背景描述
可以将问答的内容缓存起来,如果是相同的问题,那么将会直接把答案返回去,可以节约费用和计算。
安装依赖
pip install -qU langchain-core langchain-openai
编写代码
我们可以通过 InMemoryCache 进行内存缓存 或者 SQLiteCache 进行持久化存储。
详细代码如下:
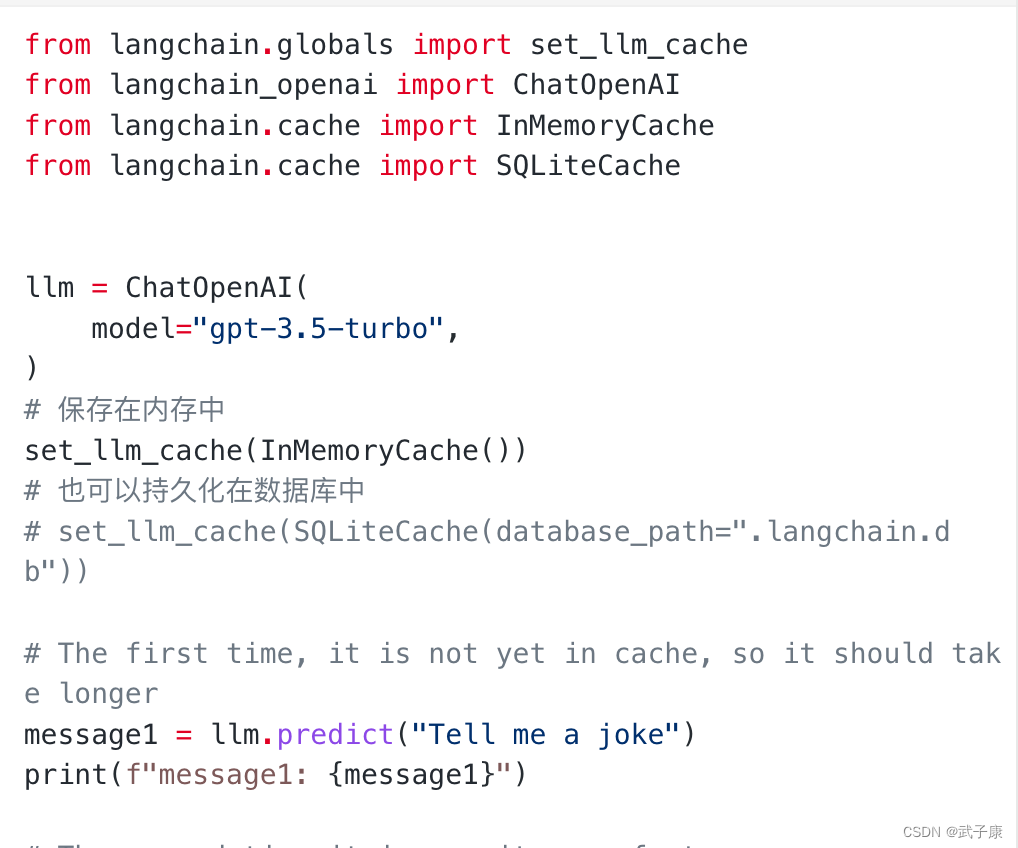
from langchain.globals import set_llm_cache
from langchain_openai import ChatOpenAI
from langchain.cache import InMemoryCache
from langchain.cache import SQLiteCache
llm = ChatOpenAI(
model="gpt-3.5-turbo",
)
# 保存在内存中
set_llm_cache(InMemoryCache())
# 也可以持久化在数据库中
# set_llm_cache(SQLiteCache(database_path=".langchain.db"))
# The first time, it is not yet in cache, so it should take longer
message1 = llm.predict("Tell me a joke")
print(f"message1: {message1}")
# The second time it is, so it goes faster
message2 = llm.predict("Tell me a joke")
print(f"message2: {message2}")
运行结果
在运行过程中,可以直观的感受到,第一次的运行速度是比较慢的,但是第二次是非常快的。
说明当中是进行缓存了,第二次直接从内存中进行返回的。
当然,如果进入后台查看API的调用情况,也会发现,只有第一次走了OpenAI的API,第二次是没有的。
➜ python3 test18.py
/Users/wuzikang/Desktop/py/langchain_test/own_learn/env/lib/python3.12/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function `predict` was deprecated in LangChain 0.1.7 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
message1: Why did the tomato turn red? Because it saw the salad dressing!
message2: Why did the tomato turn red? Because it saw the salad dressing!