从电子病历 EMRs 构建医学知识图谱
- 提出背景
- 传统的三元组结构
- 本研究采用的四元组结构
- 第四元作用
- 第四元类型
- 以往的方法
- 本研究的方法
- 大威天龙·八
论文:Real-world data medical knowledge graph: construction and applications
提出背景
本研究在中国一家三甲医院的大数据平台上进行,构建的医学知识图谱包含9种实体类型,共22,508个实体,并建立了579,094个四元组结构以代替传统的三元组结构。
在本研究中,通过使用中国一家三甲医院的大数据平台,我们构建了一个复杂的医学知识图谱,这个图谱不仅包含多种医学实体类型,还采用了四元组结构代替了传统的三元组结构,以提供更丰富的信息和关系表示。
传统的三元组结构
在传统的知识图谱中,糖尿病和相关实体之间的关系通常用三元组表示,例如:
- (糖尿病, 关联症状, 多饮)
- (糖尿病, 推荐治疗, 胰岛素注射)
这些三元组有效地表示了实体之间的二元关系。
本研究采用的四元组结构
四元组结构在三元组的基础上增加了额外的维度,可以提供更多的上下文或属性信息,使得关系描述更加详细和精确。
对于糖尿病,四元组的例子可能包括:
- (糖尿病, 关联症状, 多饮, 频率: 高)
- (糖尿病, 推荐治疗, 胰岛素注射, 适应症: 1型糖尿病)
在这些四元组中,第四元素提供了关于关系的额外信息,如症状出现的频率或治疗的具体适应症。
这不仅帮助医生更好地理解疾病的具体表现,也能针对不同类型的糖尿病提供更加个性化的治疗建议。
第四元作用
通过扩展传统知识图谱的结构和利用大规模数据,显著提升了医学知识图谱在处理复杂疾病如糖尿病时的细致度和实用性。
-
(糖尿病, 关联症状, 视网膜病变, 频率: 常见)
- 这个四元组说明视网膜病变是糖尿病的一个常见症状。
-
(糖尿病, 推荐治疗, 代谢手术, 适应症: 2型糖尿病且药物治疗无效)
- 这表示代谢手术是针对那些2型糖尿病患者的推荐治疗方案,尤其是在药物治疗无效的情况下。
-
(糖尿病, 预防措施, 定期体检, 频率: 每年)
- 这个四元组建议所有糖尿病患者每年进行定期体检,以早期发现可能的并发症。
-
(糖尿病, 饮食建议, 低糖饮食, 适应症: 所有类型)
- 这表示对于所有类型的糖尿病患者,推荐采取低糖饮食。
当诊断出患者有2型糖尿病且传统药物治疗效果不佳时,医生可以考虑推荐代谢手术。
对于初诊的糖尿病患者,医生可以强调定期体检的重要性,特别是检查可能的视网膜病变。
在日常管理中,医生会向所有糖尿病患者推荐低糖饮食,并根据患者的具体病情调整饮食建议。
第四元类型

图显示了知识图谱中用来表示事实的四元组结构。
在这个例子中,四元组由以下部分构成:
- 主体(Subject):Type 2 diabetes mellitus(2型糖尿病)
- 谓词(Predicate):disease_related_symptom(疾病相关症状)
- 宾语(Object):Polydipsia(多饮)
- 属性(Properties):包含四个属性,数量(num)、概率(probability)、特异性(specificity)和可靠性(reliability),每个属性都有其数值。
这个结构扩展了传统的三元组(SPO)结构,提供了有关特定疾病症状关系的更多详细信息,如多饮作为2型糖尿病的常见症状。
在四元组知识表示中,第四元通常是用来添加关于关系的额外信息,增加上下文或详细说明的。
这第四元可以是多种形式,具体取决于所要表达的信息和应用场景:
-
属性值:表示关系中某个方面的量化信息,如频率、强度、概率等。
- 例:(疾病, 症状, 头痛, 频率: 常见)
-
时间信息:指明实体关系的时间范围或时限。
- 例:(疾病, 治疗, 抗生素, 时间: 7天疗程)
-
空间或位置信息:指出实体关系发生的地点或位置。
- 例:(手术, 地点, 医院, 地点: 肾脏外科病房)
-
条件或限制:提供关系有效的条件或应用的限制。
- 例:(治疗, 疾病, 胰岛素, 条件: 空腹时使用)
-
来源或依据:表明某个事实或声明的来源,如研究、临床试验等。
- 例:(治疗, 疾病, 心血管练习, 依据: 最新临床指南)
-
质量或评估:给出关系或实体的质量评估或状态描述。
- 例:(症状, 疾病, 发热, 严重性: 中度)
-
序列或顺序:当多个实体和动作按特定顺序发生时指定顺序。
- 例:(治疗步骤, 疾病, 化疗, 步骤: 1)
-
个体特征:针对特定患者群体或个体的特定信息。
- 例:(药物, 适用对象, 青少年, 剂量: 减半)
第四元的具体内容需要根据建立知识图谱的目的和所要解决的问题精心设计,以确保它能够提供足够且有用的信息。
以往的方法
在之前的研究中,构建糖尿病相关的知识图谱通常只利用了少量的数据,比如特定的医学文献或者小规模的病例记录。
这种方法主要关注疾病和药物之间的直接关系,虽然对特定查询有帮助,但可能无法全面反映与糖尿病相关的所有医学信息。
本研究的方法
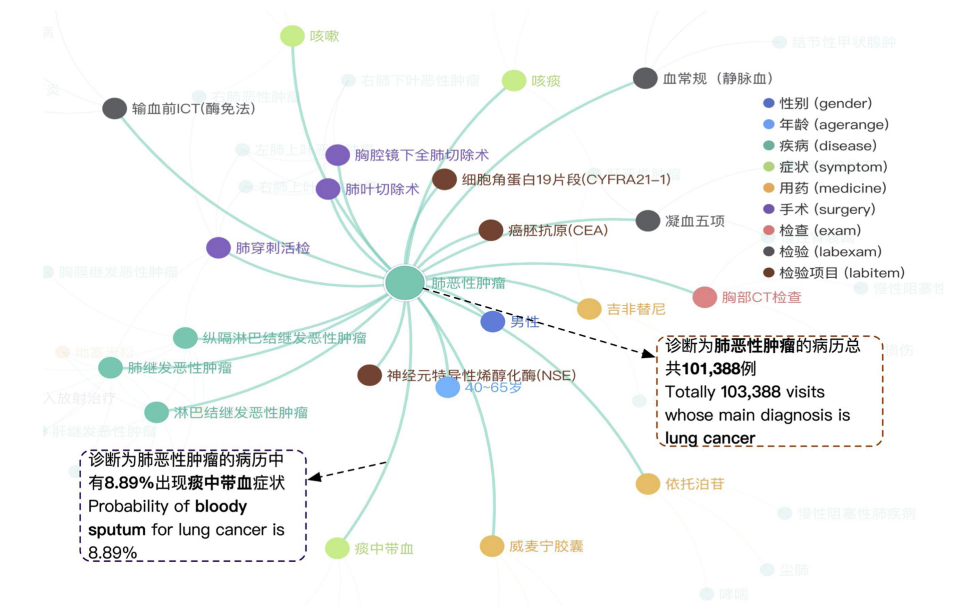
图展示了知识图谱中肺癌相关的实体和关系。
中心的大圆圈代表肺癌主诊断,周围的点代表与肺癌相关的各种实体,如症状、药物、检查项目等。
线条表示实体之间的关系,而不同颜色的点代表不同类型的实体。
这有助于理解如何通过知识图谱展现复杂的医学信息和相互关系,例如肺癌与某个症状或检查之间的关系。
本研究使用了一个大型医院的所有病历数据,这些数据不仅数量众多,而且涵盖了从症状到治疗的各种医学实体。
- 实体类型的扩展:本研究不仅包括了疾病和药物,还包括了症状、治疗措施、生活方式建议等更多类型的医学实体。
这使得知识图谱能更全面地支持医生做出诊断和治疗决策。
- 大规模数据的应用:通过分析数以百万计的病历记录,本研究能够更准确地识别出糖尿病及其相关症状和治疗方法。
这帮助医生和研究者发现更多的治疗模式和可能的病因。
- 系统化的构建过程:从初步的数据处理到复杂的分析,每一个步骤都使用了先进的技术来确保信息的准确性和实用性。
这一点对于处理像糖尿病这样的复杂疾病特别重要,因为它们的治疗需要长期跟踪和综合多方面的信息。
- 实际应用的验证:最终,这个知识图谱被用来帮助医生为糖尿病患者制定个性化的治疗方案。
它还可以用于教育患者,帮助他们更好地理解自己的健康状况和治疗选择。
本研究通过使用大规模的数据和先进的分析技术,构建了一个能够全面反映糖尿病及其相关条件的知识图谱,这在以往的研究中是很少见的。
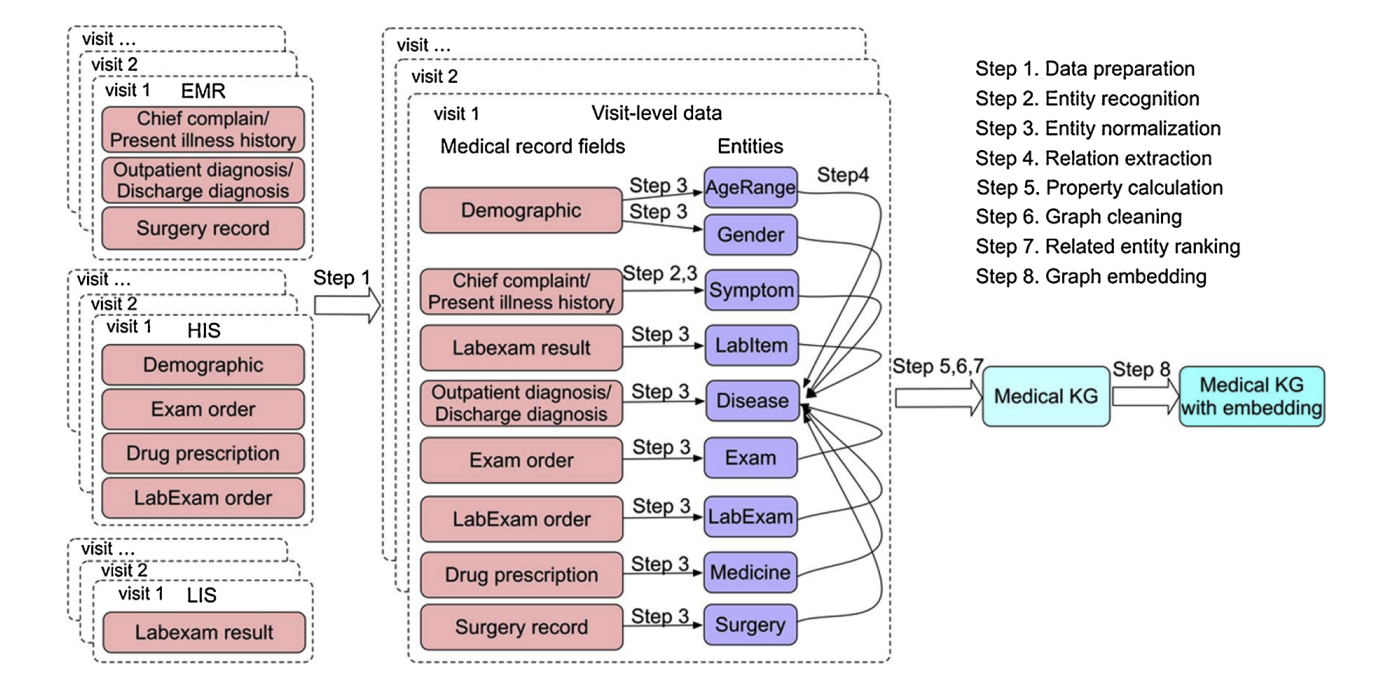
这张图是一幅流程图,展示了如何构建医学知识图谱(Medical KG)的系统化过程。
流程分为以下几个步骤:
- 数据准备(Data preparation):从不同的医疗信息系统中收集数据,比如电子病历(EMR)、医院信息系统(HIS)和实验室信息系统(LIS)。
每个系统提供的数据包括诊断、检查、药物处方等。
-
实体识别(Entity recognition):在收集的数据中识别医学相关的实体,如症状、检验项目、疾病、药物和手术等。
-
实体标准化(Entity normalization):将识别出的实体规范到标准术语,以保证知识图谱中的一致性。
-
关系提取(Relation extraction):确定实体之间的关系,例如疾病和症状之间的关系。
-
属性计算(Property calculation):为图谱中的实体计算属性值,比如可能是频率、强度等。
-
图清洗(Graph cleaning):清理和优化图谱,删除不一致或错误的信息。
-
相关实体排名(Related entity ranking):在图谱中对实体进行排名,可能基于它们的重要性或相关性。
-
图嵌入(Graph embedding):将图谱转化为嵌入向量,这样的数学表示有助于机器学习模型更有效地处理和分析。
图中的箭头显示了数据从电子医疗记录(EMR)、医院信息系统(HIS)、和实验室信息系统(LIS)流经不同步骤直到构建出带有嵌入的医学知识图谱(Medical KG with embedding)的路径。
大威天龙·八
整个流程包含以下八个主要步骤,旨在从大规模电子医疗记录中构建医学知识图谱:
- 数据准备:集成来自电子病历系统、医院信息系统、实验室信息系统和放射学信息系统的数据。
问题:大量分散的糖尿病相关数据需要汇总和整理。
解法:集成来自EMR、HIS、LIS的数据。
- 子解法1:收集诊断记录。
- 子解法2:汇总药物处方数据。
- 子解法3:整合实验室和检查结果。
原因:为了创建一个全面的糖尿病知识图谱,需要来自多个来源的详尽数据。
- 实体识别:使用命名实体识别技术从自由文本中识别出医学实体,如疾病、药物和症状。
问题:自由文本中含有多种糖尿病相关实体。
解法:应用NER技术识别实体。
- 子解法:使用混合模型结合规则和学习方法识别实体。
原因:提高实体识别的准确性和覆盖面。
- 实体标准化:将识别出的各种术语映射到标准化的医学术语,以创建一致性的实体。
问题:不同的记录可能使用不同的术语表示同一疾病。
解法:将术语映射到标准化的医学术语。
- 子解法:构建术语映射字典。
原因:确保知识图谱的一致性和准确性。
- 关系提取:建立实体间的三元组关系,特别是将疾病作为中心实体,围绕其提取相关的医学实体关系。
问题:需要明确实体间的关联。
解法:确定疾病与其他实体之间的关系。
- 子解法:专注于疾病和其他关键实体的关系。
原因:疾病是医学知识图谱中的核心实体。
- 属性计算:为知识图谱中的实体和关系计算如出现次数和概率等属性。
问题:为实体和关系定义和计算属性。
解法:计算出现次数和概率。
- 子解法:定义四元组结构以包含更多属性。
原因:属性为实体关系提供了更丰富的信息。
- 图清洗:去除图中的不一致或错误信息,提升知识图谱的质量。
问题:图谱中可能存在错误或不一致的信息。
解法:清除图谱中的无效信息。
- 子解法:应用清洗算法。
原因:提升知识图谱的质量和可靠性。
- 相关实体排名:对图中的实体进行排名,这通常基于它们的重要性或相关性。
问题:需要确定实体的重要性。
解法:对实体进行排名。
- 子解法:基于实体的临床相关性进行排序。
原因:帮助用户理解实体间的重要性差异。
- 图嵌入:将知识图谱转化为嵌入向量,以便能够通过机器学习模型进行有效处理和分析。
问题:需要将知识图谱应用于机器学习。
解法:将实体和关系转换为向量形式。
- 子解法:应用图嵌入算法。
原因:使得图谱能够被机器学习模型有效处理。
以糖尿病为例,我们来看看这八个步骤是如何应用的:
-
数据准备:从电子医疗记录(EMR)中收集包含糖尿病的诊断、药物处方、检查和手术记录等相关数据。
-
实体识别:从病历文本中识别出糖尿病及其相关的实体,如“高血糖”、“口服降糖药”、“血糖检测”。
-
实体标准化:将各种诊断术语映射到国际疾病分类(ICD-10)的标准糖尿病代码。
-
关系提取:建立糖尿病实体与其它实体(如症状、药物、检查)之间的关系。比如,“糖尿病”与“口渴”、“频繁小便”建立疾病与症状的关系。
-
属性计算:计算糖尿病及其相关实体在患者记录中的出现频次和概率。
-
图清洗:清理与糖尿病不相关或错误链接的实体和关系。
-
相关实体排名:根据与糖尿病相关的临床重要性对实体进行排名。比如,将“视网膜病变”这一并发症排在更高的位置,因为它是糖尿病的一个重要并发症。
-
图嵌入:将糖尿病及其相关实体和关系转换为向量形式,以便于机器学习模型能够对其进行分析,比如预测糖尿病患者的并发症风险。