Transformer模型-数据预处理,训练,推理(预测)的简明介绍
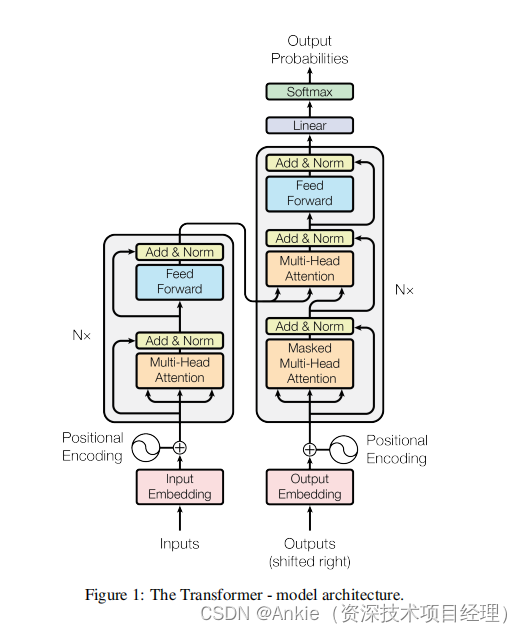
在继续探讨之前,假定已经对各个模块的功能有了充分的了解:
人工智能AI 虚拟现实VR 黑客帝国_Ankie(资深技术项目经理)的博客-CSDN博客![]() https://blog.csdn.net/ank1983/category_12546474.html
https://blog.csdn.net/ank1983/category_12546474.html
数据预处理
将德语翻译成英语,本文将使用torchtext.datasets中的Multi30k数据集。它包含训练集、验证集和测试集。所有用于加载分词器、生成词汇表、处理数据和生成批次的自定义函数都可以在附录中找到。
第一步是从spaCy加载每种语言的分词器,并使用load_vocab为两种语言创建词汇表。它调用build_vocabary,这是一个自定义函数,它使用torchtext.vocab中的build_vocab_from_iterator函数。词汇表中单词出现的最小频率为2,并且词汇表中的每个单词均为小写。build_vocabulary函数加载Multi30k数据集以生成词汇表。

生成词汇表后,可以设定一些全局变量,这些变量将以大写字母表示。以下变量分别代表“<bos>”、“<eos>”和“<pad>”的索引,这些索引对于源语言和目标语言的词汇表都是相同的。
BOS_IDX = vocab_trg['<bos>']
EOS_IDX = vocab_trg['<eos>']
PAD_IDX = vocab_trg['<pad>']
接下来可以加载数据集进行处理。
# raw data
train_data_raw, val_data_raw, test_data_raw = datasets.Multi30k(language_pair=("de", "en"))
每个集合都是一个数据迭代器,可以看作是一系列元组的列表。每个元组包含一个德语-英语对,例如(“Wie heißt du?”,“What is your name?”)。这些数据可以根据词汇表进行分词并转换为相应的索引。这些操作在自定义函数data_process中执行。
# processed data
train_data = data_process(train_data_raw)
val_data = data_process(val_data_raw)
test_data = data_process(test_data_raw)
现在,这些数据迭代器可以传递给torch.utils.data中的DataLoader,用于在训练期间生成批次。DataLoader需要数据迭代器、批次大小以及用于自定义批次的collate函数。它还允许打乱批次,并在最后一批不是完整批次时将其丢弃。需要提醒的是,批次大小是每个优化步骤中使用的序列数。
在下面的代码中,MAX_PADDING表示序列可以拥有的最大令牌数。torch.nn.functional中的pad函数会截断任何长于该值的序列,否则添加填充。这由generate_batch函数使用,该函数向序列中添加“<bos>”、“<eos>”和“<pad>”令牌,并生成用于训练的批次。在创建每个DataLoader时,数据迭代器被转换为映射风格的数据集,因为它们可以轻松地被打乱,并且可以根据需要提供其大小。
MAX_PADDING = 20
BATCH_SIZE = 128
train_iter = DataLoader(to_map_style_dataset(train_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)
valid_iter = DataLoader(to_map_style_dataset(val_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)
test_iter = DataLoader(to_map_style_dataset(test_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)
创建模型
下一步是创建用于训练数据的模型。可以使用make_model函数传递参数来创建模型,如果GPU可用,可以使用model.cuda()来确保模型将在GPU上进行训练。这些值是凭经验选择的。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = make_model(device, vocab_src, vocab_trg,
n_layers=3, n_heads=8, d_model=256,
d_ffn=512, max_length=50)
model.cuda()
此外,还可以预览模型的总可训练参数,以评估其大小。

创建训练函数
为了训练模型,可以使用学习率为0.0005的Adam优化器,以及Cross Entropy Loss作为损失函数。Cross Entropy Loss接受模型输出的logits作为输入,通过softmax函数进行转换,取每个令牌的argmax,并将其与预期的目标输出进行比较。
LEARNING_RATE = 0.0005
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)
可以使用以下函数来训练模型,这些步骤在每个训练周期中执行。模型根据损失计算logits并更新参数。最后,该函数返回周期中批次的平均损失。请注意,logits和预期输出被重塑为单个序列,而不是单独的序列。对于logits,给定(3, 10, 27),表示由27个元素向量表示的十个令牌的三个序列,新形状将为(30, 27),即一个长序列。当执行argmax时,输出是一个30个元素的向量。预期输出,其形状为(3,10),也可以被重塑为30个元素的向量,然后这两个向量可以很容易地进行比较。
def train(model, iterator, optimizer, criterion, clip):
"""
Train the model on the given data.
Args:
model: Transformer model to be trained
iterator: data to be trained on
optimizer: optimizer for updating parameters
criterion: loss function for updating parameters
clip: value to help prevent exploding gradients
Returns:
loss for the epoch
"""
# set the model to training mode
model.train()
epoch_loss = 0
# loop through each batch in the iterator
for i, batch in enumerate(iterator):
# set the source and target batches
src,trg = batch
# zero the gradients
optimizer.zero_grad()
# logits for each output
logits = model(src, trg[:,:-1])
# expected output
expected_output = trg[:,1:]
# calculate the loss
loss = criterion(logits.contiguous().view(-1, logits.shape[-1]),
expected_output.contiguous().view(-1))
# backpropagation
loss.backward()
# clip the weights
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
# update the weights
optimizer.step()
# update the loss
epoch_loss += loss.item()
# return the average loss for the epoch
return epoch_loss / len(iterator)
下面的评估函数执行与训练函数相同的流程,但不会更新权重。这将在测试集和验证集上使用,以查看模型的泛化能力。
def evaluate(model, iterator, criterion):
"""
Evaluate the model on the given data.
Args:
model: Transformer model to be trained
iterator: data to be evaluated
criterion: loss function for assessing outputs
Returns:
loss for the data
"""
# set the model to evaluation mode
model.eval()
epoch_loss = 0
# evaluate without updating gradients
with torch.no_grad():
# loop through each batch in the iterator
for i, batch in enumerate(iterator):
# set the source and target batches
src, trg = batch
# logits for each output
logits = model(src, trg[:,:-1])
# expected output
expected_output = trg[:,1:]
# calculate the loss
loss = criterion(logits.contiguous().view(-1, logits.shape[-1]),
expected_output.contiguous().view(-1))
# update the loss
epoch_loss += loss.item()
# return the average loss for the epoch
return epoch_loss / len(iterator)
最后,可以创建一个函数来计算每个周期所需的时间。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
训练模型
现在可以创建训练循环来训练模型,并评估其在验证集上的性能。
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
# loop through each epoch
for epoch in range(N_EPOCHS):
start_time = time.time()
# calculate the train loss and update the parameters
train_loss = train(model, train_iter, optimizer, criterion, CLIP)
# calculate the loss on the validation set
valid_loss = evaluate(model, valid_iter, criterion)
end_time = time.time()
# calculate how long the epoch took
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# save the model when it performs better than the previous run
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'transformer-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
输出结果:
Epoch: 01 | Time: 0m 21s
Train Loss: 4.534 | Train PPL: 93.169
Val. Loss: 3.474 | Val. PPL: 32.280
Epoch: 05 | Time: 0m 13s
Train Loss: 1.801 | Train PPL: 6.055
Val. Loss: 1.829 | Val. PPL: 6.229
Epoch: 10 | Time: 0m 13s
Train Loss: 1.093 | Train PPL: 2.984
Val. Loss: 1.677 | Val. PPL: 5.351
在评估结果之前,还可以使用评估函数在测试集上评估模型的准确性。

虽然损失已经显著下降,但并没有表明模型在德语到英语的翻译任务上有多成功。这可以通过两种方式评估。第一种是提供一个句子并在推理过程中预览其翻译。第二种是通过另一个指标(如BLEU)来计算其准确性,BLEU是翻译任务的标准指标。
推理(预测)
通过将句子传递给下面的函数,可以执行实时翻译。句子将被分词并传递给模型,一次生成一个令牌。一旦出现“<eos>”令牌,就会返回输出。
def translate_sentence(sentence, model, device, max_length = 50):
"""
Translate a German sentence to its English equivalent.
Args:
sentence: German sentence to be translated to English; list or str
model: Transformer model used for translation
device: device to perform translation on
max_length: maximum token length for translation
Returns:
src: return the tokenized input
trg_input: return the input to the decoder before the final output
trg_output: return the final translation, shifted right
attn_probs: return the attention scores for the decoder heads
masked_attn_probs: return the masked attention scores for the decoder heads
"""
model.eval()
# tokenize and index the provided string
if isinstance(sentence, str):
src = ['<bos>'] + [token.text.lower() for token in spacy_de(sentence)] + ['<eos>']
else:
src = ['<bos>'] + sentence + ['<eos>']
# convert to integers
src_indexes = [vocab_src[token] for token in src]
# convert list to tensor
src_tensor = torch.tensor(src_indexes).int().unsqueeze(0).to(device)
# set <bos> token for target generation
trg_indexes = [vocab_trg.get_stoi()['<bos>']]
# generate new tokens
for i in range(max_length):
# convert the list to a tensor
trg_tensor = torch.tensor(trg_indexes).int().unsqueeze(0).to(device)
# generate the next token
with torch.no_grad():
# generate the logits
logits = model.forward(src_tensor, trg_tensor)
# select the newly predicted token
pred_token = logits.argmax(2)[:,-1].item()
# if <eos> token or max length, stop generating
if pred_token == vocab_trg.get_stoi()['<eos>'] or i == (max_length-1):
# decoder input
trg_input = vocab_trg.lookup_tokens(trg_indexes)
# decoder output
trg_output = vocab_trg.lookup_tokens(logits.argmax(2).squeeze(0).tolist())
return src, trg_input, trg_output, model.decoder.attn_probs, model.decoder.masked_attn_probs
# else, continue generating
else:
# add the token
trg_indexes.append(pred_token)
测试:
# 'a woman with a large purse is walking by a gate'
src = ['eine', 'frau', 'mit', 'einer', 'großen', 'geldbörse', 'geht', 'an', 'einem', 'tor', 'vorbei', '.']
src, trg_input, trg_output, attn_probs, masked_attn_probs = translate_sentence(src, model, device)
print(f'source = {src}')
print(f'target input = {trg_input}')
print(f'target output = {trg_output}')
输出:
source = ['<bos>', 'eine', 'frau', 'mit', 'einer', 'großen', 'geldbörse', 'geht', 'an', 'einem', 'tor', 'vorbei', '.', '<eos>']
target input = ['<bos>', 'a', 'woman', 'with', 'a', 'large', 'purse', 'walking', 'past', 'a', 'gate', '.']
target output = ['a', 'woman', 'with', 'a', 'large', 'purse', 'walking', 'past', 'a', 'gate', '.', '<eos>']
原文链接:
https://medium.com/@hunter-j-phillips/putting-it-all-together-the-implemented-transformer-bfb11ac1ddfe