对于一些生成式场景而言,没有固定的回答结果,采用AI Agent的增强范式,可以极大地提升模型生成的效果。但是对于有固定格式、输出目标的场景而言,仅从prompt优化的角度出发很难突破瓶颈,需要通过微调来提升效果(如:分类模型);
微调方法汇总
微调的目标是提升在特定任务上的效果,因此需要搜集特定领域样本数据,然后选择合适的方法进行微调。那么选择哪种方式来更新模型参数,也是十分重要的一环,模型参数的更新大致可分为以下几种:
| 微调方法 | 描述 | 特点 | 代表方法 |
|---|---|---|---|
| 全参数调整 | 算不上真正意义上的微调,在预训练模型基础上进行全量参数调整 | 需要有大量的样本和计算资源做支撑,成本较高 | 预训练模型均可进行全量参数优化,无特殊技巧 |
| 引入强化学习 | 引入奖励模型(RM),是用一对(prompt,response)和一个奖励分数来训练一个模型,在给定输入上输出分数是机器学习中一个非常常见的任务,可以将其看作是分类或回归任务。该模型为每一个文本输入到文本输出的结果打分,来评估模型的性能。 | 依赖于奖励模型人工标注的质量,成本较高 | RLHF |
| 部分参数调整 | 大部分是冻结模型前面的参数层,仅调整后面几层的参数 | 保持模型的部分知识(如低级特征提取)不变,基于此进行微调,在大部分任务上效果不如LoRa、Adapter等方式 | BitFit |
| 增加Adapter | 在原始预训练模型基础上,额外增加几层Adapter,对新增的Adapter进行参数调整 | 会增加额外的计算成本和参数量,使得推理时间变长 | Adapter Tuning及其变体 |
| 增加前缀Token | 在模型输入或隐藏层增加可学习的前缀Token,只训练前缀参数,相当于为不同任务训练不同的自适应prompt | 为前缀保留部分序列长度会导致处理下游任务的序列长度减少 | Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2 |
| 重构简化参数 | 通过学习小参数的低秩矩阵近似模拟模型权重矩阵的参数更新,微调时仅训练低秩矩阵的参数 | 思路巧妙,结构简单效果好,适配性强 | LoRA、AdaLoRA、QLoRA |
| 混合调整 | 在Adapter、Prefix Tuning和LoRA等方法间建立联系的联合微调方法 | 结合各种微调提升技术的优点,集成的高效微调方式 | MAM Adapter、UniPELT |
微调主要方法发展进程:
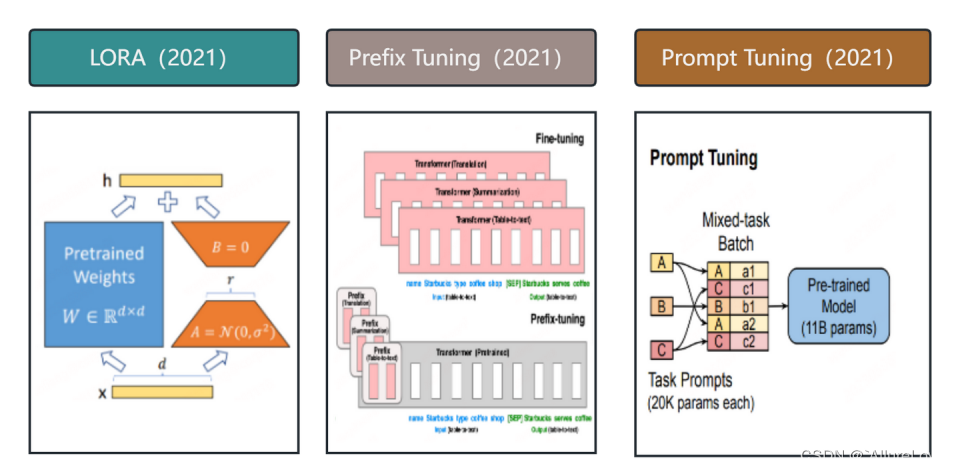
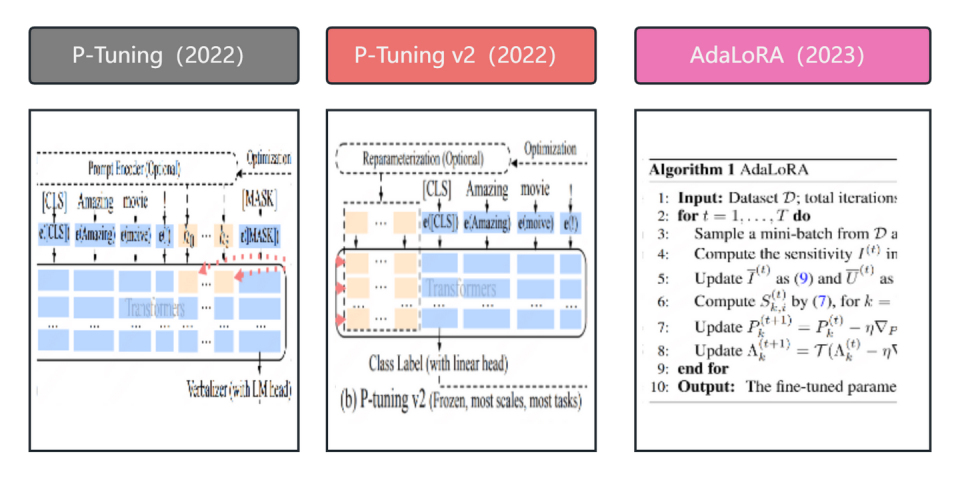
上述微调技术现在已经封装至现有的微调框架,主流的微调框架有:
- DeepSpeed Chat : 微软开源,提供了一键式RLHF训练框架,奖励模型微调和基于人类反馈的强化学习(RLHF),此外还实现了DeepSpeed HE,统一的高效混合引擎,达到训练和推理引擎之间的过渡是无缝的。;
- PEFT:PEFT 是 Huggingface 开源的一个参数高效微调库,它提供了最新的参数高效微调技术,并且可以与 Transformers 和 Accelerate 进行无缝集成;
其中PEFT使用较为广泛,微调优化算法中LoRA的应用较为广泛,因为能在少量(1000左右)数据集的基础上调整少量参数,就能够较好地适配目标场景;
资料汇总
上述方法相关资料汇总,有时间可以学习下原文:
| 方法 | 时间&机构 | 论文链接 | 代码链接 |
|---|---|---|---|
| RLHF | 2023微软 | DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales | DeepSpeed-Chat |
| BitFit | 2022巴伊兰大学 | BitFit: BitFit: Simple Parameter-efficient Fine-tuning or Transformer-based Masked Language-models | BitFit |
| Adapter Tuning | 2019谷歌 | Parameter-Efficient Transfer Learning for NLP | adapter-bert |
| Prefix-Tuning | 2021斯坦福大学 | Prefix-Tuning: Optimizing Continuous Prompts for Generation | PrefixTuning |
| Prompt Tuning | 2021谷歌 | The Power of Scale for Parameter-Efficient Prompt Tuning | prompttunning |
| P-tuning | 2021清华 | GPT Understands, Too | P-tuning |
| P-tuning v2 | 2022清华 | P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks | P-tuning-v2 |
| LoRA | 2021微软 | LoRA: Low-Rank Adaption of Large Language Models | LoRA |
| AdaLoRA | 2023微软 | Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning | AdaLoRA |
| QLoRA | 2023华盛顿大学 | QLORA: Efficient Finetuning of Quantized LLMs | qlora |
| MAM Adapter | 2022卡内基梅隆&南加利福利亚大学 | Towards A Unifined View of Parameter-Efficient Transfer Learning | unify-parameter-efficient-tuning |
| UniPELT | 2022伊利诺伊大学&Meta | UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning | UniPELT |
参考:
- 微调入门篇:大模型微调的理论学习
- 利用RLHF优化大模型:提升性能与应用能力
- 大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT
- llm-action:超全大模型微调实战教程
- 大模型的领域适配 —— Parameter-Efficient Fine-Tuning (PEFT)
- LoRA(Low-Rank Adaptation)详解








![[BT]BUUCTF刷题第14天(4.10)](https://img-blog.csdnimg.cn/direct/d412f42d241a46eba7eacefef7593b4b.png)