上一小节介绍了怎么使用 Python 读取多维表的数据,看似可以成功获取到了所有的数据,但是在实际生产使用过程中,我们会发现,上一小节的代码并不能获取到所有的多维表数据,它只能获取一页,默认是第一页。因为我使用的测试表数据量小,第一页便可读取完,所以有一种获取到所有数据的错觉。
本文介绍如何进行分页读取飞书多维表的所有数据,主要内容介绍如下:
- 在线测试:使用飞书 API 调试台测试
- 本地测试:使用 Python 代码测试,介绍通过三种不同的方法自动读取所有分页数据:通过 while 循环读取、通过 for 循环读取和通过内函数递归读取。
1、如何读取所有分页数据
那么怎么获取到所有的数据呢?
查看官方文档-查询记录,在“查询参数”中(如下图),可以看到有2个和翻页相关的参数:“page_token”和“page_size”。
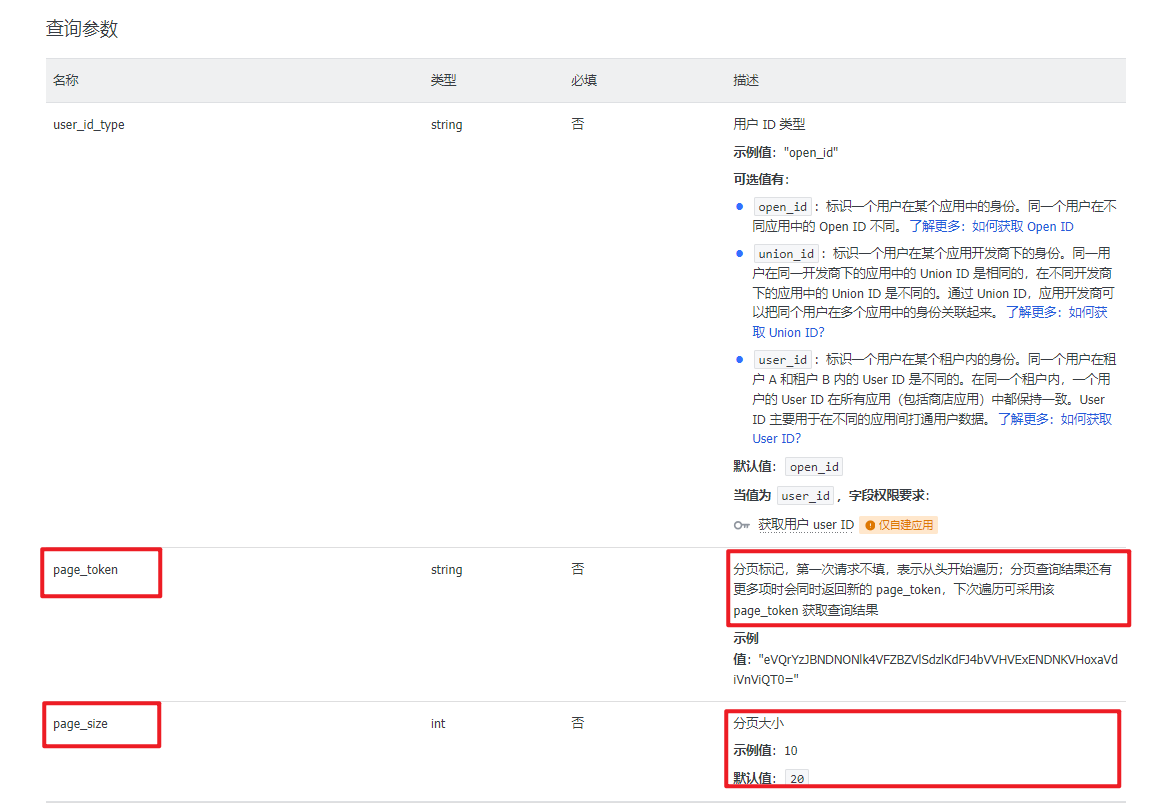
先说下“page_size”,和分页记录数相关,默认值为 20,最大值上图没介绍,不过在 API 开头有说明(如下图),单次最大查询 500 行记录。

而“page_token”是一个翻页参数,首页没有该参数,从第 2 页开始就必须要传递相关的参数,而相关的“page_token”参数的值需要通过上一页返回的数据(即响应体)进行获取,也就是说从第 2 页开始都依赖上一页的返回。
分页标记,第一次请求不填,表示从头开始遍历;分页查询结果还有更多项时会同时返回新的 page_token,下次遍历可采用该 page_token 获取查询结果。
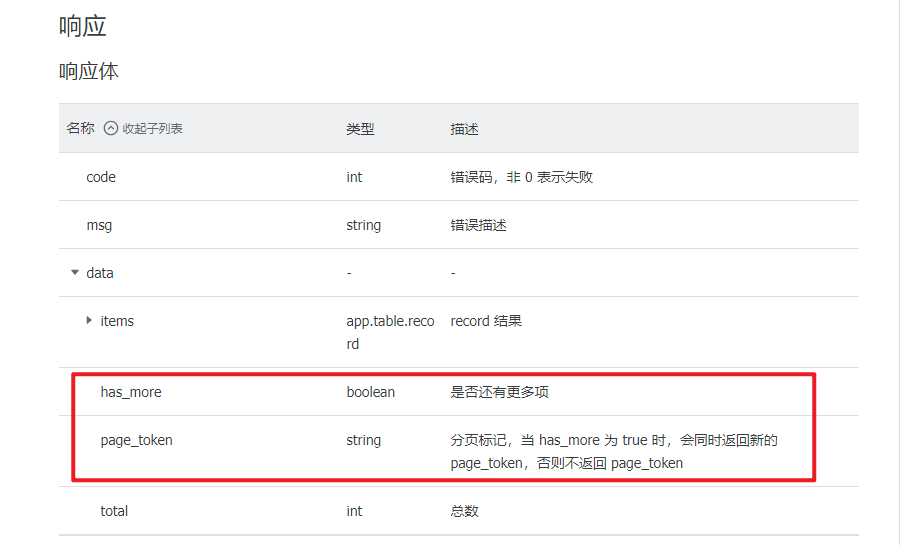
查看响应体说明,可以看到有两个参数和翻页相关:“has_more”和“page_token”。
- “has_more”用于判断有没有更多的页,有则返回 True。
- “page_token”用于传递给查询数据接口,请求下一页的数据。
1.1 调试:读取第二页数据
了解了取数逻辑之后,可以先调试一下。调试逻辑:先获取第 1 页,然后获取到第 2页的“page_token”再发起请求。
1.1.1 读取第 1 页
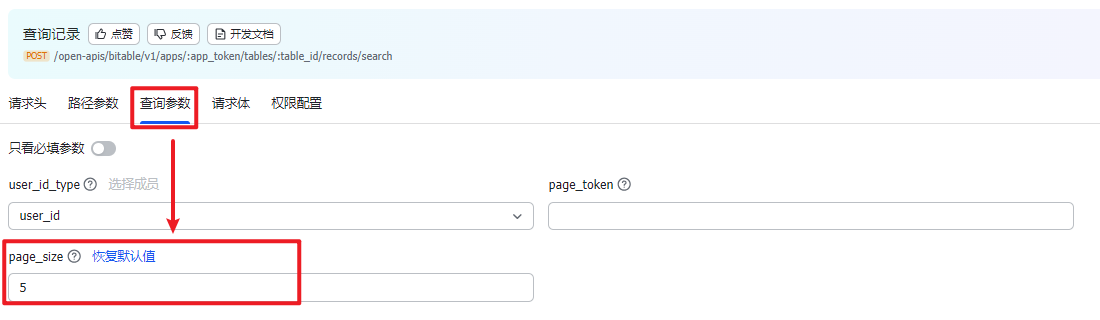
打开 API 调试台,准备多维表,多维表的参数说明等,参考 第 2 小节:《API(2):通过 Python 读取多维表数据节》的【1.1 获取 demo】。
- 请求头 和 路径参数参考第 2 小节填写即可
- 查询参数:第 2 小节只填写了必填参数,所以查询查数没有传递值(即使用默认参数值),由于我测试的数据仅有 10 条记录,所以“page_size”改为 5,以便观察翻页的参数值。
改完直接点击【开始调试】即可,结果如下,可以看到“has_more”的值为 true,“page_token”返回一个字符串。
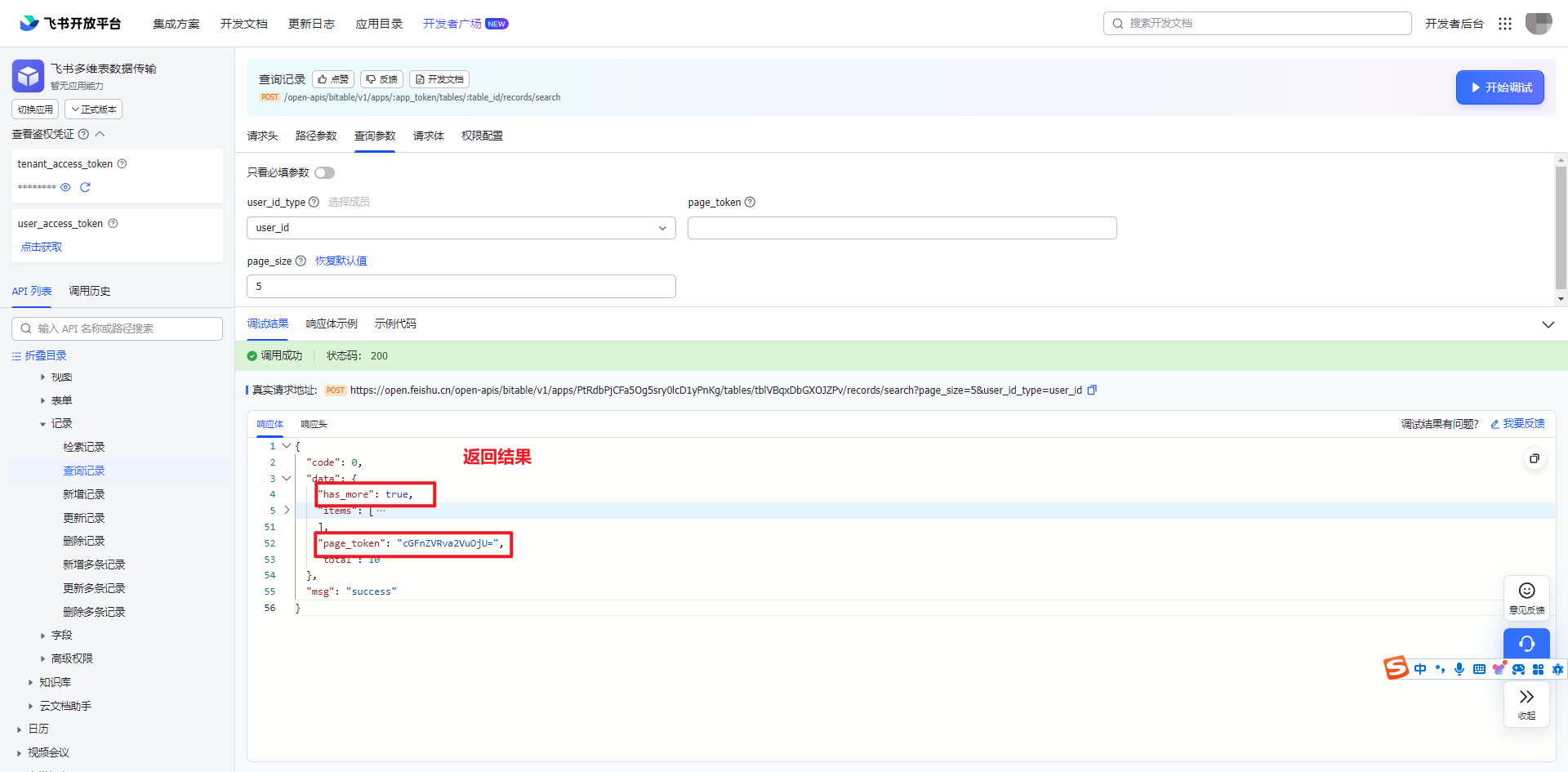
注:数据在响应体的 data>items 中,可以展开和多维表的记录比对查看下。
1.1.2 读取第 2 页
将首次请求返回的“page_token”的值填写到路径参数中“page_token”的输入框里,再次点击【开始调试】发起请求。
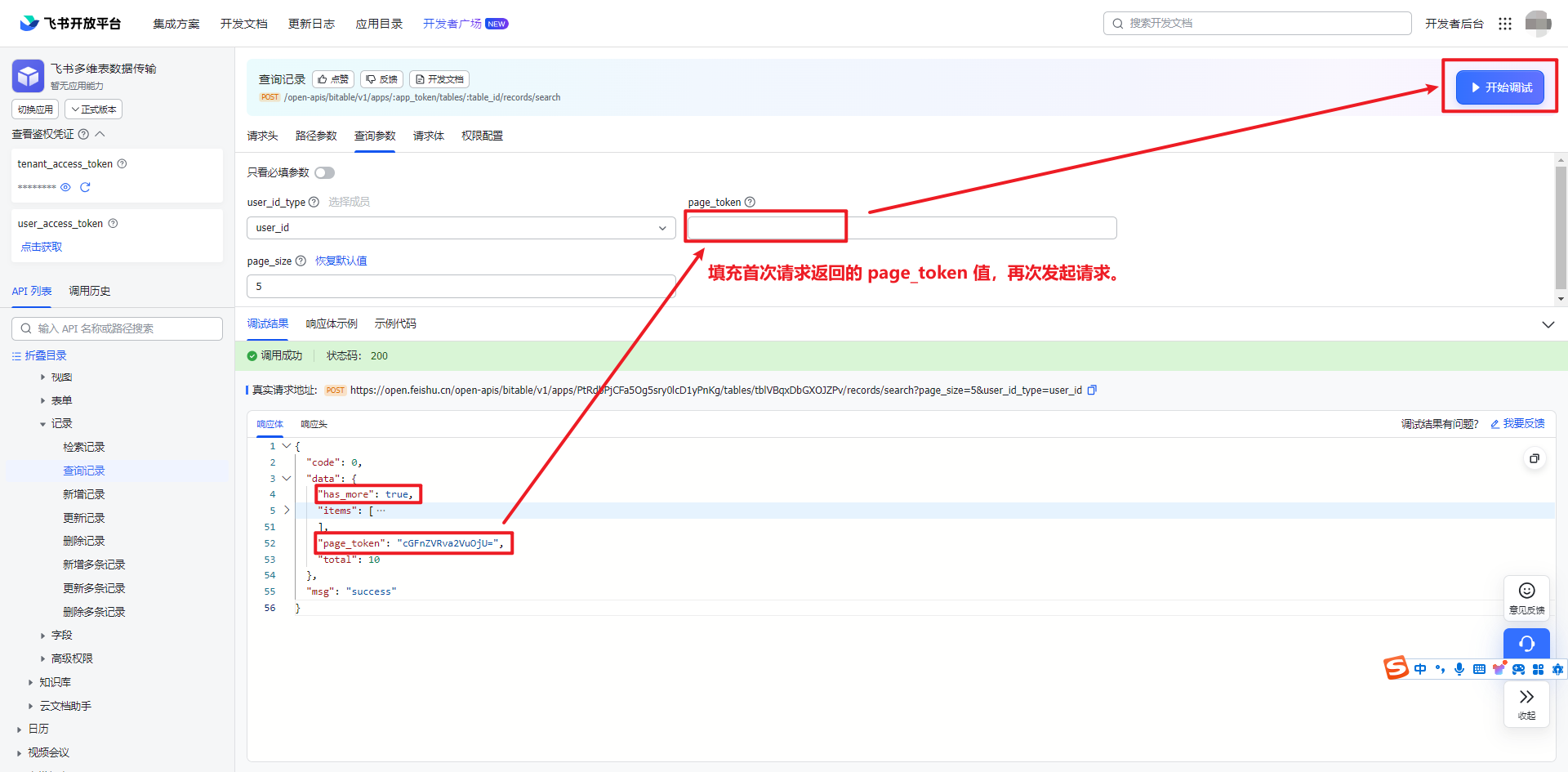
结果如下,可以看到“has_more”为 false,没有“page_token”参数。10 条记录分两次取完了,所以这个结果符合预期。
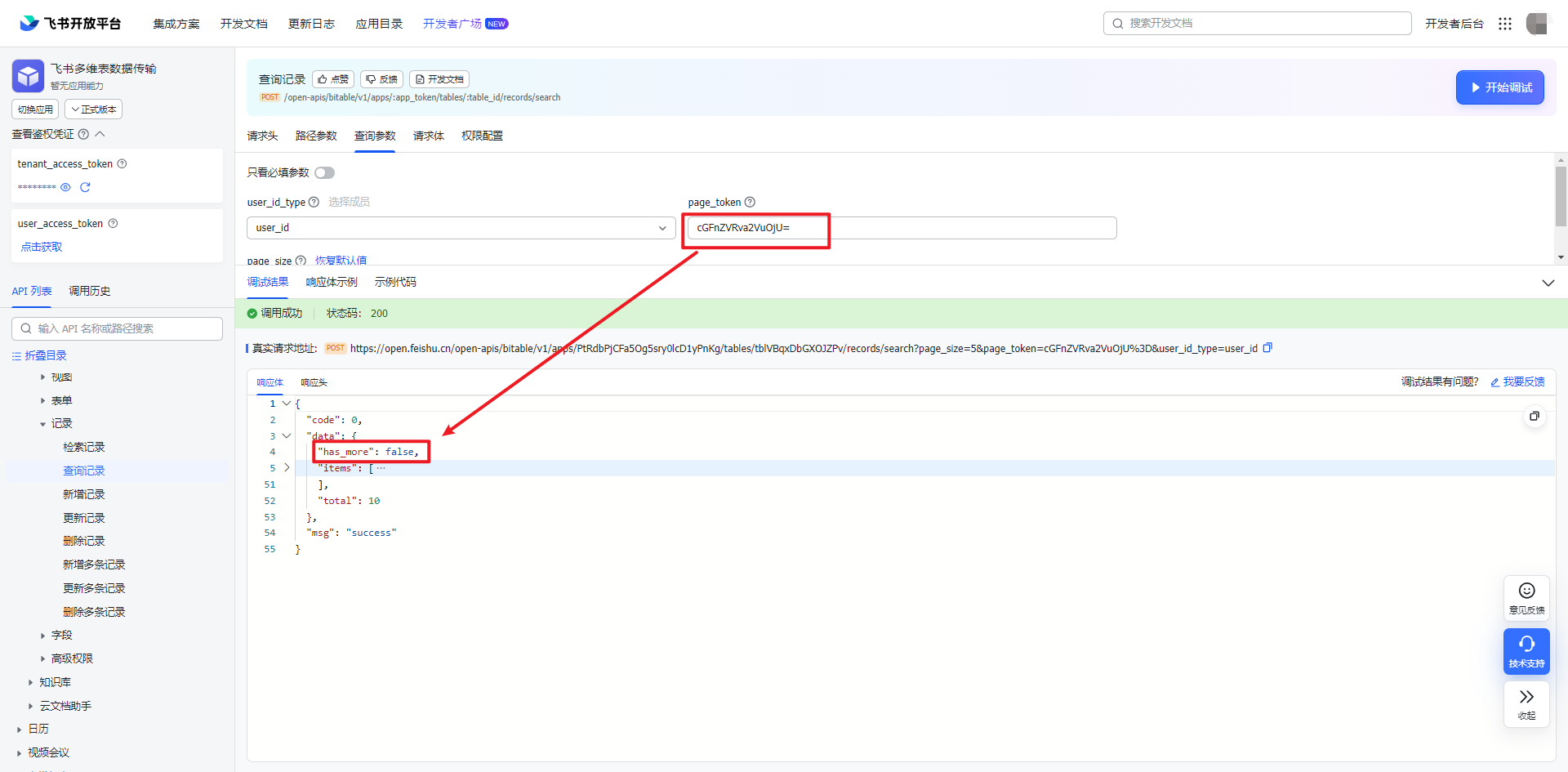
1.2 调试:本地测试读取第二页数据
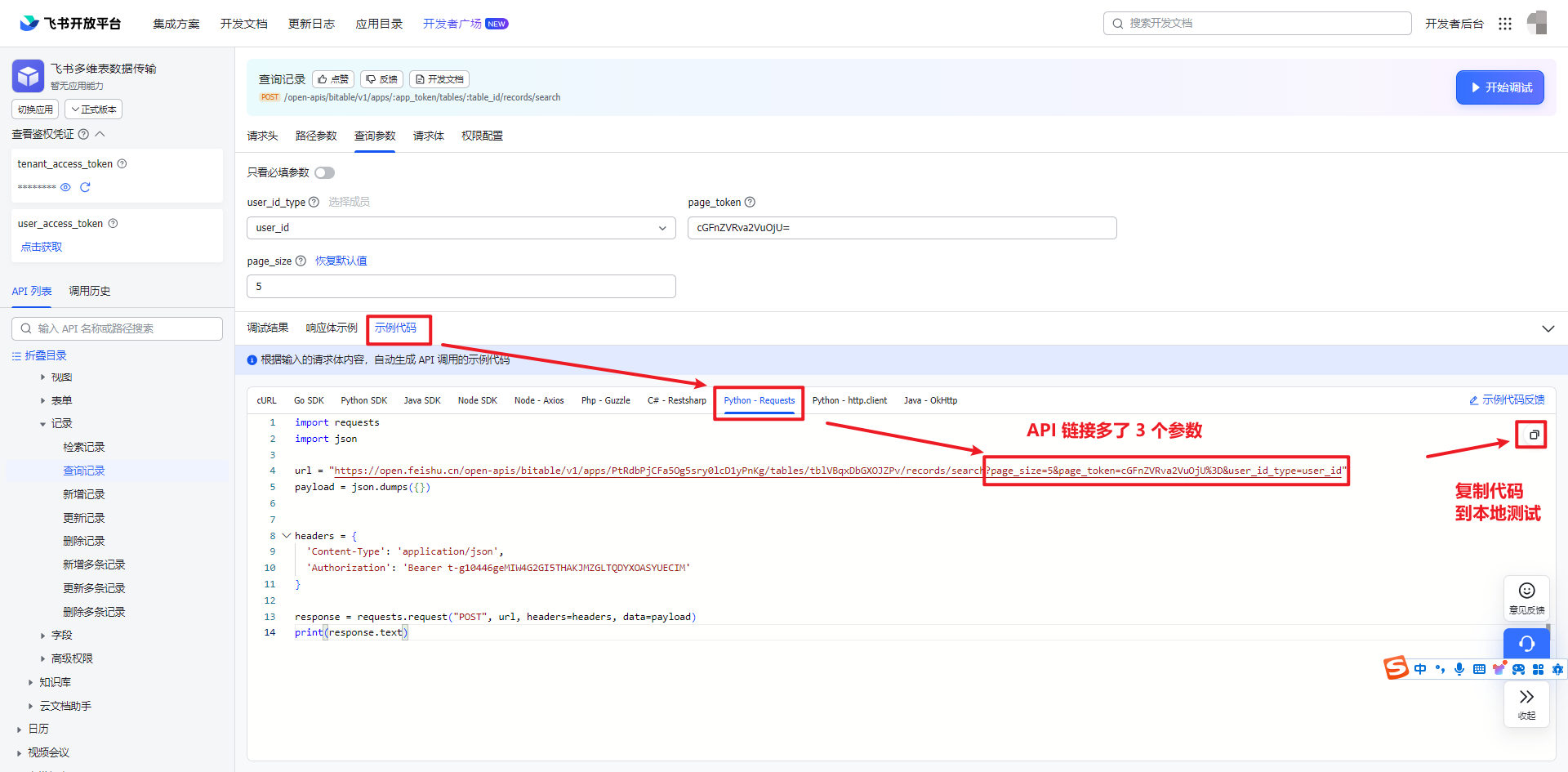
续上,第二次请求结果,点击示例代码,点击“Python-requests”,可以看到 API 连接多了 3 个参数,复制代码到本地测试运行。
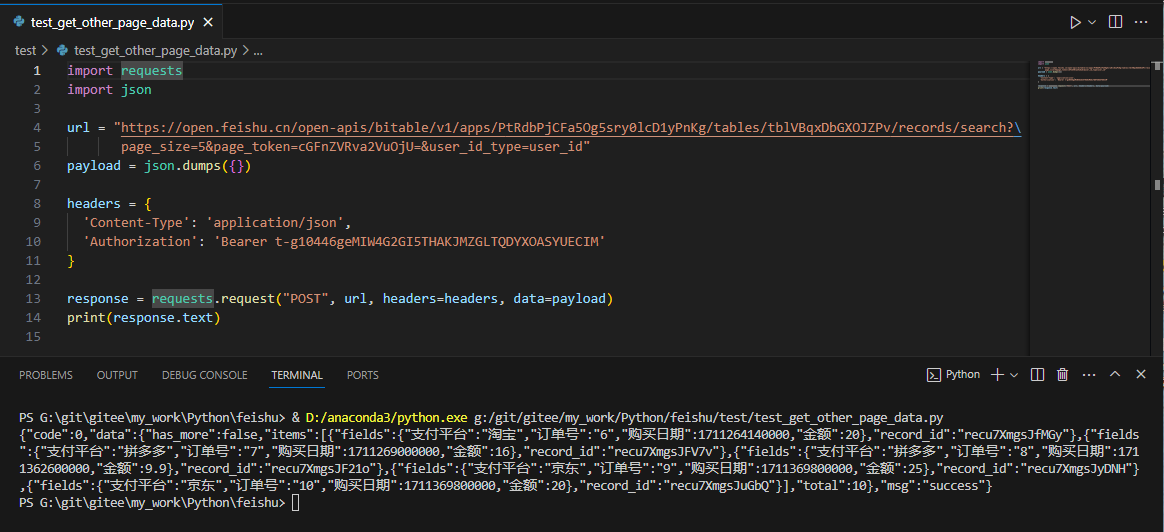
测试结果如下,正常获取到第二页的数据。
2、使用 Python 自动读取所有分页数据
上面通过手动输入“page_token”的方式读取到了测试文档的所有数据,在实际生产过程中,不可能手动一页页处理,所以需要通过代码自动将第一次获取的“page_token”传递给第二次请求。
根据飞书提供的信息,至少我们可以有三种方法来穷尽读取任意多维表的所有数据。
- 方法一:通过 while 循环读取
- 方法二:通过 for 循环读取
- 方法二:通过内函数递归读取
上一小节最后有一个获取tenant_access_token并调接口读取数据的合并代码(代码如下)。本次测试基于该代码进行迭代。
import requests
import json
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()['tenant_access_token']
def get_bitable_datas(tenant_access_token, app_token, table_id):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search"
payload = json.dumps({})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
get_bitable_datas(tenant_access_token, app_token, table_id)
2.1 while 循环读取分页数据
思路:主代码使用while循环调用get_bitable_datas()函数,并处理提取page_token,在下一次循环传递给get_bitable_datas()函数。
get_bitable_datas()函数需要进行修改,以便适配任意页的读取,并返回调用接口的数据。
url新增三个参数:page_size、page_token、user_id_type;第一页page_token=''可以正常请求数据;- 返回调用接口的数据:加上
return response.json()。
修改完参考如下:
def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()
主代码加上while循环,把调用get_bitable_datas()函数放到循环体中,并提取返回数据中的page_token和has_more,打印记录。参考如下:
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
page_token = ''
page_size = 5
has_more = True
while has_more:
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
has_more = response['data'].get('has_more')
print(response['data'].get('items'))
运行代码,结果如下:成功读取并打印分页的数据。
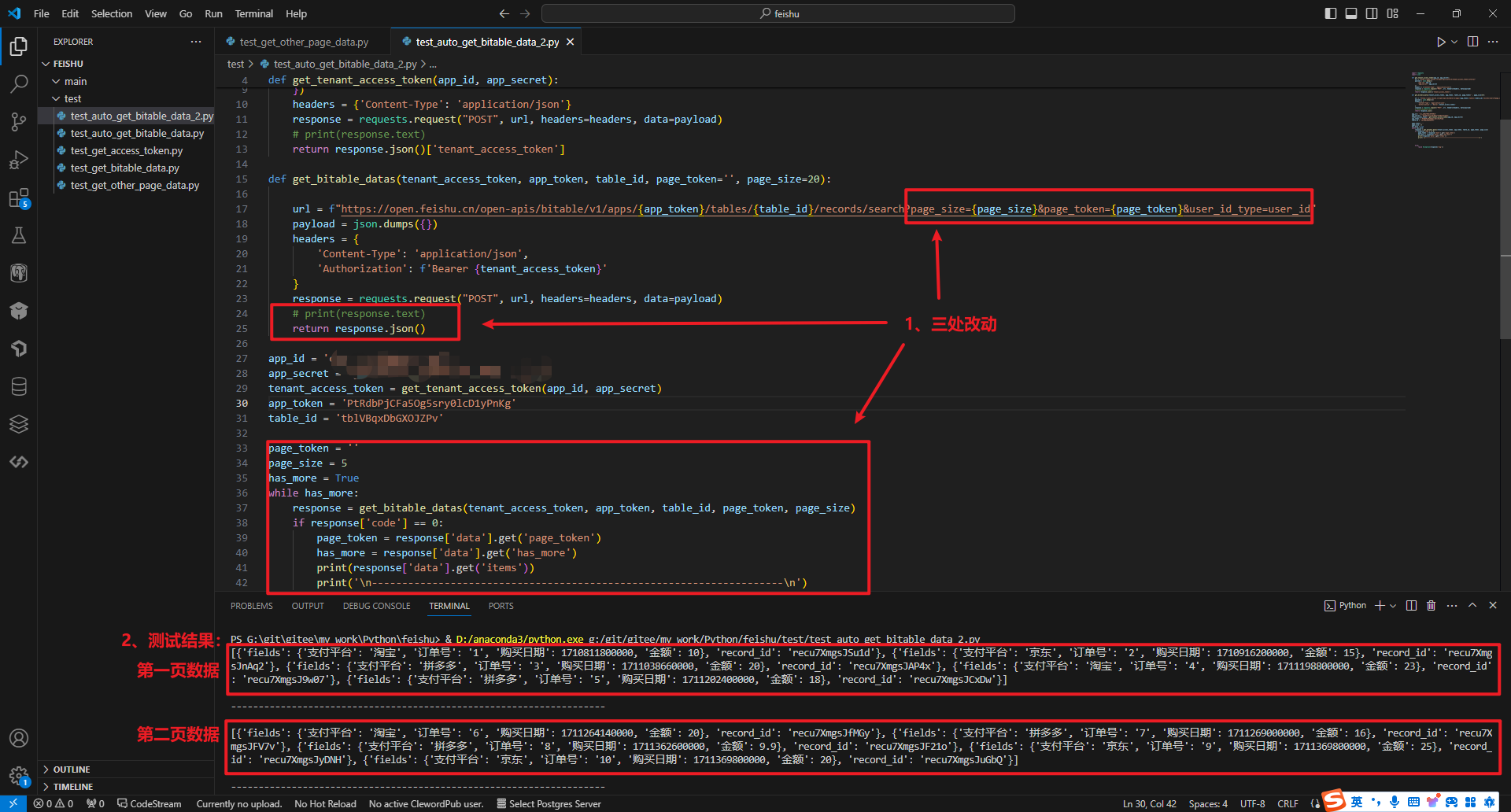
将主代码封装到main()函数中,并将所有返回的结果整到一个列表中,最终参考代码如下:
import requests
import json
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()['tenant_access_token']
def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()
def main():
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
page_token = ''
page_size = 5
has_more = True
feishu_datas = []
while has_more:
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
has_more = response['data'].get('has_more')
# print(response['data'].get('items'))
# print('\n--------------------------------------------------------------------\n')
feishu_datas.extend(response['data'].get('items'))
else:
raise Exception(response['msg'])
return feishu_datas
if __name__ == '__main__':
feishu_datas = main()
print(feishu_datas)
执行结果如下:
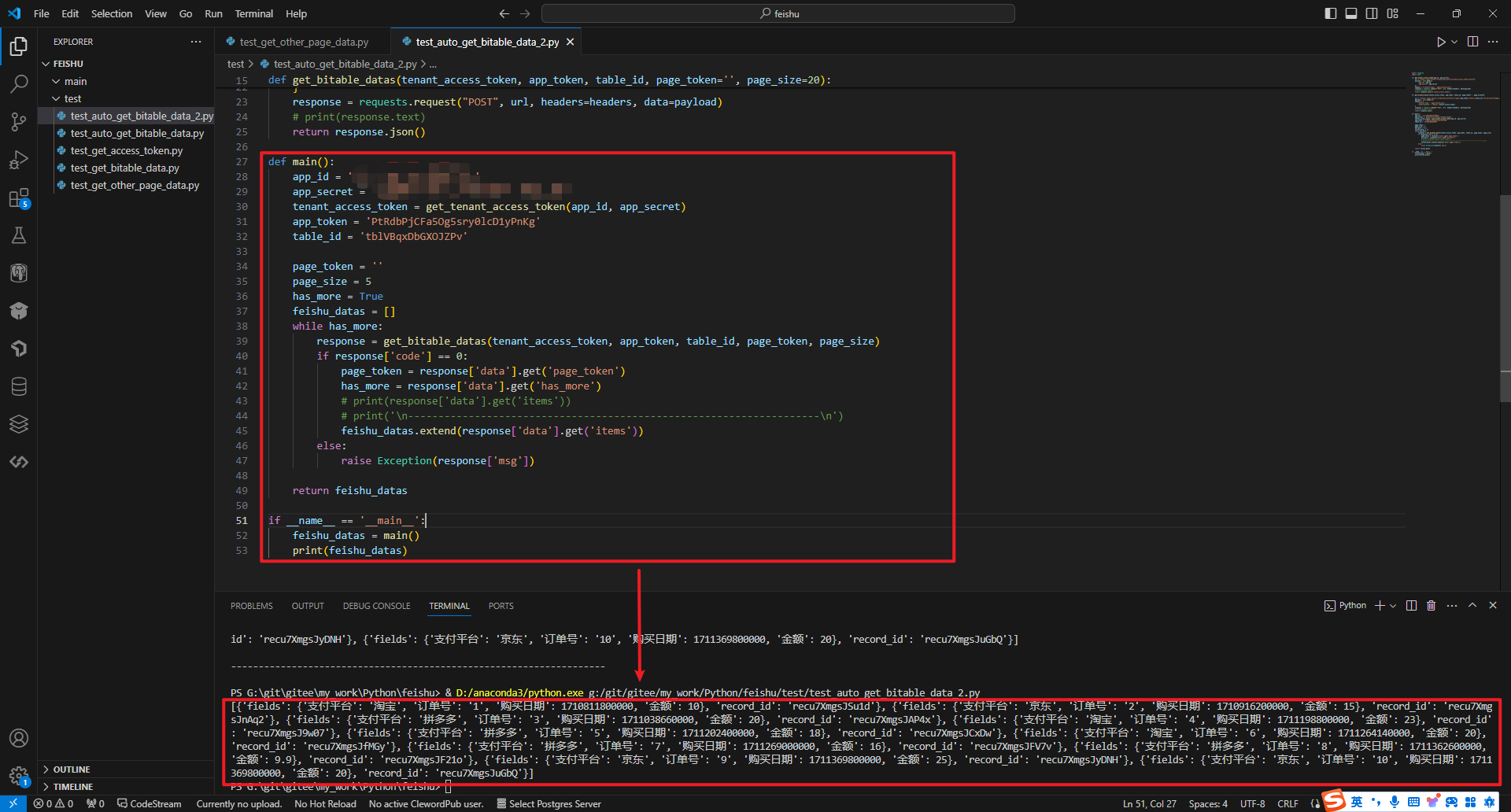
2.2 for 循环读取分页数据
注:在 2.1 基础上修改。
使用 for 循环,不如 while 循环便捷。因为 for 循环有一个难点,就是需要先确认循环的次数。而确认次数,需要知道总数据量。而确认总数据量,需要通过调接口获取,每次查询请求都会返回一个记录数据量的参数:total (如下图)。
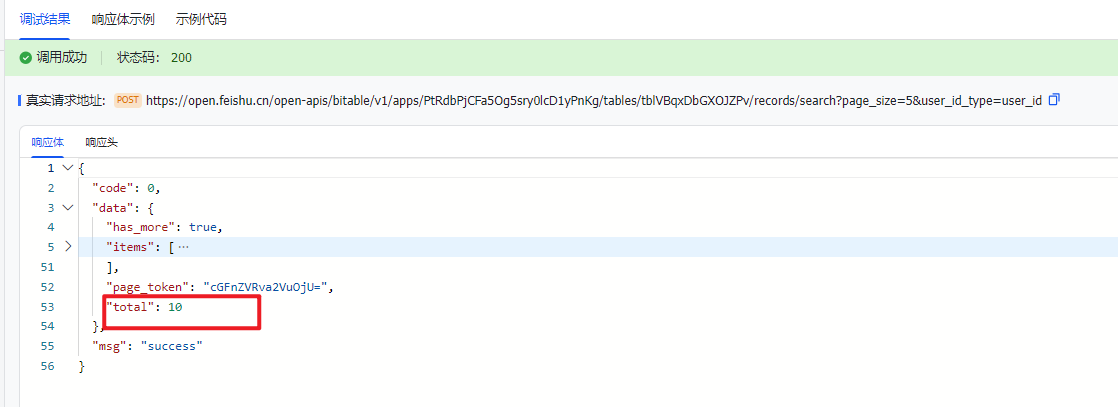
读取该值后结合每页的记录数page_size,使用公式total/size-1,然后向上取整来确定循环的次数。
关联核心代码如下:
- 先调一次接口获取到 total 的参数值,然后根据公式计算需要循环多少次(需要使用
math.ceil()方法向上取整);顺带将首次请求的page_token和feishu_datas处理 - 然后根据上面得到的次数进行遍历,读取后面页数的数据,并拼接到
feishu_datas中。
# 首次请求单独处理,获取 total、page_token、has_more、items
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
total = math.ceil(response['data'].get('total')/page_size - 1)
page_token = response['data'].get('page_token')
feishu_datas = response['data'].get('items')
# 非首次请求,统一处理
for i in range(total):
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
feishu_datas.extend(response['data'].get('items'))
最终的完整参考代码如下:
- 首次请求和非首次请求的数据分开处理;
- 使用 total 计算循环次数,不需要 has_more 参数。
import requests
import json, math
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()['tenant_access_token']
def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()
def main():
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
page_token = ''
page_size = 5
# 首次请求单独处理,获取 total、page_token、has_more、items
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
total = math.ceil(response['data'].get('total')/page_size - 1)
page_token = response['data'].get('page_token')
feishu_datas = response['data'].get('items')
# 非首次请求,统一处理
for i in range(total):
response = get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if response['code'] == 0:
page_token = response['data'].get('page_token')
feishu_datas.extend(response['data'].get('items'))
else:
raise Exception(response['msg'])
else:
raise Exception(response['msg'])
return feishu_datas
if __name__ == '__main__':
feishu_datas = main()
print(feishu_datas)
执行结果如下:
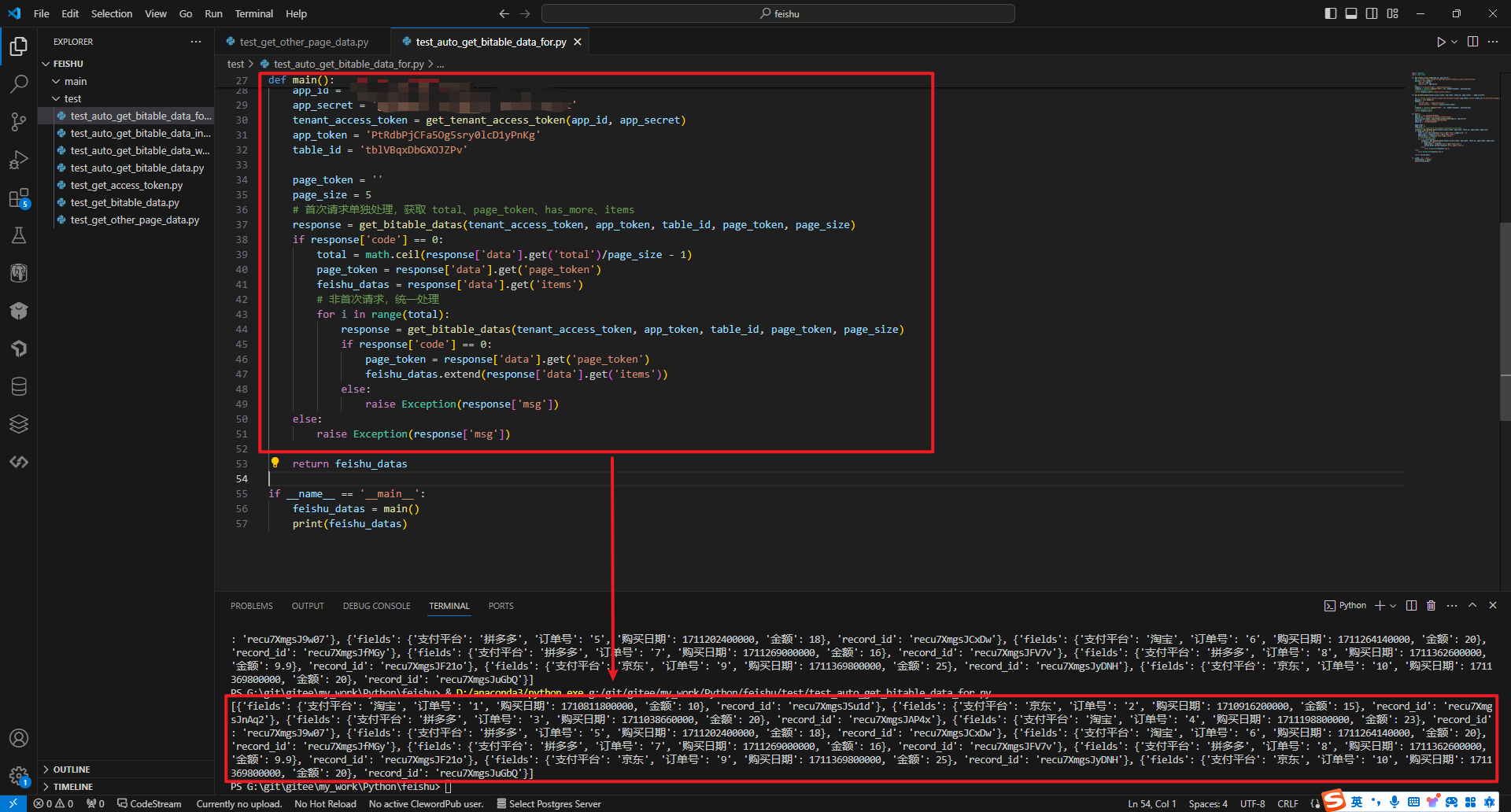
2.3 内函数递归读取分页数据
注:在 2.1 基础上修改。
本小节介绍使用内函数进行递归处理,相对会比较复杂。
目标是传入相关的参数,便可获取到多维表的所有数据。
实现该目标主要是在get_bitable_datas()函数中进行迭代:
- 递归逻辑:加上内函数
inner(),在内函数中调用外函数get_bitable_datas(); - 什么时候调用内函数?
has_more为True的时候。
数据的存储问题:将存储数据的列表feishu_datas放到函数外作为全局变量,函数get_bitable_datas()的功能是给列表feishu_datas添加元素。
直接看看最终完整的参考代码:
- 将
feishu_datas变量放到函数之前,使得全局可调用 get_bitable_datas()中新增内函数inner(),该函数功能只有一个就是调用外函数get_bitable_datas()。当has_more值为True的时候,便不断调用内函数inner(),也不断调用外函数get_bitable_datas(),直到最后一页has_more值为False时,一层层返回,最终得到记录所有数据的列表feishu_datas。- 在
main()函数中直接调用get_bitable_datas()函数便可得到记录所有数据的列表feishu_datas。
import requests
import json
feishu_datas = []
def get_tenant_access_token(app_id, app_secret):
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
payload = json.dumps({
"app_id": app_id,
"app_secret": app_secret
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
# print(response.text)
return response.json()['tenant_access_token']
def get_bitable_datas(tenant_access_token, app_token, table_id, page_token='', page_size=20):
url = f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records/search?page_size={page_size}&page_token={page_token}&user_id_type=user_id"
payload = json.dumps({})
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {tenant_access_token}'
}
response = requests.request("POST", url, headers=headers, data=payload).json()
def inner(tenant_access_token, app_token, table_id, page_token):
# 调用外函数,递归调用
get_bitable_datas(tenant_access_token, app_token, table_id, page_token)
if response['code'] == 0:
page_token = response['data'].get('page_token')
has_more = response['data'].get('has_more')
feishu_datas.extend(response['data'].get('items'))
if has_more:
# 调用内函数
inner(tenant_access_token, app_token, table_id, page_token)
else:
raise Exception(response['msg'])
def main():
app_id = 'your_app_id'
app_secret = 'your_app_secret'
tenant_access_token = get_tenant_access_token(app_id, app_secret)
app_token = 'your_app_token'
table_id = 'your_table_id'
page_token = ''
page_size = 5
get_bitable_datas(tenant_access_token, app_token, table_id, page_token, page_size)
if __name__ == '__main__':
main()
print(feishu_datas)
执行结果如下:

3、小结
使用 Python 读取多维表分页,需要传递“page_token”参数。
第一页“page_token”参数为空字符串,第二页开始从上一页的响应体提取“page_token”的值。
使用 Python 实现,可以通过三种方式读取所有分页的数据:while 循环读取、for 循环读取和内函数递归读取。
- while 循环:使用
has_more参数,直到has_more=False跳出循环; - for 循环:使用
total参数,结合page_size计算循环次数; - 内函数递归:使用
has_more参数递归调用内函数,直到has_more=False时逐层返回结果。
while 循环 相对比较好理解,而且很简洁。for 循环通过数量进行计算,或有一定风险,就是在读取的过程中,如果新增数据,可能会出现 bug,如果新增数据涉及新的页,将读取不到新增的数据。内函数递归方法,理解难度相对较高,代码相对简洁。
个人推荐顺序:while 循环>内函数递归>for 循环。







![[Linux][进程控制][进程程序替换]详细解读](https://img-blog.csdnimg.cn/direct/56a45e5de4454a8491445860e8d9a60a.png)