JavaScript逆向爬取—使用Python实现列表页内容爬取
1. 案例介绍
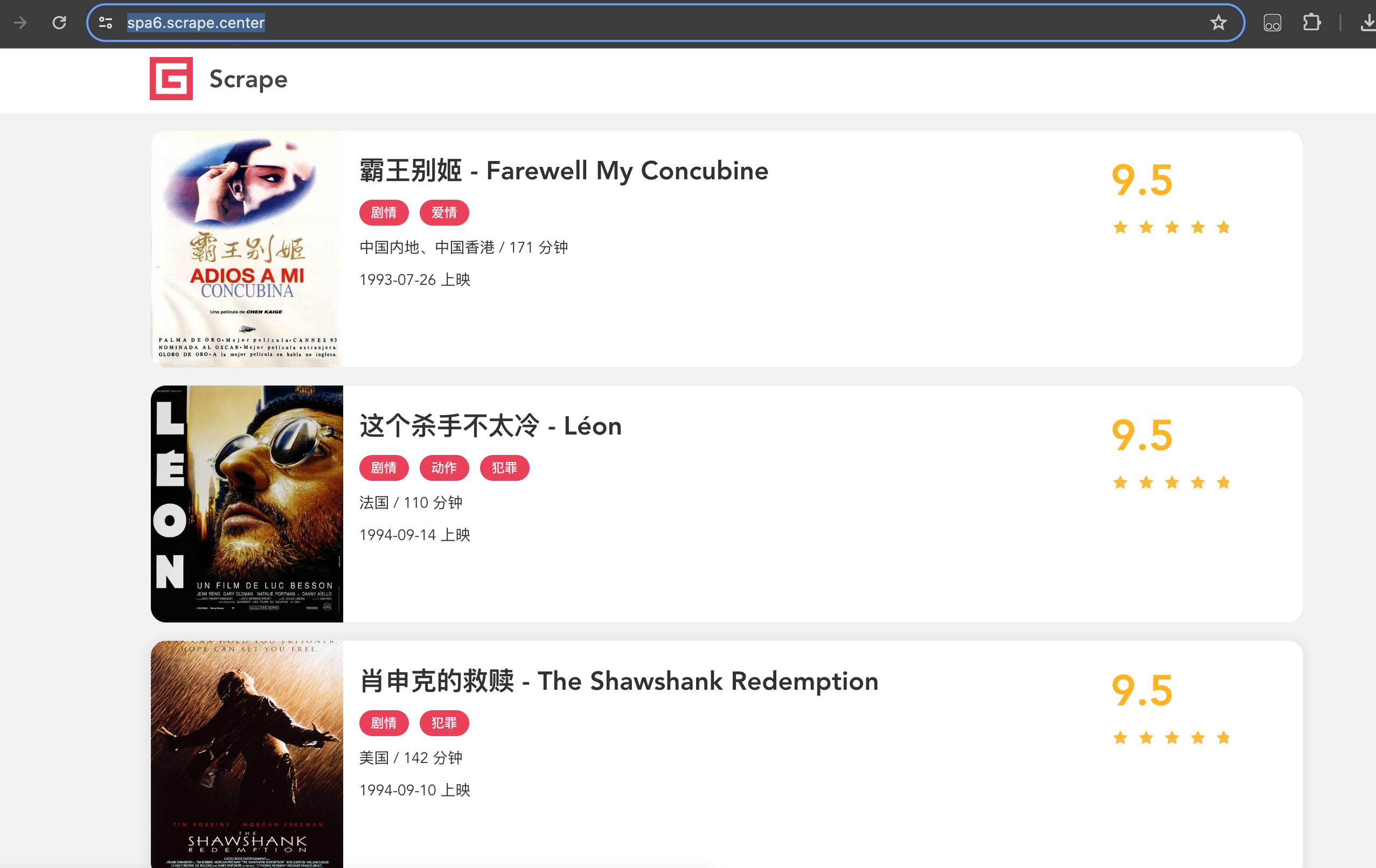
案例网址:https://spa6.scrape.center/, 如图所示:
点击任意一步电影,观察一下URL的变化,如图所示:
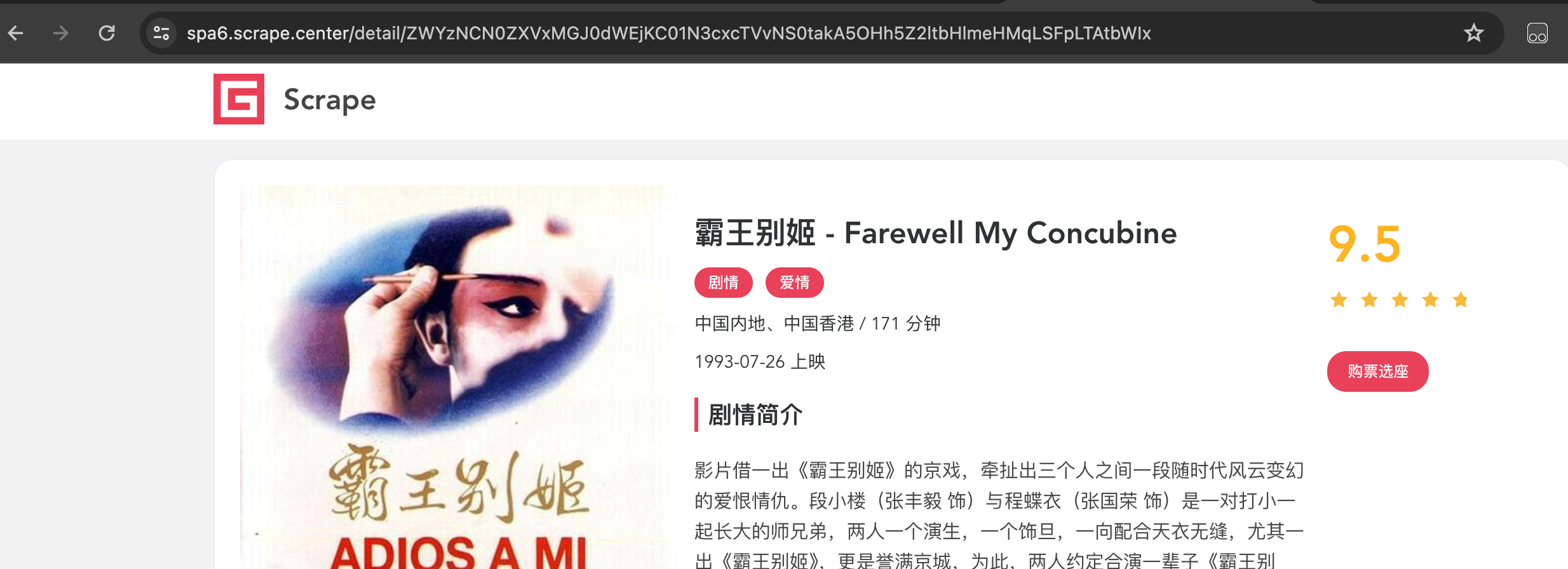
看到详情页URL包含了一个长字符串,看上去像是Base64编码的内容。
看看Ajax的请求,从列表页的第1页到第10页依次点击一下,观察Ajax请求是怎么样的,如图所示:
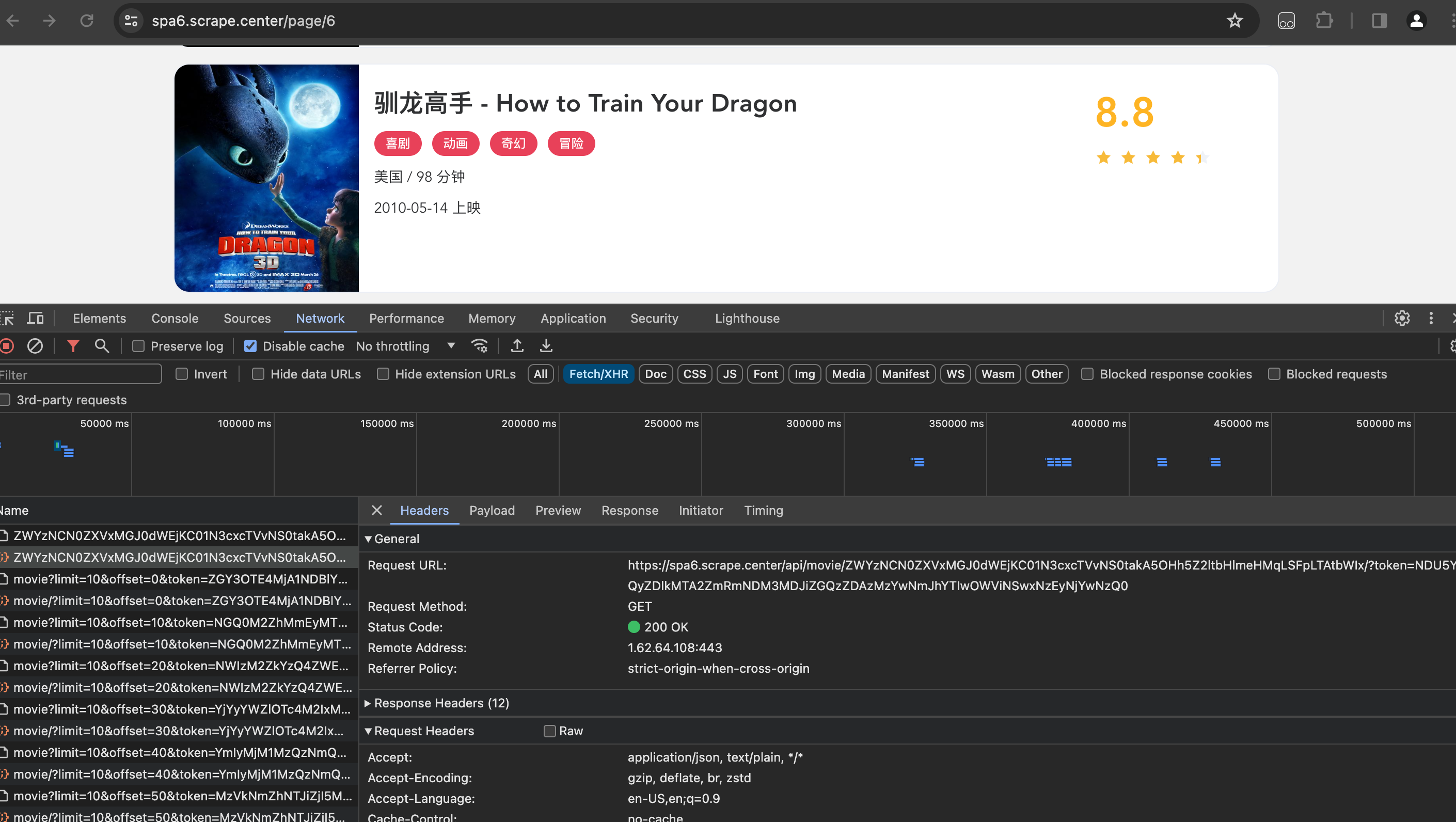
可以看到,Ajax接口的URL里多了一个token,而且在不同的页码,token是不一样的,它们同样看似是Base64编码的字符串。而且这个接口还有时效性。如果我们把Ajax接口的URL直接复制下来,短期内可以访问,但是过段时间就无法访问了,会直接返回401状态码。
再看一下列表页的返回结果,比如打开第一个请求,看看第一部电影数据的返回结果,如图所示:
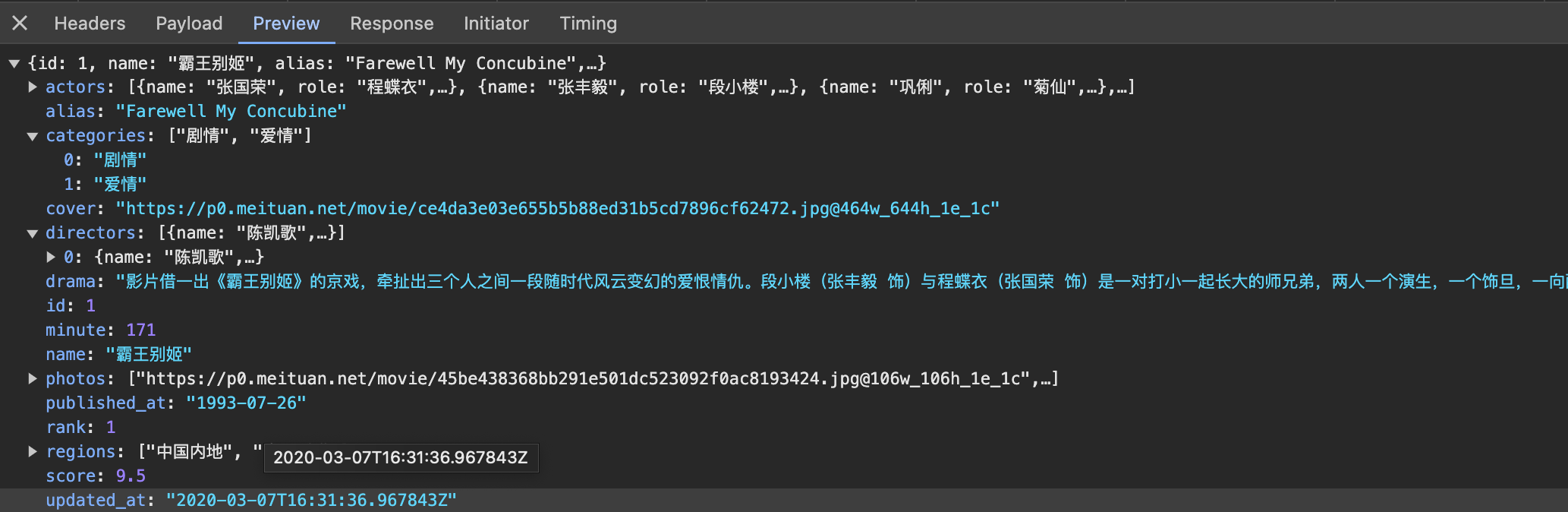
第一部电影的URL是https://spa6.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx,看起来是Base64编码,对它进行解码,结果为ef34#teuq0btua#(-57w1q5o5–j@98xygimlyfxs*-!i-0-mb1,看起来似乎还是毫无规律,这个解码后的结果又是怎么来的呢?返回结果里也并不包含这个字符串,这是怎么构造的呢?其真实数据是通过Ajax加载的,那么Ajax请求又是怎样的呢?如下图所示:
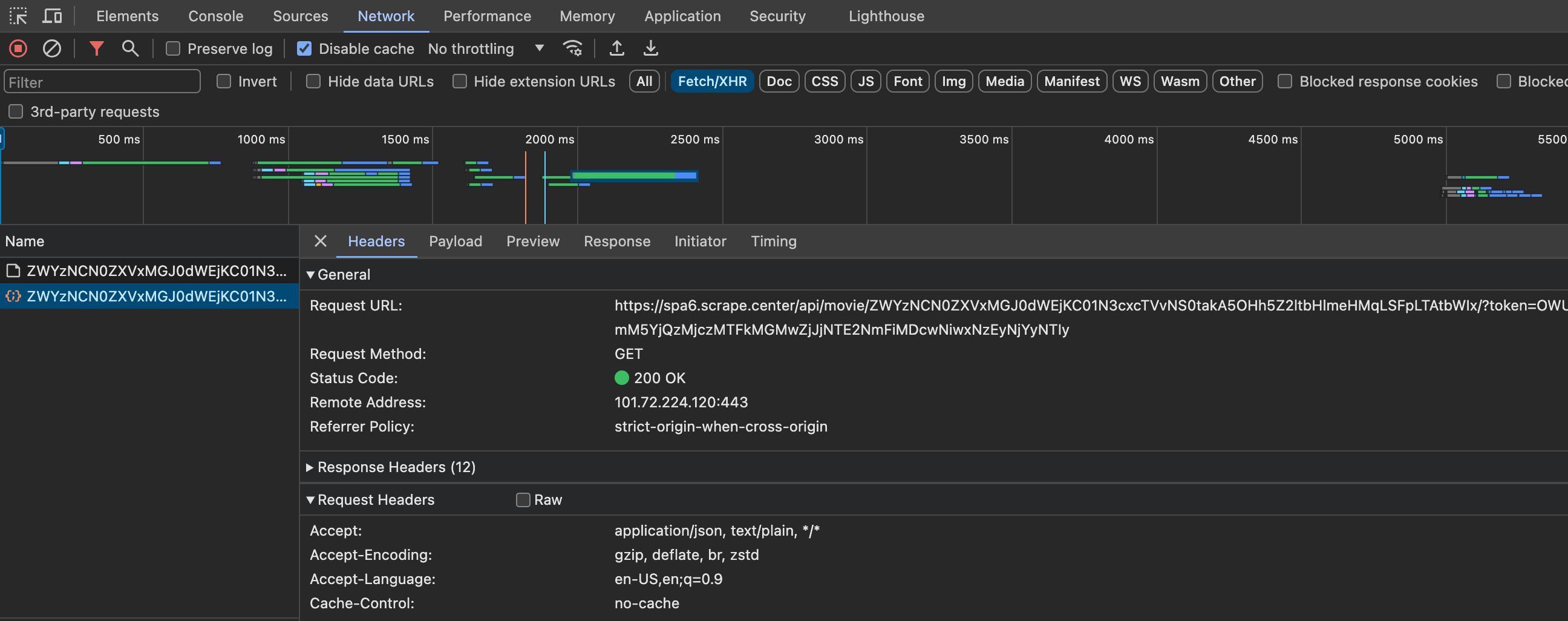
发现Ajax接口除了包含刚才说的URL中携带的字符串,又多了一个token,同样也是类似Base64编码的内容。这个网站有如下特点:
- 列表页的Ajax接口参数带有加密的token
- 详情页的URL带有加密id
- 详情页的Ajax接口参数带有加密id和加密token
那么爬取的逻辑就是,必须把这些加密id和token构造出来才行,而且必须一步步来。首先构造出列表页Ajax接口的token参数,然后获取每部电影的数据信息,接着根据数据信息构造出加密id和加密token。
由于是网页,所以其加密逻辑一定藏在前端代码里,前端为了保护器接口加密逻辑不被轻易分析出来,会采取压缩、混淆等方式来加大分析等难度。
首先看网站的源代码,在网站上点击鼠标右键,此时会弹出快捷菜单,然后点击“查看源代码”选项,结果如下图所示:
内容如下:
<!DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="width=device-width,initial-scale=1"><link rel=icon href=/favicon.ico><title>Scrape | Movie</title><link href=/css/chunk-19c920f8.2a6496e0.css rel=prefetch><link href=/css/chunk-2f73b8f3.5b462e16.css rel=prefetch><link href=/js/chunk-19c920f8.c3a1129d.js rel=prefetch><link href=/js/chunk-2f73b8f3.8f2fc3cd.js rel=prefetch><link href=/js/chunk-4dec7ef0.e4c2b130.js rel=prefetch><link href=/css/app.ea9d802a.css rel=preload as=style><link href=/js/app.5ef0d454.js rel=preload as=script><link href=/js/chunk-vendors.77daf991.js rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet></head><body><noscript><strong>We're sorry but portal doesn't work properly without JavaScript enabled. Please enable it to continue.</strong></noscript><div id=app></div><script src=/js/chunk-vendors.77daf991.js></script><script src=/js/app.5ef0d454.js></script></body></html>
这是一个典型的SPA(单页Web应用)页面,其JavaScript文件名带有编码字符、chunk、vendors等关键字,这就是经过webpack打包压缩后的源代码,目前主流的前端开发框架Vue.js、React.js等的输出结果都是类似这样的。
再看一下JavaScript代码是什么样的。在开发者工具中打开Sources选项卡下的Page选项卡,然后打开js文件夹,在这里看到JavaScript的源代码,如图所示:
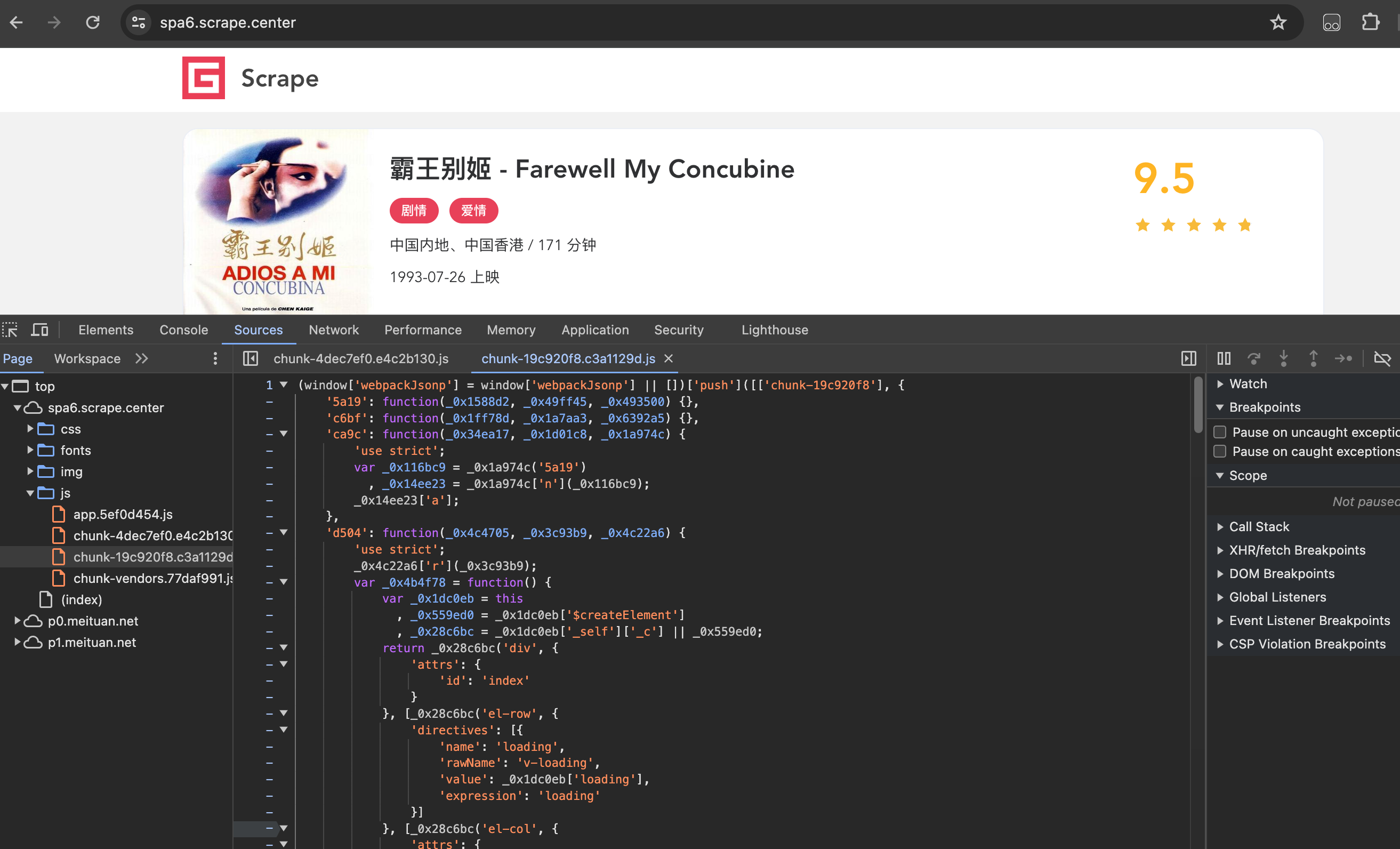
随便复制一些出来,看看是什么样子的,结果如下:
(window['webpackJsonp'] = window['webpackJsonp'] || [])['push']([['chunk-19c920f8'], {
'5a19': function(_0x1588d2, _0x49ff45, _0x493500) {},
'c6bf': function(_0x1ff78d, _0x1a7aa3, _0x6392a5) {},
'ca9c': function(_0x34ea17, _0x1d01c8, _0x1a974c) {
'use strict';
var _0x116bc9 = _0x1a974c('5a19')
, _0x14ee23 = _0x1a974c['n'](_0x116bc9);
_0x14ee23['a'];
},
'd504': function(_0x4c4705, _0x3c93b9, _0x4c22a6) {
'use strict';
_0x4c22a6['r'](_0x3c93b9);
var _0x4b4f78 = function() {
var _0x1dc0eb = this
, _0x559ed0 = _0x1dc0eb['$createElement']
, _0x28c6bc = _0x1dc0eb['_self']['_c'] || _0x559ed0;
return _0x28c6bc('div', {
'attrs': {
'id': 'index'
}
}, [_0x28c6bc('el-row', {
'directives': [{
'name': 'loading',
'rawName': 'v-loading',
'value': _0x1dc0eb['loading'],
'expression': 'loading'
}]
...
...
可以看到一些变量是十六进制字符串,而且代码全部被压缩了。要从这里找出token和id的构造逻辑。
2. 寻找列表页Ajax入口
简单介绍两种寻找入口的方式:
-
全局搜索标志字符串
-
全局搜索标志字符串
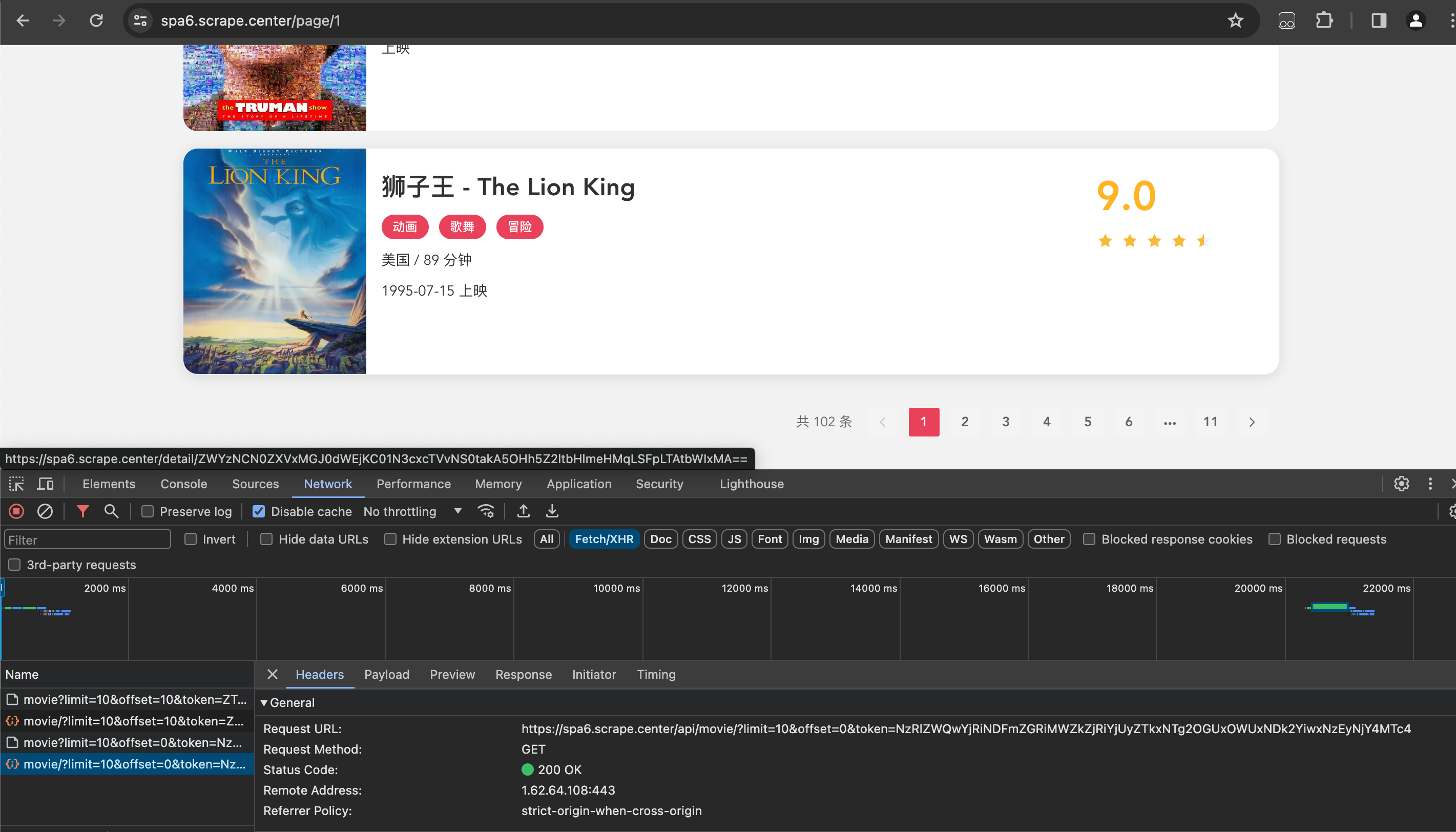
重新打开列表页的Ajax接口,看一下请求的Ajax接口,如图所示:
-
这里Ajax接口的URL为https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=NzRlZWQwYjRiNDFmZGRiMWZkZj RiYjUyZTkxNTg2OGUxOWUxNDk2YiwxNzEyNjY4MTc4,可以看到带有limit、offset、token三个参数,关键就是找token,我 们就全局搜索是否存在token吧!点击开发者右上角“三个小竖点”选项卡,然后点击Search,如下图所示:
这样就进入全局搜索模式,搜索token,可以看到的确搜索到几个结果,如下图所示:
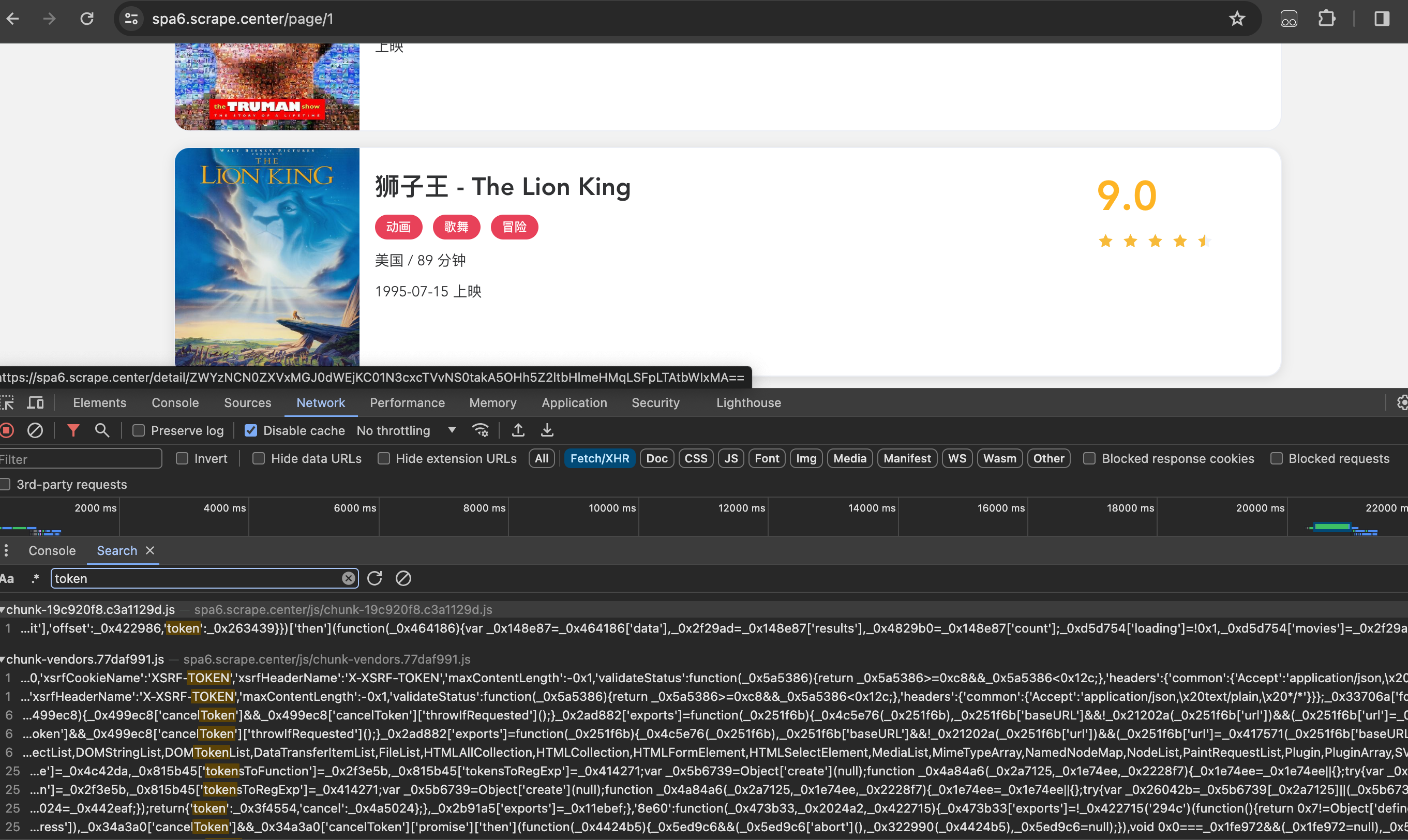
经过观察,下面的两个结果可能是我们想要的,点击第一个进入看看,此时定位到一个JavaScript文件,如下图所示:
这时可以看到整个代码都是经过压缩的,只有一行,不好看,点击左下角的{}按钮,格式化JavaScript代码,格式化后的结果如 下图所示:
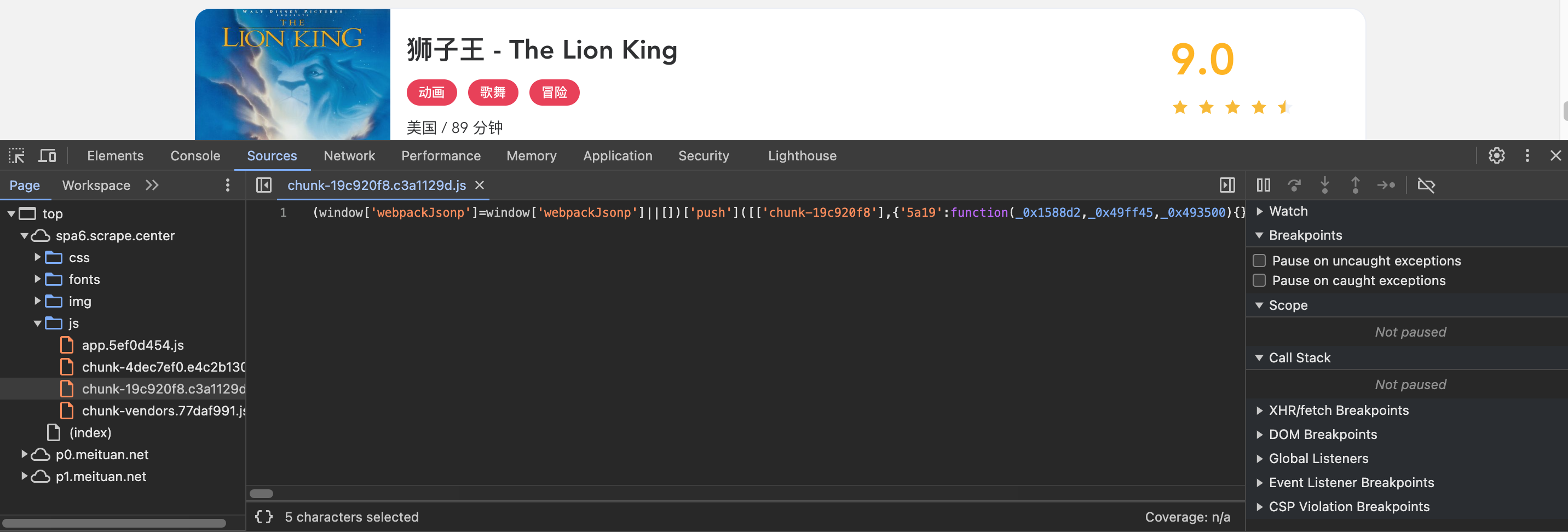
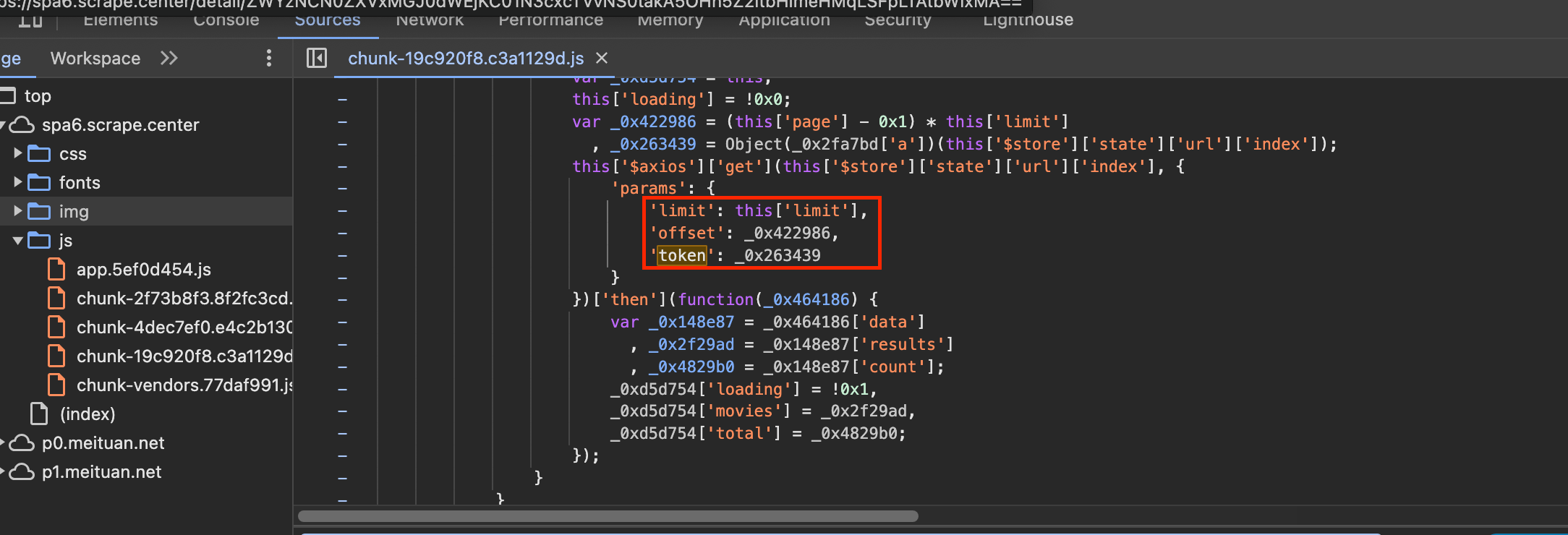
这里我们再次定位到token,观察一下看到有limit、offset、token。然后观察其他的逻辑,基本上能确定这就是构造Ajax请求的 地方,如果不是的话,可以继续搜索其他文件观察分析。现在,就成功找到了混淆的入口,这是一个寻找入口的首选方法,如下 图所示:
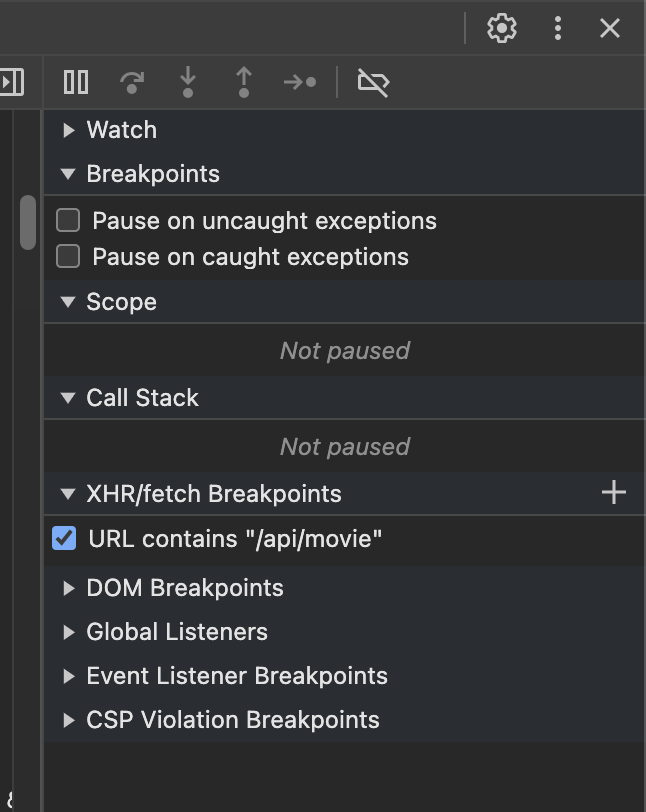
- 设置Ajax断点
我们可以在Sources选项卡右侧XHR/fetch Breakpoints处添加一个断点。首先点击+号,此时就会让我们输入匹配的URL内容。由于Ajax接口的形式是/api/movie/?limit=10…这样的格式,所以截取一段填进去就好了,这里填的就是/api/movie,如图所示:
重新点击格式化按钮{},格式化代码,看看断点在哪里,如下图所示。这里有一个字符send,我们可以初步猜测它相当于发送Ajax请求的一瞬间。
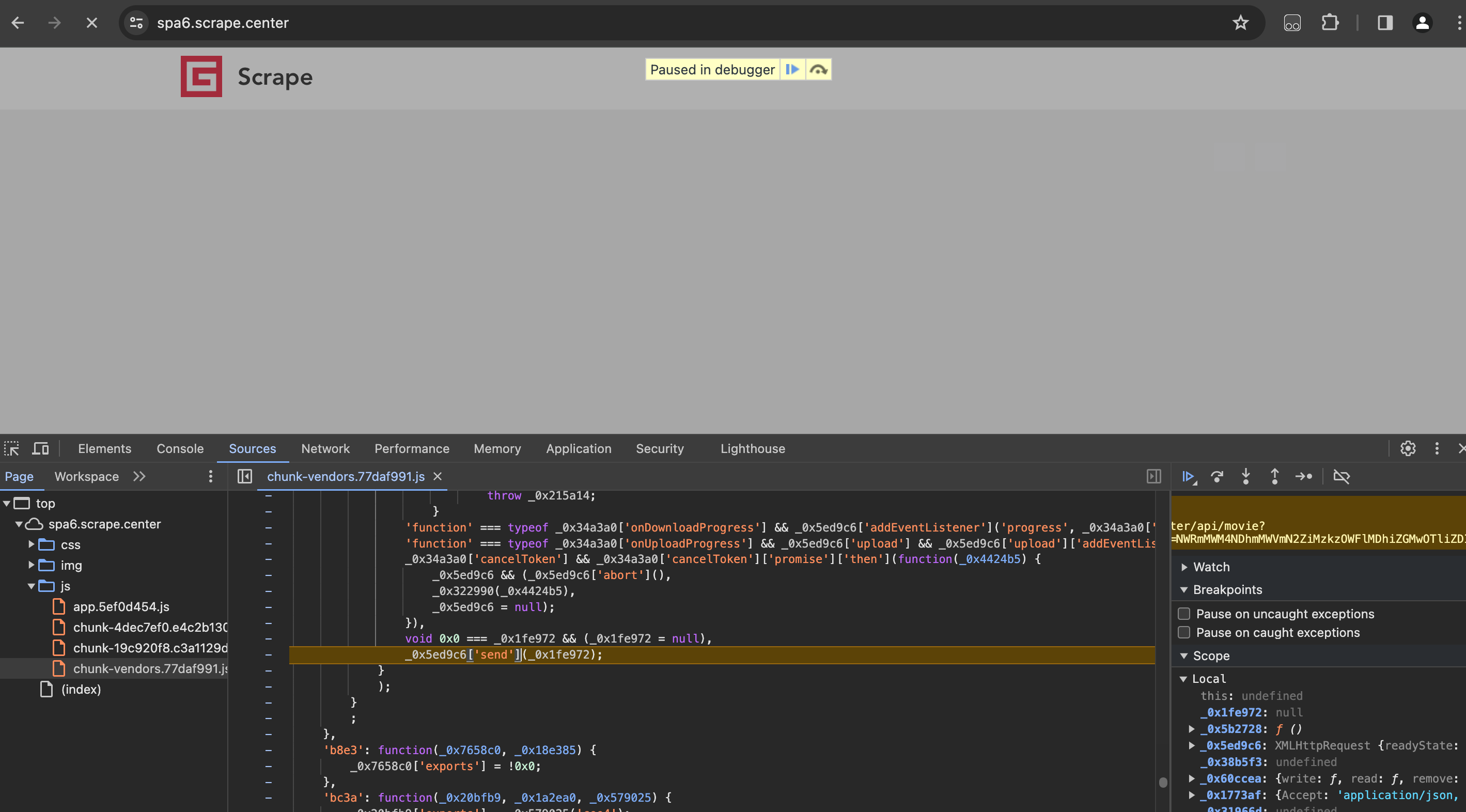
怎样回溯查找相关逻辑的方法,点击右侧的Call Stack,这里记录了JavaScript方法逐层调用的过程,如下图所:
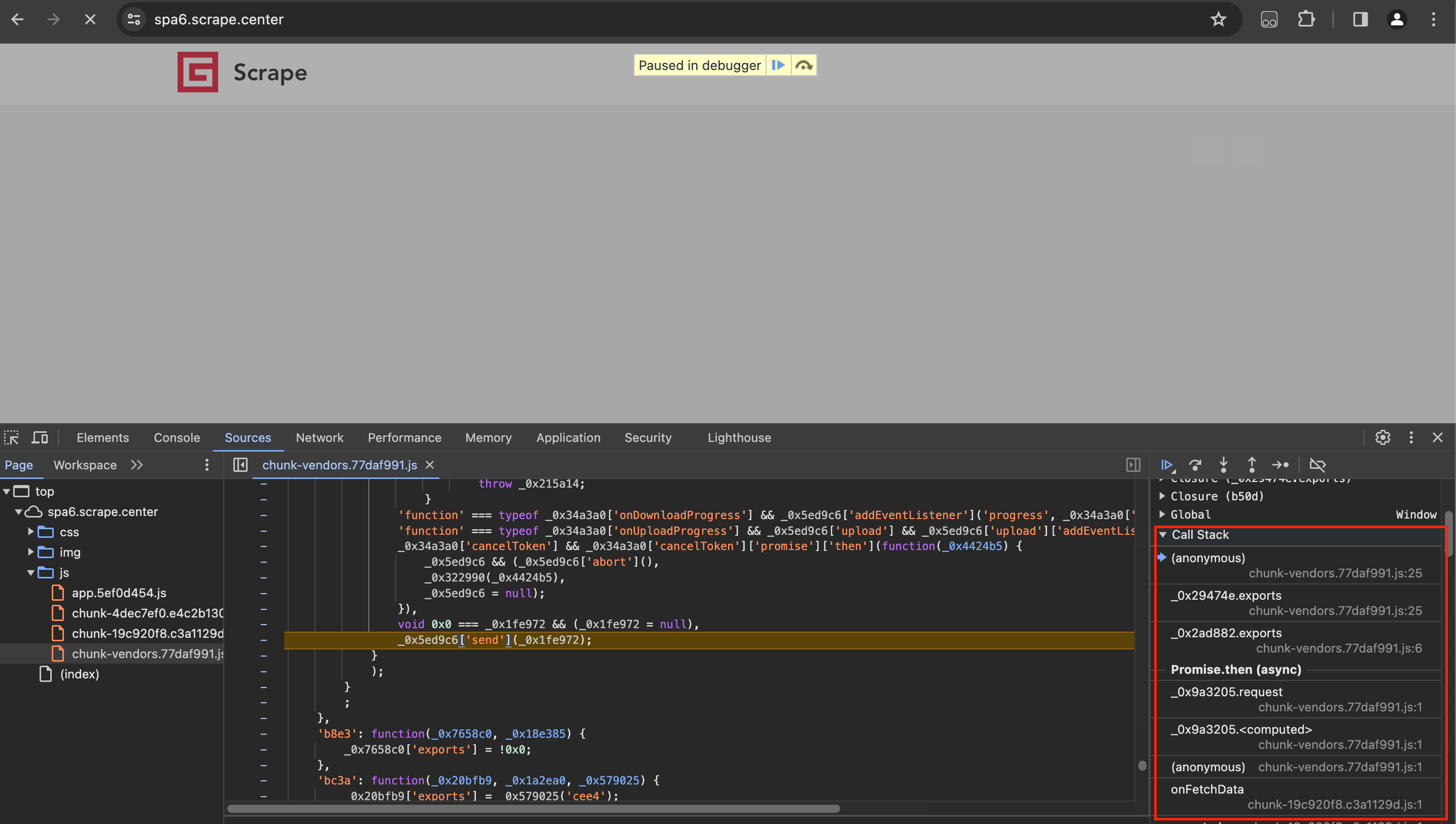 当前指向的是一个名为anonymous(也就是匿名)的调用,在它的下方显示了调用anonymous的方法,名字叫做_0x29474e,然后在下一层就显示了调用_0x2ad882方法的方法,以此类推。继续找下去,注意观察类似token这样的信息,就能找到对应的位置了。最后,找到了onFetchData,这个方法实现了token的构造逻辑,就成功找到了token参数构造位置了。如下图所示:
当前指向的是一个名为anonymous(也就是匿名)的调用,在它的下方显示了调用anonymous的方法,名字叫做_0x29474e,然后在下一层就显示了调用_0x2ad882方法的方法,以此类推。继续找下去,注意观察类似token这样的信息,就能找到对应的位置了。最后,找到了onFetchData,这个方法实现了token的构造逻辑,就成功找到了token参数构造位置了。如下图所示:
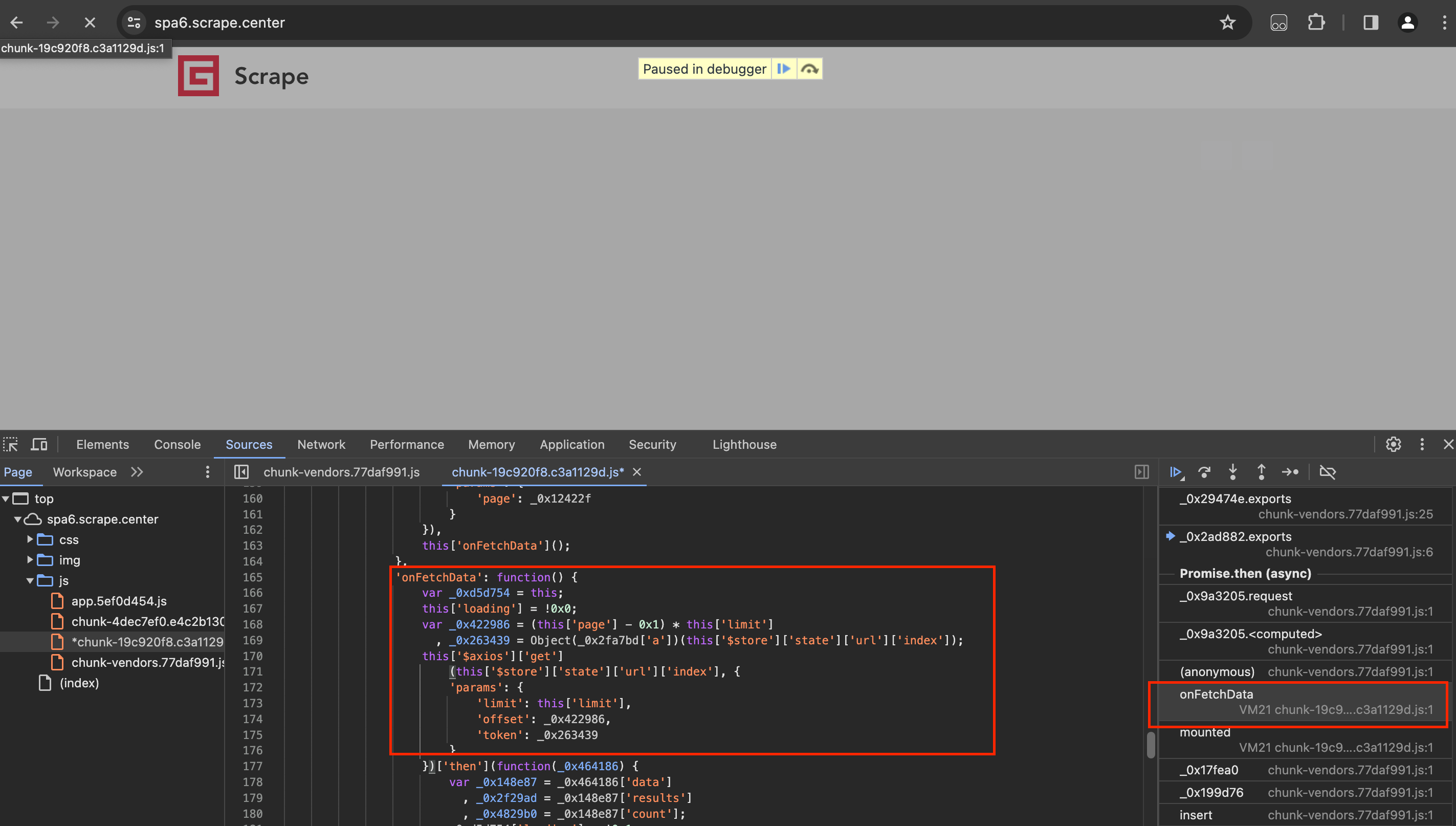
3. 寻找列表页面的加密逻辑
根据上面的回溯查找,已经找到了token的位置了,可以观察这个token对应的变量,它叫做_0x263439,所以关键就是看看这个变量哪里来的。怎么找呢?添加断点就好了。
取消上面设置的断点,看一下这个变量是哪里生成的,如下图所示:
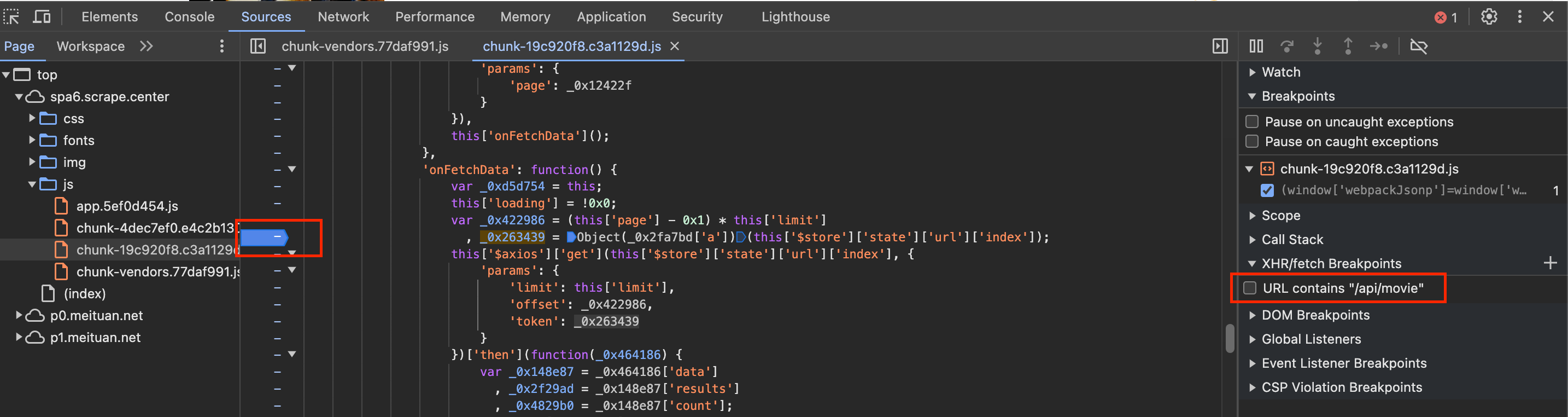
设置了新断点,刷新网页,发现网页停在新的断点上面,如下图所示:
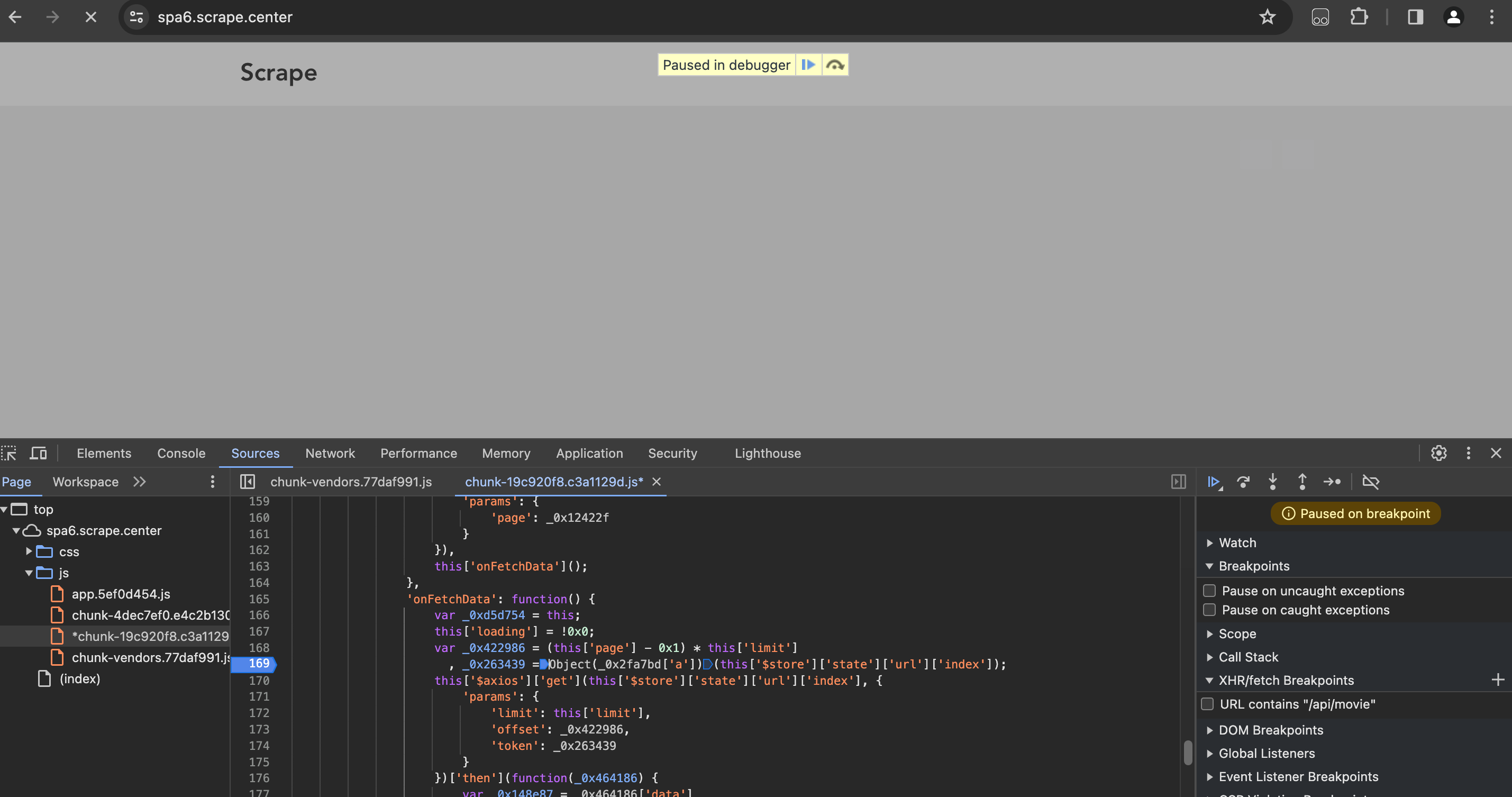
这时我们就可以观察正在运行的一些变量了,比如把鼠标放在各个变量上,可以看到变量的值和类型;把鼠标放在变量_0x2fa7bd上,会有一个浮窗显示,如下图所示:
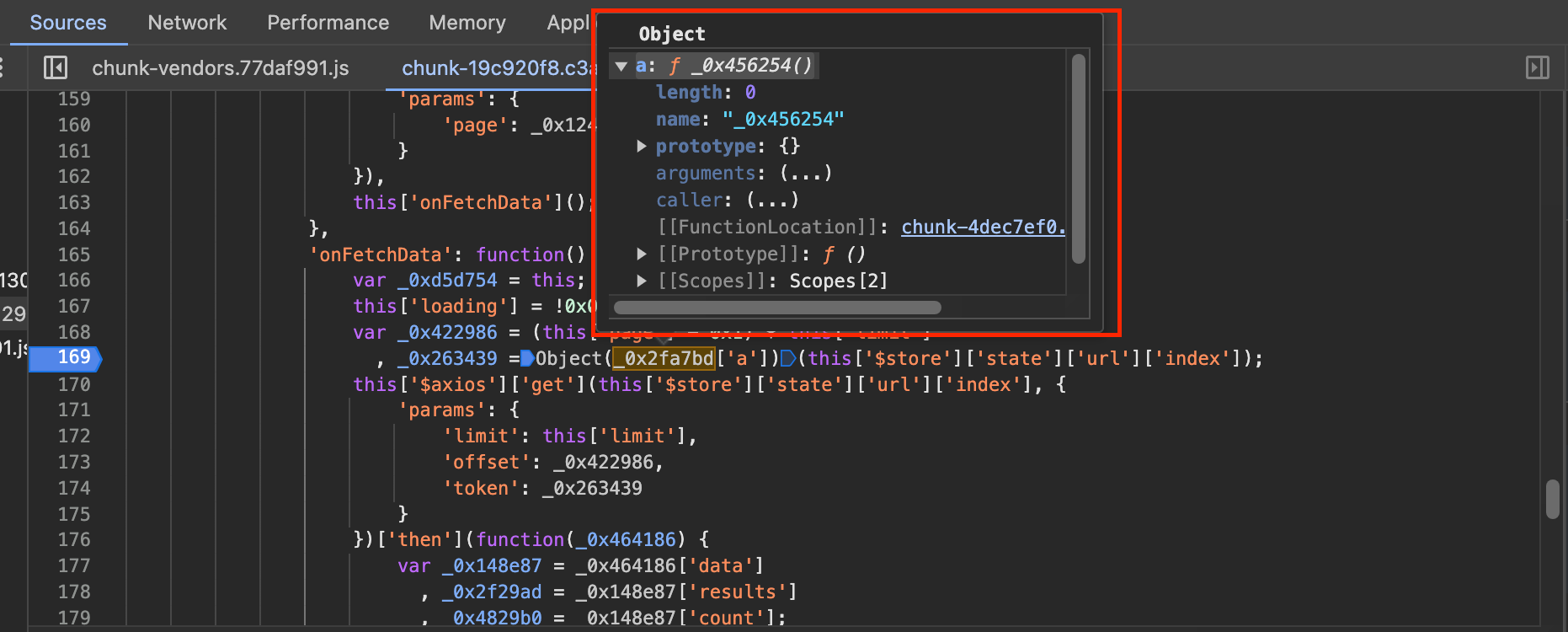
另外,还可以在右侧的Watch面板中添加想要查看的变量,如这行代码的内容为:
, _0x263439 =Object(_0x2fa7bd['a'])(this['$store']['state']['url']['index']);
我们比较感兴趣的可能就是_0x51c425,还有this里的$store属性。展开Watch面板,然后点击+号,把想看的变量添加到Watch面板里面,如下图所示:
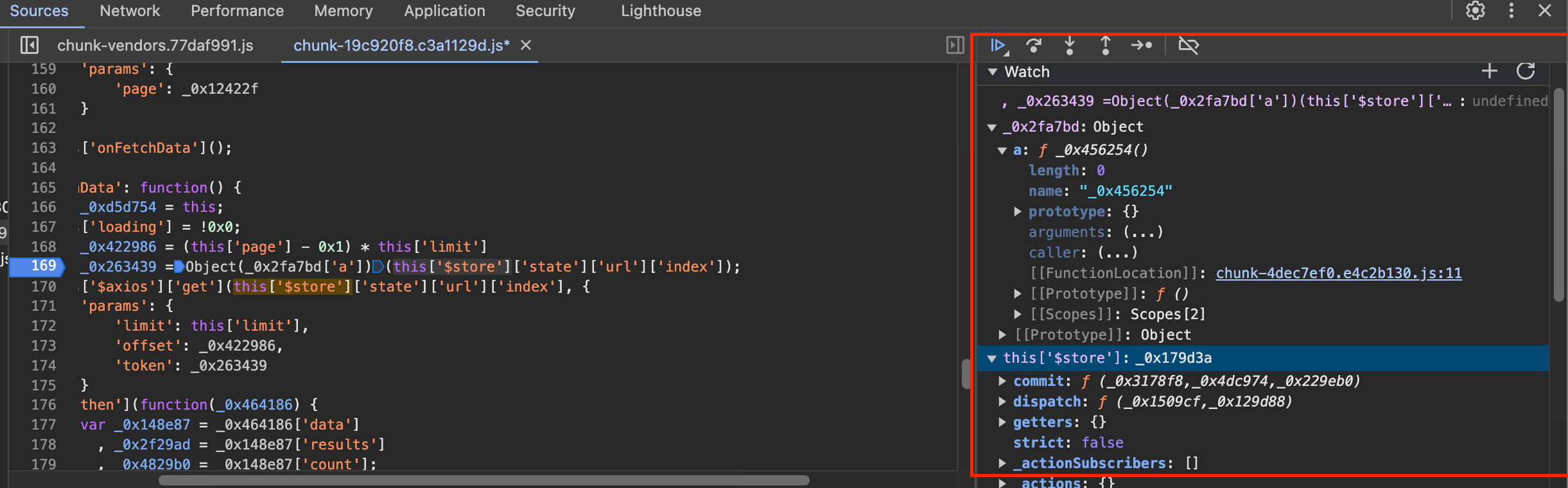
可以发现,_0x2fa7bd是一个对象,它具有属性a,其值是一个方法。this[‘$store’][‘state’][‘url’][‘index’]的值其实就是/api/movie,即Ajax请求URL的Path。_0x263439就是调用前者的方法传入/api/movie得到的。如下图所示:
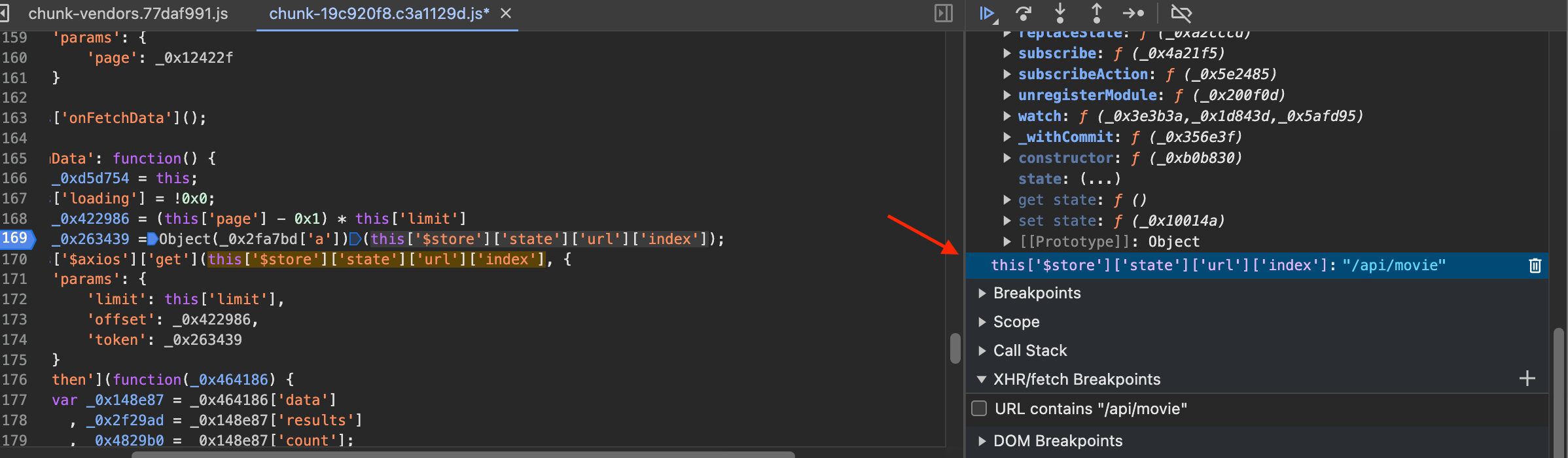
下一步就是去寻找这个方法。我们可以把Watch面板的_0x2fa7bd展开,这里会显示的FunctionLocation就是这个函数的代码位置,如下图所示:
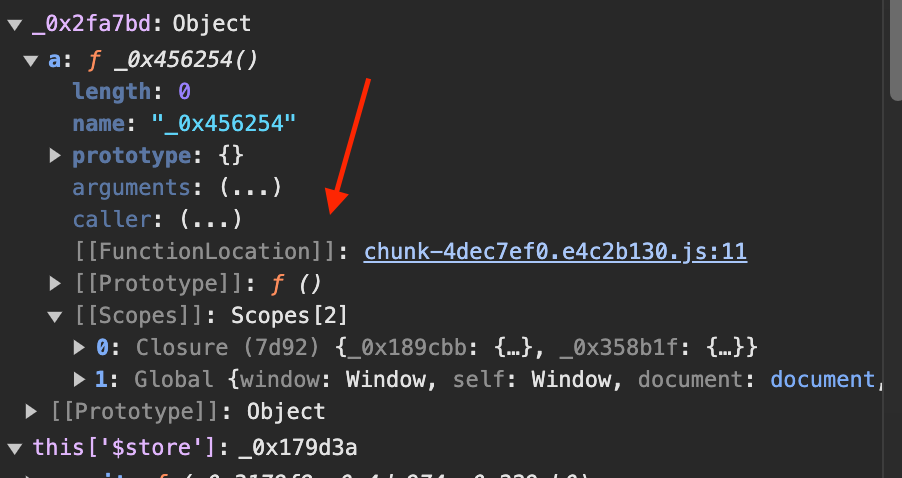
点击进入,这时我们就进入一个新的名字为_0x456254的方法里,在这个方法中,应该就有token的生成逻辑了。添加断点,然后点击面板右上角蓝色箭头状的Resume script execution按钮,如下图所示:
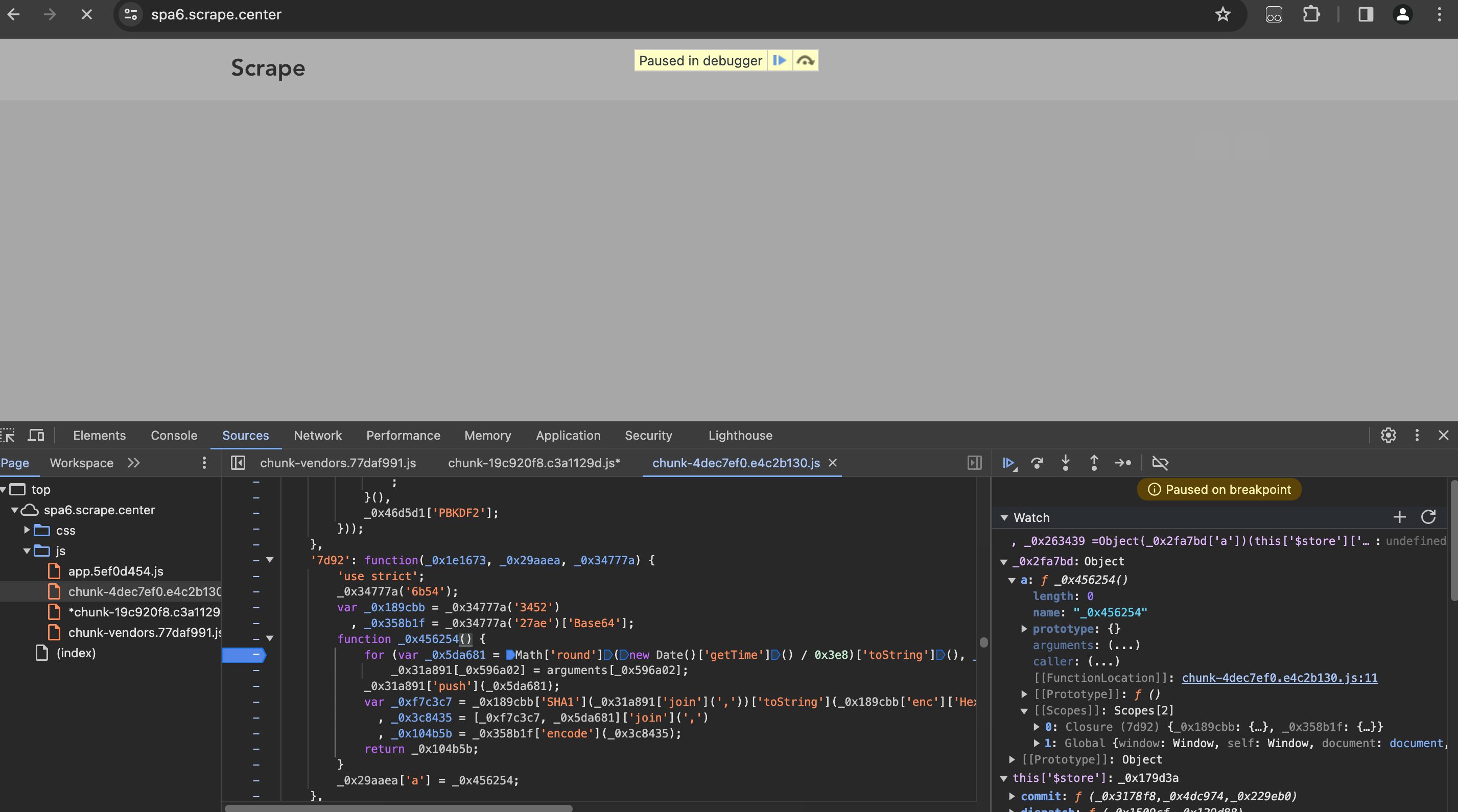
接下来,不断进行单步调试,观察这里的执行逻辑和每一步调试的结果都有啥变化,如下图所示:
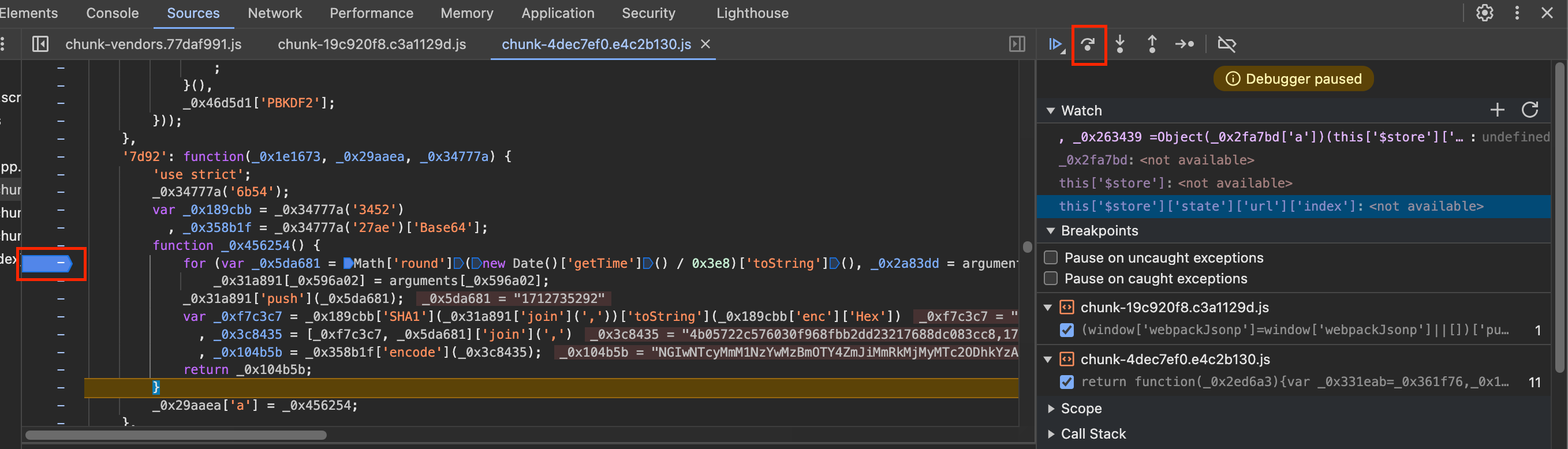
根据上面的单步调试,在Watch面板下看到每步具体结果,总结出这个token的构造逻辑,如下:
- 传入的/api/movie会构造一个初始化列表,将变量命名_0x31a891
- 获取当前的时间戳,命名为_0x5da681,调用push方法将其添加到_0x31a891变量代表的列表中
- 将_0x31a891变量用,拼接,然后进行SHA1编码,命名为_0xf7c3c7
- 将_0xf7c3c7(SHA1编码的结果)和_0x5da681(时间戳)用逗号拼接,命名为_0x3c8435
- 将_0x3c8435进行Base64编码,命名为_0x104b5b,得到最后的token
4. 使用Python实现列表页的爬取
实现这个逻辑,需要借助两个库:一个是hashlib,它提供了sha1方法;另外一个是base64库,它提供了b64encode方法对结果进行Base64编码。实现代码如下:
import hashlib
import time
import base64
from typing import List, Any
import requests
INDEX_URL = 'https://spa6.scrape.center/api/movie?limit={limit}&offset={offset}&token={token}'
LIMIT = 10
OFFSET = 0
def get_token(args: List[Any]):
timestamp = str(int(time.time()))
args.append(timestamp)
sign = hashlib.sha1(','.join(args).encode('utf-8')).hexdigest()
return base64.b64encode(','.join([sign, timestamp]).encode('utf-8')).decode('utf-8')
args = ['/api/movie']
token = get_token(args=args)
index_url = INDEX_URL.format(limit=LIMIT, offset=OFFSET, token=token)
response = requests.get(index_url)
print('response', response.json())
根据上面的逻辑加密流程实现出来了,这里先模拟爬取了第一页的内容,最后运行一下,可以得到最终的输出结果了。如下所示:
/usr/bin/python3 /Users/bruce_liu/PycharmProjects/崔庆才--爬虫/第11章JavaScript逆向爬虫/python爬取列表页.py
response {'count': 102, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国内地', '中国香港']}, {'id': 2, 'name': '这个杀手不太冷', 'alias': 'Léon', 'cover': 'https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c', 'categories': ['剧情', '动作', '犯罪'], 'published_at': '1994-09-14', 'minute': 110, 'score': 9.5, 'regions': ['法国']}, {'id': 3, 'name': '肖申克的救赎', 'alias': 'The Shawshank Redemption', 'cover': 'https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c', 'categories': ['剧情', '犯罪'], 'published_at': '1994-09-10', 'minute': 142, 'score': 9.5, 'regions': ['美国']}, {'id': 4, 'name': '泰坦尼克号', 'alias': 'Titanic',
.....
.....