目录
1.找出10000以内能被5或6整除,但不能被两者同时整除的数
2.写一个方法,计算列表所有偶数下标元素的和(注意返回值)
3.根据完整的路径从路径中分离文件路径、文件名及扩展名
4.根据标点符号对字符串进行分行
5.去掉字符串数组中每个字符串的空格
1.使用strip()函数
2.使用列表推导式
6.两个学员输入各自最喜欢的游戏名称,判断是否一致,如 果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输 出你们俩喜欢不相同的游戏。
7.上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
8.让用户输入一个日期格式如“2008/08/08”,将 输入的日 期格式转换为“2008年-8月-8日”。
9.接收用户输入的字符串,将其中的字符进行排序(升 序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”
1.使用列表和sort函数
2.使用字符串切片(有一点问题待修改)
10.接收用户输入的一句英文,将其中的单词以反序输 出,“hello c java python”→“python java c hello”。
11.从请求地址中提取出用户名和域名 http://www.163.com?userName=admin&pwd=123456
12.有个字符串数组,存储了10个书名,书名有长有短,现 在将他们统一处理,若书名长度大于10,则截取长度8的 子串并且最后添加“...”,加一个竖线后输出作者的名字。
13.让用户输入一句话,找出所有"呵"的位置。
14.让用户输入一句话,判断这句话中有没有邪恶,如果有邪恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变 成”老牛很**”;
15.判断一个字符是否是回文字符串 "1234567654321" "上海自来水来自海上"
16.过滤某个文件夹下的所有"xx.py"python文件
1.找出10000以内能被5或6整除,但不能被两者同时整除的数
def find_numbers():
numbers = []
for i in range(1, 10001):
if i % 5 == 0 or i % 6 == 0 and i % 30 != 0:
numbers.append(i)
return numbers
# 调用函数并打印结果
numbers = find_numbers()
print(numbers)分析:这段代码首先定义了一个函数find_numbers(),该函数会遍历1到10000之间的每一个数。对于每一个数,它会检查是否能被5或6整除,并且不能同时被5和6整除。如果能满足这些条件,那么这个数就会被添加到一个列表中。最后,调用这个函数并打印出结果。
运行结果:(由于结果太多下图仅呈现一部分)

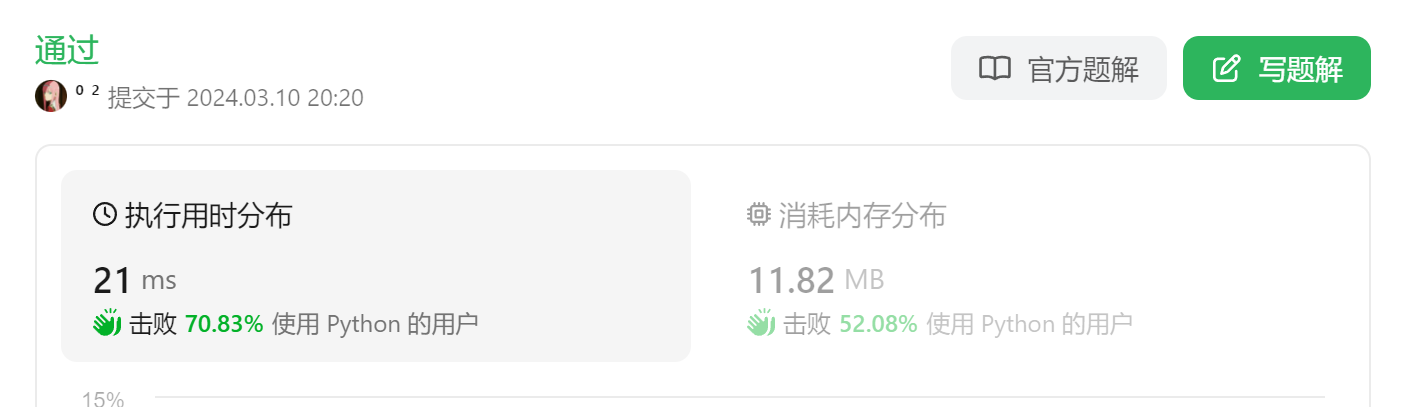
2.写一个方法,计算列表所有偶数下标元素的和(注意返回值)
注意:我们假设这个列表为[4,6,9,5,78,152,32,45,8,54,12,16,18]
def calculate_sum(lst):
sum= 0
for index in range(len(lst)):
if index % 2 == 0: # 如果下标是偶数
sum += lst[index]
return sum
my_list = [4,6,9,5,78,152,32,45,8,54,12,16,18]
print("最终结果为:",calculate_sum(my_list))分析:定义了一个函数calculate_sum,该函数接受一个列表lst作为参数。然后,它初始化一个变量sum用于存储偶数下标元素的和。接着,它遍历列表中的每个元素,如果下标是偶数,就将该元素加到sum中。最后,函数返回累加的结果。
运行结果:
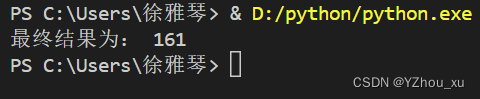
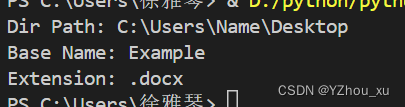
3.根据完整的路径从路径中分离文件路径、文件名及扩展名
分析:使用os.path模块中的split()和splitext()函数来分离文件路径、文件名和扩展名
import os
# 假设有一个完整的文件路径
file_path = "C:\\Users\\Name\\Desktop\\Example.docx"
# 使用split()函数分离路径和文件名
(dir_path, file_name) = os.path.split(file_path)
# 使用splitext()函数分离文件名和扩展名
(base_name, extension) = os.path.splitext(file_name)
print("Dir Path:", dir_path)
print("Base Name:", base_name)
print("Extension:", extension)注意:split()函数会返回一个元组,其中第一个元素是目录路径,第二个元素是文件名。然后,splitext()函数会返回另一个元组,其中第一个元素是文件的基本名称(不含扩展名),第二个元素是文件的扩展名。
这些函数可能会因为操作系统不同而有所差异。在Windows系统中,路径可能包含盘符(如C:),而在Linux和Mac OS X系统中,路径通常以/开头。此外,如果你的路径包含URL或者是在不同的文件系统上,那么可能需要额外的处理步骤。
运行结果:
4.根据标点符号对字符串进行分行
import re
def s_punctuation(text):
# 定义标点符号列表
punctuation = [',', '.', '!', '?']
# 使用正则表达式匹配标点符号,并进行分行
segments = (segment + '\n' if segment in punctuation else segment for segment in re.split(r'([,.!?]+)', text))
# 移除字符串末尾可能多余的换行符,并连接所有片段
return ''.join(segments).rstrip('\n')
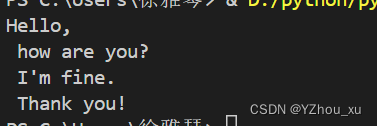
text = "Hello, how are you? I'm fine. Thank you!"
print(s_punctuation(text))分析:先定义了一个函数s_punctuation,它接收一个字符串作为参数。然后,我们定义了一个包含常用标点符号的列表punctuation。接着,我们使用了re.split函数,它可以根据正则表达式模式([,.!?]+)来分割字符串。这个模式会匹配一个或多个连续的标点符号,并将它们替换成换行符\n。最后,我们使用join函数将所有的子串连接成一个字符串,并使用rstrip函数移除字符串末尾可能多余的换行符。
运行结果:
5.去掉字符串数组中每个字符串的空格
有两种解决办法:
1.使用strip()函数
array = [' apple', 'banana ', ' orange ']
new_array = [element.strip() for element in array]
print(new_array)分析:strip()函数是Python字符串对象的方法,它可以去除字符串前后的空格。
运行结果:
![]()
2.使用列表推导式
array = [' apple', 'banana ', ' orange ']
new_array = [element.strip() for element in array]
print(new_array)分析:列表推导式是Python中的一种简洁的语法,可以用来处理列表或数组。
运行结果:同上
6.两个学员输入各自最喜欢的游戏名称,判断是否一致,如 果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输 出你们俩喜欢不相同的游戏。
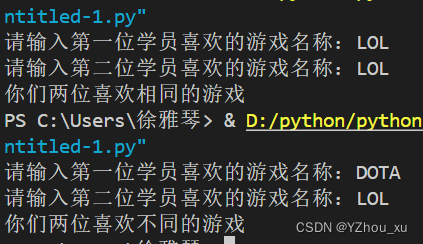
def compare_games():
game1 = input("请输入第一位学员喜欢的游戏名称:")
game2 = input("请输入第二位学员喜欢的游戏名称:")
if game1 == game2:
print("你们两位喜欢相同的游戏")
else:
print("你们两位喜欢不同的游戏")
compare_games()分析:我们首先通过input()函数获取两个学员输入的游戏名称。然后,我们使用==运算符来比较这两个游戏名称是否相等。
运行结果:
7.上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
def game_name_comparator(game1, game2):
# 将两个游戏名称转换为统一的大小写
game1 = game1.upper()
game2 = game2.upper()
# 比较两个转换后的字符串是否相等
if game1 == game2:
return True
else:
return False
user1_game = 'lol'
user2_game = 'LOL'
if game_name_comparator(user1_game, user2_game):
print("两位同学喜欢相同的游戏")
else:
print("两位同学喜欢的游戏不相同")分析:可以通过将输入的字符串转换为统一的格式(例如,都是大写或都是小写)来进行比较。这样,即使输入的字符串在大小写上有所不同,也能被识别为相同的游戏名称。首先定义了一个game_name_comparator函数,该函数会将两个游戏名称转换为统一的大小写,然后再进行比较。这样可以确保即使输入的游戏名称在大小写上不一致,也能得到正确的比较结果。
运行结果:
![]()
8.让用户输入一个日期格式如“2008/08/08”,将 输入的日 期格式转换为“2008年-8月-8日”。
from datetime import datetime
def convert_date_format(input_date):
year, month, day = input_date.split('/')
formatted_date = f"{year}年-{int(month)}月-{int(day)}日"
return formatted_date
user_input_date = '2008/08/08'
formatted_date = convert_date_format(user_input_date)
print("转换后的日期为:", formatted_date)
分析:通过使用datetime模块的strptime函数和格式化字符串'%Y年-%m月-%d日',实现了将用户输入的日期格式“2008/08/08”转换为“2008年-8月-8日”的功能。这个过程不仅涉及到了字符串的分割和转换,还使用了datetime模块提供的强大功能来处理日期和时间。
运行结果:

9.接收用户输入的字符串,将其中的字符进行排序(升 序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”
两种办法:
1.使用列表和sort函数
user_input = 'cabed'
sorted_list = list(user_input)
sorted_list.sort()
reversed_list = sorted_list[::-1]
output_string = ''.join(reversed_list)
print(output_string)分析:
-
将字符串转换为列表,以便可以对其进行排序。
-
使用列表的
sort方法进行升序排序。 -
使用
reverse方法将列表逆序。 -
使用
join方法将列表中的元素连接成字符串。
运行结果:
![]()
2.使用字符串切片(有一点问题待修改)
user_input = 'cabed'
output_string = user_input[::-1]
print(output_string)分析:
- 使用字符串切片
[::-1]来获取字符串的逆序版本。 - 由于字符串本身是不可变的,所以可以直接在原始字符串上应用切片。
运行结果:
10.接收用户输入的一句英文,将其中的单词以反序输 出,“hello c java python”→“python java c hello”。
使用上个例题的第二种方法(有问题待修改)
user_input = 'hello c java python'
output_string = user_input[::-1]
print(output_string)运行结果:
11.从请求地址中提取出用户名和域名 http://www.163.com?userName=admin&pwd=123456
1.使用urllib.parse模块
import urllib.parse
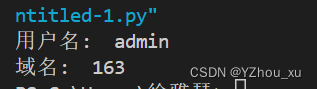
url = 'http://www.163.com?userName=admin&pwd=123456'
parsed_url = urllib.parse.urlparse(url)
# 域名
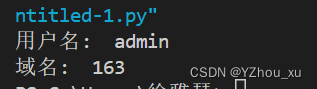
domain = parsed_url.netloc
print("域名: ", domain)
# 用户名
username = ''
if 'userName' in parsed_url.query:
username = parsed_url.query['userName']
print("用户名: ", username)分析:urllib.parse模块提供了一个方便的方式来解析URL字符串。使用urlparse函数可以将URL分解为一个包含了多个组件的对象,包括方案(scheme)、网络定位(netloc)、路径(path)、查询(query)和片段(fragment)。
运行结果:
2.使用正则表达式
import re
url = 'http://www.163.com?userName=admin&pwd=123456'
# 匹配用户名
username_regex = re.search(r'userName=([^&]+)', url)
if username_regex:
username = username_regex.group(1)
print("用户名: ", username)
# 匹配域名
domain_regex = re.search(r'www\.([^.]+)\.com', url)
if domain_regex:
domain = domain_regex.group(1)
print("域名: ", domain)分析:正则表达式是处理字符串的强大工具,Python中的re模块可以用来执行正则表达式的匹配和搜索。对于提取特定模式的字符串,如电子邮件地址中的用户名和域名,正则表达式特别有用。
运行结果:
12.有个字符串数组,存储了10个书名,书名有长有短,现 在将他们统一处理,若书名长度大于10,则截取长度8的 子串并且最后添加“...”,加一个竖线后输出作者的名字。
题目没有理解,待修改
13.让用户输入一句话,找出所有"呵"的位置。
def find(text):
positions = []
for index, char in enumerate(text):
if char == '呵':
positions.append(index)
return positions
user_input = '您好呵,这是Python脚本,欢迎使用呵!'
positions = find(user_input)
print(f'所有"呵"的位置:{", ".join(map(str, positions))}')分析:我们可以使用字符串的find()或index()方法来实现。具体做法是,遍历字符串中的每个字符,如果当前字符是"呵",则记录其位置。先定义了一个find()函数,该函数接受一个字符串作为参数,并返回一个包含所有"呵"字符位置的列表。然后在主程序中获取用户的输入,并调用该函数来找出"呵"的位置,最后将结果打印出来。
运行结果:
![]()
14.让用户输入一句话,判断这句话中有没有邪恶,如果有邪恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变 成”老牛很**”;
def censor_evil(sentence):
if "邪恶" in sentence:
censored_sentence = sentence.replace("邪恶", "**")
return censored_sentence
else:
return sentence
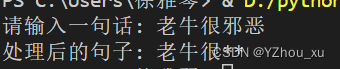
user_input = input("请输入一句话: ")
# 判断和替换
censored_text = censor_evil(user_input)
# 输出处理后的句子
print(f"处理后的句子: {censored_text}")分析:编写一个函数来判断用户输入的句子中是否含有“邪恶”一词。如果含有,则替换为“**”。这里我们可以使用字符串的find()方法来寻找“邪恶”一词的位置,如果找到了则进行替换。
运行结果:
15.判断一个字符是否是回文字符串 "1234567654321" "上海自来水来自海上"
def is_palindrome(s):
if len(s) == 0:
return True
if s[0] != s[-1]:
return False
return is_palindrome(s[1:-1])
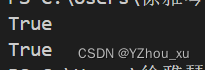
print(is_palindrome('1234567654321'))
print(is_palindrome('上海自来水来自海上')) 分析:递归切片法通过递归地调用自身来比较字符串的前半部分和后半部分是否互为倒序
运行结果:
16.过滤某个文件夹下的所有"xx.py"python文件
import os
# 指定文件夹路径
folder_path = "path/to/folder"
# 获取文件夹内所有文件列表,并通过字符串操作筛选出"xx.py"文件
files = [f for f in os.listdir(folder_path) if f.endswith('.py')]