(line != None and line != ''):
# 以跳格号分隔,并存入arr数组
arr = line.split('\t')
# 将第一列和第二列转换为整数,分别代表用户ID和物品ID
user, item = int(arr[0]), int(arr[1])
users_dimension = max(users_dimension, user)
items_dimension = max(items_dimension, item)
# 读取下一行
line = f.readline()
# contruct matrix
mat = sp.dok_matrix((users_dimension+1, items_dimension+1), dtype=np.float32)
with open(filename, 'r') as f:
line = f.readline()
while(line != None and line != ''):
arr = line.split('\t')
user, item, rating = int(arr[0]), int(arr[1]), float(arr[2])
# 如果评分大于0
if(rating > 0):
mat[user, item] = 1.0
line = f.readline()
return mat
def load_rating_file_as_list(self, filename):
ratingList = []
with open(filename, 'r') as f:
line = f.readline()
while(line != None and line != ''):
arr = line.split('\t')
user, item = int(arr[0]), int(arr[1])
ratingList.append([user, item])
line = f.readline()
return ratingList
def load_negative_file(self, filename):
negativeList = []
with open(filename, 'r') as f:
line = f.readline()
while(line != None and line != ''):
arr = line.split('\t')
negatives = []
for x in arr[1:]:
negatives.append(int(x))
negativeList.append(negatives)
line = f.readline()
return negativeList