一、任务目标
python代码写将 HarryPorter 电子书作为语料库,分别使用词袋模型,TF-IDF模型和Word2Vec模型进行文本向量化。
1. 首先将数据预处理,Word2Vec 训练时要求考虑每个单词前后的五个词汇,地址为
作为其上下文 ,生成的向量维度为50维
2.分别搜索 courtroom 和 wizard 这两个词语义最近的5个单词
3.对wizard 和witch 这两个单词在二维平面上进行可视化
内容补充:
什么是对他们进行向量化?
当涉及将文本数据转换为计算机可以处理的形式时,常用的方法之一是文本向量化。文本向量化是将文本文档转换为数值向量的过程,以便计算机可以理解和处理。
词袋模型(Bag of Words Model):
- 词袋模型是一种简单而常用的文本向量化方法。
- 在词袋模型中,每个文档被表示为一个向量,其中每个维度对应于词汇表中的一个词。
- 文档向量的每个维度表示对应词在文档中出现的频次(或者可以是二进制值,表示是否出现)。
- 这意味着词袋模型忽略了单词的顺序和上下文,只关注词的出现频率。
TF-IDF模型(Term Frequency-Inverse Document Frequency Model):
- TF-IDF是一种用于评估一个词对于一个文档在语料库中的重要性的统计方法。
- 与词袋模型类似,TF-IDF模型也将文档表示为向量,但是每个维度的值是基于词的TF-IDF得分。
- Term Frequency(TF)表示词在文档中出现的频率,而Inverse Document Frequency(IDF)表示词的稀有程度或信息量。
- TF-IDF的计算方法是将TF与IDF相乘,以突出显示在文档中频繁出现但在整个语料库中稀有的词语。
Word2Vec模型:
- Word2Vec是一种用于将词语表示为连续向量空间中的向量的技术。
- Word2Vec模型基于分布式假设,即在语料库中,具有相似上下文的词在向量空间中应该具有相似的表示。
- Word2Vec模型通常通过训练神经网络来学习词向量,其中每个词都被表示为一个密集的向量,称为嵌入(embedding)。
- 通过Word2Vec,词向量可以捕捉到词语之间的语义和语法关系,例如,语义上相似的词在向量空间中会更加接近。
二、代码部分
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from gensim.models import Word2Vec
from gensim.models import TfidfModel
from gensim.corpora import Dictionary
import matplotlib.pyplot as plt
# 导入停用词
stop_words = set(stopwords.words('english'))
# 加载数据
corpus_file = '/Users/zhengyawen/Downloads/HarryPorter.txt'
with open(corpus_file, 'r', encoding='utf-8') as file:
data = file.read()
# 预处理数据
sentences = [word_tokenize(sentence.lower()) for sentence in data.split('.')]
preprocessed_sentences = []
for sentence in sentences:
valid_words = []
for word in sentence:
if word.isalpha() and word not in stop_words:
valid_words.append(word)
preprocessed_sentences.append(valid_words)
# 构建Word2Vec模型
w2v_model = Word2Vec(sentences=preprocessed_sentences, vector_size=50, window=5, min_count=1, sg=0)
# 获取单词向量
vector_courtroom = w2v_model.wv['courtroom']
vector_wizard = w2v_model.wv['wizard']
# 搜索与“courtroom”和“wizard”最相似的5个单词
similar_words_courtroom = w2v_model.wv.most_similar('courtroom', topn=5)
similar_words_wizard = w2v_model.wv.most_similar('wizard', topn=5)
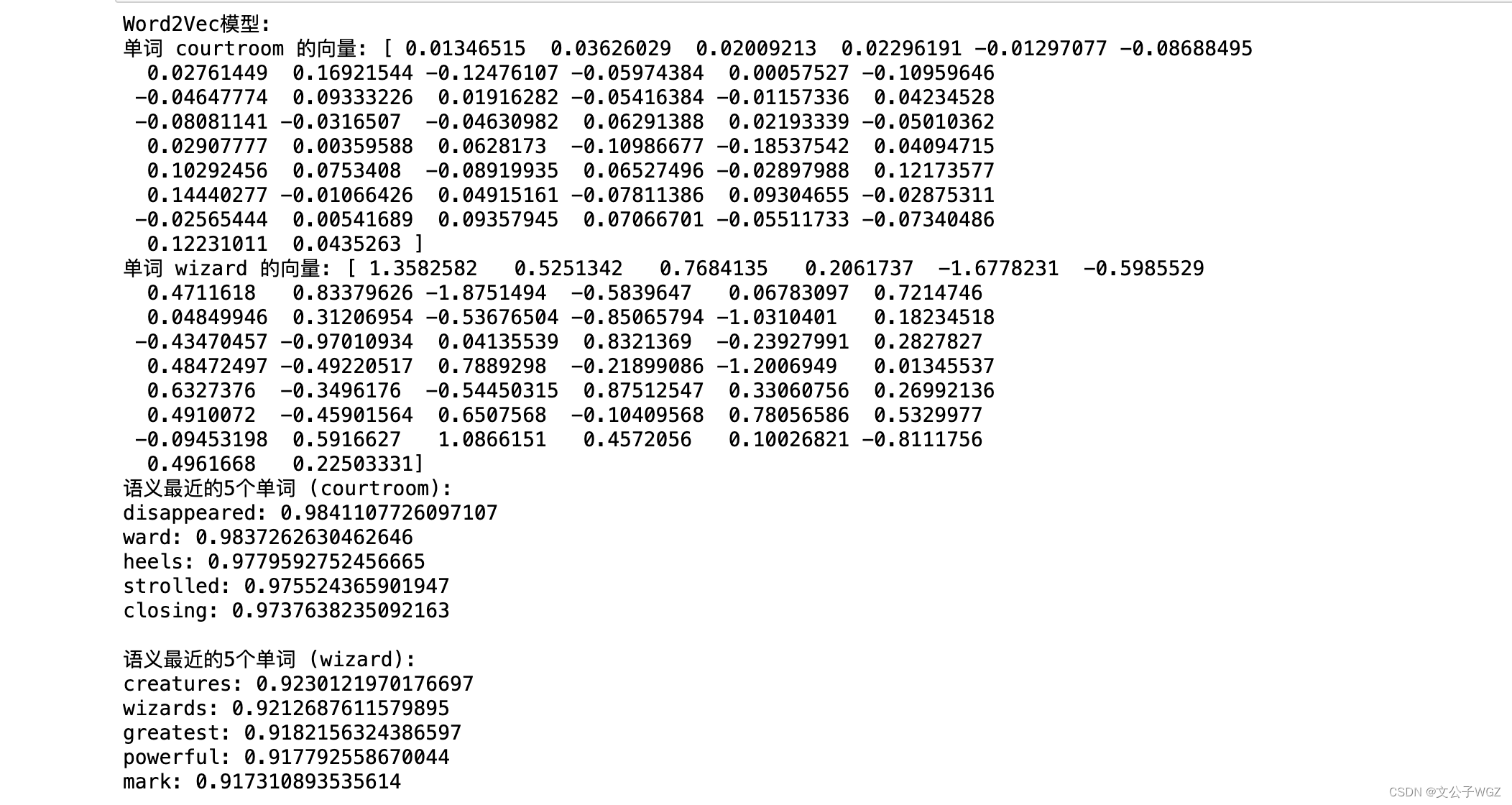
print("Word2Vec模型:")
print("单词 courtroom 的向量:", vector_courtroom)
print("单词 wizard 的向量:", vector_wizard)
print("语义最近的5个单词 (courtroom):")
for word, similarity in similar_words_courtroom:
print(f"{word}: {similarity}")
print("\n语义最近的5个单词 (wizard):")
for word, similarity in similar_words_wizard:
print(f"{word}: {similarity}")
# 构建词袋模型
dictionary = Dictionary(preprocessed_sentences)
corpus = [dictionary.doc2bow(sentence) for sentence in preprocessed_sentences]
tfidf_model = TfidfModel(corpus)
corpus_tfidf = tfidf_model[corpus]
# 可视化Word2Vec模型中wizard和witch的向量
words_to_plot = ['wizard', 'witch']
word_vectors = [w2v_model.wv[word] for word in words_to_plot]
# 可视化
plt.figure(figsize=(10, 6))
for i, word in enumerate(words_to_plot):
plt.scatter(word_vectors[i][0], word_vectors[i][1], label=word)
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.title('Visualization of Word Vectors')
plt.legend()
plt.show()
三、代码运行结果