创新点:二次分解 + 多头注意力特征融合
往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
风速预测(七)VMD-CNN-BiLSTM预测模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-CSDN博客
多特征变量序列预测(一)——CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-CSDN博客
多特征变量序列预测(三)——CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-CSDN博客
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-CSDN博客
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型-CSDN博客
多特征变量序列预测(九)基于麻雀优化算法的CEEMDAN-SSA-BiGRU-Attention预测模型-CSDN博客
多特征变量序列预测(10)基于麻雀优化算法的CEEMDAN-SSA-Transformer-BiLSTM预测模型-CSDN博客
超强预测算法:XGBoost预测模型-CSDN博客
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
VMD + CEEMDAN 二次分解,CNN-LSTM预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型——代码全家桶-CSDN博客
多特征变量序列预测 -TCN 预测模型-CSDN博客
VMD + CEEMDAN 二次分解,CNN-Transformer预测模型-CSDN博客
Python轴承故障诊断 (17)基于TCN-CNN并行的一维故障信号识别模型-CSDN博客
交叉注意力融合时空特征的TCN-Transformer并行预测模型-CSDN博客
风速预测(八)VMD-CNN-Transformer预测模型-CSDN博客
前言
本文基于前期介绍的电力变压器(文末附数据集),介绍一种基于VMD+CEEMDAN二次分解的Transformer-BiGRU预测模型,以提高时间序列数据的预测性能。电力变压器数据集的详细介绍可以参考下文:
电力变压器数据集介绍和预处理_ett small数据集-CSDN博客
1 二次分解与数据集制作
1.1 导入数据
1.2 VMD分解
第一步,根据不同K值条件下, 观察中心频率,选定K值;从K=4开始出现中心频率相近的模态,出现过分解,故模态数 K 选为4。
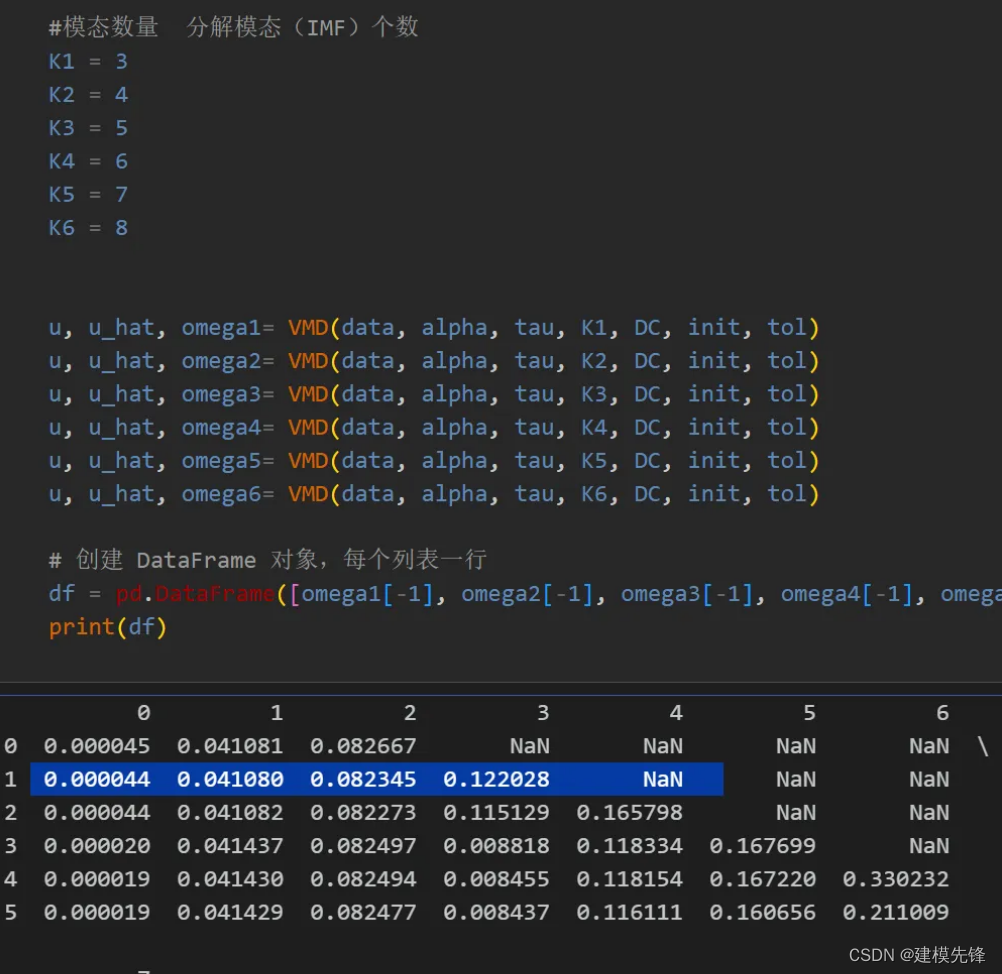
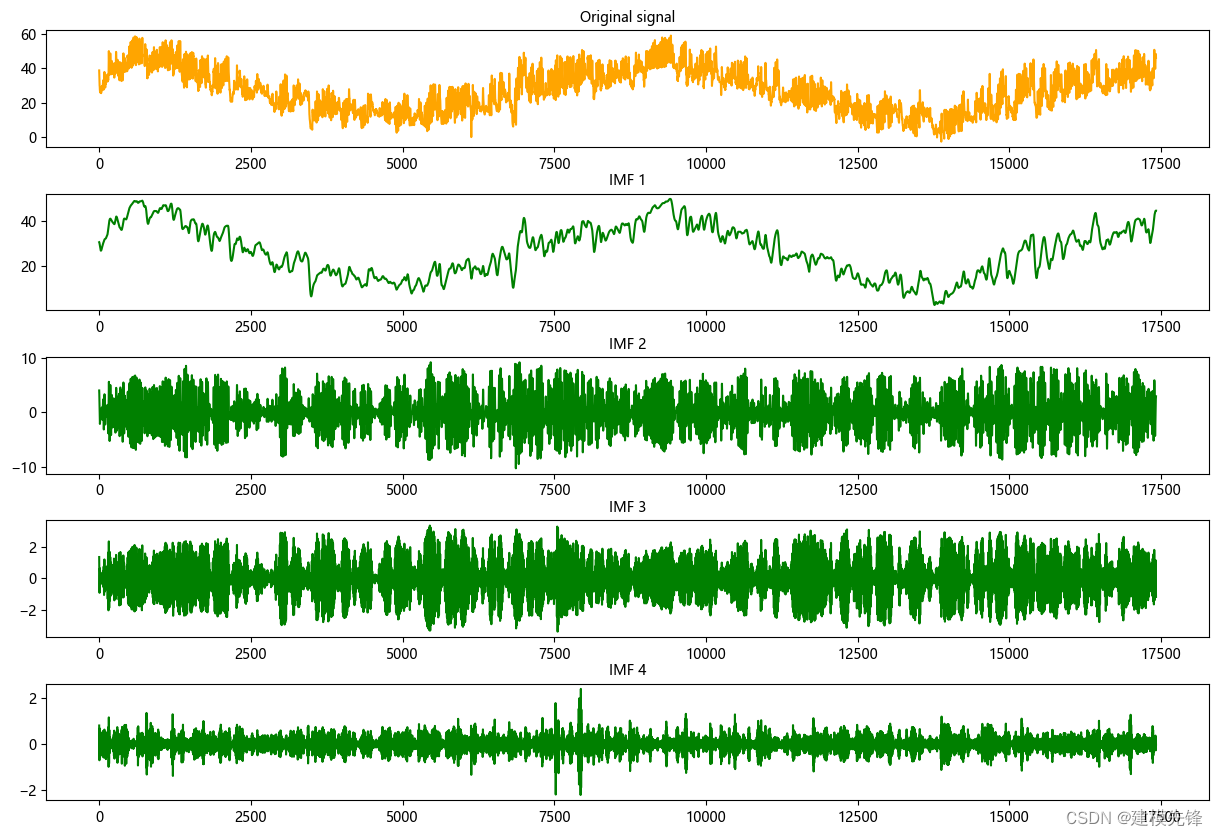
第二步,分解可视化
1.3 样本熵
样本熵是一种用于衡量序列复杂度的方法,可以通过计算序列中的不确定性来评估其复杂性。样本熵越高,表示序列的复杂度越大。
通过对VMD分解出四个分量的样本熵计算,高样本熵有着更丰富的不可控信息,为进一步提取分量中的有效信息,对VMD的最高熵值项,进行CEEMDAN分解
1.4 CEEMDAN分解
对 VMD分解出的 最高熵值项分量进行再分解

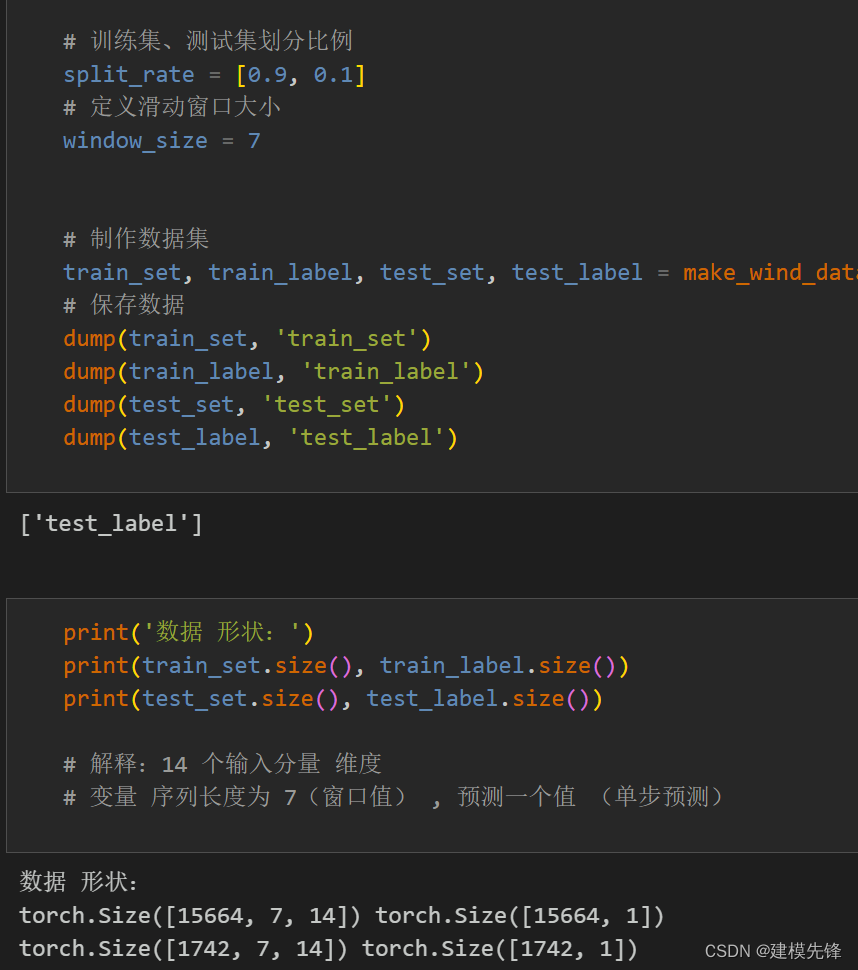
1.5 数据集制作
先合并VMD和CEEMDAN分解的分量,按照9:1划分训练集和测试集
2 基于Pytorch的 Transformer-BiGRU 预测模型
2.1 定义Transformer-BiGRU预测模型
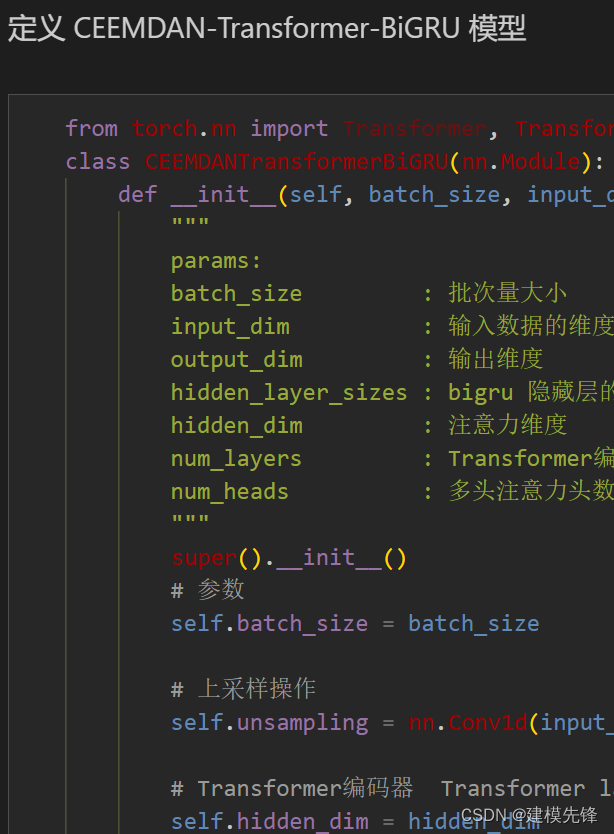
注意:输入风速数据形状为 [64, 7, 14], batch_size=64,7代表序列长度(滑动窗口取值), 维度14维代表合并分量的维度。
2.2 设置参数,训练模型
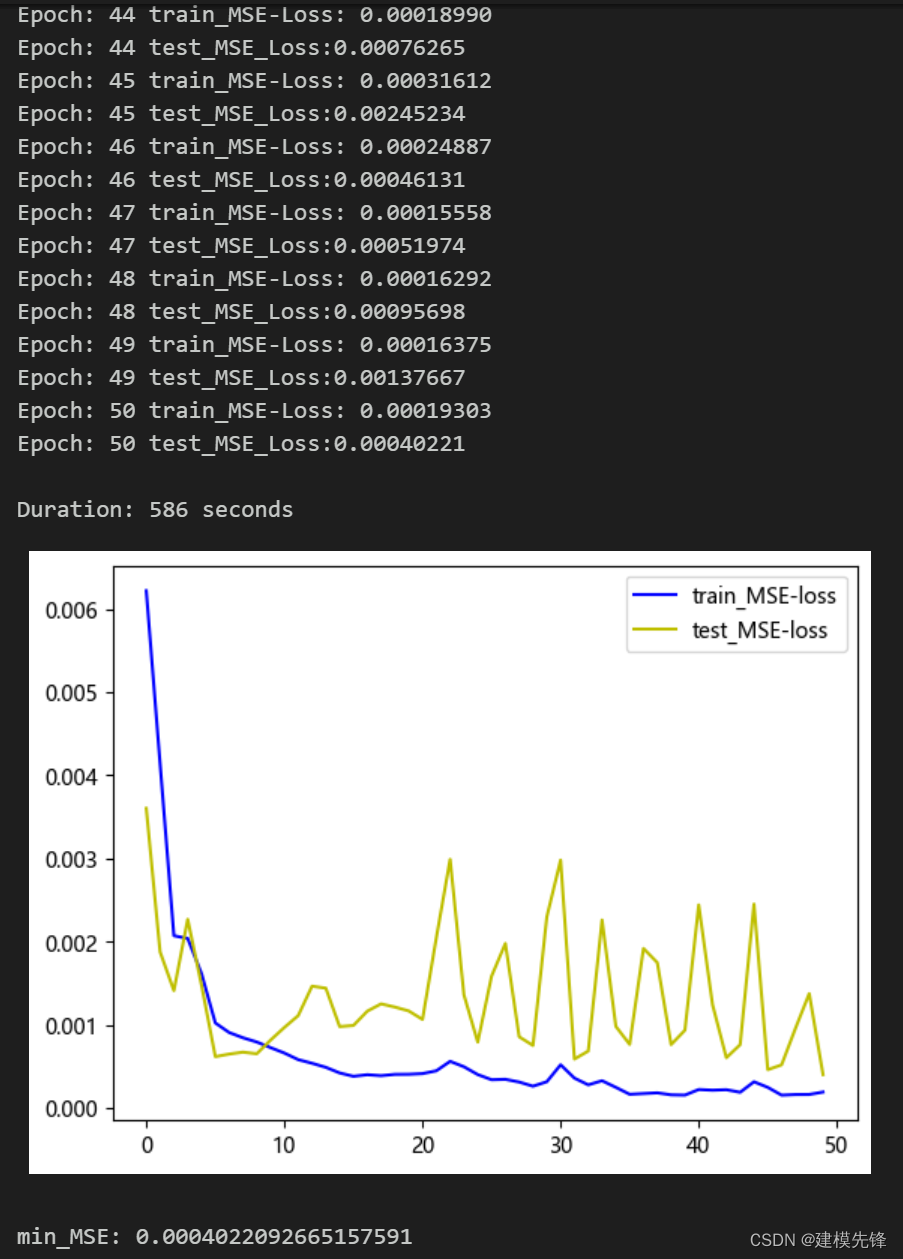
50个epoch,MSE 为0.000402,VMD+CEEMDAN二次分解的Transformer-BiGRU预测效果良好,二次分解后,能够提取序列中更多的信息,Transformer-BiGRU模型能够提取出分量特征的时空信息,预测效果提升明显,性能优越,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以修改BiGRU层数和每层维度数;
-
调整Transformer编码器层数和注意力维度数、多头注意力头数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
3 模型评估与可视化
3.1 结果可视化
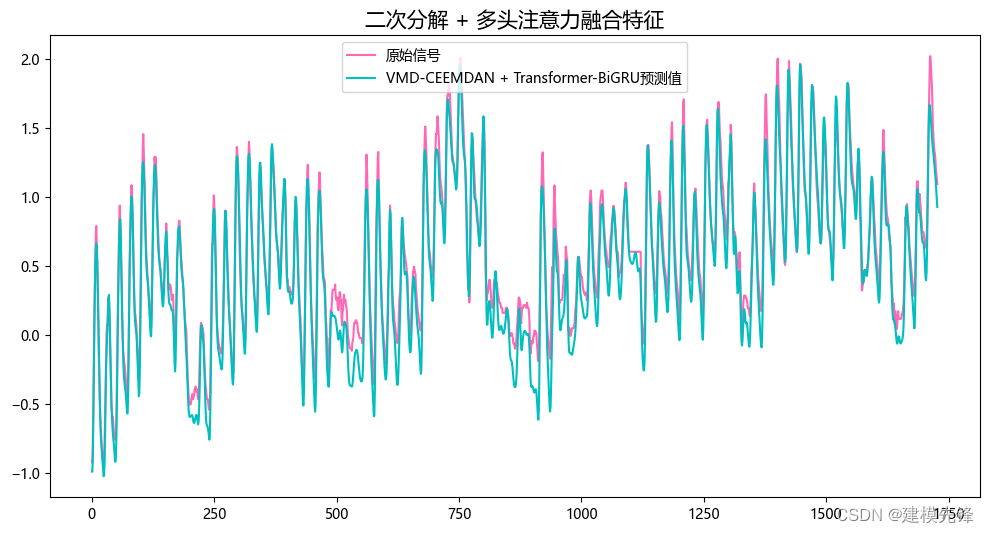
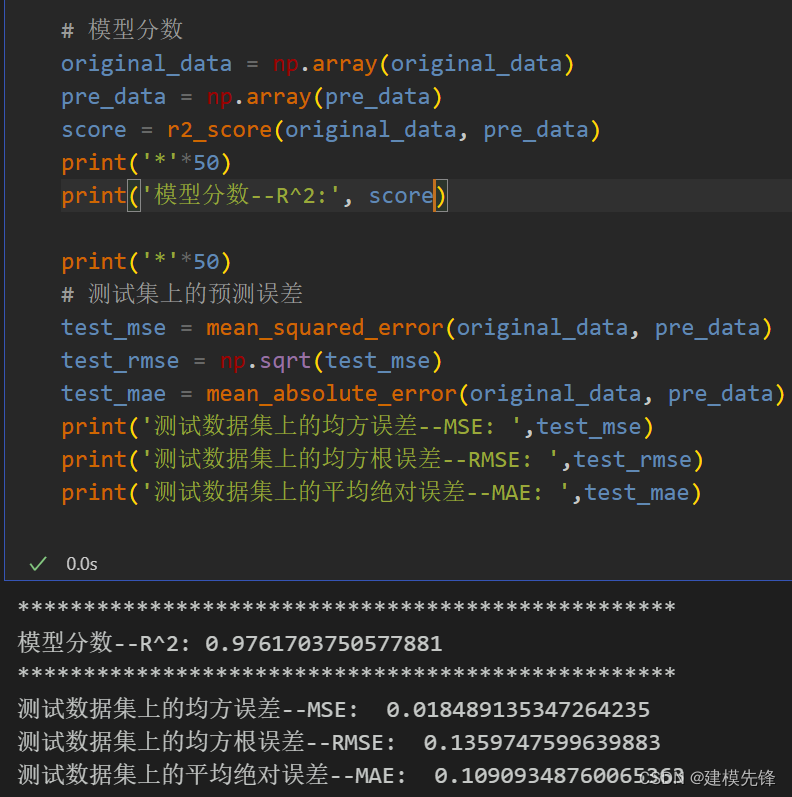
3.2 模型评估
代码、数据如下:
对数据集和代码感兴趣的,可以关注最后一行
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#代码和数据集:https://mbd.pub/o/bread/ZZ2WlJdv