目录
前言:
1.成员变量,容量与大小
2.构造函数
无参构造:
带参的使用值进行构造:
使用迭代器区间进行构造:
3.交换
4.拷贝构造
5.赋值重载
6.迭代器
7.扩容
reserve:
resize:
8.插入与删除
insert:
erase:
insert迭代器失效问题:
erase迭代器失效问题:
9.头插头删
10.[]重载
11.完整代码与测试
总结:
前言:
本篇来实现stl容器vector,有了前面string的基础,会实现起来更加的顺畅同样也是挑重要的接口来实现,结尾会附上完整代码。
1.成员变量,容量与大小
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
这里的成员变量都是指针实现的,_start指向开始的位置也就是第一元素,_finish指向最后一个元素的下一个位置,所以是开区间,_end_of_storage是容量大小,也就是指向容器的最后一个位置。
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}
大小就是最后一个元素的下一个位置减去开始的位置,也就是有效数据的个数。
容量就是可能扩容好的最后的位置减去开始的位置。
注意可以是const成员调用的,所以用const成员修饰函数,这里没有分开const修饰的函数与普通的函数是因为我们实际就算是访问容量与大小也不会修改数据;而像迭代器要分开是因为,我们会使用普通迭代器解引用修改数据,要区分开。
2.构造函数
无参构造:
vector()
:_start(nullptr)//不管调用哪个构造,带参的还是不带参数的,都要给初始化列表,因为不给初始化后成员变量都是随机值;或者是成员变量声明时给缺省
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
注意不管是带参的构造还是无参的构造,都要在初始化列表给初始化,因为不然成员变量里面都是随机值;或者是在声明成员变量的时候给上缺省值。
带参的使用值进行构造:
vector(size_t n, const T& val = T())//任意类型都有默认构造,例如模版参数是int也就成0了
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n;++i)
{
push_back(val);
}
}
vector(int n, const T& val = T())//没有这个会出现非法的间接寻址的错误,编译器识别不出来两个参数的构造是调用迭代器的那个还是这个。
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n; ++i)
{
push_back(val);
}
}
首先参数里面的第二个参数是使用匿名对象进行初始化的,我们要知道c++既然设计了面对对象的特性,那构造就不能只针对自定义类型来说了,或者说构造的时候让编译器取区分自定义类型与内置类型会带来麻烦,所以我们使用匿名对象进行构造初始化,也就是说这个构造的缺省值是T类的对象,例如:
const int& a = int();//匿名对象具有常性
const char& b = char();
int c = int();//任意类型都有默认构造,这是使用匿名对象进行初始化
我们观察调试窗口可以发现:
 这些内置类型使用默认的构造也被初始化为0了。
这些内置类型使用默认的构造也被初始化为0了。
还有注意匿名对象是具有常性的,所以使用引用接收要加上const修饰 ,而如果使用引用接收匿名对象,匿名对象的生命周期会跟着引用而延长直道引用销毁。
现在我们搞懂了第二个参数,我们再来看看第一个参数为什么要重载成两个形式,因为我们如果直接使用size_t,再结合下面的迭代器的构造,编译器就识别不出了掉用哪一个了(但会选择最合适的,就是迭代器的构造,根据模版推演类型),所以最好还是重载一个,让编译器识别的更全面。
my_vector::vector<int> v1(10, 2);
上面的代码会报错如果没有int n这个参数的重载,因为10默认是int,会先优先匹配迭代器构造的模版参数,而不是识别size_t(因为这个会发生类型转换,模版直接就推演了)。
还可以这样解决:![]()
然后函数体内就是根据要初始化的数据个数,进行扩容,再尾插即可。
使用迭代器区间进行构造:
//类模版的成员函数还可以带模版,这个模版可以用主模板的模版参数,也可以用自己的
template<class InputIterator>
vector(InputIterator first, InputIterator last)//用迭代器区间初始化,这个迭代器区间的类型可以是任何迭代器区间的类型,所以给上模版参数
:_start(nullptr)
, _finish(nullptr)
,_end_of_storage(nullptr)
{
while (first != last)//不能用小于,假设是链表传过来的迭代器区间,空间不是连续的,不能保证前面的节点的地址就小于后面的
{
push_back(*first);
++first;
}
}
首先,类模版的成员函数还可以带模版,这个模版可以用主模板的模版参数,也可以用自己的,就是这里会跟上面的带参的构造矛盾。
其次,使用迭代器区间初始化就是保证可以让任意类型的迭代器区间都可以初始化vector,例子已在vector的使用中举过。
然后就是将传过来的迭代器区间一个一个尾插到vector这个容器中,注意判断条件不能使用小于,如果传的迭代器区间的类型是一个list也就是链表,我们知道链表的存储并不是连续的,所以不能保证前面的空间的地址一个小于后面的空间地址。
3.交换
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
直接调用库中的交换即可,直接写还需要有三个深拷贝。
注意这里的swap的参数不能是const,如果使用const修饰,那v就不能变了,所以里面的成员指向的空间也不能变,交换可是要交换空间的。
4.拷贝构造
不传统的拷贝构造,但是是可以的
//vector(const vector<T>& v)
//{
// reserve(v.capacity());
// for (auto e : v)
// {
// push_back(e);//this->push_back(e)
// }
//}
//vector(const vector<T>& v)
//{
// //reserve(v.capacity());
// //扩容也可不复用
// _start = new T[v.capacity()];
// //memcpy(_start, v._start, sizeof(T) * v.size());
// for (size_t i = 0; i < v.size(); ++i)
// {
// _start[i] = v._start[i];//[]就是解引用
// }
// _finish = _start + v.size();
// _end_of_storage = _start + v.capacity();
//}
//很现代的拷贝构造(不对???为什么???要提供两个迭代器区间的构造才能用)
//vector(const vector<T>& v) //语法上支持拷贝构造和赋值不加模版参数
vector(const vector<T>& v)
{
vector<T> tmp(v.begin(), v.end());//这个要提供两个迭代器区间的构造才能用
swap(tmp);
//swap(v);//不能这样直接调用,v的类型不支持swap的参数
}
这里一个提供了3个拷贝构造,第一个我们让它叫做不传统的拷贝构造,因为它利用了范围for,其实就是先根据拷贝的对象扩容,然后再进行赋值尾插到要拷贝的内容中去。
第二拷贝构造是传统的拷贝构造,先扩容再开空间深拷贝,注意这里的赋值就是深拷贝,因为如果假设模版是string类型的,在赋值的时候解引用找到的就是string类型的元素,再赋值就是去调用string内部的赋值重载;而这样使用memcpy是按字节进行拷贝的,所以还会造成拷贝完了,new出来的变量是指向同一块空间的,然后析构两次会出错,并且插入删除数据会混乱。
最后要更新大小与容量。
第三个是更现代的拷贝构造,也就是复用了swap,这样不能直接调用swap,因为swap的参数没有const修饰,而这里的v是const类型的,不匹配,所以要先用要拷贝的对象构造出一个对象,再进行交换。
5.赋值重载
vector<T>& operator=(vector<T>& v)
{
swap(v);
return *this;
}
直接复用即可,这里就可以直接交换了, 参数是匹配的;最后要有返回值,支持连续赋值。
6.迭代器
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
iterator begin() const
{
return _start;
}
iterator end() const//这里的const是修饰的调用者的const,所以调用者不能修改数据;而返回值是如果是const迭代器那就是迭代器不能走了,不能遍历了,不行
{
return _finish;
}
7.扩容
reserve:
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n];
if (_start)//如果旧空间为空,就不进if了,直接让旧空间开好的空间;其次也因为if中要对_start解引用
{
//memcpy是浅拷贝,因为按字节拷贝还是两个开辟出了的指针指向同一块空间
//memcpy(tmp,_start,sizeof(T)*size());//这里乘capacity可能会造成浪费,因为capacity开的空间比较多
for (size_t i = 0; i < size(); ++i)
{
tmp[i] = _start[i];//如果模版参数是string这样的自定义类型,而且有开辟的空间,肯定是要深拷贝的,而这里的赋值就会调用string的赋值,符合深拷贝
}
delete[] _start;
}
_start = tmp;
_finish = sz + _start;//虽然扩容了,但是原有的finish的位置不能变,所以上面要记录一下;而且_start也变了,原来的size()就不能用了
_end_of_storage = _start + n;
}
}
扩容首先要记录大小,因为虽然扩容了,但是_finish与_statr的距离不会变,如果不记录,后面的_start要么销毁要么找不到了,不能使用了。
扩容就是先开空间,然后旧空间内容深拷贝给新空间,释放旧空间,再让旧空间指向新空间,原来在string的实现中以说过。
注意后面的更新需要用原来的旧空间的大小更新(这里就体现了记录原来大小的作用),容量就用扩好的容量更新。
resize:
void resize(size_t n,T val=T())//任意类型都有默认构造
{
if (n < capacity())
{
_finish = _start + n;
}
else
{
if (n > capacity())
{
reserve(n);
}
while ((_start + n) != _finish)
{
*_finish = val;//源码使用的是定位new,但这里的空间都是直接new出来的,定位new针对的是内存池
_finish++;
}
}
}
如果是传的容量小于原来的容量,就是删除数据,否则就是扩容,然后将扩容后的数据给上初始化的值,默认是0。
8.插入与删除
insert:
iterator insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos <= _finish);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;//虽然扩容了,但是pos与_start的距离不会变,所以记录下来
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + len;//reserve走完,pos指向的旧空间就找不到或者销毁了,要更新pos的位置,否则会面临迭代器失效的问题
}
iterator end = _finish - 1;
while (pos <= end)
{
*(end + 1) = *end;
--end;//不用担心pos为0,end--变成负的,因为这里是指针
}
*pos = val;
_finish++;
return pos;
}
插入时如果为空,就扩容,然后挪到数据。
注意这里的迭代器失效的问题,这里的迭代器失效是指的野指针的问题,因为pos在走完reserve后pos指向的还是旧空间,但是reserve已经将就旧空间释放了,再使用pos就野指针了,但是pos与_start的距离是不会变的,所以用它们记录这个距离,再reserve后再更新pos就能解决问题。
注意返回插入后的迭代器的位置。
erase:
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator start = pos + 1;
while (start != _finish)
{
*(start - 1) = *start;
++start;
}
--_finish;
return pos;
}
删除,挪动数据。
insert迭代器失效问题:
首先就是上面的野指针问题,迭代器失效。
其次就是迭代器虽然能用,但不是想要的位置了的问题。
此问题分为两种情况:
第一。如果之前调用过insert了,扩好容了(这个前提很重要),再插入数据就会面临不是想要的位置的问题:

开始调用了一下insert,说明已经扩好容了,要修改3位置的值,但是实际插入完数据pos的位置指向的数据就变了,指向的就是插入的数据30的位置。

这样也是, 开始调一次insert扩好容了,但是pos还是不是想要的位置。
第二种情况,没有扩好容,此时调用insert就需要扩容,但是扩容后pos的位置更新,pos就指向其它的位置了,再使用这个pos就找不到了,再改动数据也没有用。(但是这并不属于野指针,所以不会报错,因为pos并没有被销毁,只是指向了其它的位置。)
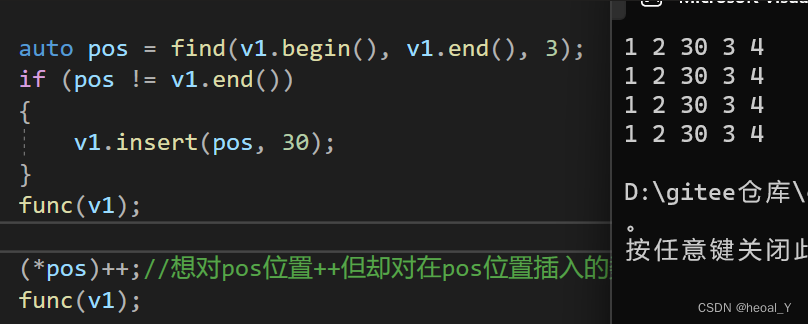
如何解决?
能不能用引用解决呢?
![]()

不能,因为begin里面是一个传值返回,返回的是临时变量的拷贝,临时变量具有常性,不能权限放大。
使用返回值记录迭代器的位置即可:

但是最好还是不要用insert后的pos,就认为它失效了,因为不知道insert里面什么时候扩容,一旦扩容就要考虑是否失效的问题;库里面实现的效果是,如果不用返回值接收pos的位置,还去使用迭代器的位置,就会断言失败。

erase迭代器失效问题:
(还剩一个更深的拷贝,erase迭代器失效,笔记中的)
9.头插头删
void push_back(const T& val)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity()* 2);//不能直接扩容二倍,如果开始是0,就错了;这里走完reserve成员变量都被初始化了
}
*_finish = val;//_finsih不会是空指针,因为如果_finish为空,说明都是_start,_end_of_storage都为空,肯定会走上面的if,然后走reserve就初始化了
_finish++;
}
void pop_back()
{
assert(!empty());
--_finish;//这样就找不到末尾的数据了
}
注意头插扩容与头删判空。判空就是_start==_finish为真就是空。
10.[]重载
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}
注意提供const版本,const的对象调用[]不能修改本身,但是普通对象调用[]后是可以修改的。
11.完整代码与测试
#pragma once
#include <iostream>
#include <assert.h>
#include <vector>
#include <string>
#include <string.h>
using namespace std;//不能放到头文件的前面,不然头文件展开后,往下找就找不到库了,头文件就不能用了
namespace my_vector
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
:_start(nullptr)//不管调用哪个构造,带参的还是不带参数的,都要给初始化列表,因为不给初始化后成员变量都是随机值;或者是成员变量声明时给缺省
,_finish(nullptr)
,_end_of_storage(nullptr)
{}
vector(size_t n, const T& val = T())//使用匿名对象初始化,例如模版参数是int也就成0了
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n;++i)
{
push_back(val);
}
}
vector(int n, const T& val = T())//没有这个会出现非法的间接寻址的错误,编译器识别不出来两个参数的构造是调用迭代器的那个还是这个。
:_start(nullptr)
, _finish(nullptr)
, _end_of_storage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n; ++i)
{
push_back(val);
}
}
不传统的拷贝构造,但是是可以的
//vector(const vector<T>& v)
//{
// reserve(v.capacity());
// for (auto e : v)
// {
// push_back(e);//this->push_back(e)
// }
//}
//vector(const vector<T>& v)
//{
// //reserve(v.capacity());
// //扩容也可不复用
// _start = new T[v.capacity()];
// //memcpy(_start, v._start, sizeof(T) * v.size());
// for (size_t i = 0; i < v.size(); ++i)
// {
// _start[i] = v._start[i];//[]就是解引用
// }
// _finish = _start + v.size();
// _end_of_storage = _start + v.capacity();
//}
//很现代的拷贝构造(不对???为什么???要提供两个迭代器区间的构造才能用)
//vector(const vector<T>& v) //语法上支持拷贝构造和赋值不加模版参数
vector(const vector<T>& v)
{
vector<T> tmp(v.begin(), v.end());//这个要提供两个迭代器区间的构造才能用
swap(tmp);
//swap(v);//不能这样直接调用,v的类型不支持swap的参数
}
void swap( vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_end_of_storage, v._end_of_storage);
}
~vector()
{
delete[] _start;//销毁_start指向的这块空间
_start = _finish = _end_of_storage = nullptr;
}
vector<T>& operator=(vector<T>& v)
{
swap(v);
return *this;
}
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _end_of_storage - _start;
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
iterator begin() const
{
return _start;
}
iterator end() const//这里的const是修饰的调用者的const,所以调用者不能修改数据;而返回值是如果是const迭代器那就是迭代器不能走了,不能遍历了,不行
{
return _finish;
}
//类模版的成员函数还可以带模版,这个模版可以用主模板的模版参数,也可以用自己的
template<class InputIterator>
vector(InputIterator first, InputIterator last)//用迭代器区间初始化,这个迭代器区间的类型可以是任何迭代器区间的类型,所以给上模版参数
:_start(nullptr)
, _finish(nullptr)
,_end_of_storage(nullptr)
{
while (first != last)//不能用小于,假设是链表传过来的迭代器区间,空间不是连续的,不能保证前面的节点的地址就小于后面的
{
push_back(*first);
++first;
}
}
void reserve(size_t n)
{
if (n > capacity())
{
size_t sz = size();
T* tmp = new T[n];
if (_start)//如果旧空间为空,就不进if了,直接让旧空间开好的空间;其次也因为if中要对_start解引用
{
//memcpy是浅拷贝,因为按字节拷贝还是两个开辟出了的指针指向同一块空间
//memcpy(tmp,_start,sizeof(T)*size());//这里乘capacity可能会造成浪费,因为capacity开的空间比较多
for (size_t i = 0; i < size(); ++i)
{
tmp[i] = _start[i];//如果模版参数是string这样的自定义类型,而且有开辟的空间,肯定是要深拷贝的,而这里的赋值就会调用string的赋值,符合深拷贝
}
delete[] _start;
}
_start = tmp;
_finish = sz + _start;//虽然扩容了,但是原有的finish的位置不能变,所以上面要记录一下;而且_start也变了,原来的size()就不能用了
_end_of_storage = _start + n;
}
}
void push_back(const T& val)
{
if (_finish == _end_of_storage)
{
reserve(capacity() == 0 ? 4 : capacity()* 2);//不能直接扩容二倍,如果开始是0,就错了;这里走完reserve成员变量都被初始化了
}
*_finish = val;//_finsih不会是空指针,因为如果_finish为空,说明都是_start,_end_of_storage都为空,肯定会走上面的if,然后走reserve就初始化了
_finish++;
}
void pop_back()
{
assert(!empty());
--_finish;//这样就找不到末尾的数据了
}
void resize(size_t n,T val=T())//任意类型都有默认构造
{
if (n < capacity())
{
_finish = _start + n;
}
else
{
if (n > capacity())
{
reserve(n);
}
while ((_start + n) != _finish)
{
*_finish = val;//源码使用的是定位new,但这里的空间都是直接new出来的,定位new针对的是内存池
_finish++;
}
}
}
iterator insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos <= _finish);
if (_finish == _end_of_storage)
{
size_t len = pos - _start;//虽然扩容了,但是pos与_start的距离不会变,所以记录下来
reserve(capacity() == 0 ? 4 : capacity() * 2);
pos = _start + len;//reserve走完,pos指向的旧空间就找不到或者销毁了,要更新pos的位置,否则会面临迭代器失效的问题
}
iterator end = _finish - 1;
while (pos <= end)
{
*(end + 1) = *end;
--end;//不用担心pos为0,end--变成负的,因为这里是指针
}
*pos = val;
_finish++;
return pos;
}
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos < _finish);
iterator start = pos + 1;
while (start != _finish)
{
*(start - 1) = *start;
++start;
}
--_finish;
return pos;
}
void empty()
{
return _start == _finish;
}
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
void func(const vector<int>& v)
{
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl;
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
void Testvector1()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
for (size_t i = 0; i < v1.size(); ++i)
{
cout << v1[i] << " ";
}
cout << endl;
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
func(v1);
}
//template<class T>
//void f()
//{
// T x = T();//都是初始化为0
// cout << x << endl;
//}
//void test_vector2()
//{
// //内置类型有没有构造函数?没有,但是能这样写
// /*int i = int();这样结果是0
// int j = int(1);*/
// f<int>();//匿名对象
// f<int*>();
// f<double>();
//}
void Testvector2()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
cout << v1.size() << endl;
cout << v1.capacity() << endl;
v1.resize(10);
cout << v1.size() << endl;
cout << v1.capacity() << endl;
v1.resize(3);
func(v1);
}
void Testvector3()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);//为什么只插入4个会越界呢?因为只插入4个再调insert会扩容,一扩容pos指向的位置会变,就会面临迭代器失效
//而插入5个数据在push_back的时候就已经扩容了,insert就不再扩容了
/*v1.insert(v1.begin(), 0);
func(v1);*/
auto pos = find(v1.begin(), v1.end(), 3);
if (pos != v1.end())
{
pos = v1.insert(pos, 30);
}
func(v1);
//最好不要用,不知道insert什么时候扩容,扩容就会面临着pos失效的问题
(*pos)++;//想对pos位置++但却对在pos位置插入的数据++了,怎么办?
func(v1);
}
void Testvector4()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);//为什么只插入4个会越界呢?因为只插入4个再调insert会扩容,一扩容pos指向的位置会变,就会面临迭代器失效
//而插入5个数据在push_back的时候就已经扩容了,insert就不再扩容了
/*v1.insert(v1.begin(), 0);
func(v1);*/
auto pos = find(v1.begin(), v1.end(), 3);
if (pos != v1.end())
{
v1.erase(pos);
}
func(v1);
}
void Testvector5()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int>::iterator it = v1.begin();
while (it != v1.end())
{
if (*it % 2 == 0)
{
it = v1.erase(it);//erase以后就不能访问了,g++可以,还是认为erase后迭代器失效,用返回值接收即可
}
else
{
it++;
}
}
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void Testvector6()
{
vector<int> v1(10, 5);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}
void Testvector7()
{
vector<int> v1(10, 5);
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
vector<int> v2(v1);//不写构造,对于动态开辟的new出来的需要深拷贝,默认的值拷贝就不行了
for (auto e : v2)
{
cout << e << " ";
}
cout << endl;
vector<std::string> v3(3, "1111111111111111111");
for (auto e : v3)
{
cout << e << " ";
}
cout << endl;
vector<std::string> v4(v3);
for (auto e : v4)
{
cout << e << " ";
}
cout << endl;
v4.push_back("2222222");
v4.push_back("2222222");
v4.push_back("2222222");
for (auto e : v4)
{
cout << e << " ";
}
}
}






![[计算机效率] 鼠标手势工具:WGestures(解放键盘的超级效率工具)](https://img-blog.csdnimg.cn/direct/19d90fc41eaa412b8786eddac9aff2b3.png)